




ChatBI是指通过NL2SQL技术支持企业通过自然语言查询数据生成报表。为了让您更好地了解ChatBI的功能和操作方法,我们将以“阿里香”餐饮管理系统为例,全面串联ChatBI的各个功能要点,帮助您快速上手并高效使用。
数据准备
CREATE TABLE restaurant_info (
id INT COMMENT '门店ID',
position VARCHAR(128) COMMENT '门店地点',
PRIMARY KEY (id)
) COMMENT='门店表';
CREATE TABLE menu_info (
id INT COMMENT '菜品ID',
name VARCHAR(64) COMMENT '菜品名称',
type INT COMMENT '菜品类型',
unit_price INT COMMENT '菜品单价',
PRIMARY KEY (id)
) COMMENT='菜品表';
CREATE TABLE bill_info (
id INT COMMENT '账单ID',
items VARCHAR(512) COMMENT '下单菜品',
actural_amount INT COMMENT '实际付费',
restaurant_id INT COMMENT '就餐门店',
waiter VARCHAR(16) COMMENT '服务员',
diner_count INT COMMENT '就餐人数',
pay_time DATE COMMENT '下单时间',
PRIMARY KEY (id)
) COMMENT='账单表';您可点击下载样例数据请根据您的表结构详细信息填写表和列的注释,以便大语言模型能够更好地识别和理解数据。这将有助于提升模型在数据处理和分析过程中的准确性和效率。
开通PolarDB for AI能力
开启功能并购买AI节点:使用PolarDB for AI的ChatBI功能之前,您需要先开启PolarDB for AI功能并购买AI节点。这个过程涉及多个步骤和技术细节,为了确保正确无误地完成配置。详细开启过程请参见开启PolarDB for AI功能。
创建账号:在成功配置AI节点后,您需要设置一个用于创建和管理数据库账号。该账号应具备足够的权限,以便读取和写入目标数据表,从而顺利执行ChatBI转换过程中涉及的各类数据库操作。
使用集群地址连接集群:如果您计划使用DMS登录PolarDB for AI,请特别注意登录时的集群地址设置。由于PolarDB for AI可能涉及不同的集群配置,您需要调整登录配置连接集群并执行AI SQL,以确保使用正确的集群地址。
使用ChatBI
接下来,您可以使用PolarDB for AI的NL2SQL模型来生成与用户问题相对应的SQL语句。有关详细信息请参见自然语言到SQL语言转义(基于大语言模型的NL2SQL)。
创建表结构索引
通过以下SQL语句,您可以创建一个名为schema_index的表结构索引表,以便向大模型提供表结构信息。
/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar,
table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names
text_ik_max_word, column_comments text_ik_max_word, sample_values
text_ik_max_word, vecs vector_768,ext text_ik_max_word, PRIMARY key (id));这张表不会直接显示在数据库中。如果您需要查看相关信息,请使用以下SQL语句进行查询。
/*polar4ai*/SHOW TABLES;接下来,您可以使用以下SQL语句将数据表结构导入到索引表schema_index中。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;执行时,PolarDB for AI会默认对当前库下的所有表进行向量化操作,并对列值进行采样。
执行该语句后,您将获得后台任务的task_id,例如:bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以使用以下SQL查询当前任务的状态。当返回的taskStatus为finish时,表示索引构建已完成。
/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;使用NL2SQL模型回答问题
您可以执行以下SQL语句在线使用基于LLM的NL2SQL。在以下示例中,用户提出的问题是这一周的总收入有多少,使用的表结构索引schema_index。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select '这一周的总收入有多少') WITH (basic_index_name='schema_index');数据库在处理请求时需要等待一段时间以获取大模型的回复,预期的返回结果如下:

