




之前谈到MySQL的一些Join算法,处置之外,还可以通过优化技术,提高MySQL的查询效率。这些优化开关可以通过optimizer_switch进行控制。下面介绍MySQL的优化技术。
1.index_merge(索引合并)
索引合并(Index Merge)是一种优化技术,允许MySQL在执行查询时结合多个单列索引的结果,以提高查询效率。
在优化器optimizer_switch选项中,存在多种索引合并场景【index_merge,
index_merge_union,index_merge_sort_union,index_merge_intersection】
- index:单条语句多个OR条件。
- intersection:将基于多个索引扫描的结果集取交集后返回给用户。
- union:将基于多个索引扫描的结果集取并集后返回给用户。
- sort-union:与union类似,不同的是sort-union会对结果集进行排序,随后再返回给用户。
mysql>CREATE TABLE T( `id` int NOT NULL AUTO_INCREMENT,
`a` int NOT NULL,
`b` char(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`) USING BTREE,
KEY `idx_b` (`b`) USING BTREE
)ENGINE=InnoDB AUTO_INCREMENT=1;
INSERT INTO T (a, b) VALUES (1, 'A'), (2, 'B'),(3, 'C'),(4, 'D'),(1, 'E');
mysql> explain SELECT * FROM T WHERE a=1 OR b='B';
+----+-------------+-------+------------+-------------+---------------+-------------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+---------------+-------------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | T | NULL | index_merge | idx_a,idx_b | idx_a,idx_b | 4,5 | NULL | 4 | 100.00 | Using union(idx_a,idx_b); Using where |
+----+-------------+-------+------------+-------------+---------------+-------------+---------+------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
type类型为index_merge,表示使用了索引合并。key列显示使用到的所有索引名称,该语句中同时使用了idx_a和idx_b两个索引完成查询。
2.Semi join (半连接)
Semi-join半连接主要场景:检查一个结果集(外表)的记录是否在另外一个结果集(字表)中存在匹配记录,半连接仅关注”子表是否存在匹配记录”,而并不考虑”子表存在多少条匹配记录”,半连接的返回结果集仅使用外表的数据集,查询语句
中IN或EXISTS语句常使用半连接来处理。
1、DuplicateWeedout:使用临时表对semi-join产生的结果集去重。
2、FirstMatch只选用内部表的第1条与外表匹配的记录。
3、LooseScan: 把inner-table数据基于索引进行分组,取每组第一条数据进行匹配。
4、Materializelookup: 将inner-table去重固化成临时表,遍历outer-table,然后在固化表上去寻找匹配。
5、MaterializeScan:将inner-table去重固化成临时表,遍历固化表,然后在outer-table上寻找匹配。
主要用于去重,当外表查找在内表满足条件的records时,返回外表的records,也就是说它只返回存在内表中的外表的记录.semi-join子查询必须EXSIT和IN语句组成
SELECT id, name
FROM t1
WHERE EXISTS
(SELECT 1 FROM t2 WHERE t1.id= t2.id);
备注:在整个过程中半连接生成内存临时表,又进行了读写等操作。
3.Anti Join反连接
反连接是两个数据集连接时,返回第一个数据集中的结果,但要求其在第二个结果集中没有匹配项(和半连接相反)。和半连接类似,反连接在第二个数据集中找到第一个匹配项时即会停止处理(结果为False)。和半连接不同的是,最终返回的是在第二个结果集中没有匹配项的数据。
从MySQL 8.0.17开始,下面情况下子查询被转换为antijoins:
- NOT IN (SELECT … FROM …)
- NOT EXISTS (SELECT … FROM …).
- IN (SELECT … FROM …) IS NOT TRUE
- EXISTS (SELECT … FROM …) IS NOT TRUE.
- IN (SELECT … FROM …) IS FALSE
- EXISTS (SELECT … FROM …) IS FALSE.
