




在使用PySpark开发时,需要在本地安装Hadoop和Spark环境,并进行一定的配置才能正常使用。
搭建环境
本次使用的环境版本为hadoop3.2.1和spark3.0.2
1. 安装JDK
推荐安装Jdk8(过程略)
2. 安装hadoop
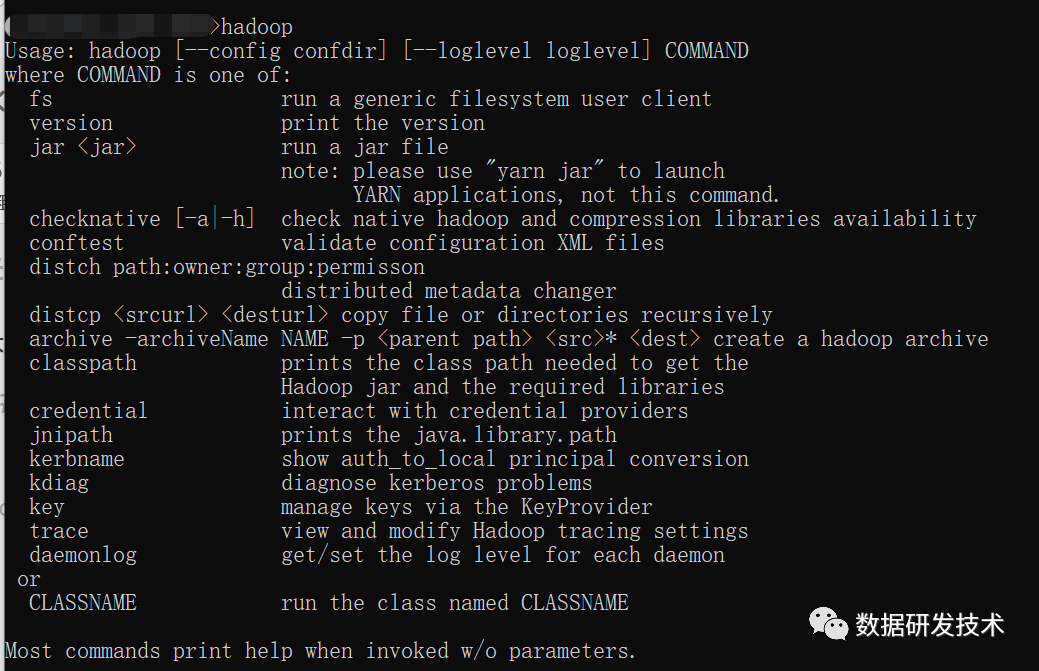
下载hadoop,推荐使用国内镜像 解压到本地,路径不能包含空格! 配置环境变量 HADOOP_HOME
,并在PATH
中增加%HADOOP_HOME%\bin在cmd中测试安装是否成功
3. 安装spark
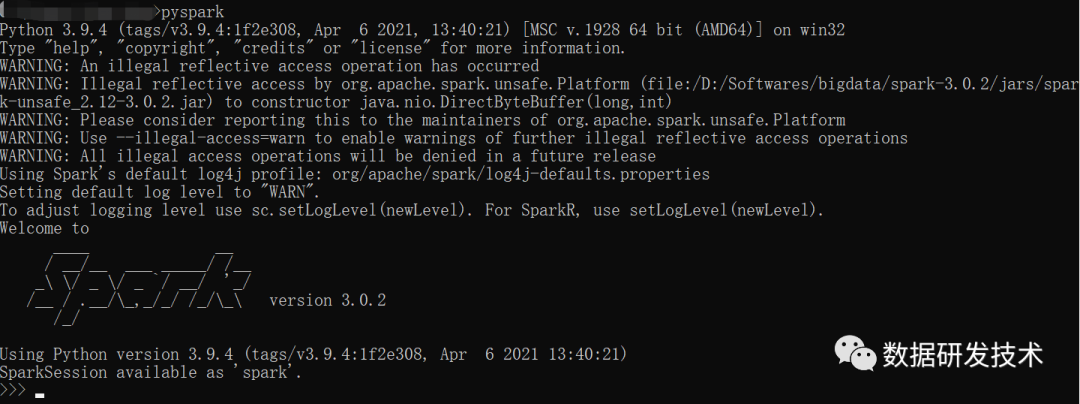
下载Spark:spark-3.0.2-bin-hadoop3.2.tgz,推荐使用国内镜像 解压到指定路径,路径不能包含空格! 配置环境变量,配置 SPARK_HOME
,并且在PATH
中添加%SPARK_HOME\bin%在命令行测试是否安装成功
4. 安装python
推荐安装python3,这里使用python3.9
5. 下载winutils
下载地址:https://codechina.csdn.net/mirrors/cdarlint/winutils 选择需要的版本,将相关文件复制到本地的%HADOOP_HOME%\bin下面
6. 安装pyspark、findspark
使用pip安装pyspark和findspark
pip install pyspark findspark
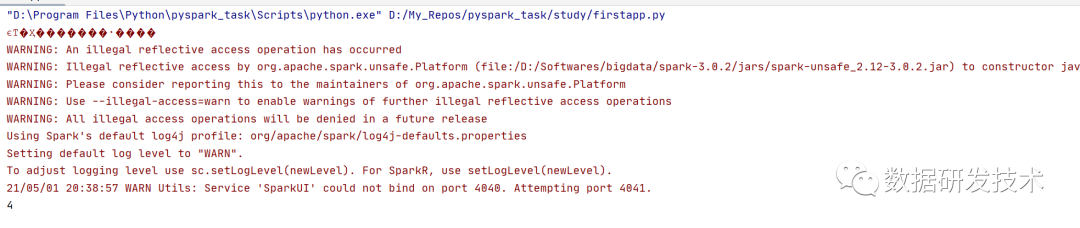
7. 测试第一个pyspark程序
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext("local","first app")