根据上述示例,我们还可以提出一些典型的问题。这些问题涵盖了多种情况,包括GROUP BY、多表JOIN、ORDER BY以及公式等。
问题序号 | 用户问题 | NL2SQL返回值 |
1 | 每个门店收入情况排序 |
|
2 | 在上海哪家门店收入最高 |
|
3 | 上海平均每个人消费多少 |
|
4 | 这个月菜品下单量前十有哪些 |
|
5 | 这个月比上个月收入的环比增长百分比多少 |
|
6 | 上海的哪家门店人流量最高 |
|
可以看到,基于LLM的NL2SQL模型能够较好地回答用户的问题,但有些问题的回复并未达到预期效果。例如,在第二个问题中,用户希望返回门店名称。如果重新表述为在上海哪家门店收入最高,请返回店名,模型将返回以下 SQL 语句:SELECT r.name FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position = '上海' ORDER BY b.actural_amount DESC LIMIT 1;。当然,我们也可以通过对模型进行精细调优来提高其准确率,这些问题将在下文中逐一解决。
精调模型
配置问题模板
您可以使用一些通用的问题模板,通过引入特定知识来指导模型,从而使其能够根据特定的知识生成SQL语句。
第一步:执行以下SQL,创建问题模版表polar4ai_nl2sql_pattern。其中,表名必须以polar4ai_nl2sql_pattern开头,表结构中必须包含上述建表语句中的五个列。
CREATE TABLE `polar4ai_nl2sql_pattern` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`pattern_question` text COMMENT '模板问题',
`pattern_description` text COMMENT '模板描述',
`pattern_sql` text COMMENT '模板SQL',
`pattern_params` text COMMENT '模板参数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;第二步:接下来,创建问题模板的索引表pattern_index。
/*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question
text_ik_max_word, pattern_description text_ik_max_word, pattern_sql
text_ik_max_word, pattern_params text_ik_max_word, pattern_tables
text_ik_max_word, vecs vector_768, PRIMARY key (id));我们为第二个问题配置模板,以进行精调,目的是返回店面的地址。
请执行以下SQL语句以添加一个新的模式(pattern):
INSERT INTO polar4ai_nl2sql_pattern (id, pattern_question, pattern_description, pattern_sql, pattern_params) VALUES (
1,
"在#{position}哪家门店收入最高",
"在【地点】哪家门店收入最高",
"SELECT r.position FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position LIKE '%#{position}%' ORDER BY b.actural_amount DESC LIMIT 1;",
'[{"table_name":"restaurant_info"},{"table_name":"bill_info"}]'
);在模式(pattern)中采用了槽位,以便匹配多个地点。在pattern_sql列中填写正确的SQL语句,并在槽位位置用#{}进行标记。pattern_params列用于表信息的额外后置处理补充,但在此可以忽略。
第三步:接下来,将问题模板的信息导入索引表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;与 schema_index构建索引表的过程类似,这里也会返回一个任务ID。您可以通过执行/*polar4ai*/show task 'xxx-xxx-xxx'来查看当前任务的状态。
如果
polar4ai_nl2sql_pattern表中的数据发生更新,则需要重新创建pattern_index并进行导入操作。可以使用以下 SQL 语句删除旧表:/*polar4ai*/DROP TABLE pattern_index;
