




DeepSeek vs ChatGPT
尽管官方文档和案例场景日益完善,但当遇到业务逻辑复杂的问题时,开发者仍需在碎片化的参考材料中反复试错,耗费大量时间。
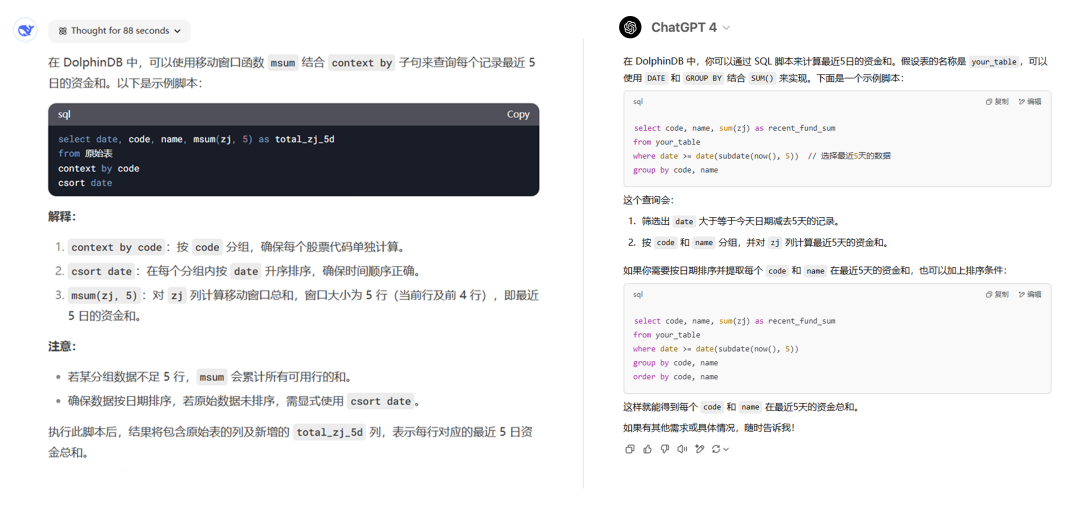
Q1:请教一下,我的原始表包含 date, code, name, zj(资金) 四个列,我想要查询记录中最近5日资金和,在 DolphinDB 中使用 SQL 怎么写脚本?
💻DeepSeek:
DeepSeek 给出的答案可行。
GPT 第一次生成的回答有误,用户希望得到每一条记录最近五天的资金总和,而 group by 每个分组只返回一条结果。
反馈给 GPT 后,它修改了回答:

此时得到的代码可以满足需求。
Q2:请问 DolphinDB 中有什么函数可以解决以下问题:数据表有33列,产品代码,32个行业的占比数据,如何筛选32个行业每个行业占比均小于50%的行?