data = sc.textFile("../datas/test.txt")
count = data.count()
print(count)
8. 配置pyspark访问hive
将被访问的hadoop集群中的相关配置文件复制到本地hadoop集群中,具体文件是$HADOOP_HOME/etc/hadoop/下的 yarn-site.xml、core-site.xml、hdfs-site.xml、hadoop-env.sh、mapred-site.xml、workers将$HADOOP_HOME/etc/hadoop/下的相关文件复制到本地%SPARK_HOME%\conf下,具体文件有 yarn-site.xml、core-site.xml和hdfs-site.xml
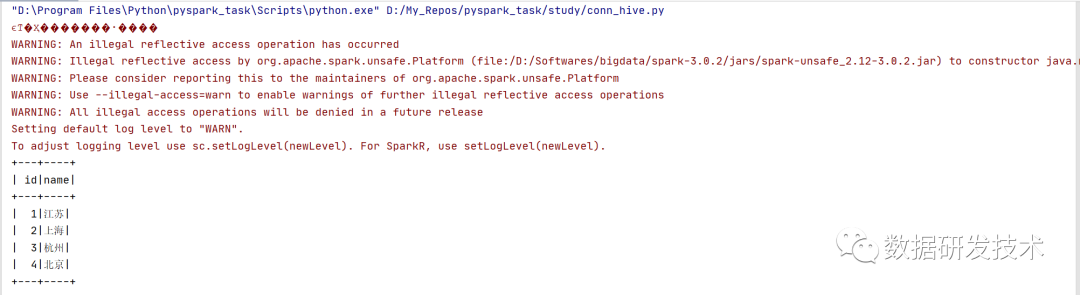
9. 测试windows下的pyspark访问hive
测试程序
import findspark
findspark.init()
from pyspark.sql import SparkSession
import warnings
warnings.filterwarnings('ignore')
spark = SparkSession.builder.master("local[*]")\
.appName("test").enableHiveSupport().getOrCreate()
read_df=spark.sql("select * from test1")
read_df.show()
测试结果
关注公众号数据研发技术回复:hadoop 获取完整文档
文章转载自数据研发技术,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
