




PostgreSQL审计日志优化
背景
PG打日志的方式分析
PG是多进程模型, 每个postgres进程不断接收处理请求, 在请求处理完成之后拼出待打印日志, 输入到管道(pipe)里, 在管道(pipe)的另一端由pg的syslogger进程统一消费并落盘.
此处的核心是使用管道(pipe). 具体流程如下:
初始化时由postmaster进程创建一个pipe, 将pipe的读取端交给fork出来的syslogger进程, pipe的写入端则继续由postmaster持有, 进而由之后fork出的所有backend进程继承
pipe的写入端重定向stdout和stderr, 这样所有由backend进程输出到stdout或者stderr的内容均可以被syslogger获取.
为了能利用同一个pipe写入不同类型的日志, pg定义了写入pipe时数据的schema. 同时linux pipe提供写入原子性的支持, 但条件是一次性写入数据大小必须小于PIPE_BUF(4KB), 所以数据写入pipe之前会适当做切分, 以保证单个数据块的大小被限制在PIPE_BUF(4KB)以下.
优化思路
问题
基于表象和以上的流程分析, 可以确定两个问题:
pipe的原子写入是内核使用锁保证的, 因此在大量backend并发的前提下, 锁竞争非常激烈
只有一个pg syslogger进程作为消费者, 在有大量日志输出的情况下, 消费能力十分有限, 会影响整体性能.
思路
根据现有的问题, 有两个显而易见的优化思路
将一个pipe拆分成多个pipe或者其它进程间通信的通道, 以降低竞争.
后端通过一组进程或者线程并行从多个pipe中同时往下刷日志, 提高消费能力, 如果担心对磁盘IO压力太大, 可以做适当控制
优化方案
调研
思考
pipe是不是一个足够好的方式? 在这种场景下有没有比pipe更好的进程间通信方式? 对比一下几种进程间通信的方式:
pipe: 优势是由操作系统来维护buffer, 但是pipe在内核有锁, 而且原子写入粒度默认是4K
socketpair: 操作系统维护buffer, 没有锁, 需要应用层去实现, 单次写入数据大小不限.
共享内存: 需要自行管理buffer, 控制并发, 实现起来有成本.
测试
此处撸了一个demo程序对比一下各种方式在多进程大并发前提下的性能和吞吐:
对比维度:
只对比pipe和socketpair两种方式(这两种实现方式十分接近); 另外因为一些偶然的原因, 发现虽然pipe自身是能保证原子性的, 但在并发场景下给pipe加锁之后反而得到了不同的结果, 值得关注;
分别使用1个进程, 10个进程和50个进程并发写, 只有一个pipe或者socketpair消费
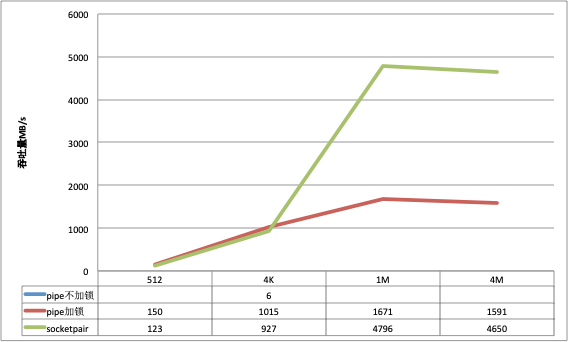
数据块大小使用512, 4K, 1M, 4M分别做测试
对比指标: 吞吐量
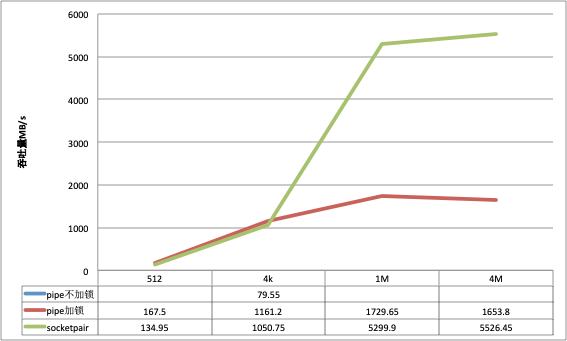
以下是测试结果:
1个进程写
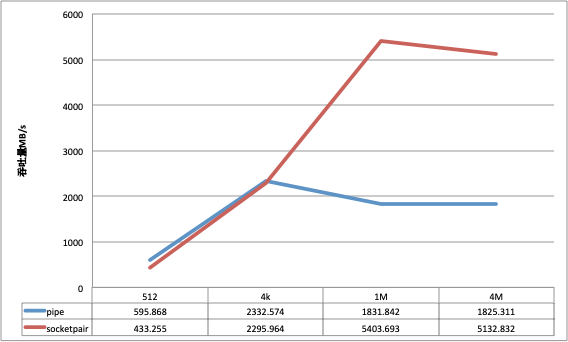
在数据包比较小的场景下, pipe的吞吐会稍好于socketpair, 但是随着数据包的变大, pipe的吞吐量并没有获得相应的提升, socketpair的优势很明显.
