




 点击蓝字,关注我们
点击蓝字,关注我们

▍作者:朱赟 浙江大学
论文标题:GraphCLIP: Enhancing Transferability in Graph Foundation Models for Text-Attributed Graphs
原文链接:https://arxiv.org/abs/2410.10329
代码链接:https://github.com/ZhuYun97/GraphCLIP
录用会议:The ACM Web Conference (WWW) 2025
一、摘要
文本属性图(Text-Attributed Graphs, TAGs)是一种图结构数据,其中每个节点都包含原始文本信息。由于现实世界中存在大量丰富的文本节点特征,并且随着大语言模型(LLM)的快速发展,TAGs 在社交网络、推荐系统、引文网络等多个领域得到了广泛应用,受到学术界和工业界的高度关注。然而,当前的 TAG 方法仍面临两大主要挑战:(1)对标签信息的高度依赖;(2)跨域零样本或少样本的迁移能力不足。这些问题不仅限制了数据和模型规模的扩展,还由于高昂的人工标注成本和扩展方式的制约,阻碍了图基座模型的开发与应用。
为了解决上述挑战,本文提出了 GraphCLIP 框架,旨在通过一种自监督对比图-摘要预训练方法,学习具备强大跨域零样本/少样本迁移能力的图基础模型。具体而言,我们借助 LLM 生成并整理大规模的图-摘要对数据,并结合不变性学习机制设计自监督图-摘要预训练方法,以增强图基础模型的跨域零样本迁移能力。此外,对于少样本学习场景,我们设计了一种与预训练目标一致的新型图提示调优技术,用以缓解灾难性遗忘问题并降低学习成本。
大量实验证明,GraphCLIP 在零样本场景下的表现优于72B 参数量的大语言模型,在少样本场景下也超越了其他图提示学习方法。此外,在多种下游任务(如节点分类、链接预测等)上的评估结果进一步验证了 GraphCLIP 的通用性和鲁棒性。
二、动机
结合 LLMs 的 TAG 方法大致可以分为三类(图1所示)[1]:LLM 作为增强器(LLM as Enhancer)、LLM 作为预测器(LLM as Predictor)、LLM 作为对齐器(LLM as Aligner)。
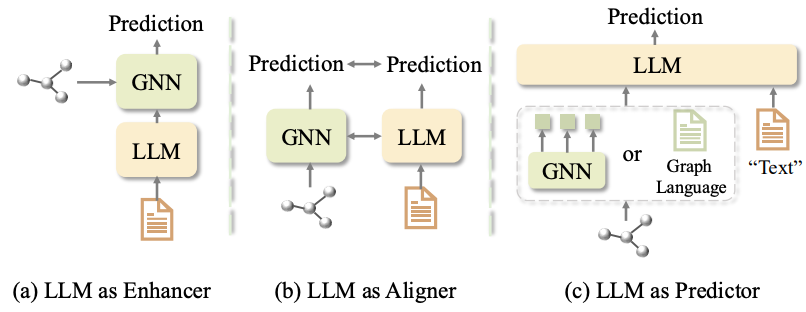
图1:TAG 方法分类
在“LLM 作为增强器”的范式中,核心思想是利用语言模型的能力来增强原始文本特征或生成高质量的节点表示。这种方法超越了传统的浅层嵌入方法(如词袋模型 BoW),能够捕捉更丰富的语义信息。例如,OFA[2] 和 ZeroG[3] 利用语言模型作为节点特征提取器,通过带标签的源数据预训练图模型,并结合复杂的图提示技术将其应用于目标数据。然而,这类方法存在一个显著的局限性:它们高度依赖高质量的标注数据。这种依赖不仅增加了人工成本,还限制了模型的扩展能力。根据规模扩展法则,缺乏大规模未标注数据的支持可能导致模型的通用性存在问题。
在“LLM 作为预测器”的范式中,研究的重点是如何将图数据转换为 LLMs 能够理解的格式。例如,GraphGPT[4] 和 LLaG[5]A 使用图神经网络(GNNs)将图数据编码为图标记,并训练额外的投影器,通过指令微调将这些标记映射到文本空间。尽管这种方法在某些任务上表现出色,但它同样需要目标数据的高质量标签。此外,最近的研究表明,这类方法在跨域零样本任务中的表现较差,尤其是在面对分布外数据时,模型的泛化能力显得不足。
