




作者: 宋昭 https://zhuanlan.zhihu.com/p/16505194635
MySQL 从8.0开始先后支持了instant add column
趁着假期,梭了一把,ibdNinja,一个提供各种维度解析,分析.ibd的工具,欢迎试用。
Github传送门:ibdNinja
ibdNinja
目录
1. ibdNinja 主要功能
2. ibdNinja 用法示例
3. 重点介绍:解析包含instant add/drop columns的record示例
4. 限制
1. ibdNinja 功能
1. 解析SDI
从ibd文件的SDI(Serialized Dictionary Information)中提取、解析出该文件包含的所有表及其索引的数据信息。
2. 动态解析任意包含多版本表定义Table的Record *
基于解析出的字典信息,ibdNinja支持解析并打印文件中任一table的任一index的任一page中的任一Record(支持解析所有列类型)。并且能够动态适配解析同一张表在经过多次 instant add column 和 instant drop column 操作后,不同表定义版本records共存情况下的任意record。
详情及示例在本文[第3节]
3. 多维度数据分析
借助Record解析能力,支持从Record、Page、Index到Table级别的数据分析,计算并展示多维统计信息:
Record级别:
- Record的总字节大小(header + body)、字段数及是否包含deleted mark。
- Header的具体十六进制内容。
- 每个字段(包括用户定义列,系统列,instant dropped列)的详细信息,包括字段名、字段字节大小、字段类型及字段具体内容的十六进制打印。