10个进程并发写
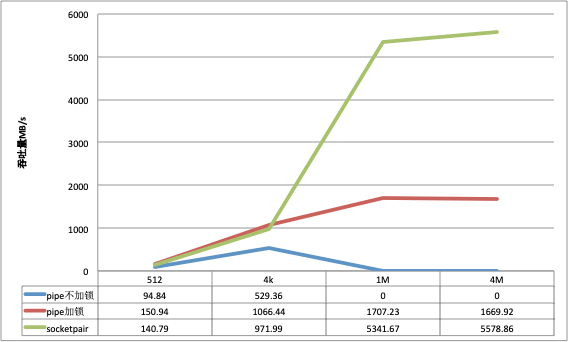
并发写的情况对于不加锁的pipe, 只测试512和4K的数据包大小(超过4K pipe不能保证原子性).
socketpair同单进程一样, 在小数据包的场景下吞吐量略微逊色于pipe, 但是大数据包的场景下远远优于pipe;
比较奇异的是pipe虽然保证原子性, 但对pipe进行额外加锁之后吞吐显然明显高了很多, 观察CPU的使用率和进程状态也可以感受到pipe不加锁竞争相对激烈:
pipe加锁:
同时系统负载也升高
pipe不加锁, 显然CPU利用率更高(全部耗在sys上了), 且出现大量D状态的进程, 和此前线上观察到的情况一致, 这一点值得深究
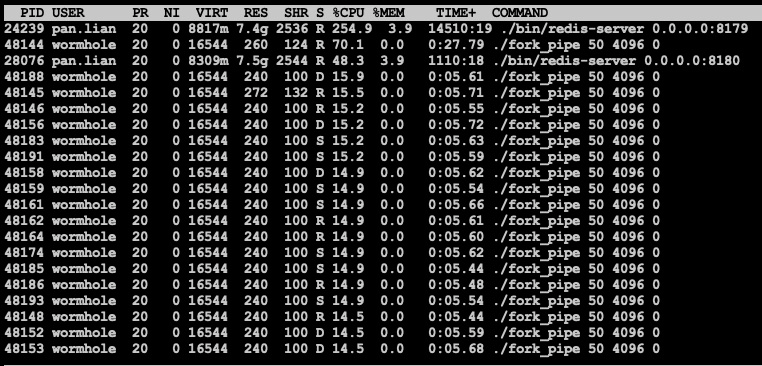
系统负载情况

对pipe加了锁之后吞吐和socketpair基本无异, CPU使用pipe略高, 当然吞吐也略大:
pipe加锁
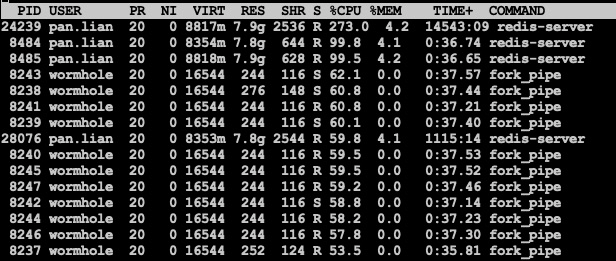
socketpair
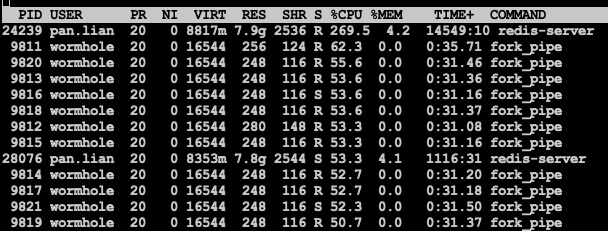
50个进程并发写
pipe相对于socketpair在小数据包的情况下吞吐还是好一些, 不加锁的pipe竞争更加激烈, 吞吐量明显减小, 其余整体情况与10并发无太大区别.
