




ABSTRACT
citus是作为PG的分布式插件扩展,本文介绍了citus适合的四种负载,介绍了Microsoft使用citus解决数据问题的一种场景
INTRODUCTION
- PG很流行,扩展机制提供了不用fork分支的开发方法
- 传统上,分布式数据的三种构建方法
- 从头开始构建数据库引擎
- 分叉一个开源数据库系统并在其基础上构建新特性
- 通过一个位于应用程序和数据库之间的层(即中间件)提供新功能。(类似阿里的TDDL / DRDS)
三种方法一直跟上社区都非常难。Citus 是第一个通过 PostgreSQL 扩展 API 提供其功能的分布式数据库。使得可以透明地集成分片层、分布式查询规划器和执行器以及分布式事务。有如下好处:
- 极低的工程成本保持与最新 PostgreSQL 功能和工具的兼容性
- citus将数据分布到常规的 PostgreSQL 服务器上,可以利用PG高级特性
- 分布式不可能在所有场景100%兼容单机并且没有性能损失,也不是所有应用都是scale out的需求,我们把能从分布式中受益的场景分为四种workload,citus也是被这四种场景驱动开发的(小鹏像是RA和HC的混合负载)
- Multi-tenant / SaaS
- real-time analytics
- high-performance CRUD
- data warehousing
4. 本文三项主要贡献。
- 我们描述了在与客户交流中观察到的四种工作负载模式及其在可扩展性和分布式数据库能力方面的要求。
- 我们描述了 PostgreSQL 扩展 API 以及 Citus 如何使用这些 API 实现一个全面的分布式数据库系统
- Citus 架构展示了我们如何在一个单一的分布式数据库系统内满足广泛的数据密集型应用的需求。
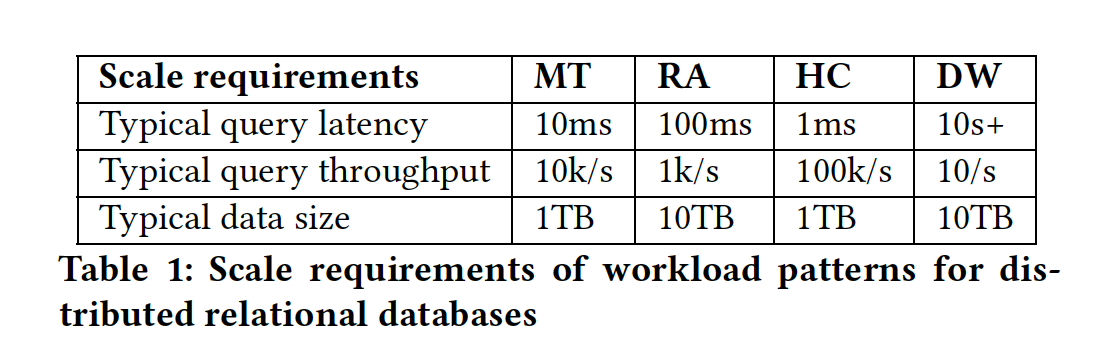
WORKLOAD REQUIREMENTS
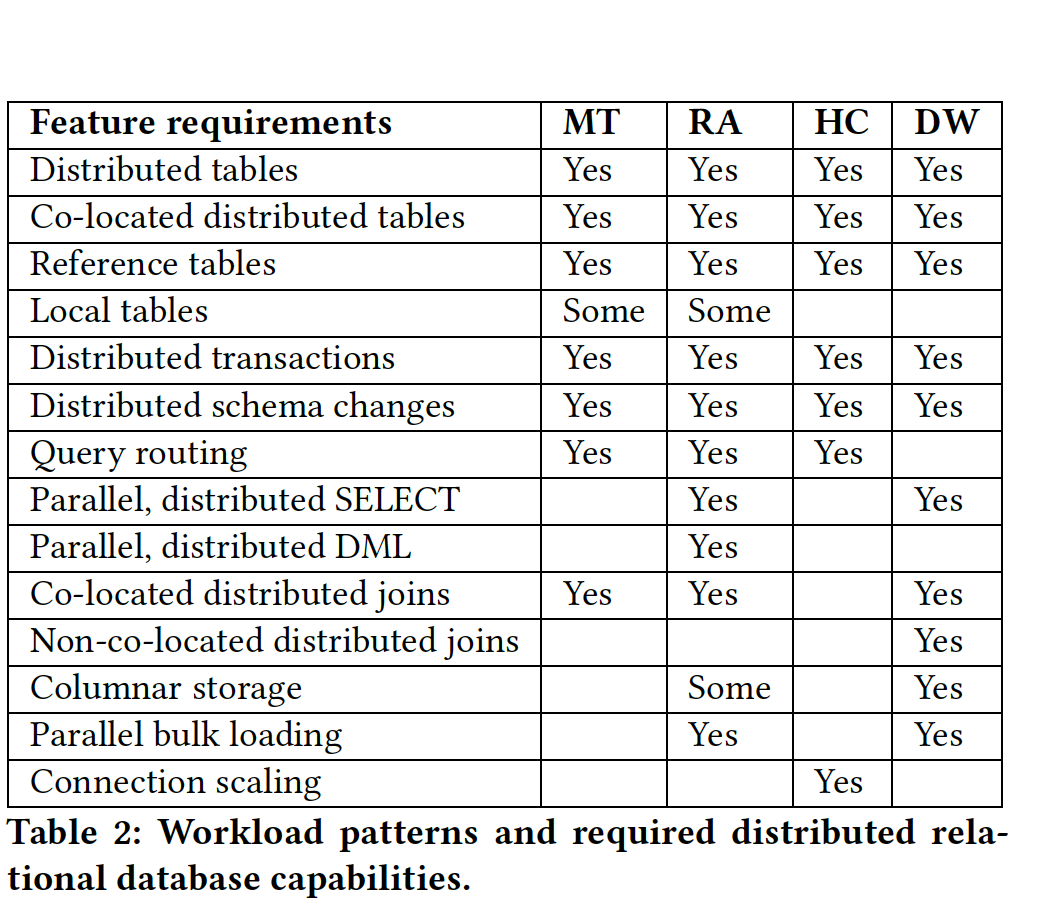
- MT
- RA
- HC
- DW
CITUS ARCHITECTURE
- 在Citus集群中,所有服务器都运行带有Citus扩展以及任意数量其他扩展的PG实例。
- Citus使用PG扩展API来以两种方式改变数据库的行为