Page级别:
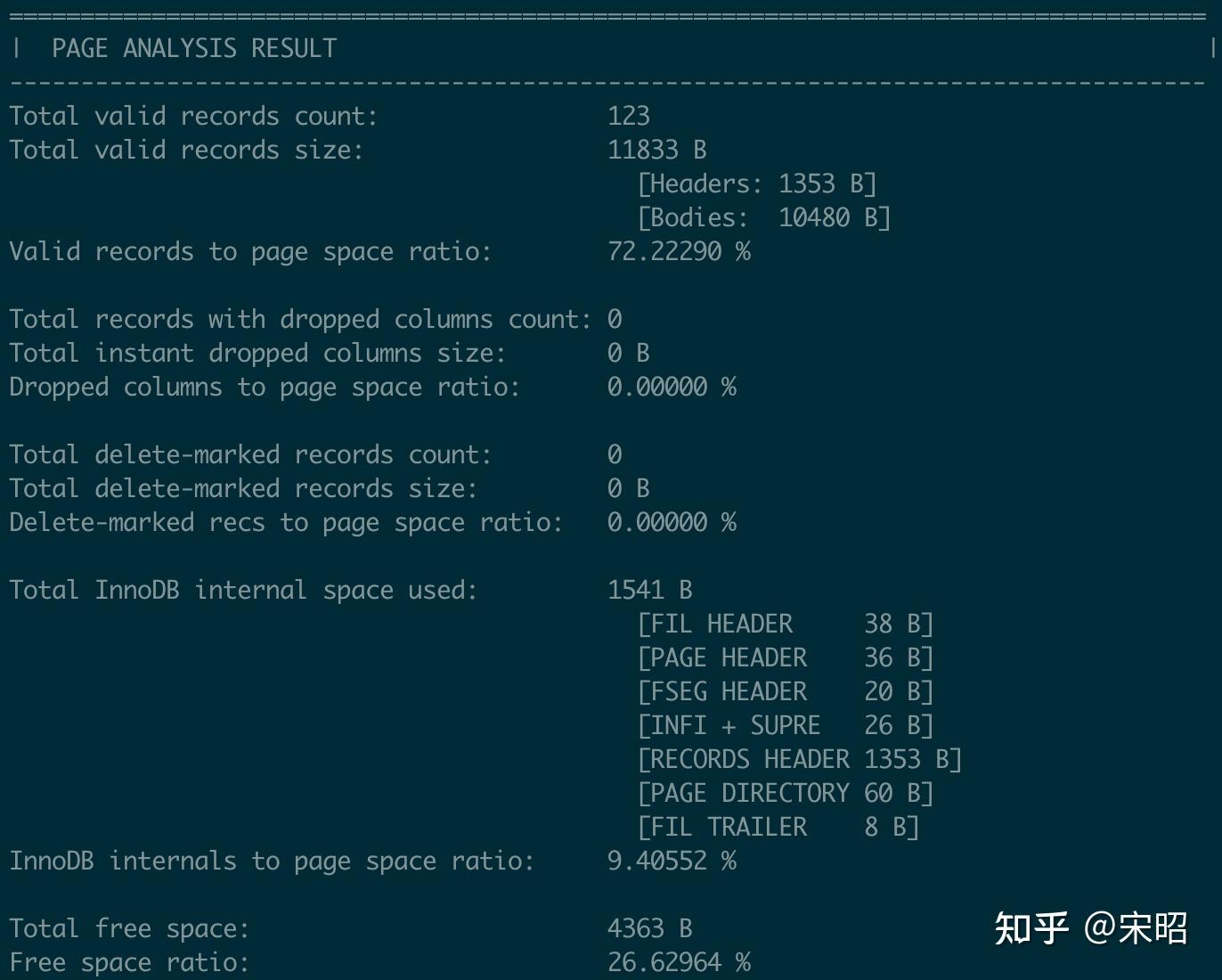
- Page中合法record的数量、总大小及page空间占比。
- 含有
instant dropped column的记录数,及这些已经dropped但依旧存在且占用空间的列的总大小及page空间占比。 - Deleted mark的record数量、总大小及page空间占比。
- Page中被InnoDB内部使用(如Page header,record headers,page directory等)的空间大小及其占比。
- Page中的空闲空间大小及其占比。
Index级别:
- 针对某一索引,从root Page开始逐level逐page分析,聚合所有page的统计信息,分为非叶子层级和叶子层级分别展示(统计项类似Page级别的统计)。
Table级别:
- 针对某张表,从其主索引开始,逐个索引分析,展示该表所有索引的统计信息。
4. 打印索引每层的leftmost page number
支持打印指定索引每一层的leftmost page number,方便用户通过他们对该索引逐level逐page地手动分析,或打印所有记录。
5. [TODO] 修复ibd文件损坏
因为ibdNinja已经支持解析record,所以对于Index page损坏的ibd文件,可以很容易的从page中删除损坏的records或者从Index中删除损坏的pages,尝试最大程度修复文件
2. ibdNinja 用法示例
编译非常简单,直接在当前目录下执行make即可
1. 帮助信息(--help, -h)
2. 打印ibd文件中的表及索引信息(--list-tables, -l)
以解析系统表空间文件mysql.idb为例,使用--file, -f 后,可以看到:
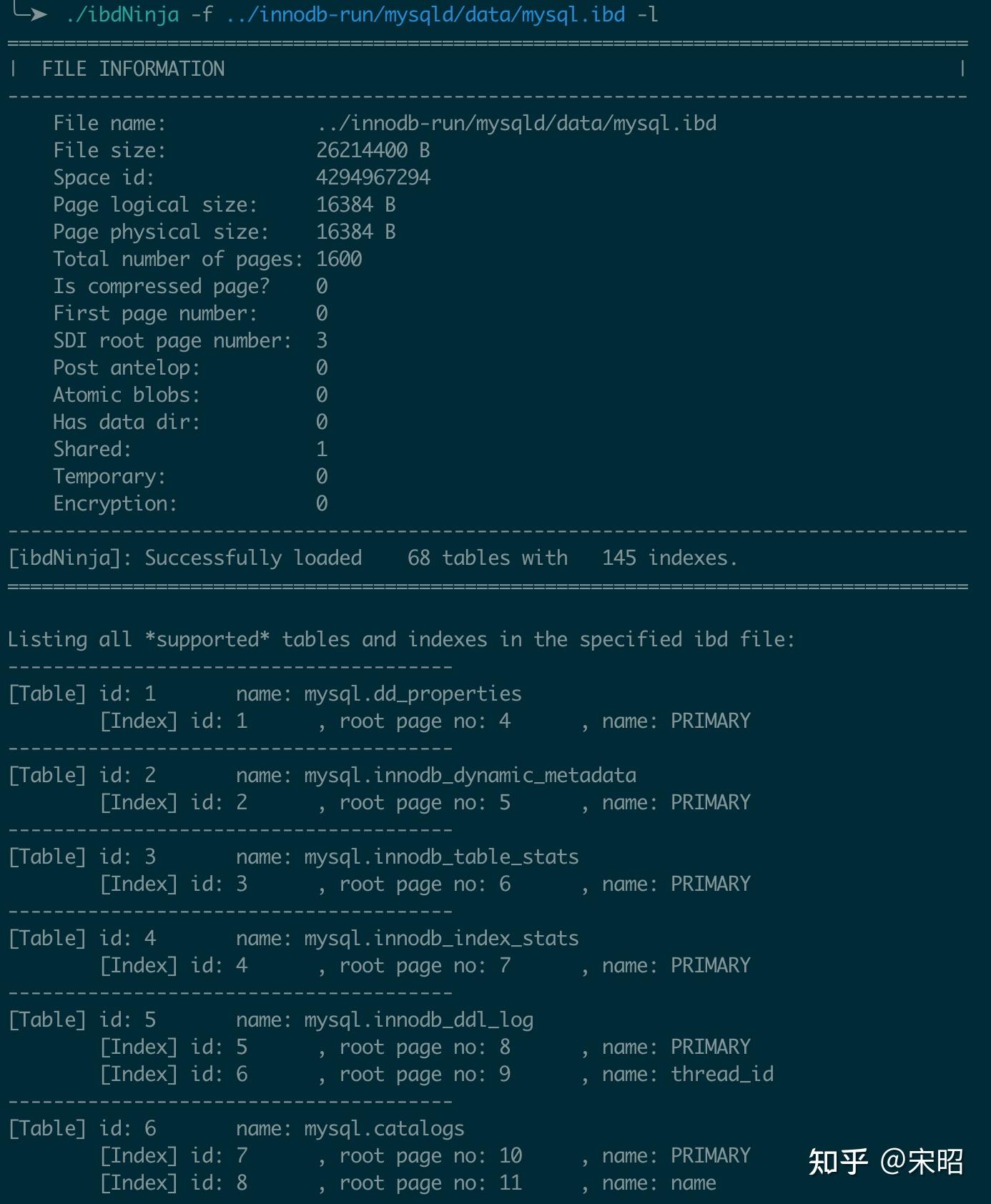
- ibd文件的概括信息,成功解析并加载数据字典的表及索引的个数
- ibd文件包含的所有表的表ID及表名
- 对于每一张表,其包含的所有的索引的ID,root page number及索引名
有了这些信息就可以使用其他参数进一步探索这个ibd文件了
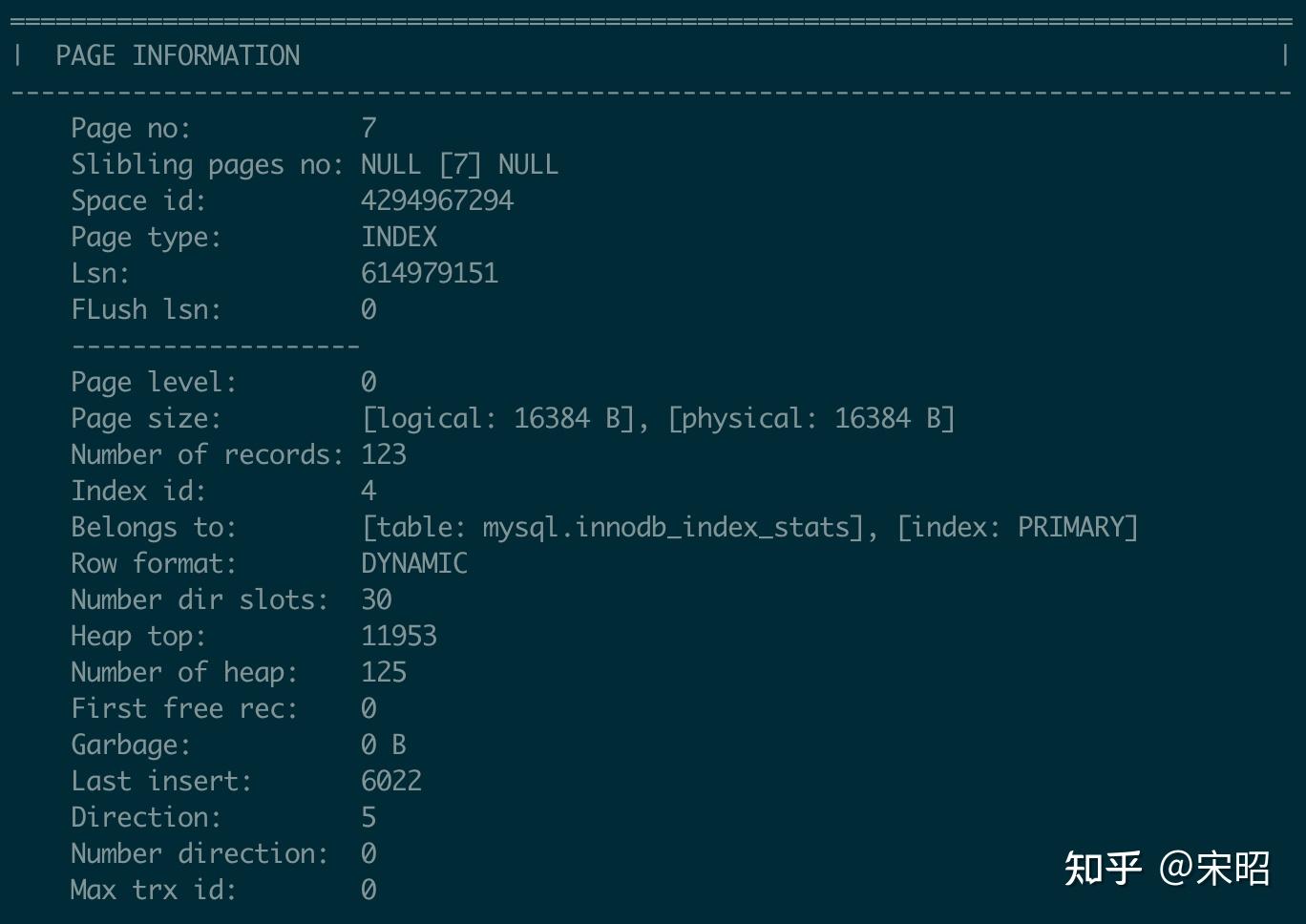
3. 解析并打印的指定Page(--parse-page, -p PAGE_ID)
同样以mysql.ibd为例,我们尝试解析其中的表mysql.innodb_index_stats的PRIMARY index的root page(上一个示例可以看到其root page no 为7),
执行
./ibdNinja -f ../innodb-run/mysqld/data/mysql.ibd -p 7输出包含3部分:
- Page的概括信息,比如slibling pages no 可以知道该page的左及右page no,Belongs to可以知道该page数据那个索引,Page leve可以知道该Page所处的层数等等
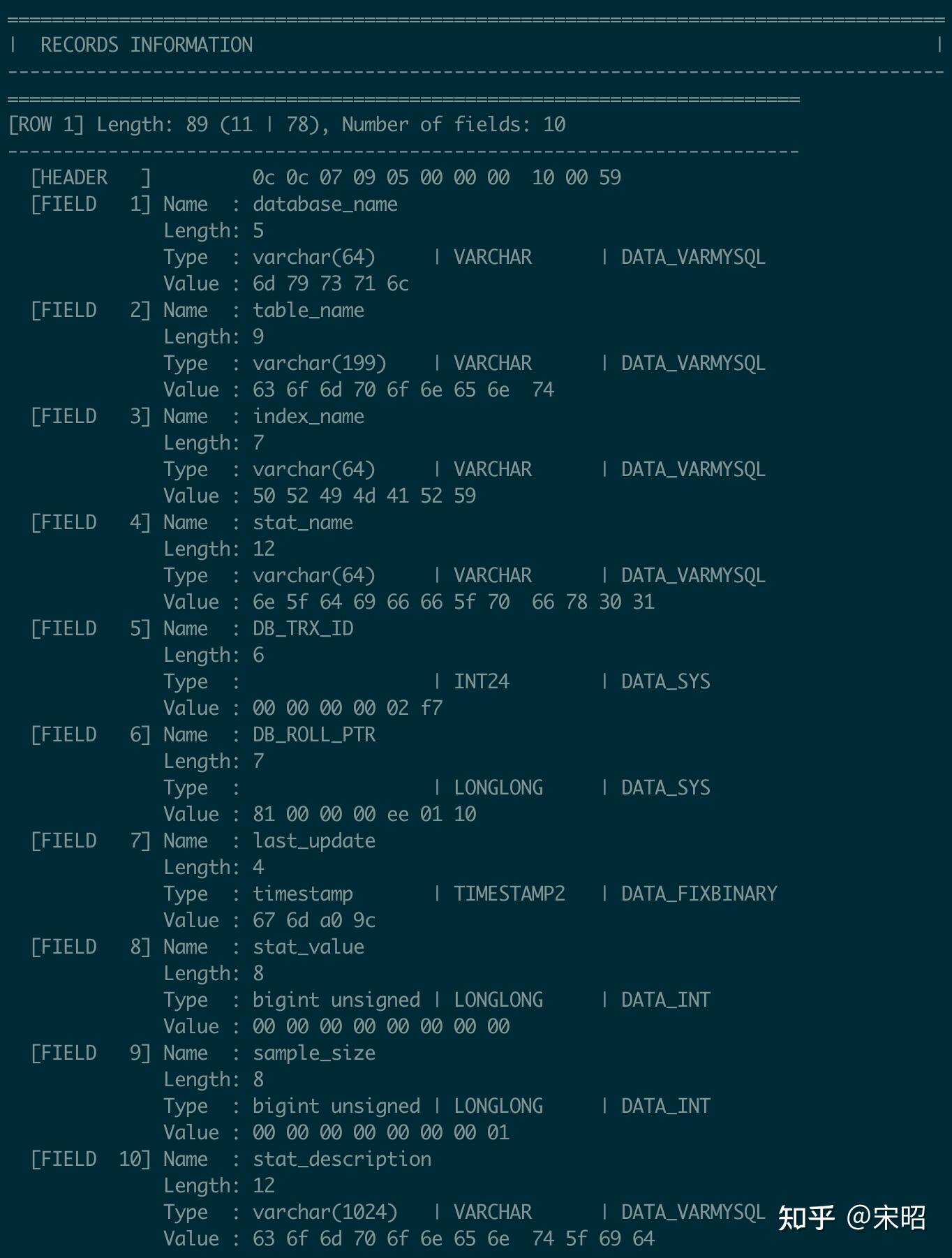
- Page中每一条record的详细信息,比如下图是其中一条record的信息,可以看到它的Length是89B,其中header是11B,body是78B,包含10个fields,然后是Header的11个字节的16进制打印,接着是每一个field的详细信息,如name,length,type及16进制的详细value打印
