




引言:
【无需人类“手把手教”,AI自己学会高难度推理!】
国产大模型团队DeepSeek扔出一枚“核弹”:全球首个纯强化学习训练的大模型DeepSeek-R1-Zero,以及它的升级版DeepSeek-R1,在数学、代码、逻辑推理任务中直接对标OpenAI-o1!更劲爆的是——全部开源!
一、两大“推理怪兽”横空出世
1. DeepSeek-R1-Zero:野路子学霸的逆袭
训练秘籍:完全靠“自己刷题”(纯强化学习),不用人类标注答案(无监督微调) 超能力:
✅ 自主涌现复杂推理路径(如多步数学证明)
✅ 解题思路堪比人类学霸翻车现场:
❌ 有时话痨重复
❌ 答案格式混乱
❌ 中英文混杂输出
2. DeepSeek-R1:配上“导航仪”的六边形战士
关键升级:训练前注入冷启动数据(相当于给AI一本《解题规范手册》) 终极形态:
✅ 解题准确率追平OpenAI-o1
✅ 答案清晰易读
✅ 支持代码/数学符号规范排版
二、黑科技揭秘:AI如何“无师自通”?
1. 纯RL训练:让AI自己“刷题千万遍”
传统方法:先人工教基础(SFT),再让AI自己练(RL) DeepSeek突破:
🔹 直接让AI从零开始“题海战术”
🔹 日均处理数亿级推理问题
🔹 自主发现隐藏解题规律
2. 知识蒸馏:把“大学教授”塞进“中学生大脑”
神奇操作:
1️⃣ 用DeepSeek-R1当“教授”
2️⃣ 蒸馏出6个“学生模型”(基于Llama/Qwen架构)战绩:
🏆 32B版小模型(DeepSeek-R1-Distill-Qwen-32B)
➡️ 全面碾压OpenAI-o1-mini
➡️ 刷新密集模型SOTA记录
3. 模型对比和改进分析
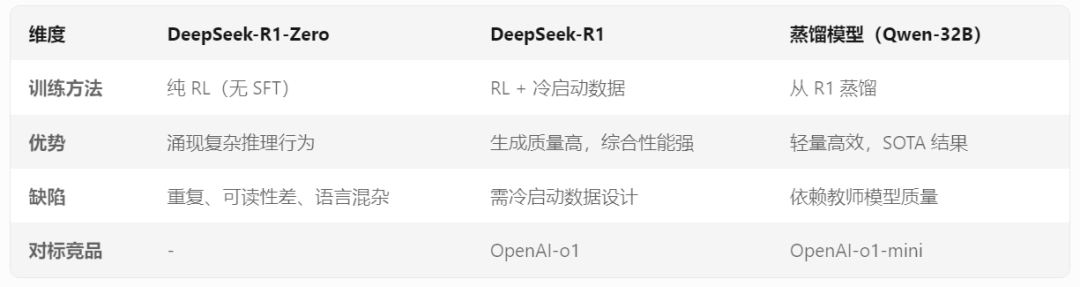
三、开源革命:开发者狂欢开始!
1. 开源全家桶
开放内容:
🔸 R1-Zero原始模型
🔸 R1升级版模型
🔸 6个蒸馏小模型(7B/13B/32B)一键体验:
GitHub仓库已支持HuggingFace快速部署
2.关键技术创新
纯 RL 路径的突破
🔸 传统 RLHF(如 ChatGPT)依赖 SFT 初始化,而 R1-Zero 直接通过 RL 训练,证明大规模 RL 可独立塑造推理能力。
🔸 意义:为无监督/弱监督场景下的模型训练提供新思路。
蒸馏技术的应用
🔸 从大模型(R1)蒸馏到密集小模型(如 Qwen-32B),实现性能与效率的平衡。
🔸 技术细节推测:
使用任务特定损失函数(如数学解题的步骤对齐)。 结合注意力迁移(Attention Transfer)和逻辑蒸馏(Logical Distillation)。
3. 四大应用场景
教育领域:自动批改数学证明题(如自动解题、步骤生成) 编程助手:复杂代码逻辑debug (如代码补全、Bug 修复) 科研分析:论文数据推理验证 商业决策:供应链优化路径推演
四、未来之战:推理模型的星辰大海
当前挑战:
🔹 超长文本连贯推理
🔹 多模态(图文混合)逻辑推演DeepSeek路线图:
✅ 2024 Q3:发布千亿参数推理模型
✅ 2024 Q4:开放企业级API服务
五、总结
DeepSeek-R1 系列通过 RL 训练范式创新 和 高效蒸馏技术,在保持模型轻量化的同时实现推理性能的突破。其开源策略将加速推理模型在学术和工业界的落地,尤其在数学、代码等场景中具备显著竞争优势。对开发者而言,可重点关注蒸馏模型(如 Qwen-32B)的实践应用,结合自有数据微调以适配具体任务。
文章转载自数据库运维之道,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
