




开源生态
众所周知,MySQL主备库(两节点)一般通过异步复制、半同步复制(Semi-Sync)来实现数据高可用,但主备架构在机房网络故障、主机hang住等异常场景下,HA切换后大概率就会出现数据不一致的问题(简称RPO!=0),因此但凡业务数据有一定的重要性,都不应该选择MySQL主备架构(两节点)的数据库产品,推荐选择RPO=0的多副本架构。
MySQL社区,对于RPO=0的多副本技术演进:
- MySQL官方开源,推出了基于组复制的MySQL Group Replication(MGR)高可用解决方案,内部通过XCOM
封装了 Paxos 协议提供了数据一致性的保障。 - 阿里云 PolarDB-X,来源于阿里电商双十一、异地多活的业务打磨和验证,在2021年10月份进行了全内核开源,全面拥抱MySQL开源生态。PolarDB-X 定位为一款集中分布式一体化数据库,其数据节点Data Node(DN)采用了自研的X-Paxos
协议,高度兼容MySQL 5.7/8.0,不仅提供了金融级高可用能力,还同时具备高扩展的事务引擎、灵活的运维容灾、低成本的数据存储的特点,参考:《PolarDB-X 开源 | 基于Paxos的MySQL三副本》。
PolarDB-X集中分布式一体化的理念:数据节点DN可以被独立出来作为集中式(标准版)形态,完全兼容单机数据库形态。当业务增长到需要分布式扩展的时候,架构原地升级成分布式形态,分布式组件无缝对接到原有的数据节点,不需要数据迁移,也不需要应用侧做改造,即可享受分布式带来的可用性与扩展性,架构说明:《集中分布式一体化》
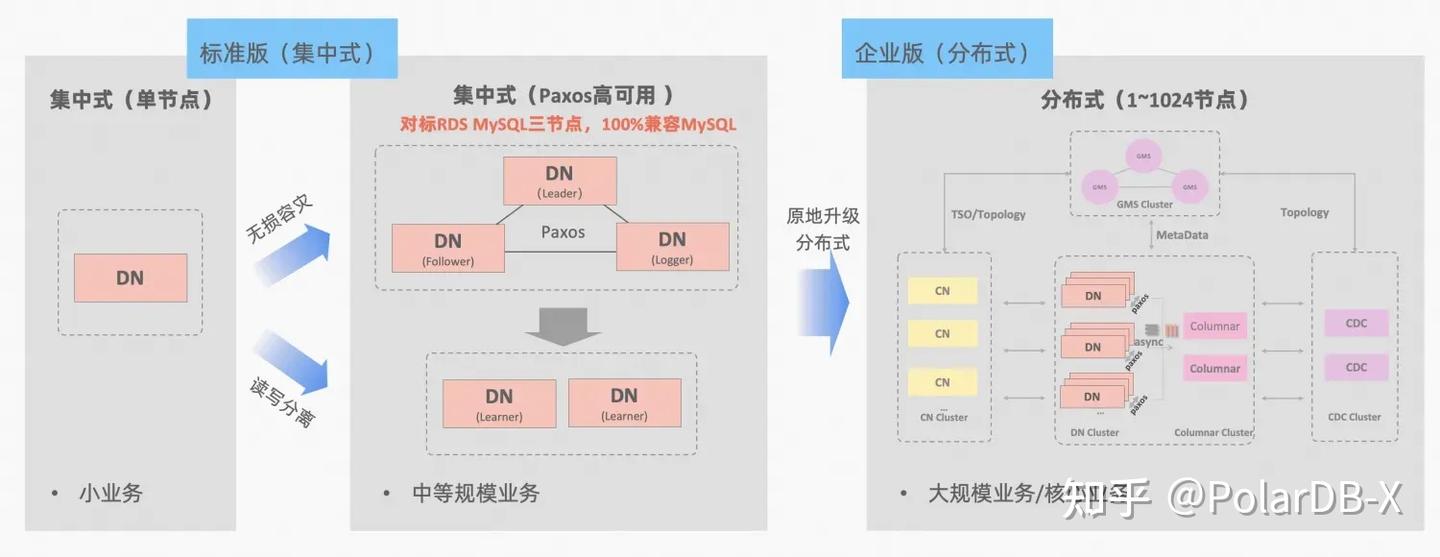
MySQL的MGR和PolarDB-X的标准版DN,两者从最底层的原理上都采用了Paxos协议,那么在实际使用上,具体的表现和差异如何呢?本文从架构对比、关键差异、测试对比方面进行分别详细阐述。
MGR/DN简称说明:MGR代表MySQL MGR
TL;DR
详细对比分析比较长,可以先看一下总结和结论,有兴趣的话可以顺着总结在后续文章中找一下线索。
MySQL MGR,一般的业务和公司都不建议使用,因为需要有专业的技术知识和运维团队才有机会用好,本文也复现了MySQL MGR三个业界流传已久的"暗坑":
- 暗坑1:MySQL MGR,XCOM协议
走了全内存模式,默认是不满足RPO=0的数据一致性保证(本文后续有testcase复现丢数的问题),需要显示配置一个参数才可以保证,目前MGR的设计上性能和RPO无法兼得 - 暗坑2:MySQL MGR在有网络延迟下性能比较拉胯,文章中测试了4钟网络场景的对比(包括同城3机房、两地三中心),性能参数配置下跨城只有同城的1/5,如果再开启RPO=0的数据保证,性能更没法看。因此,MySQL MGR更适合用在同机房场景,跨机房容灾不适合
- 暗坑3:MySQL MGR的多副本架构,备节点的故障都会让主节点Leader出现流量跌0,不太符合常理。文章中重点尝试开启MGR的单Leader模式(对标MySQL以前的主备副本架构),模拟备副本的宕机和恢复的两个动作,备节点的运维操作也会让主节点(Leader)出现流量跌0(持续10来秒),整体的可运维性比较差。因此,MySQL MGR在主机运维上要求比较高,需要专业的DBA团队
PolarDB-X Paxos相比于MySQL MGR,在数据一致性、跨机房容灾、节点运维上都没有MGR类似的坑,但也有个别小缺点、以及容灾上的优点:
- 缺点:简单的同机房场景下,小并发下的只读性能、高并发下的纯写性能,比MySQL MGR略低5%左右,同时多副本的网络发送,性能上有进一步的优化空间