在“LLM 作为对齐器”的范式中,研究的重点是将图和文本模态映射到共享的嵌入空间,从而实现跨模态的知识对齐。例如,ConGrat[6] 和 G2P2[7] 采用自监督的图-文本对比预训练方法,专注于在同一图内迁移预训练模型。然而,这些方法通常忽略了跨域或跨图的迁移能力,导致其在处理异源数据时表现有限。
总结来看,现有的 TAG 方法面临两个主要挑战:
(1) 对标签信息的高度依赖:大多数现有方法(如 ZeroG、OFA 和 LLaGA 等方法需要源数据的标签信息作为训练信号,这不仅导致高昂的人工成本,还限制了模型对大规模未标注数据的利用。根据规模扩展法则,这种依赖性会阻碍模型的泛化能力和性能的进一步提升。
(2) 跨域零/少样本迁移能力有限:理想的图基础模型应具备强大的跨域零样本能力,即能够在无需调整参数的情况下直接应用于目标数据并取得不错的性能。这一点类似于多模态领域的 CLIP、BLIP 等工作和 NLP 领域的 LLMs。然而,大多数现有方法在目标数据上的零样本部署中表现不佳。具体而言,它们要么无法进行零样本学习,因为需要使用目标数据的标签训练分类头以生成预测;要么由于预训练期间获取的可迁移知识不足而导致零样本性能较差。此外,在低资源场景(如少样本学习)中,如何有效利用目标数据中的少量训练样本并避免灾难性遗忘仍然是一个重大挑战。
三、方法
3.1 图-摘要对生成
在 TAG 领域,每个节点通常包含大量描述性文本。大多数现有的 TAG 方法利用这些文本信息与结构化数据共同预训练图模型;然而,这些方法高度依赖标签信息,且由于标注成本昂贵,限制了其可扩展性。此外,一些方法尝试从原始文本数据中设计自监督训练信号,但原始文本与图级信息之间仍存在显著差距,导致模型性能不佳且迁移能力有限。这些局限性阻碍了类似于 CLIP 和 BLIP 在多模态领域中图基础模型的发展。
为了解决上述挑战,我们充分利用大语言模型(LLMs)出色的摘要能力,生成与图相关的摘要,从而构建图-摘要对数据。具体而言,我们采用 GraphML 图标记语言[8],并精心设计提示模板(图2),以增强 LLMs 对输入图的理解能力。这一方法利用了 LLMs 在标记语言处理上的优势,将图结构数据转换为序列数据输入大模型。
在设计的模板中(图2),我们为节点内容定义了两个属性:标题和摘要。此外,还设立了一个用于描述边类型的属性。蓝色文本部分为占位符,实际应用中将被具体数据替换。通过使用该模板,我们能够无缝地将 TAG 转换为 LLMs 易于理解的格式。
考虑到系统的可扩展性,我们采用了带重启的随机游走采样器,从大规模图中采样子图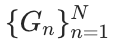 。这些子图随后被输入到提示模板(图2)和设计的指令(图3)中,使 LLMs 能够生成相应的图摘要
。这些子图随后被输入到提示模板(图2)和设计的指令(图3)中,使 LLMs 能够生成相应的图摘要 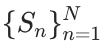 。在本研究中,我们选择 Qwen2-72B 作为图摘要生成器。结合实际中的未标注图数据,我们生成并整理了大规模的图-摘要对数据,涵盖学术、电子商务和社交等多个领域,总计超过2亿个 tokens。
。在本研究中,我们选择 Qwen2-72B 作为图摘要生成器。结合实际中的未标注图数据,我们生成并整理了大规模的图-摘要对数据,涵盖学术、电子商务和社交等多个领域,总计超过2亿个 tokens。

图2:图数据转化成序列数据的提示模板

图3:任务指令
3.2 自监督图-总结对比预训练
3.2.1信息编码
对于图-摘要对数据,我们采用不同的编码器处理各自模态的信息。然后,设计一种新颖的对比损失,将这些模态对齐到同一个子空间中。