让我们重新执行生成问题的SQL,并附上pattern_index提示。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select '在上海哪家门店收入最高') WITH
(basic_index_name='schema_index',pattern_index_name='pattern_index');
构建配置表
若您希望对问题进行前置处理,或者对最终生成的SQL进行后置处理时,可以使用配置表进行配置。
词汇含义提示
在第六个问题中,由于“大模型”无法准确理解“人流量”这一词汇的含义,因此可以通过配置polar4ai_nl2sql_llm_config表进行预处理。
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT '是否生效',
`text_condition` text COMMENT '文本条件',
`query_function` text COMMENT '查询处理',
`formula_function` text COMMENT '公式信息',
`sql_condition` text COMMENT 'SQL条件',
`sql_function` text COMMENT 'SQL处理',
PRIMARY KEY (`id`)
);插入相关的配置项,告知大模型将“人流量”或“客流量”统计为“就餐人数”。
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
1,
1,
"人流量||客流量",
"",
"人流量或客流量使用就餐人数总和进行统计",
"",
""
);其中,is_functional为1表示该配置项有效。字段text_condition的值为“人流量||客流量”,用于在问题中匹配含有“人流量”或者“客流量”的情况。formula_function中的内容则是通过文字(或公式)向大模型解释专业词汇的含义。
在此情况下,无需构建索引表和进行向量化处理,可以直接执行SQL生成,结果如下。

模糊匹配提示
在第3个问题中,地名匹配使用=操作符进行检索将导致失败。因此,我们需要提示在进行地名匹配时应使用模糊搜索,可以添加以下配置项。
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
2,
1,
"",
"",
"门店地点position的匹配需要使用模糊搜索",
"",
""
);其中,text_condition为空,表示该配置项将全局生效(请谨慎使用)。
结果如下图所示。可以看到,地点的匹配成功地使用了模糊搜索。

同理,在第5个问题中,“环比”和“同比”的计算公式也可以录入到 polar4ai_nl2sql_llm_config配置表中,以提高生成SQL的精确度。您可以自行进行挑战尝试。
图表输出
在使用NL2SQL生成SQL语句后,通常希望获得该SQL查询的结果,并同时展示一些更直观的视觉效果,如柱状图、饼图等。PolarDB的SQL2Chart方案能够执行用户的 SQL 查询,并最终返回相应的报表。
配置问题模板
polar4ai_nl2sql_pattern表需要增加一列chart_setting,以提供图表配置。
CREATE TABLE `polar4ai_nl2sql_pattern` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`pattern_question` text COMMENT '模板问题',
`pattern_description` text COMMENT '模板描述',
`pattern_sql` text COMMENT '模板SQL',
`pattern_params` text COMMENT '模板参数',
`chart_setting` text COMMENT '图表配置',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;请插入图表配置记录。
INSERT INTO polar4ai_nl2sql_pattern (id, pattern_question, pattern_description, pattern_sql, pattern_params, chart_setting) VALUES (
3,
"今年每个月的收入情况",
"今年每个月的收入情况",
"SELECT DATE_FORMAT(pay_time, '%Y-%m') AS month, SUM(actural_amount) AS income FROM bill_info WHERE YEAR(pay_time) = 2024 GROUP BY month ORDER BY month;",
'[{"table_name":"bill_info"}]',