- Citus将数据库对象(如自定义类型和函数)复制到所有服务器。
- Citus添加了两种新的表类型来利用额外的服务器。
3.1 PG extensions APIs
API | 用途 |
User-defined functions (UDFs) | 管理元信息、实现remote procedure calls |
Planner and executor hooks | 分布式计划执行、生成Custom Scan |
CustomScan | 分布式执行 |
Transaction callbacks (e.g. pre-commit, post-commit, abort). | 分布式事务 |
Utility hook | DDL、COPY |
Background workers | 分布式死锁检测、2PC recovery和clean up |
3.2 Citus architecture diagram
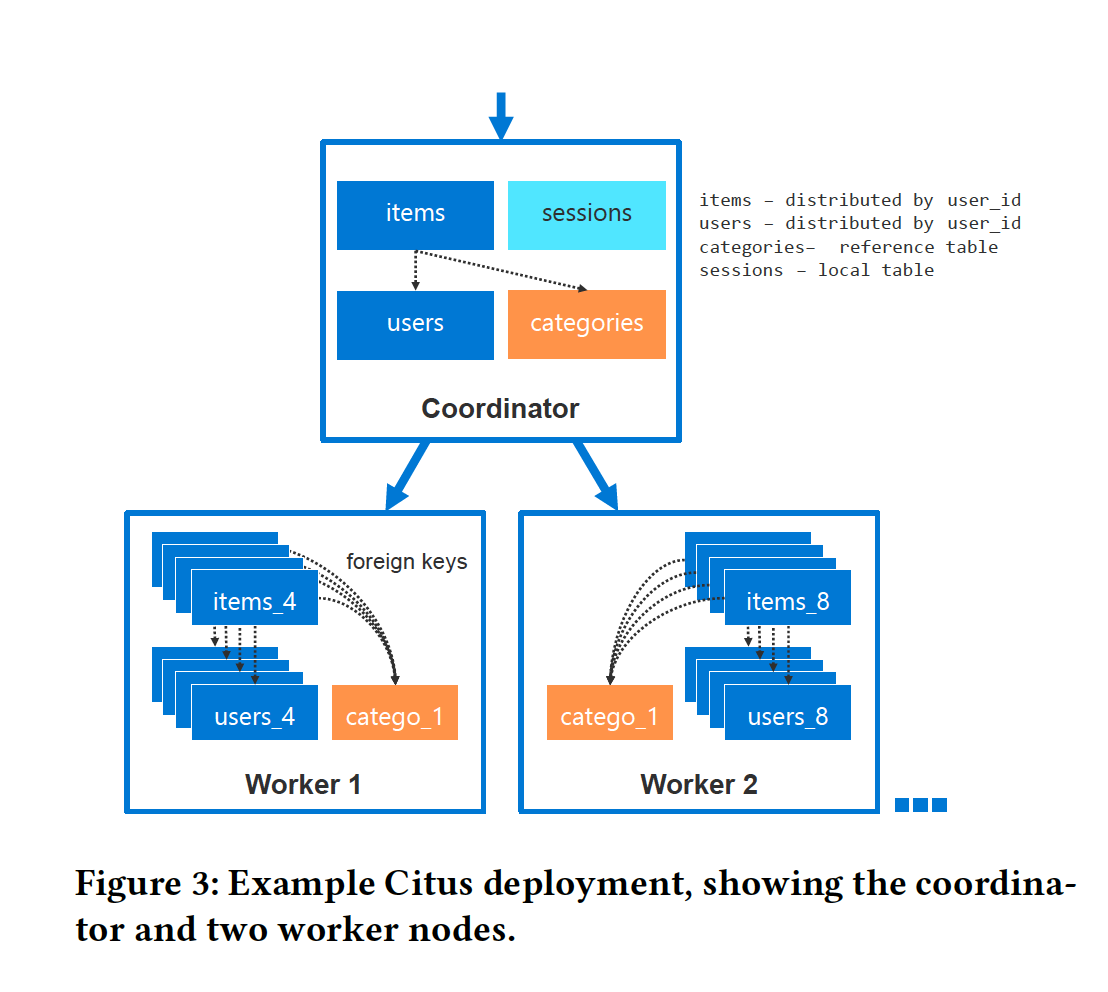
CN存元数据,DN存shard数据,规模小的时候CN也可以当DN用
3.2.1 Scaling the coordinator node
citus可以把元数据和更改复制到所有节点,也就是DN也可以处理请求,只有CN负责DDL。但这种模式会导致连接变多,成为另一个瓶颈,现在citus是用连接池解决的(PgBouncer)。(怀疑从CN的模式就是后续citus推出的)
3.3 Ctius table types
3.3.1 分片表(Distributed tables)
- 按照hash分区,每个分片一段hash值,一个worker可以包含多个逻辑分片
- 先创建普通表,再用citus UDF转换成分片表

3.3.2 亲和(Co-location)
- 对于互相亲和的表,Citus 可以保证相同范围的哈希值对应的数据都在相同的 worker 节点上,因此,在执行 join 等操作时,citus 不需要进行跨节点通信。
- 创建的时候可以指定和谁亲和,不然根据分布键的data type决定

3.3.3 引用表/复制表(Reference tables)
复制到所有节点(包括CN)

3.4 Data rebalancing