💻DeepSeek:
DeepSeek 给出三种解法:
💻ChatGPT:
GPT 给出了两种回答:
方法一正确,但可行性较差,SQL 写起来非常复杂;方法二的元编程思路正确,但示例代码不正确。
Q3:请问在 DolphinDB 中如何实现类似 python list 对象的切片双冒号的功能?譬如有一个交易日历向量 a,如何实现每20个交易日取一个日期组成新的时间序列,即使用类似 python 的 a[::20] ?
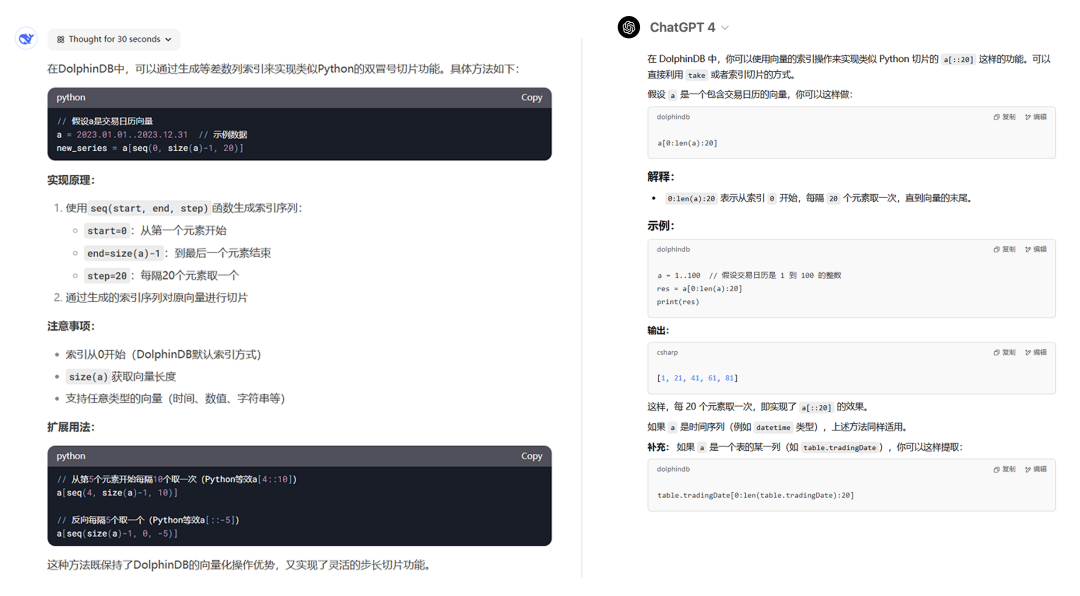
💻DeepSeek:
由于 seq 函数不支持三个参数,DeepSeek 的回答有误。
💻ChatGPT:
GPT 的回答出现了两个错误:
首先,sequence[start:end:step] 是 Python 的语法,而不是 DolphinDB 的语法;其次,len 函数是 Python 的函数,DolphinDB 中没有此函数。
输入上述反馈进行纠正。
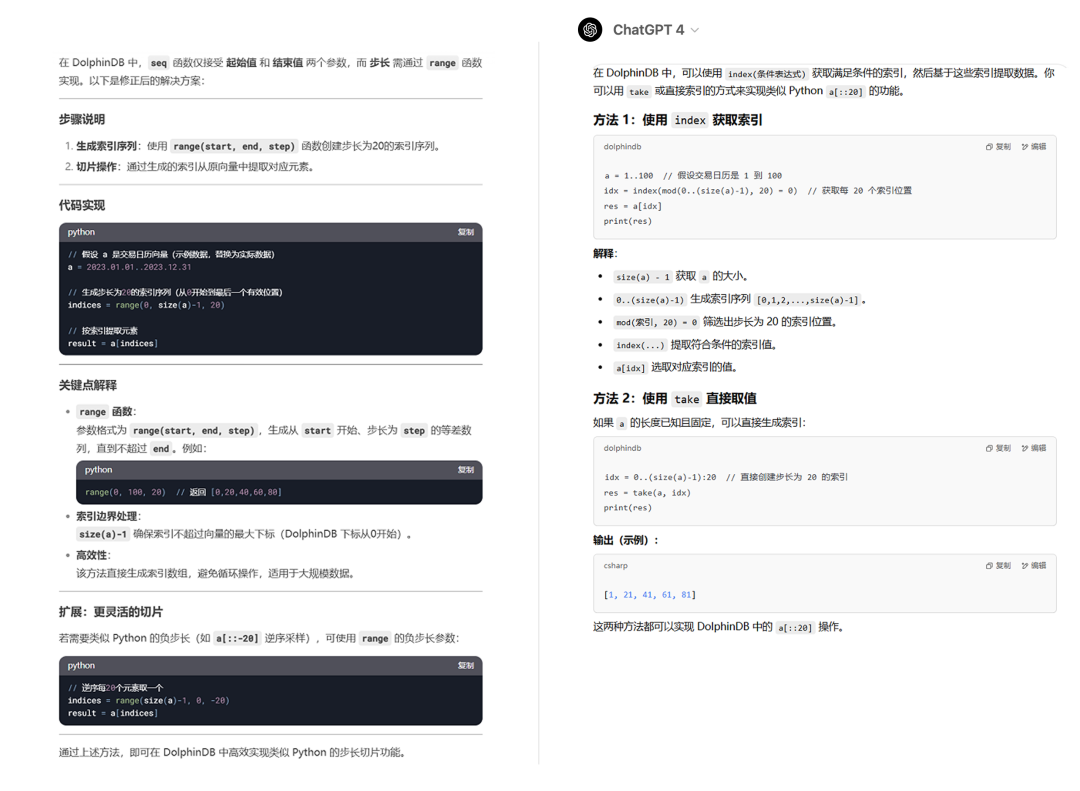
这次的回答仍然存在不足,DolphinDB 并没有 range 函数。
💻ChatGPT:
GPT 给出的两种方法也仍然存在瑕疵:
Q4:在 python 中可以用下列代码求出最接近的值,DolphinDB 中如何编写脚本?
vector_list = [1, 3, 5, 7, 9] # 假设这是给定的向量list
target_value = 6
closest_value = min(vector_list, key=lambda x: abs(x - target_value))
print("最接近的数值是:", closest_value)

💻DeepSeek:
DeepSeek 一次性给出了可行的方案。
💻ChatGPT:

从对比测试结果来看,两大模型在解答 DolphinDB 技术问题时都存在“幻觉输出”的共性问题,具体表现为有时推荐的函数/语法无效。
综合来看,DeepSeek-R1在技术适配性上表现更优,其大概率能提供符合 DolphinDB 语法规范的可行方案。GPT-4 虽然展现了流畅的自然语言表达能力,但在对 DolphinDB 的了解,以及技术细节的处理上存在短板,需要多次修正才能接近正确答案。
实践证明,合理运用 AI 工具能够优化 DolphinDB 的学习路径,缩短问题定位耗时,但也必须把握“AI 辅助+人工验证”的原则。对于 AI 给出的回答,需要理性看待,可以将其作为思路启发工具,而非代码权威来源,还需要结合 DolphinDB 官方文档手册,核查其给出的函数命名、语法结构等是否正确,同时验证代码执行逻辑是否贴合场景需求。
剧透一下,我们的研发小伙伴目前也正基于 DeepSeek 开发辅助 DolphinDB 编程的大模型,欢迎大家在评论区留言,也可以扫描下方二维码加入技术群,一起聊聊需求,你的每一条建议都有可能成为后续版本的新功能~

最后还有一个彩蛋 
我们特别邀请了 DeepSeek 这位“硅基架构师”用代码思维解读一下 DolphinDB,没想到 TA 的回答比想象中还要硬核…
Q:如果让 Python 和 DolphinDB 共同出演《哪吒之魔童闹海》,它们最适合扮演电影中的哪位角色?