'{"chart_type":"line","x_axis":"month","y_axis":"income","x_label":"月份","y_label":"收入","title":"收入情况"}'
);其中,为“今年每个月的收入情况”这一问题配置相关的 SQL 和图表信息。在此,图表类型设为折线图(line),并设置横纵坐标及相应的列名。
重新导入到索引表pattern_index,等待任务完成。
/*polar4ai*/DROP TABLE IF EXISTS pattern_index;
/*polar4ai*/CREATE TABLE pattern_index(id integer,
pattern_question text_ik_max_word, pattern_description text_ik_max_word,
pattern_sql text_ik_max_word, pattern_params text_ik_max_word,
pattern_tables text_ik_max_word, vecs vector_768, PRIMARY key (id));
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;通过data2chart模型生成图片
通过NL2SQL生成SQL查询及其对应的pattern_id。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql,
SELECT '每个门店收入情况排序') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index',
pattern_index_threshold=0.1,with_pattern_id=1);结果如下图所示:

通过一条SQL查询即可在线生成该SQL对应的图片链接。
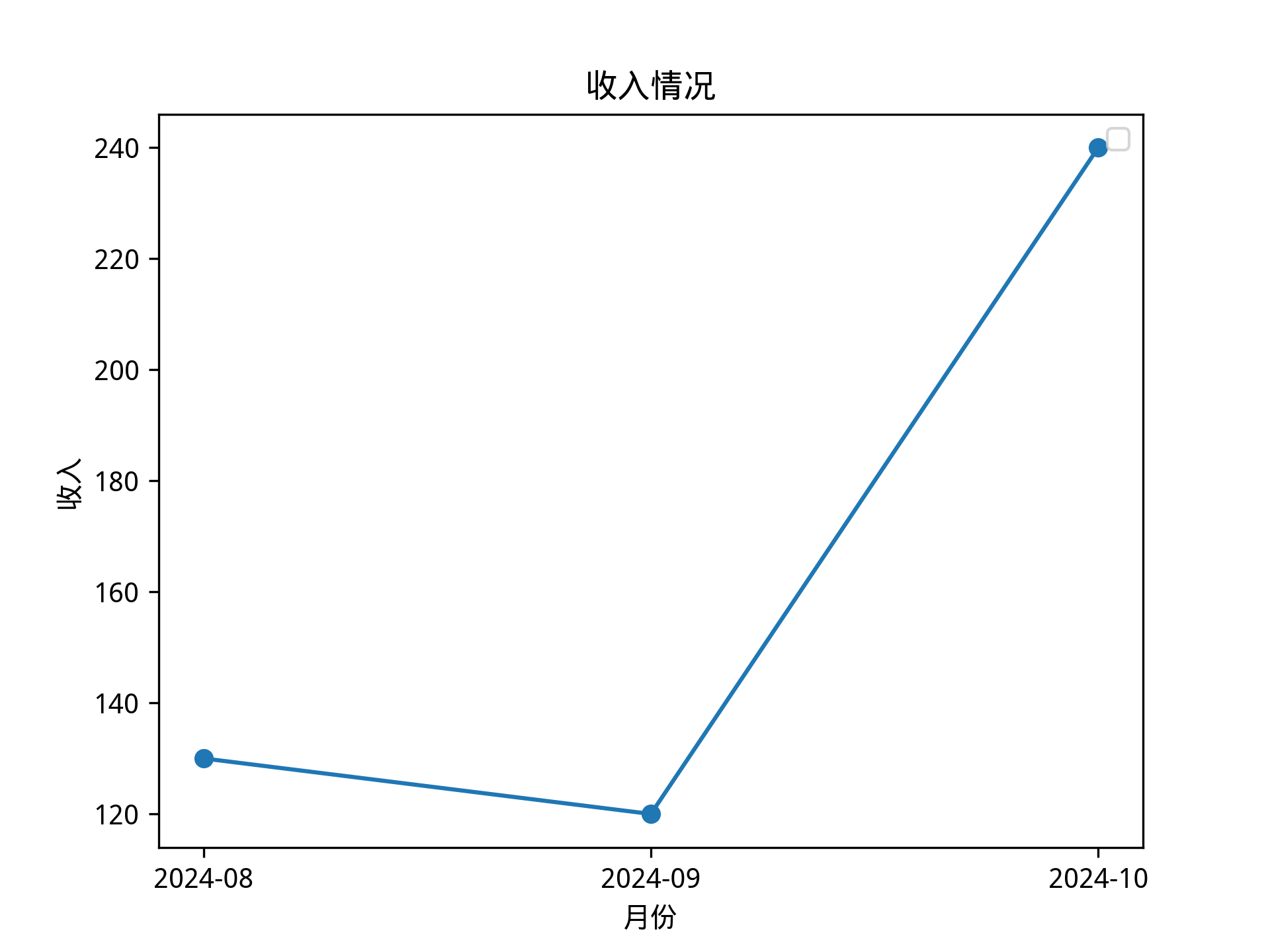
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_data2chart,
SELECT DATE_FORMAT(pay_time, '%Y-%m') AS m, SUM(actural_amount) AS income FROM
bill_info WHERE YEAR(pay_time) = 2024 GROUP BY m ORDER BY m) WITH
(basic_index_name='schema_index', setting_table_name='polar4ai_nl2sql_pattern', setting_id='3', result_type='IMAGE');执行结果如下,返回的是一个存储在OSS上的图片URL地址(有效期为一天)。
返回图片结果如下:
如果您想尝试其他类型的图表(例如柱状图或饼图),可以进行相应设置。详细信息请参见SQL2Chart。
常见问题
Q:在DMS平台上执行SQL语法时出现错误。
A:请检查DMS连接集群的地址是否正确。详情请参见连接集群并执行AI SQL。
Q:错误信息:9050 - Empty data 'polar4ai_nl2sql_pattern'为空。
A:'polar4ai_nl2sql_pattern'表中没有数据。如果没有可用的模式(pattern),则无需进行向量化导入。
Q:执行data2chart时出现错误:1149 - You have an error in your SQL syntax;。
A:造成这个错误的原因有很多。
检查列名:确认SQL语句中是否使用了关键字或函数名作为列名。
将SQL语句作为字符串插入:将SQL语句作为字符串插入到数据库中。
通过sql_fetching参数获取SQL:通过sql_fetching参数获取该条SQL进行生成。
Q:错误信息:
2003 - Execute sql failed in ai db执行失败。A:优先检查数据库账号中关于AI权限是否已开启,详细请参见开启PolarDB for AI功能;然后检查SQL语句中是否存在特殊字符(尽量去掉注释、换行和缩进符号)。
重新微调训练模型
若模型无法满足您的业务需求,您可以重新训练模型,并对模型内部参数进行微调,以达到更佳的效果。
限制条件
仅支持AI节点规格为16核125 GB+ 一张GU100 polar.mysql.x8.2xlarge.gpu的集群使用该功能。
当前一次只能训练一个模型。
目前只能部署一个模型。
使用说明
训练模型
/*polar4ai*/CREATE MODEL udf_qwen14b WITH (model_class='qwen-turbo',
model_parameter=(basic_index_name='schema_index', pattern_index_name='pattern_index',training_type='efficient_sft')) as (SELECT '')、参数说明