- rebalancing的必要性
- 业务的增长
- 数据分布的不均衡
- rebalancing 策略
- 默认是每个节点shard数相等
- 用户也可以基于data size / 用SQL创建策略
- rebalancing 实现
- 选择一个shard的时候也要将Co-location的一起移动
- 使用PG逻辑复制
- 移动时老shard还是可以读写
- 复制追上的时候citus获取shard的写锁 -〉等待复制结束 -〉修改元数据 -> 新查询进入新worker
- 最后切换的时候一般只要几秒,最小化write downtime
3.5 Distributed query planner
- 当 SQL 查询引用 Citus 表时,分布式查询规划器会生成一个包含 Custom-Scan 节点的 PostgreSQL 查询计划,该节点包含分布式查询计划。
- 分布式查询计划由一组任务(在分片上运行的查询)和可选的一组子计划组成,子计划的结果需要broadcast or re-partitioned,以便后续任务可以读取这些结果。
- Citus 需要处理各种工作负载,演变为具有针对不同查询类别的规划器
- 简单的 CRUD 查询需要最小的规划开销。
- 复杂的数据仓库查询需要高级查询优化,带来更高的规划开销。
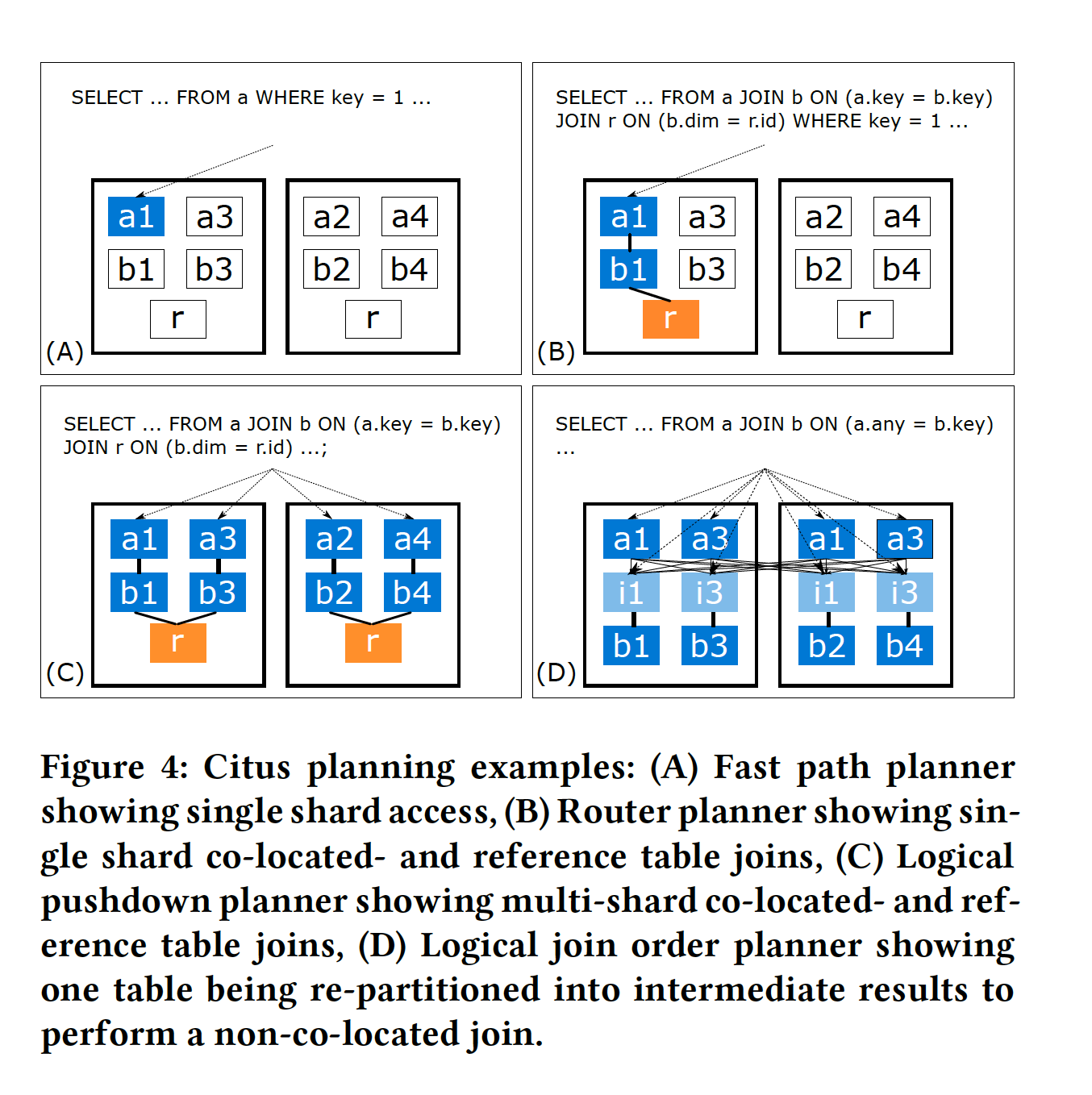
优化器类型 | SQL特征 | 实现模式 | 优点 | 适应场景 |
Fast path planner | 分布键点查 | 直接把逻辑表改成value对应的分片shard名发送到对应worker即可 | 高性能、低延迟 | HC |
Router planner | 一组亲和表 + 命中同样shard的任意复杂查询 | 查询中的表名会被重写为匹配分布列值的共同定位分片的名字 | 直接发到PG worker,因此可以支持所有SQL特性 | MT (SaaS) |
Logical planner——查询跨越了分片 目标是尽量在将数据merge到CN前将计算下推 | ||||
Logical pushdown planner | 能全部下推——join key都是分布键 && 分片表都是亲和的 && 不用全局merge算子(group by带有分布键) | 在很大程度上不关心join中的 SQL 构造,分布式查询计划可以轻松地实现并行。 | 支持更复杂的SQL | 其他(RA和DW) |