图模态信息编码: 考虑到模型规模对图基础模型的涌现(emergence)和统一(homogenization)至关重要,我们使用容易 scale up 的 Graph Transformer(GTs)来编码图信息。给定一个子图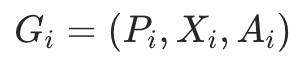 ,我们按如下方式编码图信息:
,我们按如下方式编码图信息:
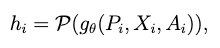
其中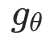 表示 Graph Transformer,例如 GraphGPS[9],
表示 Graph Transformer,例如 GraphGPS[9],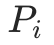 表示子图的位置嵌入,如 RWPE[10],
表示子图的位置嵌入,如 RWPE[10],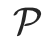 是均值池化函数,用于得到子图的图级编码
是均值池化函数,用于得到子图的图级编码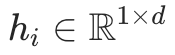 。
。
摘要文本模态信息编码: 为了将句子/文档级别的信息编码成紧凑且语义丰富的向量,我们使用句子级文本编码器:
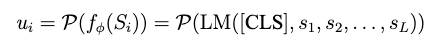
其中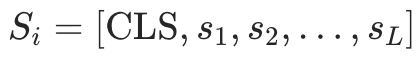 是子图
是子图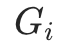 的摘要文本, 我们使用均值池化函数 对标记表征进行平均池化,作为文档级信息的摘要编码
的摘要文本, 我们使用均值池化函数 对标记表征进行平均池化,作为文档级信息的摘要编码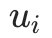 。在后续部分中,为简洁起见,后续省略 。
。在后续部分中,为简洁起见,后续省略 。
3.2.2图-摘要对比预训练
在获得图和摘要编码 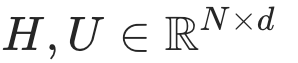 后,我们采用对比损失来对齐这两种模态。与之前的多模态预训练方法(如 CLIP)不同,不同图在各个领域之间的差异可能很大,因此捕捉图域中的可迁移或因果特征至关重要。为实现这一目标,我们引入不变性学习[11]来高效提取因果特征而非虚假关联特征。
后,我们采用对比损失来对齐这两种模态。与之前的多模态预训练方法(如 CLIP)不同,不同图在各个领域之间的差异可能很大,因此捕捉图域中的可迁移或因果特征至关重要。为实现这一目标,我们引入不变性学习[11]来高效提取因果特征而非虚假关联特征。
下面,我们首先回顾对比损失和不变性学习的概念。然后,我们阐述如何将它们结合起来解决图基础模型的挑战。
对比损失:

然而,这种损失对分布偏移不鲁棒,因为在对齐损失(alignment loss)中的期望算子无法保证不变特征,导致较差的可迁移性(附录 B)。为了解决这一困境,我们将不变性学习融入我们的方法中。
不变学习定义:

该方法严重依赖环境和下游标签,这与我们的自监督对比损失不兼容。为了解决这个问题,我们将不同的增强函数看作是不同环境,优化正样本对的 alignment loss 得到 invariant alignment loss(具体推导与解释可参考论文[12]中 Section 2.4),从而增强在不同图上的可迁移性和泛化能力:

上确界操作量化了在“最具挑战性”的增强下两种表示之间的差异,与公式6中描述的平凡期望相反。该方法使得不变对齐损失能够在不同域中生成一致的线性最优预测器,从而促进原对齐损失所缺乏的增强型OOD泛化和可迁移性。进一步分析和理论证明见论文附录C。
关于用对齐损失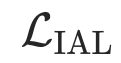 替换
替换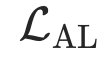 的一个重要问题在于估计
的一个重要问题在于估计 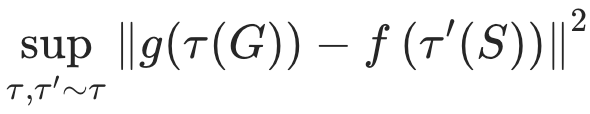 ,因为这需要遍历所有增强空间。为了有效地识别连续空间中的最坏情况,我们采用对抗训练来逼近上确界运算:
,因为这需要遍历所有增强空间。为了有效地识别连续空间中的最坏情况,我们采用对抗训练来逼近上确界运算:
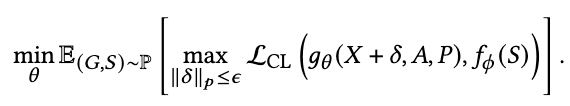
其中内循环优化损失以逼近最具挑战性的扰动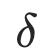 ,其幅度
,其幅度 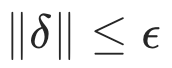 ,以确保其不会改变原始视图的语义标签。这里,我们仅在图编码上添加扰动。
,以确保其不会改变原始视图的语义标签。这里,我们仅在图编码上添加扰动。
整体预训练流程如下图所示:
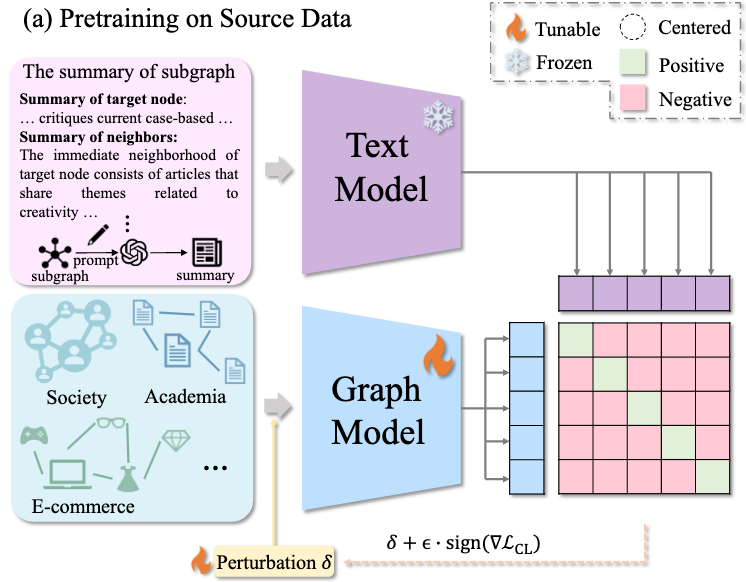
图4:预训练流程
3.3 目标数据上的模型迁移
3.3.1零样本学习
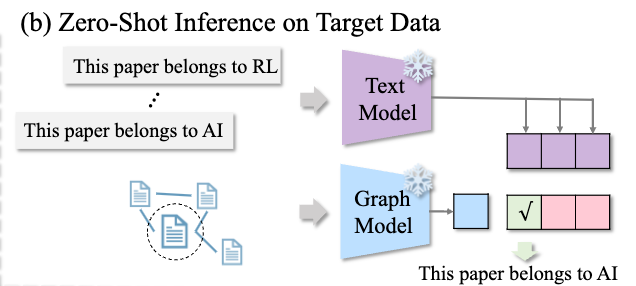
图5:零样本学习
通过上述方式进行预训练后,GraphCLIP 无需任何额外训练,可以直接部署在目标数据集上,即使用如图5所示的零样本推理。通过精心设计提示以包含目标标签信息。例如,针对引用网络,与标签信息相关的句子被表述为“This paper belongs to {class}”。具体的模板详见附录。形式上,零样本学习定义如下:
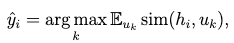
其中 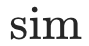 表示余弦相似度函数,与节点
表示余弦相似度函数,与节点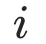 最相似的标签句子作为预测标签。
最相似的标签句子作为预测标签。
3.3.2少样本设置下的图提示微调
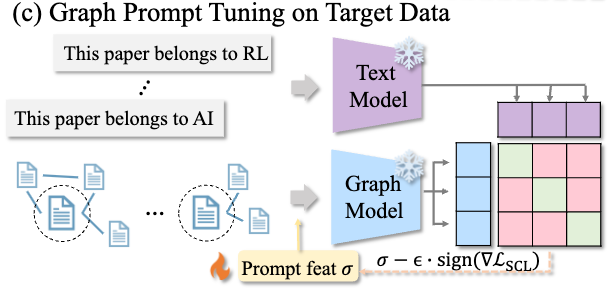
图6:少样本设置下的图提示微调
在低资源场景中,每类目标数据只有少量样本,有效利用这些数据同时防止过拟合和灾难性遗忘至关重要。在这项工作中,我们引入了一种新的图提示调优方法来应对这一挑战。
具体来说,在图提示微调过程中,文本和图模型都保持冻结状态,只允许有限的一组参数可学习。为了与我们的预训练目标对齐,我们引入了类似于预训练期间使用的扰动的可学习提示特征,并采用监督对比损失。最终,图提示调优的总损失如下:
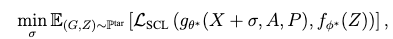
其中 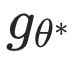 和
和 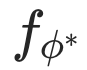 分别表示冻结的图和文本模型,
分别表示冻结的图和文本模型, 表示与标签相关的句子,