1000进程并发写
继续调大并发, pipe和socketpair与小并发情况下无明显差异, 真实场景下需进一步压测
pipe的锁问题探究
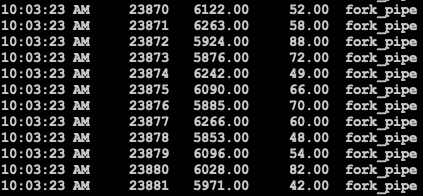
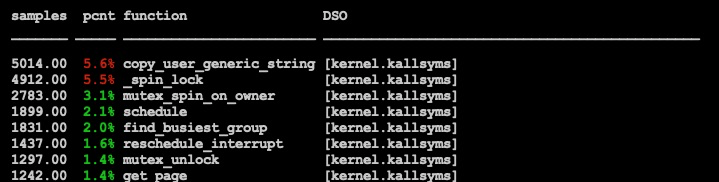
对pipe的问题问题进行进一步探究, perf后可见pipe不加锁时内核的spin lock是性能热点

此时上下文切换的情况:
相反对pipe加锁时都在拷贝string的操作上了
上下文切换明显少很多
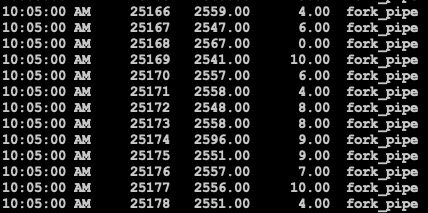
所以原因是pipe内部保证原子性的操作使用了spin lock, 轮询spinlock的进程太多, 整体上下文切换过多, 整体效率反而偏低.
结论
并发写场景下, 依赖pipe自身的原子性会造成激烈竞争, 吞吐量下降, 外层给pipe加锁能缓解很多;
并发写场景下, 使用pipe可能会出现D状态进程
对比pipe和socketpair, 在小数据包场景下pipe吞吐量要略高, 同时cpu消耗也高点, 但是随着数据包的增大, pipe吞吐量并没有提升, 反而socketpair提升明显.
整体方案
简单方案: 给pipe加个mutex就好很多了, 吞吐量提升1.5~2倍, 能解决很多问题.
正规方案:
首先区分出系统日志和审计日志, 其次要保持对原有方案的兼容, 所有系统日志还是按照原有方式输出, 优化仅针对审计日志进行.
进程间通信的方式使用socketpair, 并且设置一组socketpair, 每个backend根据hash写入对应socketpair. syslogger进程也设置成一组进程, 不同syslogger进程有自己的唯一标识, 单独输出到自己的日志文件, logagent支持同时tail多个日志文件并上传.
为了兼容性考虑, 在配置多个syslogger进程的情况下, syslogger进程0仍然使用原有的方式采集并输出系统日志, 而其余syslogger进程当前仅输出审计日志.
为了进一步提高吞吐量, 在写入端可以做下缓存, 积攒足够大小或者等待足够时间再行写入, 类似group commit.