Logical join order planner | 探测到join中有非亲和的 | 评估所有join order(使用co-located joins/broadcast joins/re-partition joins),选择最小化网络交互的join order | ||

对每个SQL,citus从简单到复杂遍历这四种planner,如果能用就用。这种策略有如下优点:
- 每种工作负载的延迟预期存在数量级差异。
- 其次,这种差异也和每个planner的开销match。
例如,一个复杂的数据仓库查询可能需要几分钟才能完成。在这种情况下,用户并不介意前几种planner多几毫秒的开销。
具体实现(FROM citus planner README)
- 入口 distributed_planner
- 非常简单的场景,citus直接fastpath生成一个PlannedStmt
- 其余的场景,先调用standard_planner生成PlannedStmt,再修改成citus的计划
- Fast-path router planner/Router planner/Modification planning/Recursive planning/Logical planner
- Fast-path router planner
- 不用调standard_planner
- Router planner
- set_rel_pathlist_hook会获取分布表上的filters,citus利用它来进行shard prune,如果prune后都只有1个shard,并且是相同的shard,这就是Router planner的范畴
- Router planner修改分布式表的名字为shard名字
- 不能直接修改query,因为shard表的oid在CN中并不存在
- citus先把分布式表修改为function polar_cluster_extradata_container,最后deparser的时候再识别这个function转换成shard表
- Modification planning(有DML,且所有的join都是亲和的)