- Page 分析信息总结,包含所有valid的records个数,总大小及占比,instant dropped columns及delete marked record的个数,总大小及占比,InnoDB内部使用空间详情及大小占比,page空闲空间大小及占比
4. 分析指定索引(--analyze-index, -i INDEX_ID)
同样以mysql.ibd为例,我们先通过示例2的--list-table, -l 命令拿到其包括的表信息,这里我们以其中包含的表mysql.tables为例:
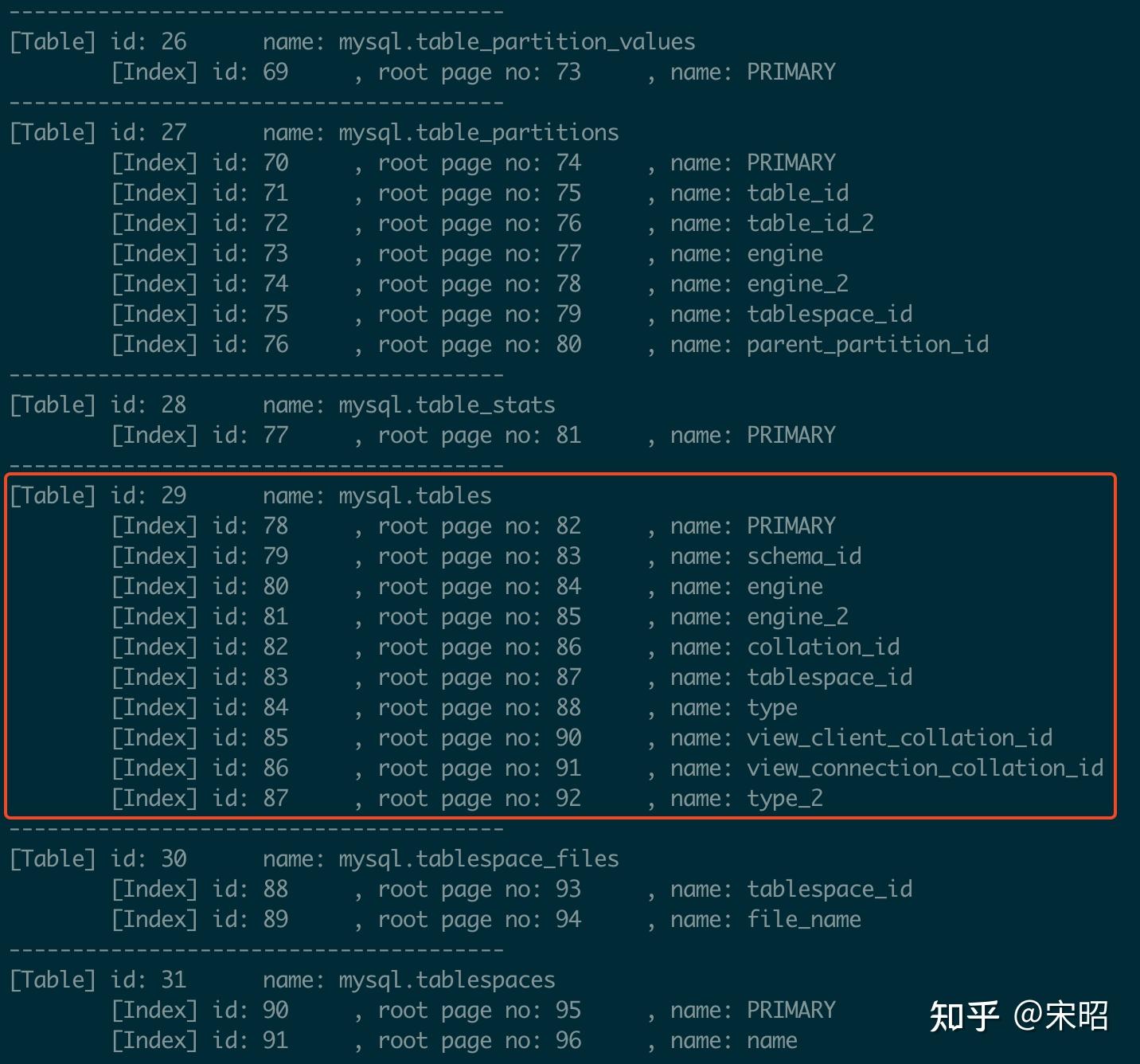
可以看到表mysql.tables的ID为29,包含10个索引,我们以PRIMARY index为例,其ID为78,我们来分析这个索引:
执行
./ibdNinja -f ../innodb-run/mysqld/data/mysql.ibd -i 78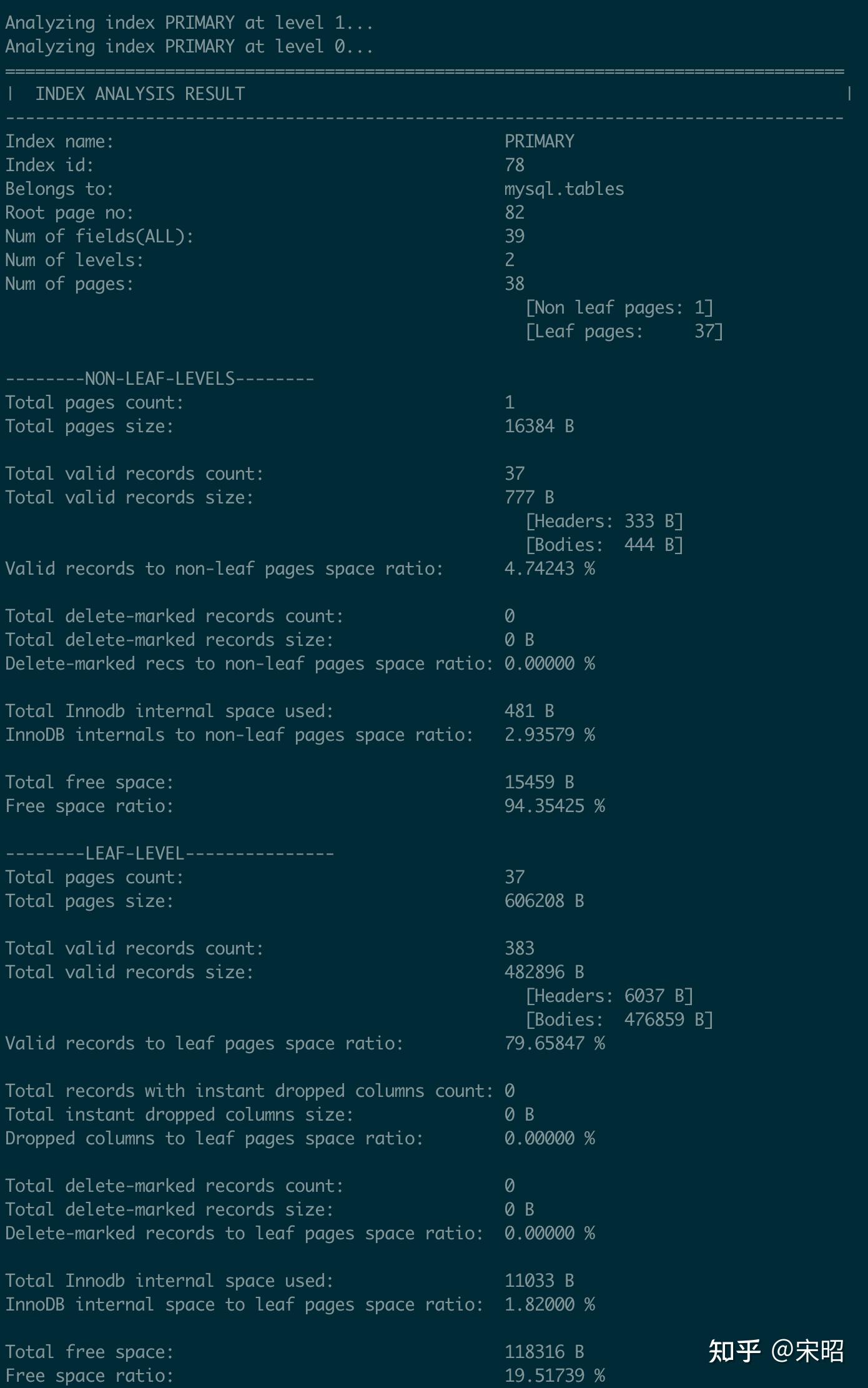
可以看到,ibdNinja从PRIMARY index的root page开始逐Level逐page遍历分析,最后汇总了该索引的分析信息,如上图所示:
- 首先是一些概括信息,如名称,包含层数,page数等
- 接着是对Non-leaf levels的统计(如page个数,record个数,各种占比等等)
- 最后是对Leaf level的统计(如page个数,record个数,各种占比等等)
5. 分析指定表(--analyze-table, -t TABLE_ID)
同样以mysql.idb为例,首先执行--list-table, -l拿到表及其索引信息,还是以上面的表mysql.tables为例,我们看到这张表的ID为29,那么就可以执行