优化过程和结果
基线
参数:
-i -s 1000
-M prepared -n -P 1 -c 100 -j 100 -T 600
不写审计日志
性能
稳态下在100000上下
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: prepared
number of clients: 100
number of threads: 100
duration: 600 s
number of transactions actually processed: 58821688
latency average = 1.020 ms
latency stddev = 0.812 ms
tps = 98032.865502 (including connections establishing)
tps = 98038.759916 (excluding connections establishing)
statement latencies in milliseconds:
0.002 \set aid random(1, 100000 * :scale)
0.001 \set bid random(1, 1 * :scale)
0.001 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.056 BEGIN;
0.203 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.093 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
0.123 UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
0.135 UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
0.099 INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
0.309 END;
写审计日志:
参数
log_line_prefix='\1\n\t%p\t%r\t%u\t%d\t%t\t%e\t%T\t%S\t%U\t%E\t\t'
log_statement='all'
log_min_duration_statement=1000
性能
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: prepared
number of clients: 100
number of threads: 100
duration: 600 s
number of transactions actually processed: 11913214
latency average = 5.036 ms
latency stddev = 4.757 ms
tps = 19853.554579 (including connections establishing)
tps = 19854.891443 (excluding connections establishing)
statement latencies in milliseconds:
0.002 \set aid random(1, 100000 * :scale)
0.001 \set bid random(1, 1 * :scale)
0.001 \set tid random(1, 10 * :scale)
0.000 \set delta random(-5000, 5000)
0.564 BEGIN;
0.883 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.602 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
0.782 UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
0.788 UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
0.691 INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
0.736 END;
写日志流程优化
根据预设方案, 此处进行两个简单的优化, 做下原型验证, 一是开启多logger并行下刷, 一是批量写pipe.
(注: 测试数据为较早前进行, 仅为50客户端50线程并发写)
开启并行下刷之后
分多个队列下刷(实际是4个)
参数:
polar_enable_multi_syslogger=true
polar_syslogger_num=5 (实际起作用的是4个)
性能:
scaling factor: 500
query mode: prepared
number of clients: 50
number of threads: 50
duration: 600 s
number of transactions actually processed: 47037825
latency average = 0.638 ms
latency stddev = 1.799 ms
tps = 78395.251816 (including connections establishing)
tps = 78397.758514 (excluding connections establishing)
稳态在80000上下
批量写pipe
当前写pipe都是一条日志写一次, pipe还有锁争抢, 现修改如下:
将pipe改为socket pair, 批量写, 大小为64K, 观察再大之后写入时间成倍上升(可能的原因是socket的buffer满了, 在此未对socket的buffer做设置)
scaling factor: 500
query mode: prepared
number of clients: 50
number of threads: 50
duration: 600 s
number of transactions actually processed: 49116913
latency average = 0.611 ms
latency stddev = 2.616 ms
tps = 81860.305750 (including connections establishing)
tps = 81863.022561 (excluding connections establishing)
稳态下在83500上下
可见性能还不够理想, 我们的目标是将整体损失降到10%以内, 仔细观察思考了一下, 有两点值得深入做下优化, 一是syslogger CPU占用率比较高, 4个syslogger进程每个都在90%左右, 二是看代码发现PG拼日志字符串的框架比较重, 存在多次内存拷贝.
syslogger进程的优化
对syslogger的event loop优化
logger每次event loop都要重新create wait event, wait, 完成后再free, 效率比较低, 在栈上很容易抓到create和free的调用
优化方式很简单, 直接将event事件的创建和删除都放到event loop外部, 各进程CPU降到60左右

fwrite参数优化
pstack logger进程栈信息基本都在write上, 本身很正常, 但是strace可以看到存在大量的write系统调用, 考虑是否可以通过buffer进行优化.
pg的logger进程使用fwrite写文件, 而fwrite是自带buffer的. 在pg中buffer实际设置参数为IOLBF, 含义是按'\n'下刷, 可以认为针对写日志这种场景, 是没有起到任何的buffer作用的. 此处可以改为IOFBF, 即全缓存, 缓存满了才会下刷. 修改再启动之后通过strace可以看到write系统调用大量减少, 整体CPU进一步下降:

elog准备日志的流程优化
logger的进程实际很空闲, 看似瓶颈并不在写上, 把写pipe的步骤关掉, 结果好1~2%左右, 没有明显提升, 相比不写日志的基线的差距仍有10%+, 可以认为瓶颈在拼日志字符串上.