- Recursive planning(处理无法下推的CTE和subquery)
- 对于这类subquery,生成的分布式计划存在DistributedPlan->subPlanList,然后把这个subquery替换成 read_intermediate_result
- 执行的时候,依次执行subPlanList,每个的output都发送给all workers,写入intermediate result(subplan_execution.c)
- 因此在优化器的另外阶段,会把read_intermediate_result当成复制表
- Logical planner
- Fast-path router planner
3.6 Distributed query executor
- 由分布式planner生成的计划包含一个调用分布式执行器的 CustomScan 节点。
- Fast path / Routher planner的计划就是一个单一的 CustomScan 节点,因为执行发给DN就行了。
- Logical planner的计划可能需要一个合并步骤(例如,跨分片的聚合)。在这种情况下,在 CustomScan 之上会有额外的执行节点,这些节点由原生 PostgreSQL 执行器处理。
- 当 PostgreSQL 执行器调用 CustomScan 时,Citus 首先执行子计划(如果有的话),然后将执行交给一个称为“adaptive executor”的组件。
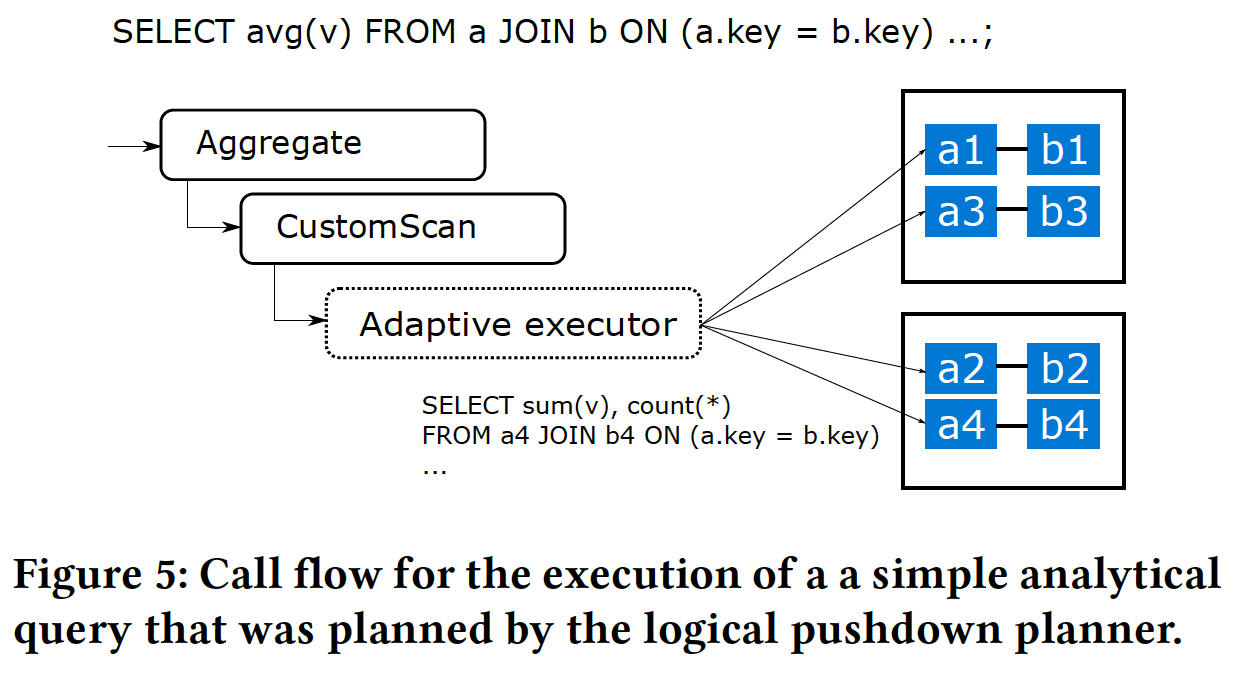
3.6.1 adaptive executor
- 设计目标:支持混合负载(快速路由到单个分片 / 多个连接并行执行) + 适应PG多进程架构
- citus发现在一个worker上使用多个连接并行执行比PG内置的并行查询更快,这种模式建立连接和创建进程的开销是问题
- citus如何对并行度(尽量开多个连接)和低延迟(尽量复用连接)进行trade off——slow start
- 对每个query,刚开始每个worker节点连接数 n = 1
- 每10ms,n = n + 1
- 如果有t个pending task没有连接来执行,n = n + min(n, t)