SELECT id, name
FROM t1
WHERE NOT EXISTS
(SELECT 1 FROM t2 WHERE t1.id= t2.id);
4.ICP优化(Index Condition Pushdown):下沉到引擎成执行
ICP允许在存储引擎层过滤索引中的记录,而不是在服务器层进行。就是说当满足引擎层处理条件时,所以操作都在引擎层处理,并且减少回表次数,减少IO操作。
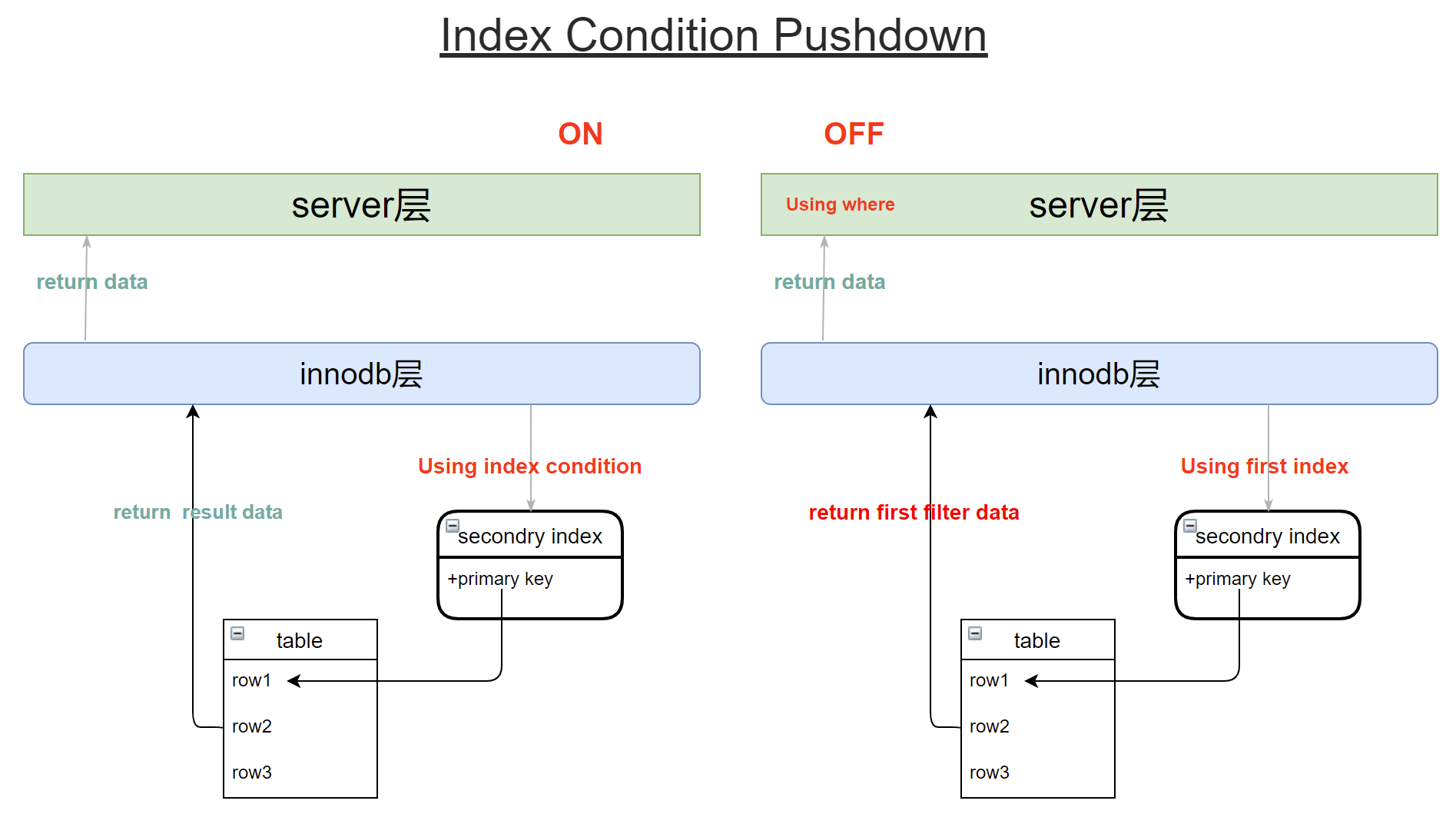
通过执行计划中的Extra提示信息可以区分Using index / Using index condition 进行区分。
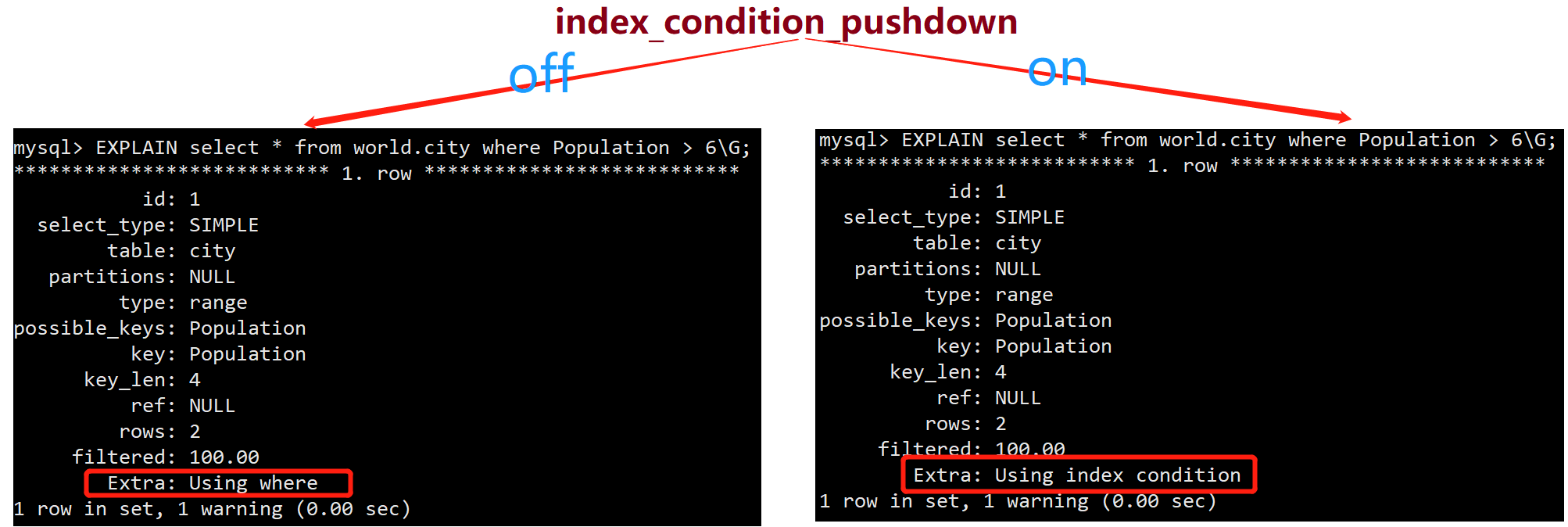
ICP使用条件:
- ICP用于range、ref、eq_ref和ref_or_null访问方法。
- ICP可以用于InnoDB和MyISAM表,包括分区表。
- 对于InnoDB表,ICP只用于二级索引
- 虚拟生成的列上创建二级索引时,不支持ICP。
- 引用存储函数的条件不能下推
- 引用子查询的条件不能下推。
5.MRR优化(Multi-Range Read):
MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
MRR是针对范围查询和索引扫描时,使用的优化手段。MRR 是对索引读取的优化,通过对缓冲区的索引记录排序,把随机读取转换为顺序读取,从而提高了索引查询的性能。从资源的使用情况上来看就是让CPU和内存多做点事,来换磁盘的顺序读。内存中的排序是通过read_rnd_buffer_size参数进行分配。当然内存read_rnd_buffer_size太小无法启用 MRR功能。除此之外,read_rnd_buffer_size参数也是MyISAM随机读缓冲的大小。
MRR功能是通过optimizer_switch优化器行为,进行控制:
mysql>SHOW VARIABLES LIKE '%read_rnd_buffer%';
mysql> set optimizer_switch =“mrr=on,mrr_cost_based=off”;