仔细看代码, PG的elog框架实现效率比较低, 不仅路径长, 中间存在多次buffer copy, 仅这一小段代码就存在三次内存申请释放及拷贝的情况
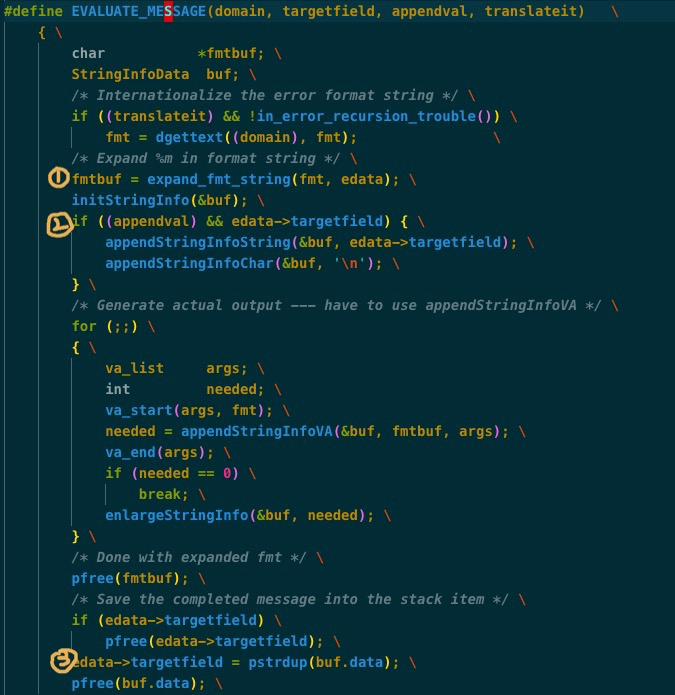
这里考虑分配一个buffer, 在写日志的过程中可以摒弃内存分配和释放, 把所有要写的内容直接直接拷贝到buffer上, 这样所有数据只拷贝一次(当然write pipe的时候还要拷贝第二次), 同时buffer也可以不断积累, 进行批量写. 优化之后的结果如下:
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1000
query mode: prepared
number of clients: 100
number of threads: 100
duration: 600 s
number of transactions actually processed: 54810504
latency average = 1.095 ms
latency stddev = 0.747 ms
tps = 91347.219563 (including connections establishing)
tps = 91353.436072 (excluding connections establishing)
statement latencies in milliseconds:
0.002 \set aid random(1, 100000 * :scale)
0.001 \set bid random(1, 1 * :scale)
