




在离线数仓方面,Spark现在所占据的地位勿庸置疑。我们来看看如何在Hadoop3.x中集成Spark。
1. 下载与解压
从镜像站下载 下载地址,选择3.0.2版本。上传到服务器后解压到/app目录下
tar zxvf spark-3.0.2-bin-hadoop3.2.tgz -C /app
# 修改目录名
cd /app
# mv spark-3.0.2-bin-hadoop3.2 spark-3.0.2
ln -s spark-3.0.2-bin-hadoop3.2 spark
2. 修改配置
1. 修改spark-env.sh
cd /app/spark-3.0.2/conf
cp spark-env.sh.template spark-env.sh
# 编辑spark-env.sh,并添加相关环境变量
export JAVA_HOME=/app/jdk1.8.0_281
export SPARK_MASTER_HOST=hadoop101
export SPARK_MASTER_PORT=7077
# 避免和hadoop其他应用端口冲突(默认就是8081,可不添加该配置)
export SPARK_MASTER_WEBUI_PORT=8081
2. 修改slaves文件
cd /app/spark-3.0.2/conf
cp slaves.template slaves
# 在文件中添加spark的工作节点,以下3台机器作
hadoop101
hadoop102
hadoop103
3. 修改日志等级
cd /app/spark-3.0.2/conf
cp log4j.properties.template log4j.properties
# 修改log4j.properties配置文件中的log4j.rootCategory
将 log4j.rootCategory=INFO, console 修改为 log4j.rootCategory=WARN, console
4. 添加系统环境变量
在文件 /etc/profile.d/env.sh 中添加SPARK_HOME
# SPARK
export SPARK_HOME=/app/spark-3.0.2
# 同步到各机器
sudo /home/hadoop/bin/xsync /etc/profile.d/env.sh
# 在所有服务器应用新的环境变量
source /etc/profile
5. 修改spark-config.sh
在spark启动时可能会报错:failed to launch: nice -n 0 /soft/spark/bin/spark-class org.apache.spark.deploy.worker
修改 $SPARK_HOME/sbin/spark-config.sh,添加 JAVA_HOME 环境变量
export JAVA_HOME=/app/jdk1.8.0_281
参考文档:https://blog.csdn.net/qq_40707033/article/details/93210838
3. 集成hadoop
1. 复制配置文件
复制hadoop的配置文件到spark的conf目录下
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml $SPARK_HOME/conf/core-site.xml
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml $SPARK_HOME/conf/hdfs-site.xml
3.2. 配置spark on yarn
3.1. 修改/app/hadoop-3.2.1/etc/hadoop/yarn-site.xml,添加相关配置
<!-- 配置yarn资源 检查之前是否配置过-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>true</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vemem-pmem-ration</name>
<value>2</value>
<description>Ration between virtual memory to physical memory when setting memoery limits for containers</description>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
3.2. 修改/app/spark-3.0.2/conf/spark-env.sh,添加hadoop_conf_dir
# 配置spark on yarn
export HADOOP_CONF_DIR=/app/hadoop-3.2.1/etc/hadoop
3.3. 复制hadoop的yarn-site.xml到spark配置目录下