参数名 | 说明 | 默认值 | 可选值/范围 |
model_class | 模型类型,当前支持{'qwen-14b-chat', 'qwen-turbo'}。 | 无 | {'qwen-14b-chat', 'qwen-turbo'} |
model_parameter | 模型参数配置,包括必需和可选参数。 | 无 | 无 |
basic_index_name | 训练数据中的数据库信息采自的索引表名称,此处需为数据库索引表。 | 无 | 无 |
pattern_index_name | 训练数据中的问题模板信息采自的索引表名称,此处需为问题模板索引表。 | 无 | 无 |
trainning_type | 训练类型,允许值{'efficient_sft', 'sft'}。'efficient_sft'表示高效训练,一般为LoRa方式;'sft'表示全参数训练。 | 无 | {'efficient_sft', 'sft'} |
n_epochs | 循环次数,模型训练过程中学习数据集的次数。建议范围为1-3遍,可依据需求进行调整。 | 3 | [1, 200] |
learning_rate | 学习率,表示每次更新数据的增量参数权重。学习率越大,则参数变化越大,对模型影响越大。 | '3e-4' | 无 |
batch_size | 批次大小,代表模型更新参数的数据步长。建议的批次大小为16或32。 | 16 | {8, 16, 32} |
lr_scheduler_type | 学习率策略,动态改变训练过程中更新权重时采用的学习率大小。 | 'linear' | {'linear', 'cosine', 'cosine_with_restarts', 'polynomial', 'constant', 'constant_with_warmup', 'inverse_sqrt', 'reduce_lr_on_plateau'} |
eval_steps | 模型验证的间隔步长,用于阶段性评估训练准确率及损失。 | 50 | [1, 2147483647] |
sequence_length | 训练数据的序列长度,单个样本的最大长度,超出长度将自动截断。 | 2048 | [500, 2048] |
lr_warmup_ratio | warmup占总训练步数的比例。 | 0.05 | (0, 1) |
weight_decay | L2正则化,帮助减少过拟合问题。 | 0.01 | (0, 0.2) |
gradient_checkpointing | 开启或关闭gradient checkpointing,用于节省显存。 | 'True' | {'True', 'False'} |
use_flash_attn | 是否使用Flash Attention。 | 'True' | {'True', 'False'} |
lora_rank | LoRa训练中的秩大小,影响训练中数据对模型的作用程度。 | 8 | {2, 4, 8, 16, 32, 64} |
lora_alpha | LoRa训练中的缩放系数,用于调整初始化训练权重。 | 32 | {8, 16, 32, 64} |
lora_dropout | 训练过程中随机丢弃神经元的比率,防止过拟合,提高模型泛化能力。 | 0.1 | (0, 0.2) |
lora_target_modules | 选择模型的特定模块进行微调优化。 | 'ALL' | {'ALL', 'AUTO'} |
查看模型
/*polar4ai*/SHOW model udf_qwen14b删除模型
/*polar4ai*/DROP model udf_qwen14b查看所有模型
/*polar4ai*/SHOW models模型部署
训练完成的模型只有在经过部署后,才能在NL2SQL中使用。
/*polar4ai*/deploy model udf_qwen14b查看部署
/*polar4ai*/SHOW deployment udf_qwen14b删除部署
/*polar4ai*/DROP deployment udf_qwen14b查看所有部署
/*polar4ai*/SHOW deployments使用部署的模型进行自然语言转SQL
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT 'id为1的内容是什么?') WITH (basic_index_name='schema_index', llm_model='udf_qwen14b')参数说明
参数 | 描述 |
basic_index_name | 不可为空,需填写当前问题关联的数据库信息索引表。 |
llm_model | 可为空。如果不填写,将调用未经微调的模型进行自然语言转SQL;如果填写,请确保填写已部署且状态为“serving”的部署名称。未完成部署的模型无法在此使用。 |
