




作者 | YMatrix 研发经理 王昊
架构设计的测试
请问下面的函数应该如何做单元测试?
func 业务处理1() {
// 连接数据库,查询表
xxxxxxxx
if 出错 {
// 删除本地文件,退出
}
// ssh 连接远程地址,执行命令
// 发起 rpc 调用,调用其他服务的 api
}
解决方案:
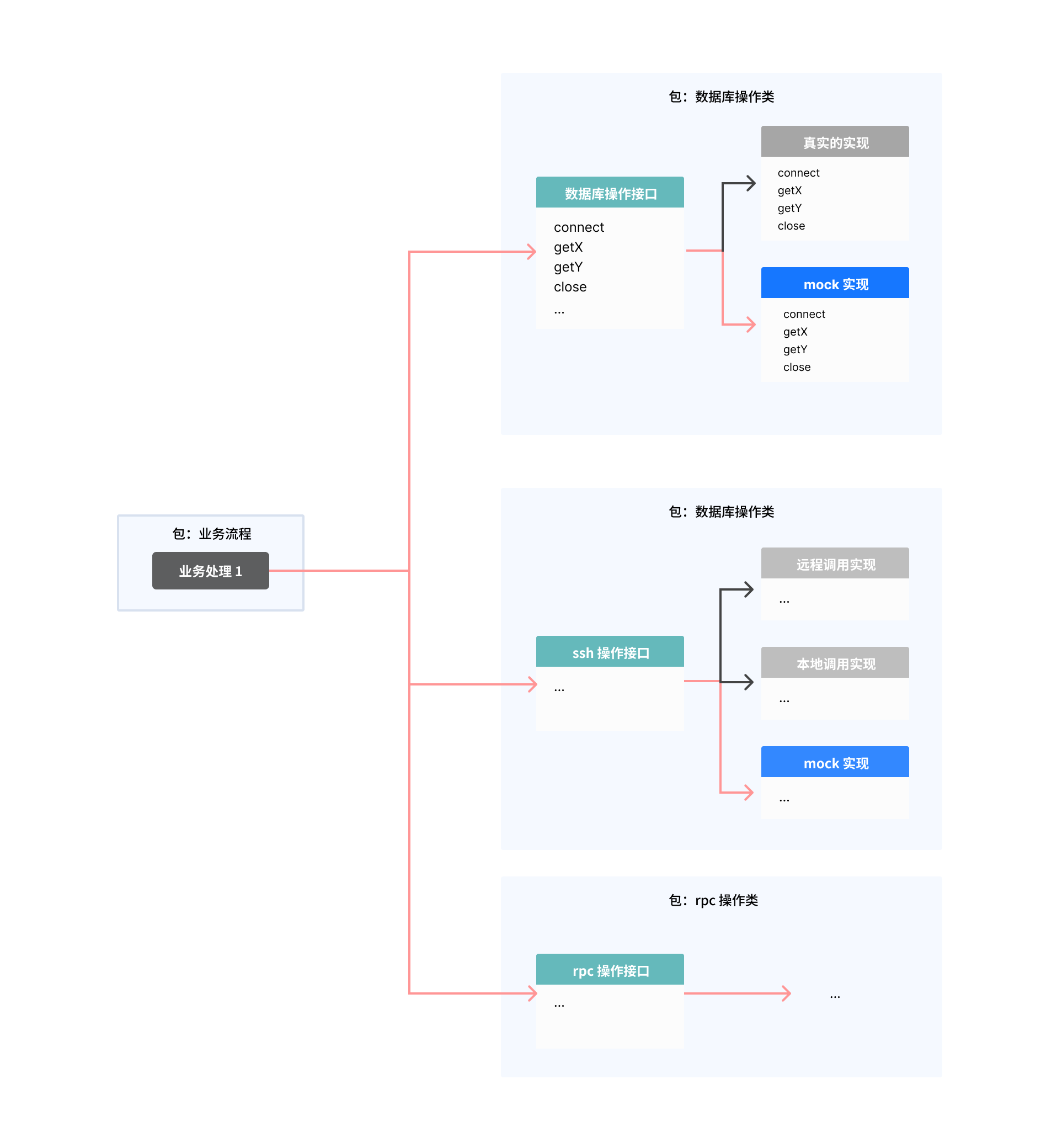
㊙️ 以上几点,理解和实施都不难,想要做好秘方就是“别犯懒”
异常注入:gp_inject_fault
在特定的位置注入异常 严格控制程序运行时序
探索性测试:无尽的沙盒游戏
对于我所工作的数据库行业来说,SQL语法 X 数据类型 X 具体的数据 X 执行顺序 ...... 组成了一个几乎无限大的空间,想要靠固定的测试 case 覆盖全部场景是无法做到的:

探索性测试:

探索性测试的思路:
a. 随机的数据类型
b. 随机的列数
c. 随机的索引
d. 随机的数据内容
e. 随机的数据分布
f. 随机的语法结构
g. 随机的名字(数据库名、schema名、表名、字段名,各种合法字符)
h. 随机的 segment 个数、布局
i. 随机的端口、磁盘路径
j. 随机的网络延迟,硬件故障
k. ...