./ibdNinja -f ../innodb-run/mysqld/data/mysql.ibd -t 29该命令会依次分析mysql.tables包含的10个索引,并打印他们的统计信息,这里就不展示了,每个索引的统计信息结构同--analyze-index, -i展示一样
6. 打印指定索引每一层的leftmost page no(--list-leafmost-pages, -e INDEX_ID)
同样以mysql.idb为例,通过上面的示例我们知道表mysql.tables的PRIMARY index的ID为 78,那么我们就可以通过--list-leafmost-pages, -e INDEX_ID来拿到该索引每一层的leftmost page no
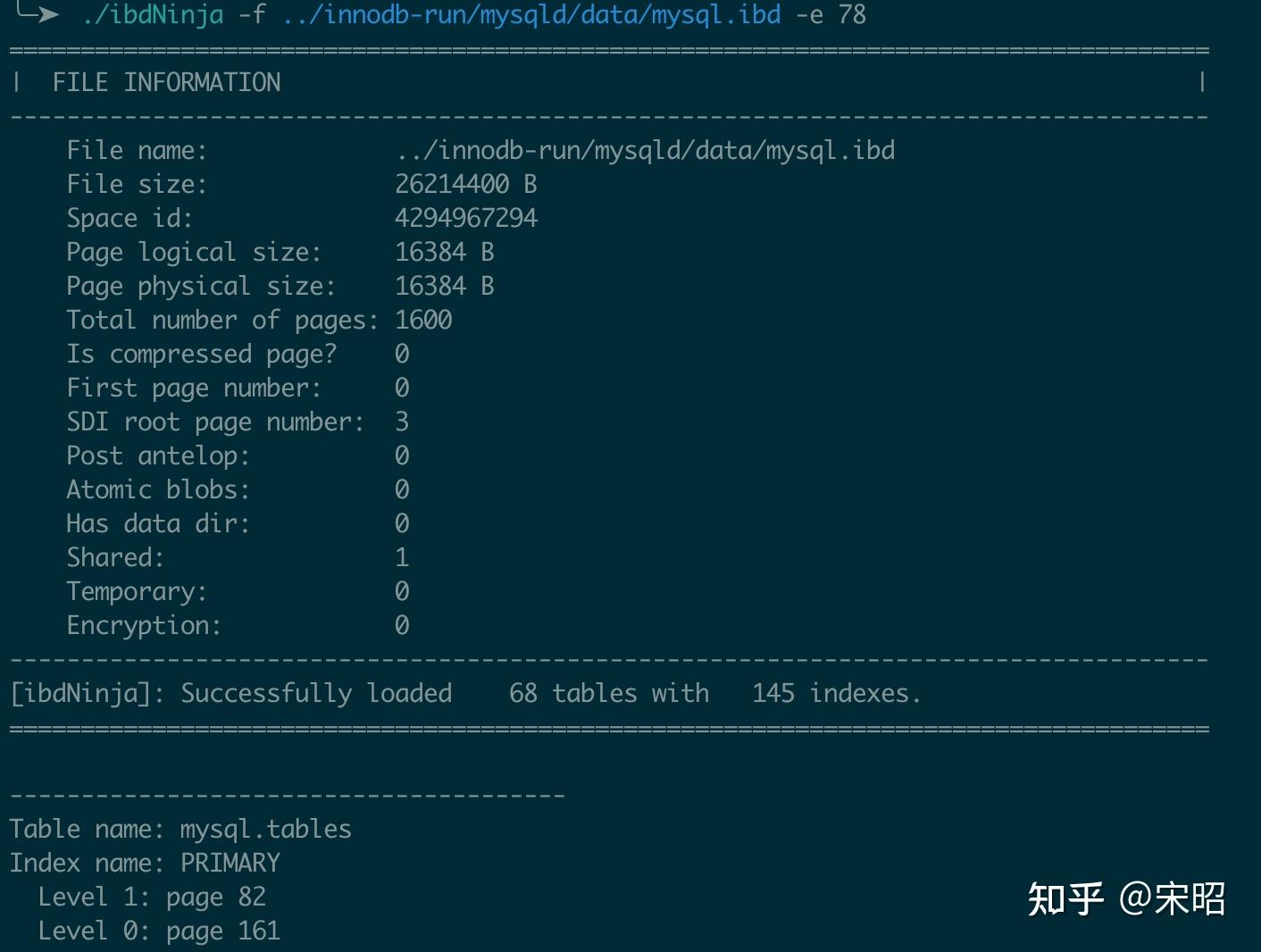
可以看到该索引有2层,level 1的leftmost page no是82,level 0(leaf level)的leftmost page no的161,之后我们就可以使用前面展示的--parse-page, -p PAGE_NO来打印这些page的详细信息,并从中拿到Slibling pages no,方便接着解析其左,右page,完成整个Index的遍历
注:--parse-page, -p PAGE_NO 会打印page中的所有record详细信息,这通常会很多,如果想跳过打印record信息,可以额外使用--no-print-record, -n来跳过,如-p 161 -n
3. 重点介绍:解析包含instant add/drop columns的record示例
我们首先创建一张表:
CREATE TABLE `ninja_tbl` (
`col_uint` int unsigned NOT NULL,
`col_datetime_0` datetime DEFAULT NULL,