ln -s $HADOOP_HOME/etc/hadoop/yarn-site.xml $SPARK_HOME/conf/yarn-site.xml
3.4. 将jar上传到hdfs中
hadoop fs -mkdir /spark-jars
hadoop fs -put $SPARK_HOME/jars/* /spark-jars
3.5. 修改spark-default.conf,添加相关配置
# 填入的mycluster是hadoop集群名
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/spark-logs
spark.yarn.jars hdfs://mycluster/spark-jars/*
# 解决sparksql报超长问题
spark.sql.debug.maxToStringFields 100
# 监控spark job的端口配置,默认4040,可不配
spark.ui.port 4040
4.配置历史服务器
cd /app/spark-3.0.2/conf
cp spark-defaults.conf.template spark-defaults.conf
# 修改该文件中的下面两个配置
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/spark-logs
# 需要确保hdfs中的该目录存在,如果不存在,可手工创建,执行以下命令:
hadoop fs -mkdir /spark-logs
5. 配置Spark HA
修改 $SPARK_HOME/conf/spark-env.sh,添加zookeeper配置
# 将master相关配置注释掉
#export SPARK_MASTER_HOST=hadoop101
#export SPARK_MASTER_PORT=7077
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop101:2181,hadoop102:2181,hadoop103:2181 -Dspark.deploy.zookeeper.dir=/spark"
# 每个work的线程数
export SPARK_WORKER_CORES=2
# 每个work可用的内存数
export SPARK_WORKER_MEMORY=2G
6. 启动spark集群
# 在打算作为master的节点执行
$SPARK_HOME/sbin/start-all.sh
# 在备用节点上面执行
$SPARK_HOME/sbin/start-master.sh
# 查看zookeeper目录,验证高可用,依次执行
$ZOOKEEPER_HOME/bin/zkCli.sh -server hadoop101
ls /
ls /spark
ls /spark/master_status
ls /spark/leader_election

7. 验证spark功能
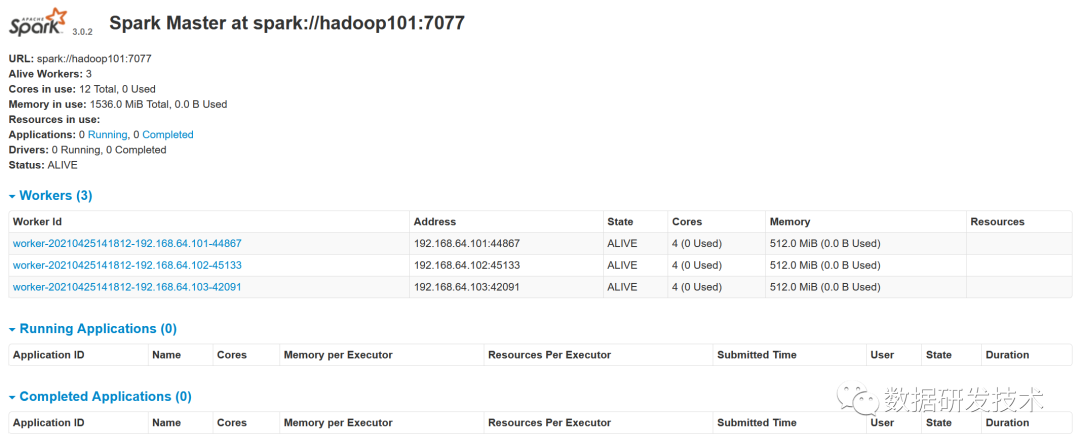
访问web页面,查看集群情况 http://192.168.100.124:8081/
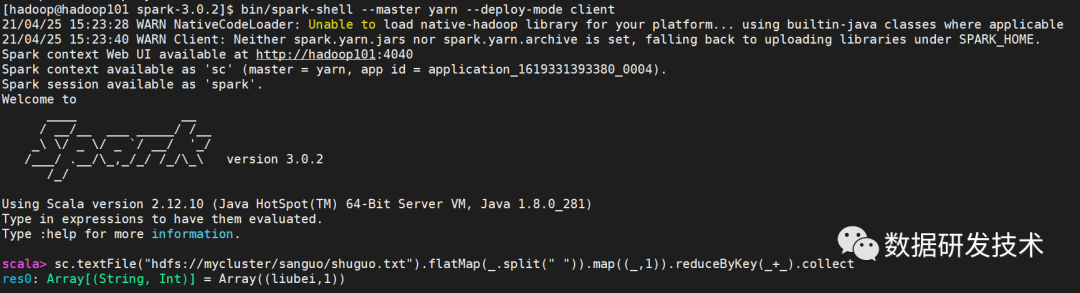
使用spark进行字数统计
$SPARK_HOME/bin/spark-shell
sc.textFile("hdfs://mycluster/sanguo/shuguo.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
8. 配置Spark on Hive
复制/app/apache-hive-3.1.2/conf/hive-site.xml到spark的conf下
ln -s /app/apache-hive-3.1.2/conf/hive-site.xml hive-site.xml
ln -s $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf/hive-site.xml
复制metastore的jdbc驱动包到spark/jars下面
cp /app/apache-hive-3.1.2/lib/mysql-connector-java-8.0.22.jar /app/spark-3.0.2/jars/
cp $HIVE_HOME/lib/mysql-connector-java-8.0.22.jar $SPARK_HOME/jars
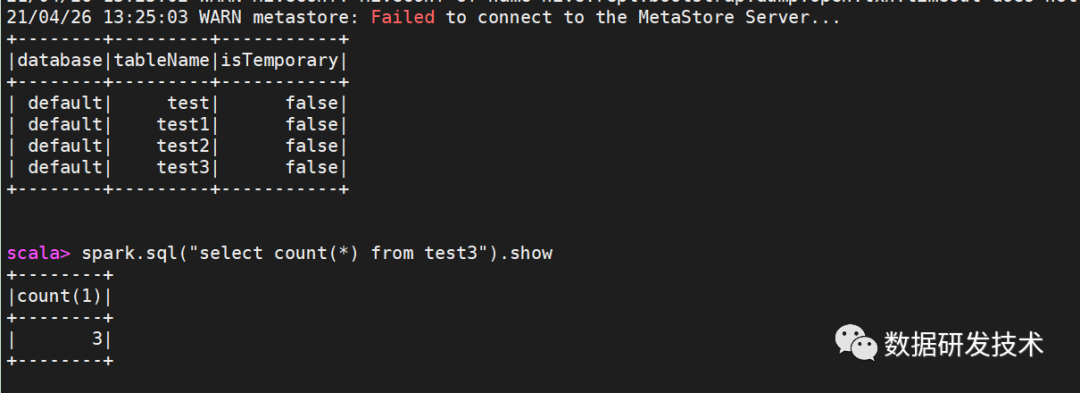
功能验证
$SPARK_HOME/bin/spark-shell
# 在交互命令行执行
scala> spark.sql("select count(*) from test3").show
欢迎关注微信公众号,回复hadoop,获取从零开始Hadoop系列完整文档
文章转载自数据研发技术,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