表示与标签相关的句子,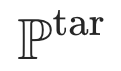 表示标记目标数据的分布。
表示标记目标数据的分布。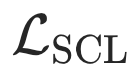 是监督对比损失,它将具有相同标签的对视为正样本,不同标签的对视为负样本。图提示学习后,目标测试数据的评估按照上节中概述的方式进行。
是监督对比损失,它将具有相同标签的对视为正样本,不同标签的对视为负样本。图提示学习后,目标测试数据的评估按照上节中概述的方式进行。
四、实验结果
4.1 节点分类
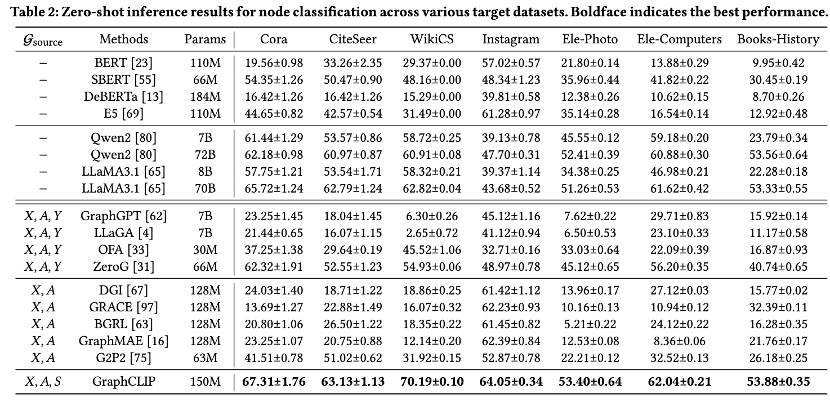
从上表可以发现,大语言模型(如 LLaMA3.1-70B 和 Qwen2-72B)在零样本场景表现优异,但难以有效利用结构化信息,在 WikiCS 等数据集上的准确率较低。其次,LLaGA 和 GraphGPT 通过图指令调优尝试引入图结构信息,却易过拟合源数据,导致泛化能力不足。OFA 和 ZeroG 依赖标签预训练,但因标签不匹配和未能捕捉因果特征,跨域迁移能力受限。相比之下,本文方法结合自监督训练和不变性学习,显著提升了跨域和域内迁移能力,例如在 WikiCS 上达到70.19%的准确率,较 ZeroG 提升超15%。综上,本文方法克服了现有方法的诸多局限,展现出卓越的迁移和泛化性能,为图学习跨域任务提供了新解决方案。
4.2 链接预测
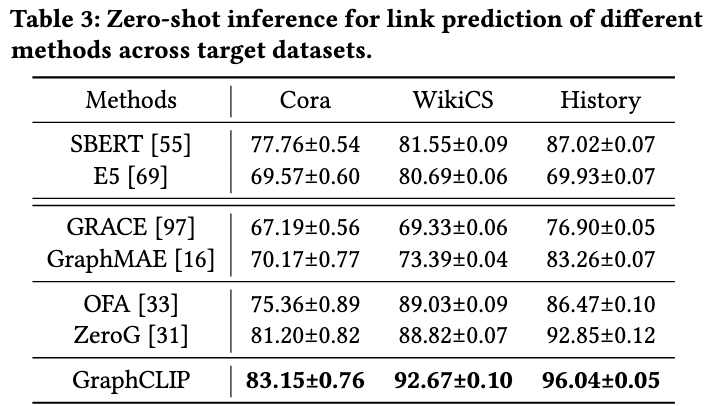
上表显示 SBERT 在零样本链接预测任务中表现优异。ZeroG 基于 SBERT,通过 LoRA 微调以更好地整合结构信息,进一步提升性能。相比现有方法,本文方法在所有目标数据集的零样本迁移条件下实现了最佳链接预测结果。这不仅验证了自监督预训练任务的有效性,也展示了框架的多功能性和先进性。
4.3 图提示学习
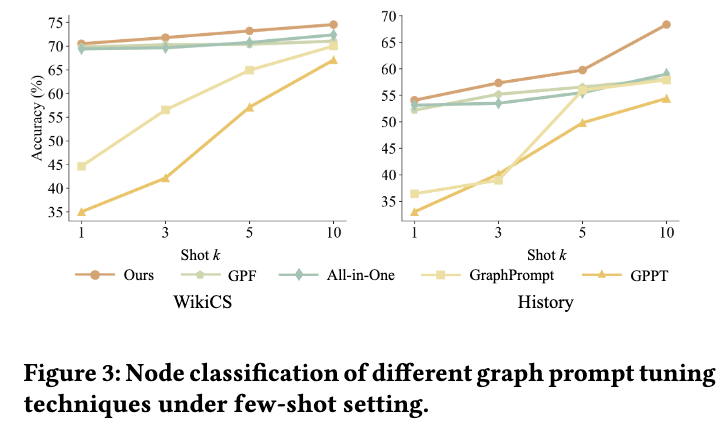
从上图可见,GPPT 和 GraphPrompt 在1-shot 和3-shot 设置下表现较差,主要这些方法需要额外训练 class tokens,无法利用文本模型直接推理。然而,随着样本数增加至5-shot 和10-shot,这些方法的性能逐渐接近其他基线。
相比之下,GPF 和 All-in-One 直接在图空间操作,可以利用对齐的文本模型,但由于训练目标与预训练目标不一致,偶尔出现负迁移。例如,在1-shot 设置下,GPF 和 All-in-One 的准确率分别为69.82%和69.42%,低于0-shot 的70.19%。
本文提出的提示调优方法通过统一训练目标,有效缓解灾难性遗忘并降低学习成本,在各种少样本场景下均表现优异,超过其他方法。这进一步验证了方法设计的有效性。
4.4 源数据上的探索
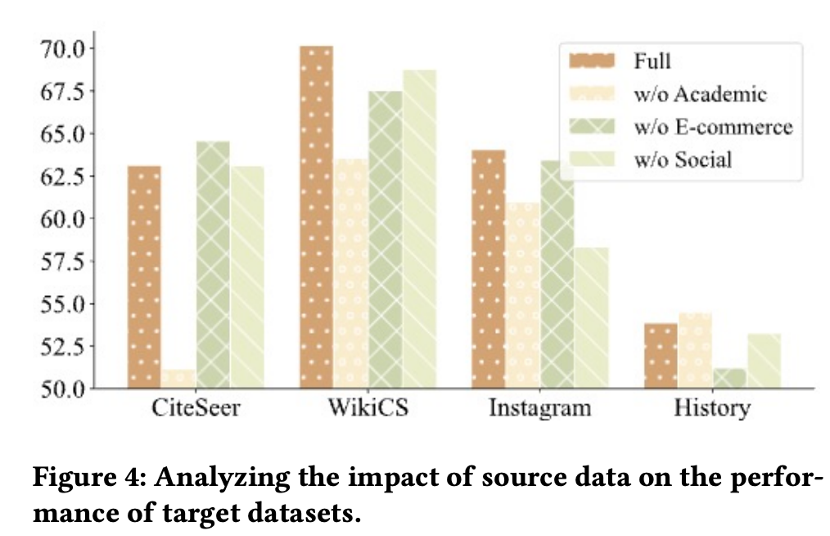
本节研究了源数据选择对跨域和域内迁移能力的影响。通过屏蔽不同源域,在 CiteSeer(学术)、WikiCS(维基)、History(电商)和 Instagram(社交)数据集上评估性能。其中,“Full”表示使用全部源数据;“w/o Academia”排除了学术数据;“w/o E-commerce”排除了电商数据;“w/o Social”排除了社交数据。
上图实验结果表明:首先,更多源数据提升了跨域迁移能力,例如“Full”在 WikiCS 上表现最佳。其次,域内源数据对域内迁移至关重要,“w/o Academia”在 CiteSeer 和“w/o E-commerce”在 History 上的表现显著逊色于“Full”。最后,虽然整合所有领域数据可能略微影响某些域内迁移,但整体性能有所提升。因此,本文选择使用全部源数据。未来研究将探索更复杂的数据组合,以更好地平衡不同源域。