`col_varchar` varchar(10) DEFAULT NULL,
PRIMARY KEY (`col_uint`)
) ENGINE=InnoDB;基于当前表定义(V1)插入一条record:
INSERT INTO ninja_tbl values (1, NOW(), "Row_V1");接着我们通过ALTER TABLE对该表新增两列:
ALTER TABLE ninja_tbl ADD COLUMN col_datetime_6 datetime(6);
ALTER TABLE ninja_tbl ADD COLUMN col_char char(10) DEFAULT "abc";接着基于当前表定义(V2)插入一条record:
INSERT INTO ninja_tbl values (2, NOW(), "Row_V2", NOW(), "ibdNinja");接着再通过ALTER TABLE对该表Drop两列
ALTER TABLE ninja_tbl DROP COLUMN col_varchar; ALTER TABLE ninja_tbl DROP COLUMN col_char;
最后基于当前表定义(V3)插入一条record
INSERT INTO ninja_tbl values (3, NOW(), NOW());通过上面的操作,我们对表ninja_tbl构造了3种不同的表定义并基于每一种表定义插入了一条数据,现在我们通过使用ibdNinja来尝试解析这3条record,因为只有3条数据,所以ninja_tbl的主键索引肯定只有一个page(root number 4),我们直接使用-p命令来解析,我们跳过其他输出只关注3条record的解析:
- 先看Record 1