mysql> EXPLAIN SELECT /*+ MRR(city)*/ * from city where population BETWEEN 1 and 10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: range
possible_keys: idx_Population
key: idx_Population
key_len: 4
ref: NULL
rows: 26
filtered: 100.00
Extra: Using index condition; Using MRR
1 row in set, 1 warning (0.00 sec)
注意:MRR 只是针对优化回表查询的速度,当不需要回表访问的时,MRR就失去意义了(比如覆盖索引)
6.Skip_scan
跳跃扫描是一种在MySQL8.0版本中引入的优化特性,旨在在不满足组合索引最左前缀原则的情况下,优化器仍能有效利用组合索引,从而提高查询效率。Skip Scan的工作原理基于B+树索引的结构。在B+树中,数据是按照索引键的顺序存储的,Skip Scan会针对每个索引键的值启动多次范围扫描,每次扫描根据构建的键值直接在索引上定位,从而忽略那些不满足条件的记录。
mysql> ALTER TABLE t1 ADD INDEX idx_f1_f2(f1, f2);
mysql> EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 < 10\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: range
possible_keys: idx_f1_f2
key: idx_f1_f2
key_len: 8
ref: NULL
rows: 53
filtered: 100.00
Extra: Using where; Using index for skip scan
1 row in set, 1 warning (0.00 sec)
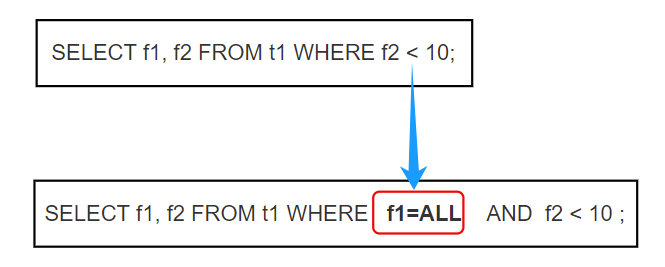
按照其他数据库里索引跳跃式扫描方式可以理解把前缀的所有条件都加入进去,之后按照原始条件条件进行过滤:
总结
了解MySQL优化器的查询原理并选择合适的优化方式,同时根据实际情况进行灵活调整,在有限的范围内,可以显著提升MySQL数据库的性能。