4.5 模型规模分析
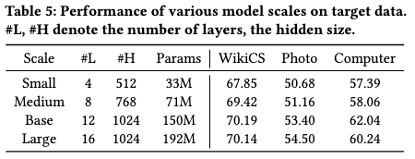
本节将对模型规模的影响展开研究。针对图模型,我们构建了四种规模:Small(4层,隐藏层512)、Medium(8层,768)、Base(12层,1024)和 Large(16层,1024)。上表显示,Base 模型的性能优于较小的模型,归因于参数规模的优势。然而,Large 模型虽在部分情况下略有提升,但伴随显著的计算开销,且在某些数据集上表现下降。因此,综合考虑性能与效率,我们选用 Base 模型作为主要实验配置。
4.6 消融实验

本节将逐一消融 GraphCLIP 的不同组件:“w/o Summary”使用原始文本代替生成摘要;“w/o Freeze”不解冻文本模型;“w/o IL”移除不变性学习。
上表实验结果表示:生成摘要对零样本迁移至关重要。原始文本缺乏结构信息且可能含噪,导致性能下降,例如“w/o Summary”在 Photo 和 Computers 数据集上分别仅为41.65%和46.26%,比 GraphCLIP 低超10个百分点。“w/o Freeze”在 WikiCS 和 History 上的表现最差,分别为58.92%和29.40%,表明全量微调导致过拟合。“w/o IL”在大多数数据集上逊色于 GraphCLIP,说明不变性学习显著提升了迁移能力。
五、总结
本章提出了 GraphCLIP 框架,旨在提升图基础模型(Graph Foundation Models, GFMs)在低资源环境中的迁移能力。为应对这一挑战,GraphCLIP 从数据和算法两个方面进行了深入设计。
在数据层面,构建并整理了一个大规模图-摘要配对数据集,为模型提供丰富的训练资源。算法方面,提出了一种对比图-摘要预训练方法,并结合不变性学习技术,以增强模型的迁移表现。此外,设计了一种全新的图提示优化策略,该策略与预训练任务高度契合,有效缓解了模型在迁移过程中可能遇到的灾难性遗忘问题。
在零样本和少样本学习的应用场景中,GraphCLIP 均表现出优于现有方法。这些结果表明,构建一个高度通用且能够高效适应实际应用场景的图基础模型具有巨大潜力。
[1]Li Y, Li Z, Wang P, et al. A survey of graph meets large language model: progress and future directions[C]//Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 2024: 8123-8131.
[2] Liu H, Feng J, Kong L, et al. One For All: Towards Training One Graph Model For All Classification Tasks[C]//The Twelfth International Conference on Learning Representations.
[3] Li Y, Wang P, Li Z, et al. Zerog: Investigating cross-dataset zero-shot transferability in graphs[C]//Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2024: 1725-1735.