- 优点:100%兼容MySQL 5.7/8.0的特性,同时在多副本的备库复制、故障切换路径上做了比较多的精简优化,高可用切换RTO<=8秒,业界常见的4钟容灾场景都表现不错,可以替换semi-sync(半同步)、MGR等
1. 架构对比
名词解释
MGR/DN简称说明:
- MGR:MySQL MGR的技术形态,后续内容简称:MGR
- DN:阿里云PolarDB-X 集中式(标准版)的技术形态,其中分布式下的数据节点DN可以被独立出来作为集中式(标准版)形态,完全兼容单机数据库,后续内容简称:DN
MGR
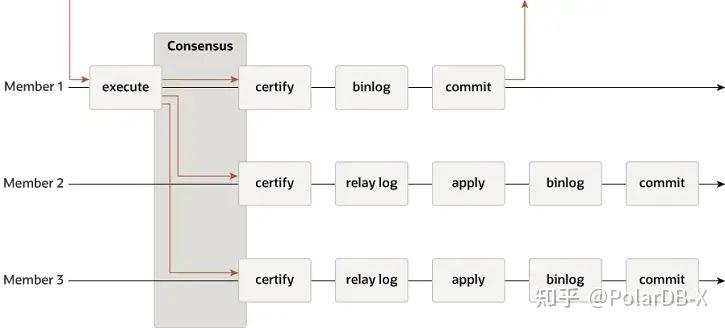
MGR 支持单主、多主模式,完全复用 MySQL 的复制系统,包括 Event、Binlog & Relaylog 、Apply、Binlog Apply Recovery、GTID
- Leader:
- 事务提交前调用before_commit钩子函数group_replication_trans_before_commit,进入 MGR 的多数派复制
- MGR 借助 Paxos 协议,将 THD 上缓存的 Binlog Events 同步所有在线节点
- MGR 收到多数派应答后,确定可以提交事务
- THD 进入事务组提交流程 ,开始写本地 Binlog更新Redo回复客户端OK报文
- Follower:
- MGR 的 Paxos Engine 持续侦听来自 Leader 的协议消息
- 经过完整的一次 Paxos 共识过程,确认这个(批)Event 在集群已经达到多数派
- 将接收的Event写入 Relay Log
,IO Thread Apply Relay Log - Relay Log应用走完整的组提交流程,备库会最终会生成自己的binlog文件
MGR采用上述流程的原因,是因为MGR默认是多主模式,每个节点都可以写,所以单个Paxos Group内Follower节点需要将接受的日志先转成RelayLog,然后结合自身作为Leader接收的写事务提交,在两阶段组提交流程中生产Binlog文件提交最终事务。
DN

DN 复用了 MySQL的基础数据结构和函数级代码,但是将日志复制、日志管理、日志回放、崩溃恢复环节跟X-Paxos 协议紧密结合在了一起,形成了自己的一套多数派复制和状态机机制。与MGR的关键区别在于 DN 事务日志多数派达成一致的切入点在主库事务提交过程中。
- Leader:
- 进入事务的组提交流程,在组提交的Flush阶段,将各THD 上的 Events 写入 Binlog 文件,然后再通过X-Paxos将日志异步广播给所有 Follower
- 在组提交的Sync阶段,先持久化Binlog,然后更新X-Paxos 持久化的位点
- 在组提交的Commit阶段,先要等待 X-Paxos 收到多数派应答后,然后提交这组事务,最后回复客户端OK报文
- Follower:
- X-Paxos 持续侦听来自 Leader 的协议消息
- 收到一个(组) Events,写入到本地 Binlog,回应答
- 收到下一个消息,其中携带了已经达成多数派的位点Commit index
- SQL Apply线程后台持续应用接收到的Binlog日志,最多只应用到多数派位点位置
这种设计的原因是,DN当前只支持单主模式,所以X-Paxos 协议层面的日志就是 Binlog 本身,Follower也省去了 Relay Log,其持久化的日志和 Leader 等的日志的数据内容是等价相同的。