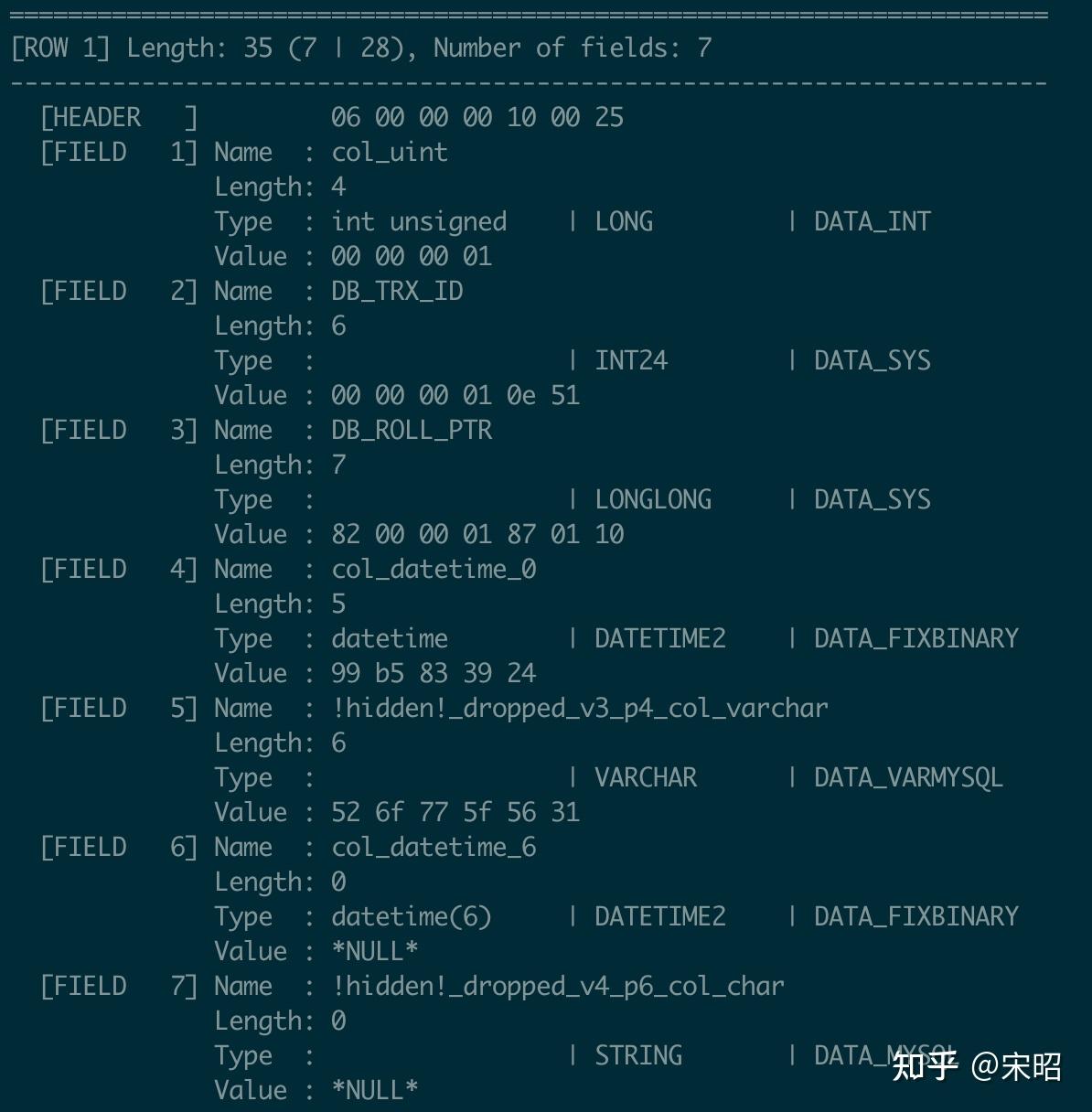
FIELD 1 (col_uint): 值为1,是我们在表定义V1插入的数据,
FIELD 5 (col_varchar): 是V1定义的,可以看到这条record的FIELD 5是有值的,但名字是!hidden!_dropped_v3_p4_col_varchar, 因为这列在V3被instant drop掉了(但这条record 1只是对外隐藏了它,实际这列在page中依旧存在)
FIELD 6 (col_datetime_6): 是在V2新增的,所以record 1肯定不会有值,可以看到它的length是0
FIELD 7 (col_char): 是在V2新增V3 drop的,所以record 1同样不会有值
- 再看Record 2
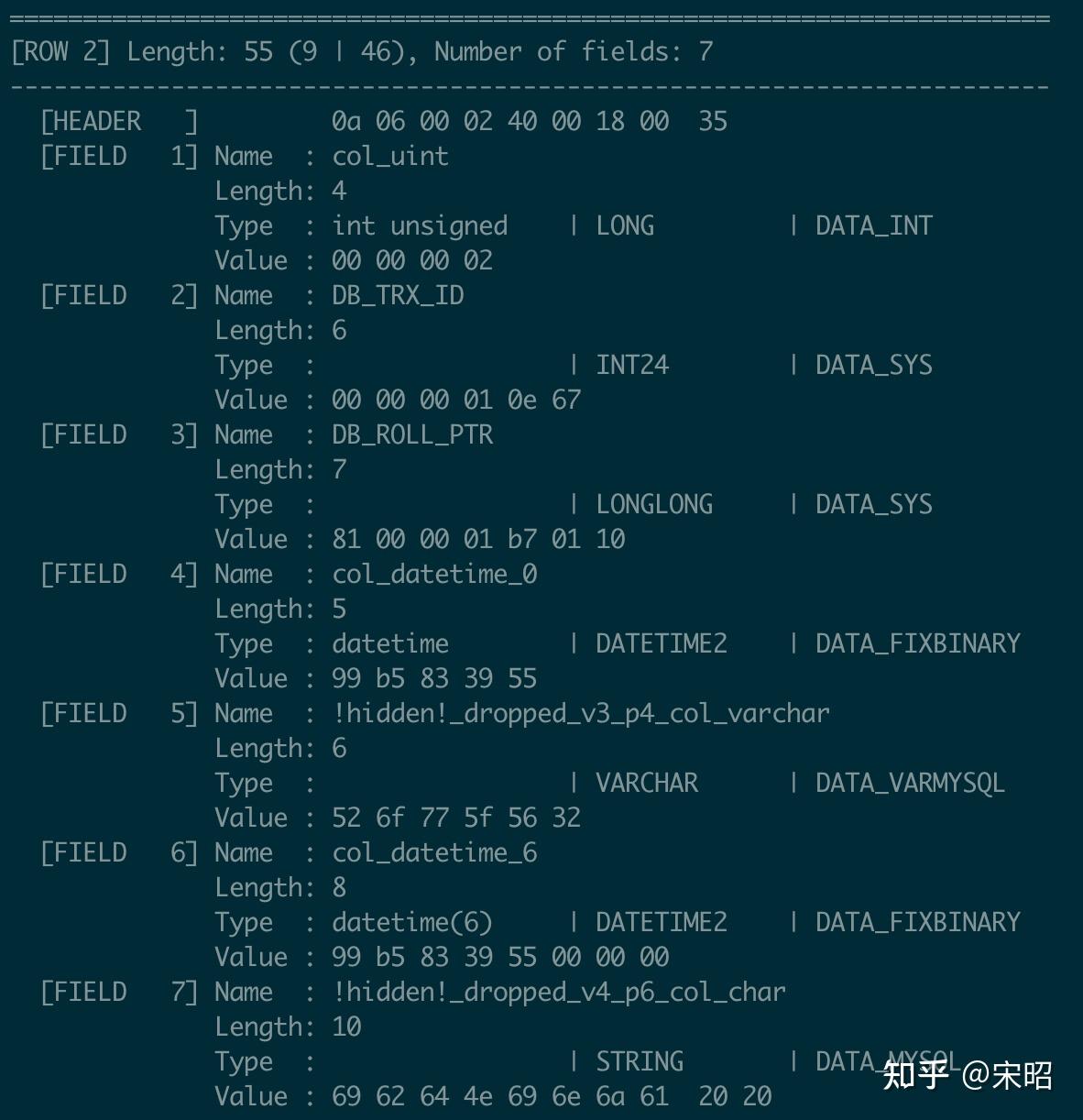
FIELD 1 (col_uint): 值为2,是我们在表定义V2下插入的
FIELD 5 (col_varchar): 是在V1定义V3被drop的列,record 2是在drop前插入的,所以该列包含值
FIELD 6 (col_datetime_6): 是在V2新增的,所以record 2该列同样包含值
FIELD 7 (col_char): 是在V2新增V3 drop的,所以record 2该列同样包含值
- 再看Record 3
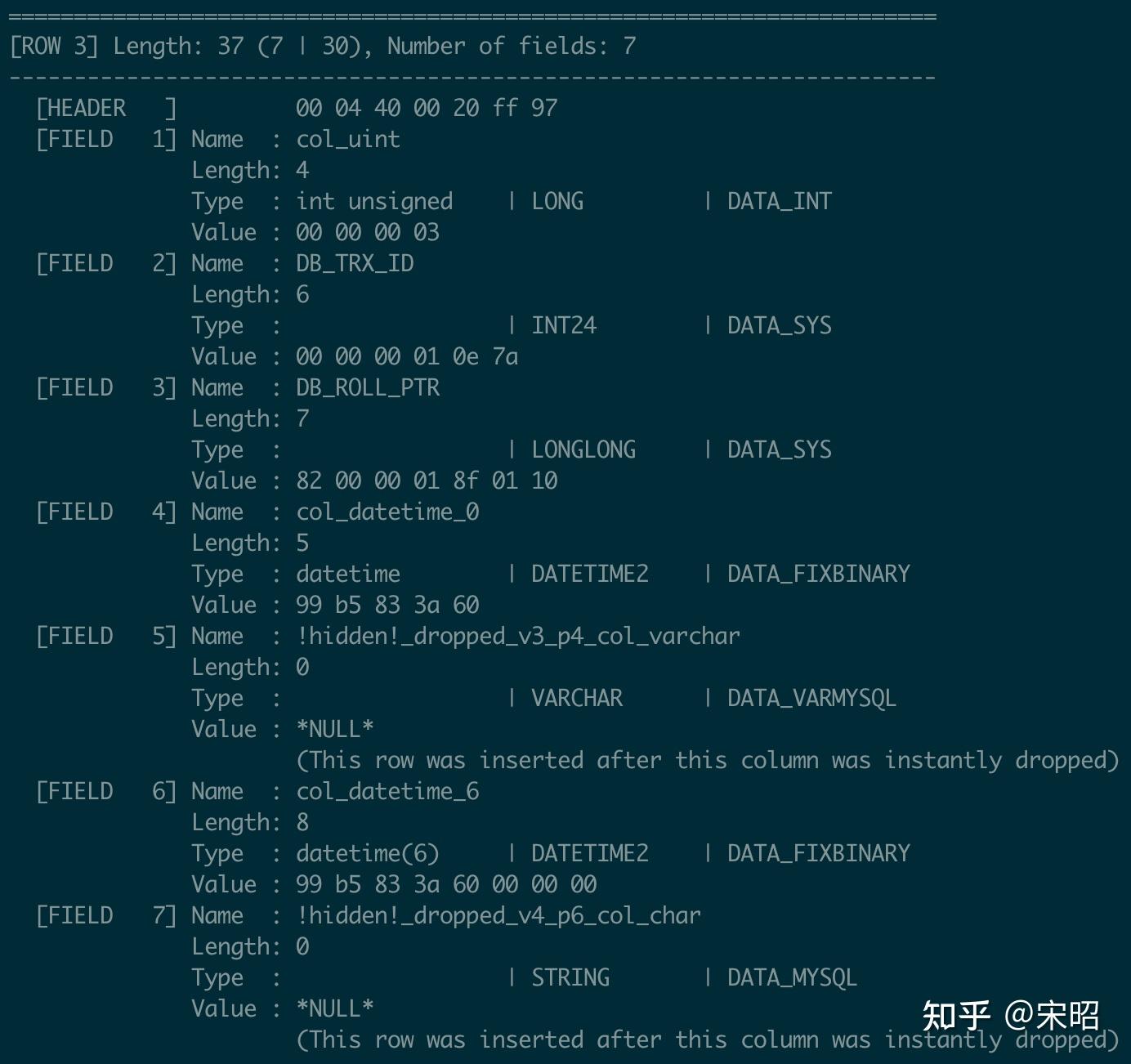
FIELD 1 (col_uint): 值为3,是我们在表定义V3下插入的
FIELD 5 (col_varchar) 和 FIELD 7 (col_char): 都在V3下都被drop了,而record 3是在drop之后插入的,所以可以看到它的这两列都是空值。