0.001 \set tid random(1, 10 * :scale)
0.001 \set delta random(-5000, 5000)
0.066 BEGIN;
0.206 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.108 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
0.135 UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
0.148 UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
0.111 INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
0.318 END;
性能瓶颈
重新诊断一下性能瓶颈
syslogger
syslogger的CPU占用率仅为

大部分时间处于wait状态, 明显syslogger不是瓶颈
backend
查看扁鹊, 可以看到write_audit_log整个函数中append string消耗还是比较大的, 可见最终瓶颈还是在backend上, 拼字符串操作太重:
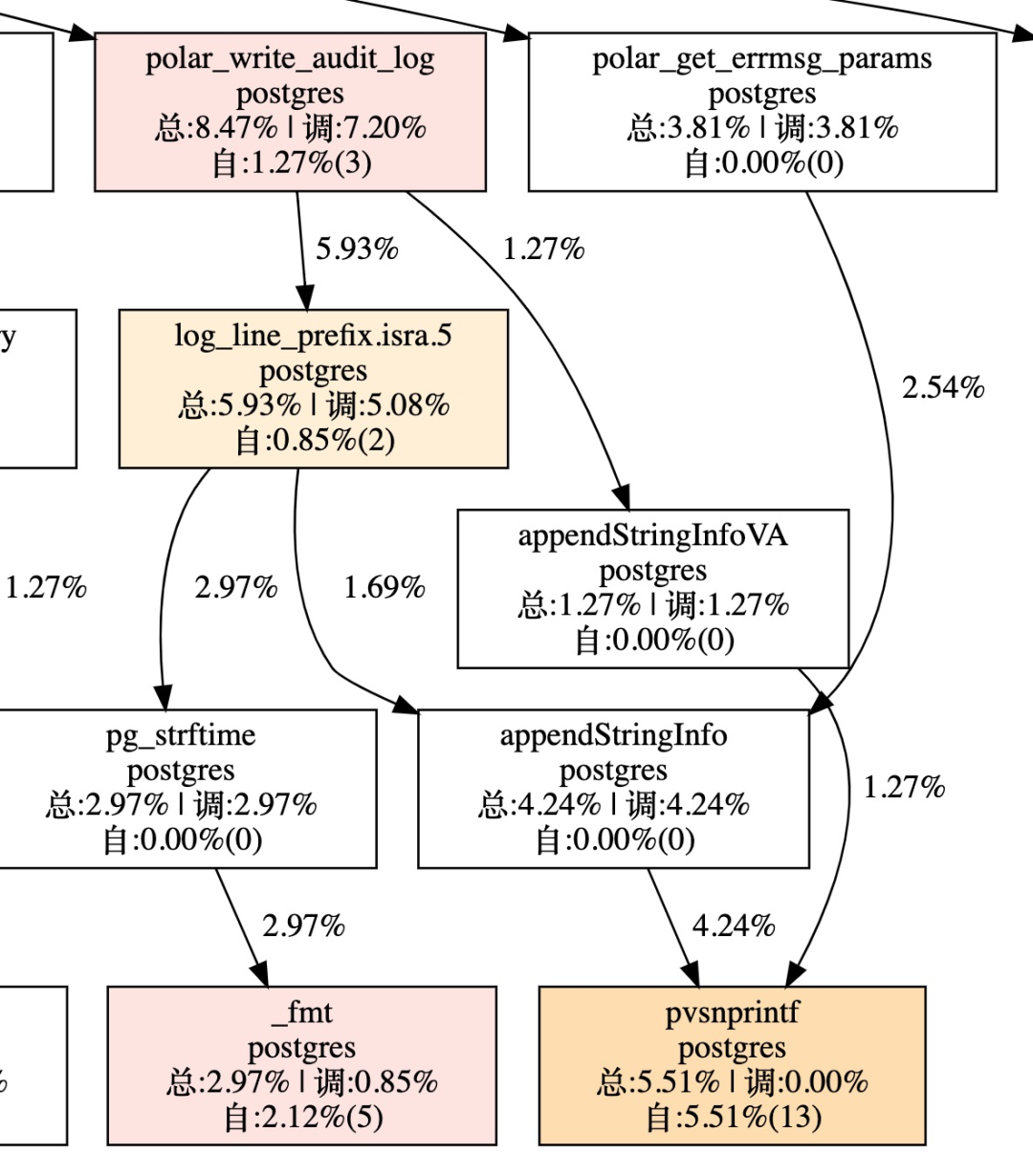
结论
对比最后一次优化的结果及基线, 在开启审计日志的情况下性能提升4.61倍, 在未开启审计日志的情况下性能损失仅在7%, 实际多次测试中最差在10%左右. 整体性能瓶颈在backend拼日志字符串上, 暂无进一步优化空间. 所以结论是线上可用, 但建议开关暴露给用户, 使其可自行开启关闭审计日志.