- 还是会在共享内存里控制n的最大值,防止超出连接数限制。
- n的最大限制需要被CN上执行query的进程公平分配
- slow start设计的原因
- in memory index scan大约1ms以内执行完了,不用新建连接
- 分析SQL耗时很多,建立连接的开销此时显得微不足道
- 因为事务锁、可见性的问题,因此citus跟踪每个连接访问了哪些分片,以确保在同一事务中对同一组亲和的分片的任何后续访问都会使用相同的连接。分配算法如下:
- 在开始执行一个语句时,如果事务中之前访问过的分片已经被访问,task将被分配给对应的连接,否则它们将被分配到worker的task池中。
- 当一个连接准备好时,执行器首先从它的task中取一个分配的任务,否则从task池中取一个。
3.7 Distributed transactions
3.7.1 Single-node transactions
很简单,直接交给worker处理即可
3.7.2 Two-phase commit protocol
核心是使用PG的2PC
- CN上分布式事务需要commit的时候
- CN给每个参与的DN发送prepared,并且为每个2PC写入数据到CN的元数据中,然后CN提交
- 当CN提交已经持久化之后,开始去每个参与的DN上commit
- 2PC recovery
- 后台进程对比CN上记录的2PC信息,以CN的记录为准,有就必须commit,没有就必须abort
- 当有多个CN的时候,每个CN自己做自己的2PC recovery
3.7.3 Distributed deadlocks
- citus扩展了PG的死锁检测,出现死锁的时候abort掉事务
- 后台进程每2s查询每个DN的lock graph,将他们merge到一起,如果成环了,说明出现了死锁,将最短的事务abort掉
- 除非存在实际死锁,否则在典型的(分布式)数据库工作负载中,只有少数事务会在等待锁。因此,分布式死锁检测的开销很小。
- 当分布式死锁经常发生时,建议用户更改其事务中语句的顺序。
3.7.4 Multi-node transaction trade-offs.
多节点分布式事务在citus中有一致性、原子性和持久性,但是没有分布式snapshot来保证全局一致性,没这么做的原因:
- 需要修改PG提供snapshot的扩展机制
- 这四种工作负载模式中并没有发现对分布式快照隔离的强烈需求,客户目前也没有表达对此的需求。
- 在多租户(MT)和CRUD应用程序(HC)中,大多数事务是单点。
- 分析(RA和DQ)之间的事务没有强依赖关系,因此snapshot要求不高。
- 现有的全局snapshot技术需要额外的网络往返或等待时钟,有显著的性能成本增加了延迟。吞吐量 = 连接数/响应时间,建立大量的连接一般行不通,因此延迟就很重要
- 未来实现这个能力,也是可选的
3.8 Specialized scaling logic
DDL
发送到所有DN,分布式事务处理
COPY
单机PG是串行的,citus为每个shard并行化了
INSERT..SELECT
- 如果 SELECT 需要在CN上进行merge步骤,命令将在内部作为分布式 SELECT 执行,并COPY到目标表中。
- 如果不需要merge步骤,但源表和目标表不亲和,INSERT..SELECT 会在插入到目标表之前对 SELECT 的结果进行distributed re-partitioning。
- 否则,INSERT..SELECT 将直接在亲和的分片上并行执行。
Stored procedures
- 根据分布式参数和亲和表,可以下推到DN上执行,这样可以避免CN和DN的网络rt
- DN可以执行存储过程的大部分逻辑,必要时也可以在多个DN上执行分布式事务
3.9 High Availability and backups
HA——每个节点有hot standby,节点fail的时候promote standby,修改citus元信息、DNS和virtual IP,整体耗时20-30s
备份——每个节点单独进行备份,citus支持创建一致的restore point。创建一致的restore point的时候会阻塞CN上事务record表的写入,因此会阻塞2PC。集群恢复到一致的restore point可以保证跨节点的分布式事务的一致性(2PC要么都commit,要么都abort),能被CN 统一recovery
BENCHMARKS
4.1 Multi-tenant benchmarks
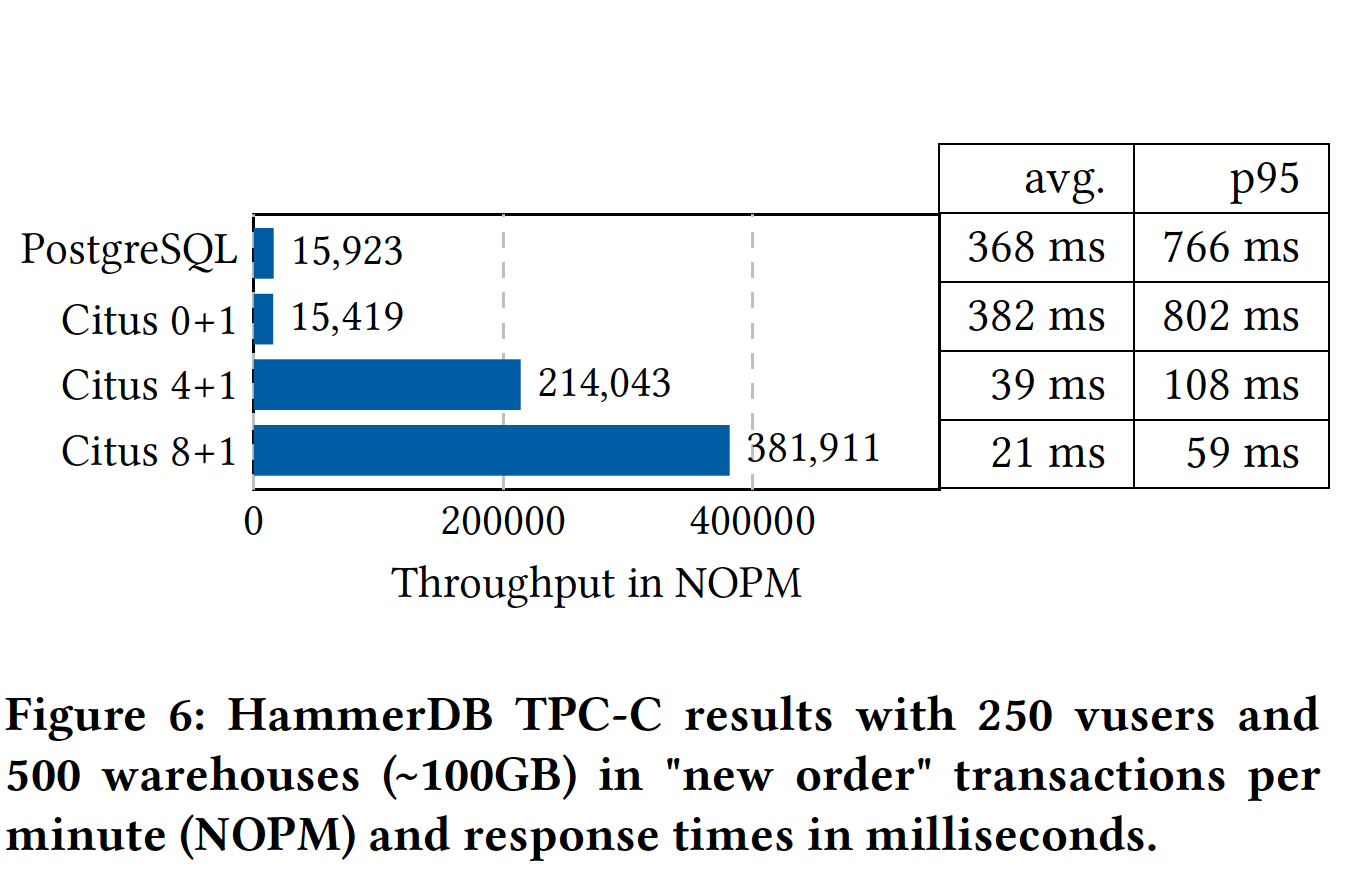