e. ...
3. 评估探索性测试的覆盖效果,补齐短板。
4. 利用随机 case,进行长期疲劳测试,挖掘更多潜在稳定性问题。
利用弹性、廉价且相对稳定可靠的 IT 资源
我们在这里分享一个,使用 AWS 进行标准压测操作的案例。教你如何用一根雪糕的价钱,随时随地调用一定规模的独占 IT 资源。
1. AWS云主机(重点)
有国内版本,访问延迟不是问题 网络、性能表现非常稳定 因为硬件式样固定且独占,有利于重复验证,对性能测试更友好 Spot instance 巨能省
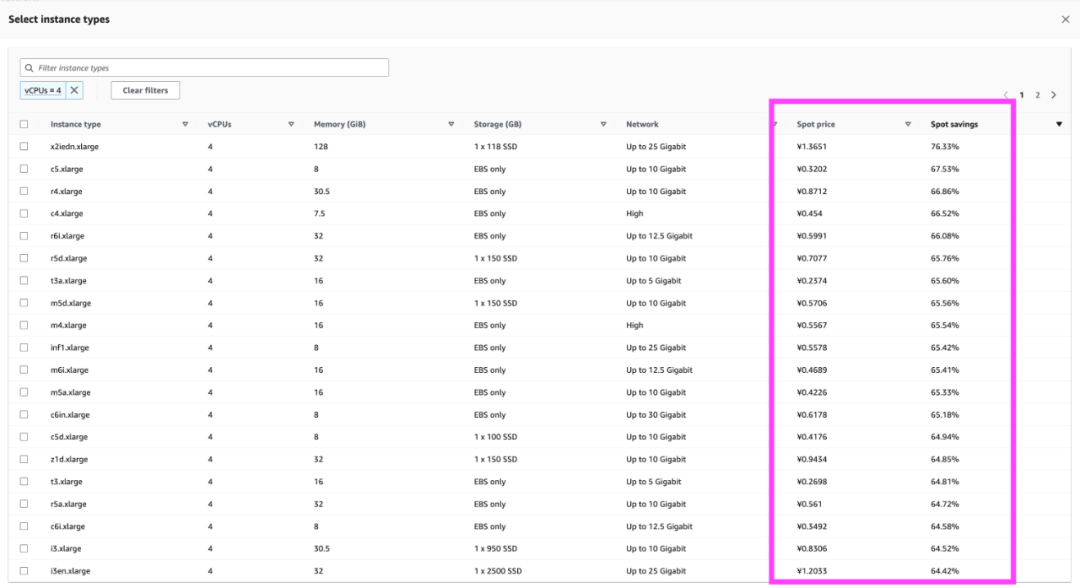
可能被 AWS 自动回收(极少发生),不适用于长期固定使用。
2. 使用 AWS 云主机需要了解的知识
机器系列
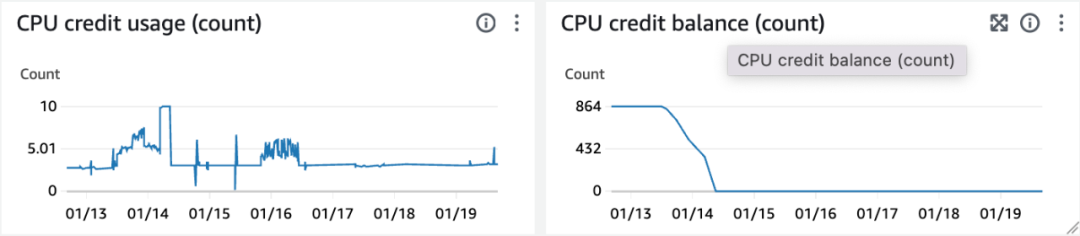
t 系列:可以选择非常小的实例,省钱,但是 cpu 有 credit 限制,常用作功能测试,不适合压测。
r系列(内存优化型):相同 CPU 配置下,内存更多 (r5.xlarge = 4c32g)
c系列(计算优化型):相同 CPU 下,内存更少(c5.xlarge = 4c8g)
m系列(通用型):CPU、内存平衡(m5.xlarge = 4c16g) https://docs.aws.amazon.com/zh_cn/ec2/latest/instancetypes/instance-type-names.html
例如,同样是 m 系列主机,m5 和 m6 都有 4c16g 选择,应该怎么选呢? 仔细参阅:
https://aws.amazon.com/ec2/instance-types/ m5 vs m6a,普适原则:买新不买旧


网络/磁盘带宽
仔细参阅:
https://aws.amazon.com/ec2/instance-types/
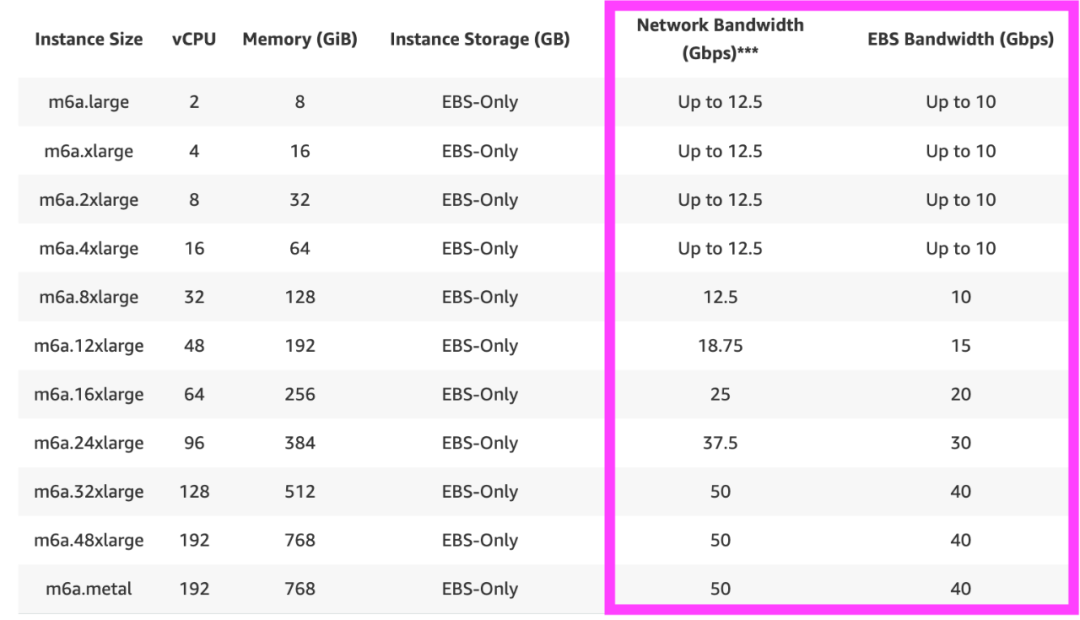
在压测时,需要根据测试的场合、预期的压力规划使用的机器类型。
磁盘选择
仔细参阅:
https://aws.amazon.com/ebs/volume-types/ 重要原则:挂载多块性能一般的磁盘,优于挂载一块超级昂贵的大磁盘。 多块盘的 through put 总和 = 主机的 EBS Bandwidth 定价:
https://www.amazonaws.cn/en/ebs/pricing/?nc1=h_ls 最佳实践:多块丐版 gp3(125MB/s+3000IOPS)能够满足大多数场合。 不要再用上一代产品 gp2 了。 ec2 机器关机了,EBS 磁盘依然会交钱。
树立认知:测试在 YMatrix 是研发的必修课,而不是选修课。我们作为数据库产品的构建者,虽然不像我们的销售、售前、运维的同学们站在前线,但我们工作是他们向客户传达的最终价值。作为工程师,我们要关注我们的产品的质量,要让我们的构建的产品通过我们前线的同学,为客户真正创造价值,为了达到这个目标,测试一定是我们需要努力下功夫的必修课。
感谢你的阅读,YMatrix 期待与志同道合的你一起同行。