- 最后我们来看对于该page的分析结果:
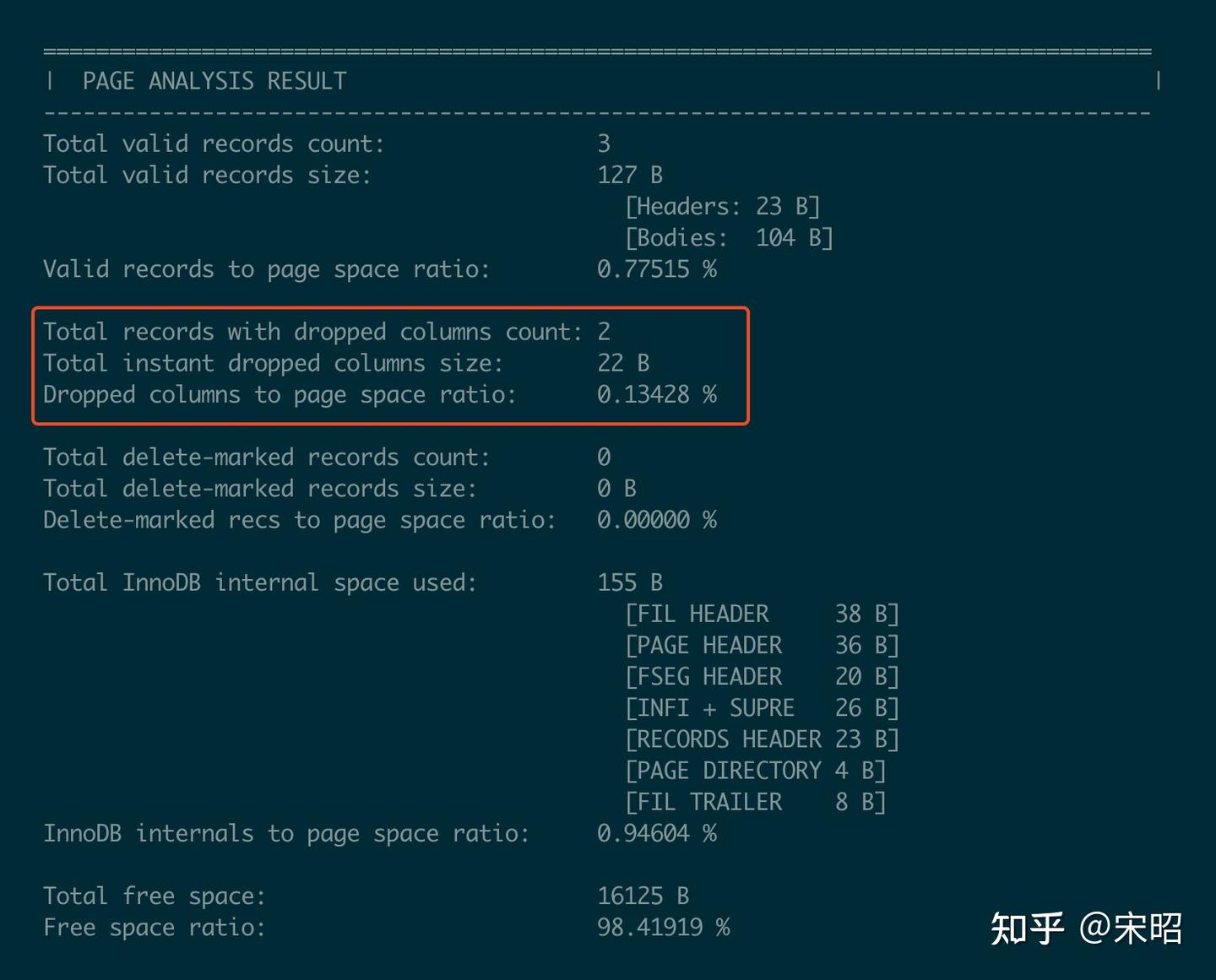
如上图红框所示,可以看到该page中有两条record包含已经被drop列的旧值,这些列的大小及占比。通过这些信息我们就可以准确的知道instant drop column对空间的浪费比例。
同样的,如果该page包含deleted mark records,也可以看到他们的大小及占比。
这些信息除了page级别,还可以进行Index级别的统计(使用--analyze-index, -i INDEX_ID)
4. 限制
圣诞假期梭的第一版,所以存在一些功能局限,也可能还有bug(欢迎提Issue):
- 支持MySQL版本:
当前支持MySQL 8.0 (8.0.16 - 8.0.40)
(因为MySQL 8.0.16之前的版本在生成SDI的时候存在bug,导致SDI会缺失dd_object::indexes::elements中的一些元信息)
- 支持平台:
当前支持Linux、MacOS
(我的开发测试环境没有Windows)
- 功能限制:
Tablespace:
- 暂不支持解析加密的tablespace
Table:
- 暂不支持解析使用表压缩、页压缩的table
- 暂不支持解析加密的table
- 暂不支持解析分区表
- 暂不支持解析FTS的auxiliary index table及common index table
Index:
- 暂不支持解析Full-Text index注意:ibdNinja的分析是基于InnoDB持久化到ibd的数据页进行的,存在于redo中可能还没来得及刷到ibd中的脏页暂时无法纳入统计,所以对于存在大量脏页的场景可能会导致分析结果存在一些偏差及可能的错误