Citus 4 + 1把数据全装到内存中去了,所以性能提升很大
4.1.1 Distributed transaction performance
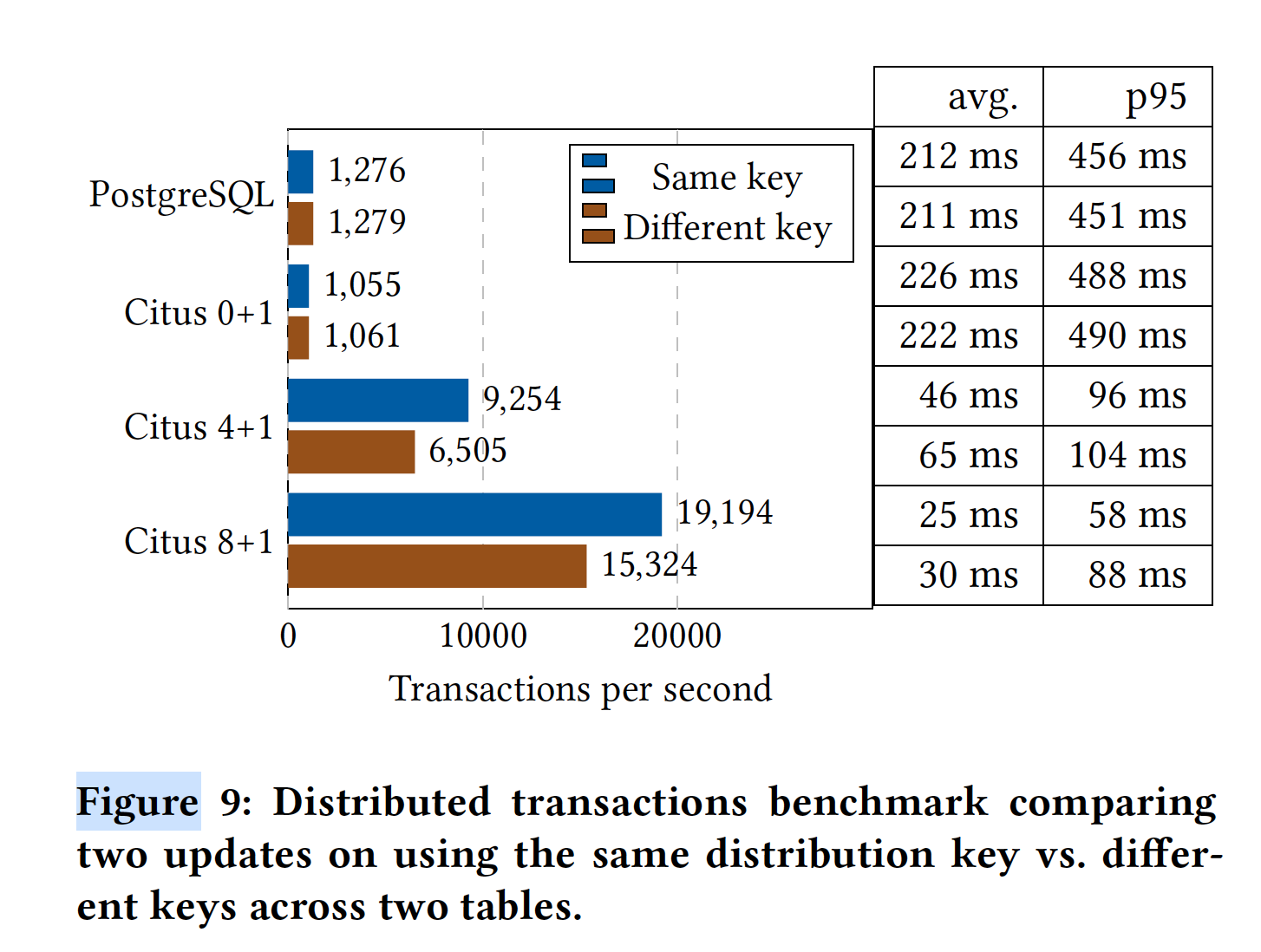
分布式事务损耗了20% - 30%
4.2 Real-time analytics benchmark
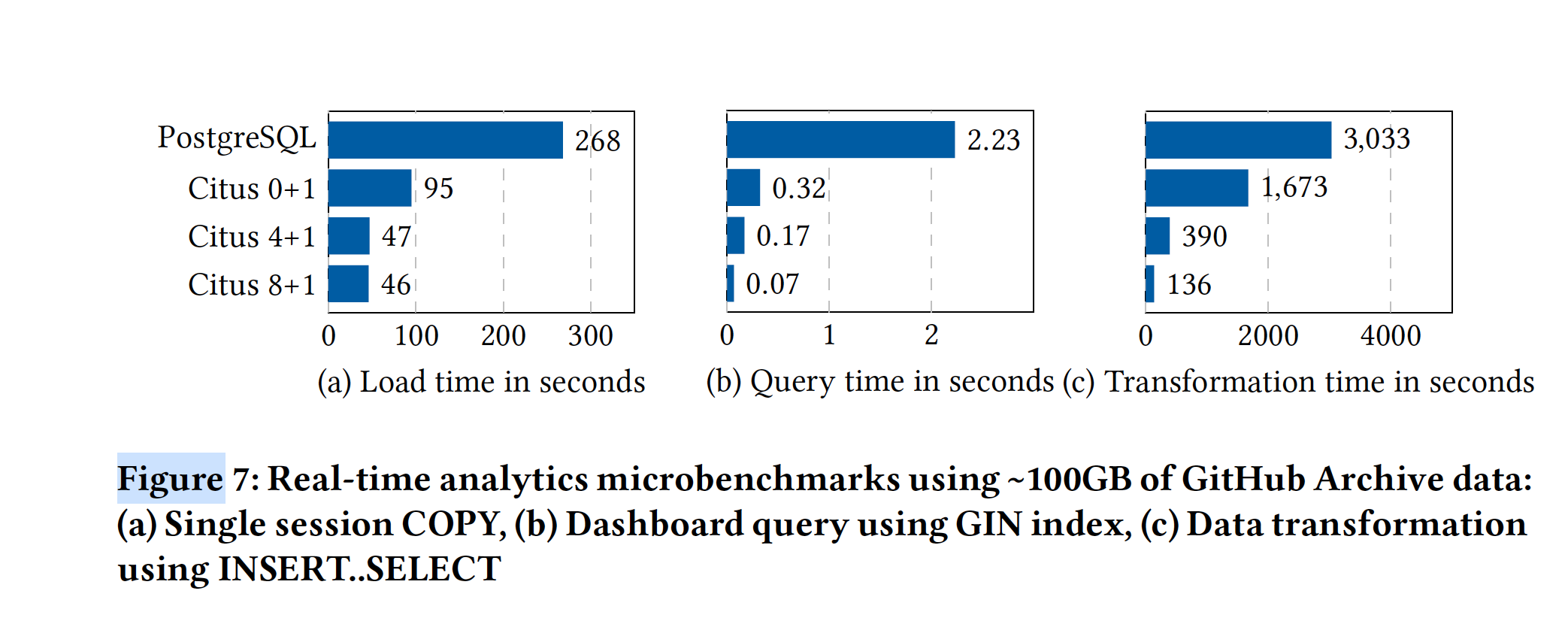
4.3 High performance CRUD benchmark
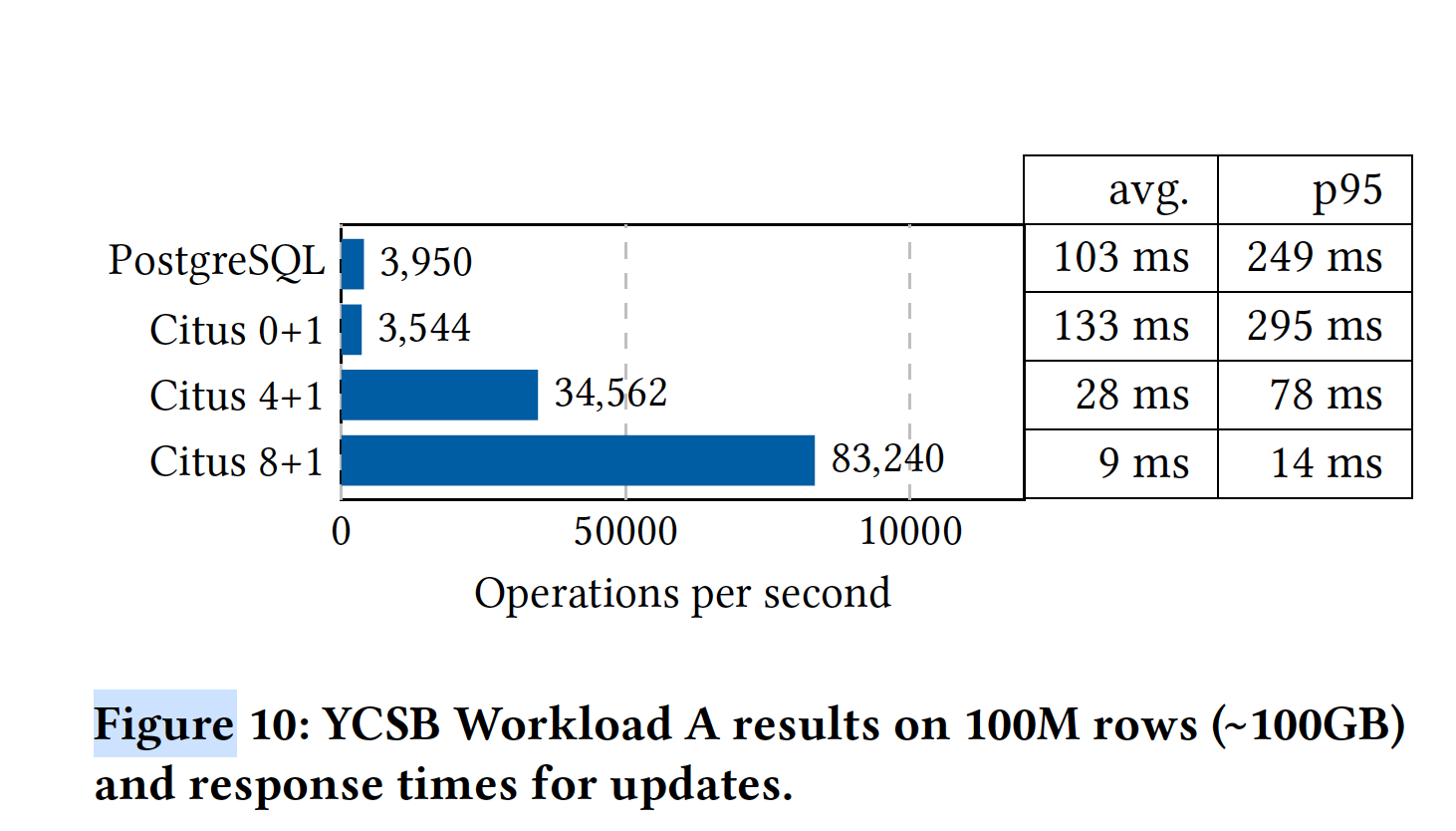
4.4 Data warehousing benchmark
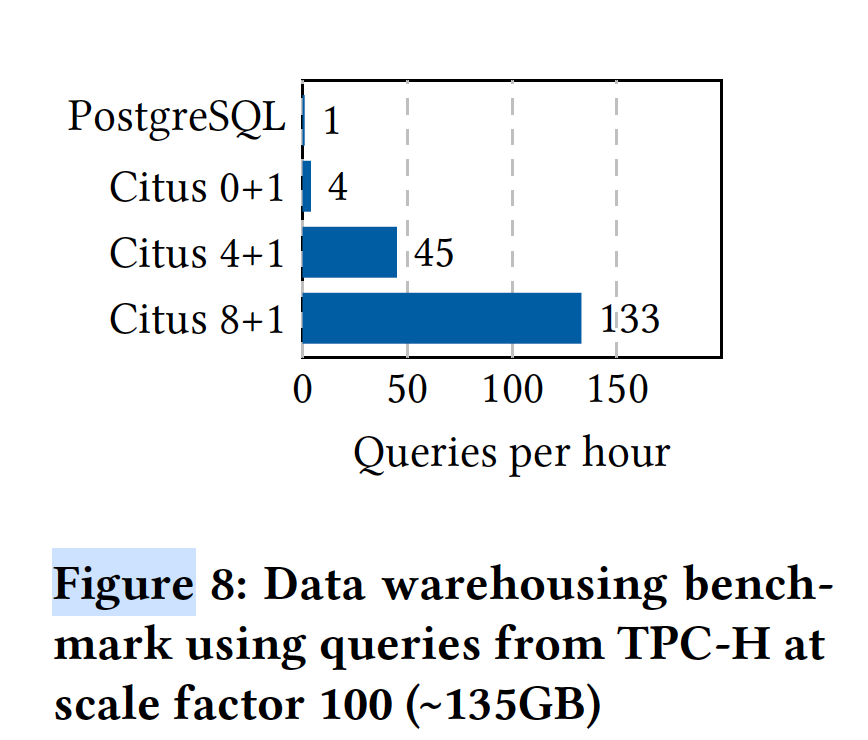
IO密集 -> CPU密集
CITUS CASE STUDY: VENICEDB
介绍了citus在微软的应用,管理了超PB的数据,满足以下需求(论文表达只有citus同时满足这些需求)

RELATEDWORK
- Vitess——有内置连接池、专注于MT和HC场景
- Greenplum/Redshift——同样基于PG,支持列存,在网络间shuffle数据加速join(citus这方面优化的没这么好)
- Aurora——存算分离,单机的优势,不赘述了
- Spanner/CockroachDB/Yugabyte——他们提供了全局snapshot,死锁采用wound-wait模式
- TimescaleDB——处理时序数据,因为hook不兼容所以不能和citus一起用,但是pg_pathman可以和citus一起用
CONCLUSIONS AND FUTUREWORK
- 尚未完全支持在分布式表上的 PostgreSQL 功能的支持。这些功能包括非亲和的相关子查询、递归 CTE 和不同表类型之间的逻辑复制。
- 我们也越来越多地看到用户使用混合数据模型,将小表保存在单个服务器上,只分布大表。针对这些场景进行自动化数据模型优化。
- Citus 正越来越多地用于更为专门的工作负载模式,例如 MobilityDB 和 Kyrix-S。针对这些工作负载,可以实现许多潜在的分布式查询优化。我们将探索使 Citus 本身具有可扩展性,以便更快地迭代这些优化。