[4] Tang J, Yang Y, Wei W, et al. Graphgpt: Graph instruction tuning for large language models[C]//Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2024: 491-500.
[5] Chen R, Zhao T, JAISWAL A K, et al. LLaGA: Large Language and Graph Assistant[C]//Forty-first International Conference on Machine Learning.
[6] Brannon W, Kang W, Fulay S, et al. ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings[C]//Proceedings of TextGraphs-17: Graph-based Methods for Natural Language Processing. 2024: 19-39.
[7] Wen Z, Fang Y. Augmenting low-resource text classification with graph-grounded pre-training and prompting[C]//Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2023: 506-516.
[8] Brandes U, Eiglsperger M, Lerner J, et al. Graph markup language (GraphML)[J]. 2013.
[9] Rampášek L, Galkin M, Dwivedi V P, et al. Recipe for a general, powerful, scalable graph transformer[J]. Advances in Neural Information Processing Systems, 2022, 35: 14501-14515.
[10] Dwivedi V P, Luu A T, Laurent T, et al. Graph Neural Networks with Learnable Structural and Positional Representations[C]//International Conference on Learning Representations.
[11] Arjovsky M, Bottou L, Gulrajani I, et al. Invariant risk minimization[J]. arXiv preprint arXiv:1907.02893, 2019.
[12] Zhu Y, Shi H, Zhang Z, et al. Mario: Model agnostic recipe for improving ood generalization of graph contrastive learning[C]//Proceedings of the ACM Web Conference 2024. 2024: 300-311.
·END·

欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
