




2. 关键差异
2.1. Paxos协议效率
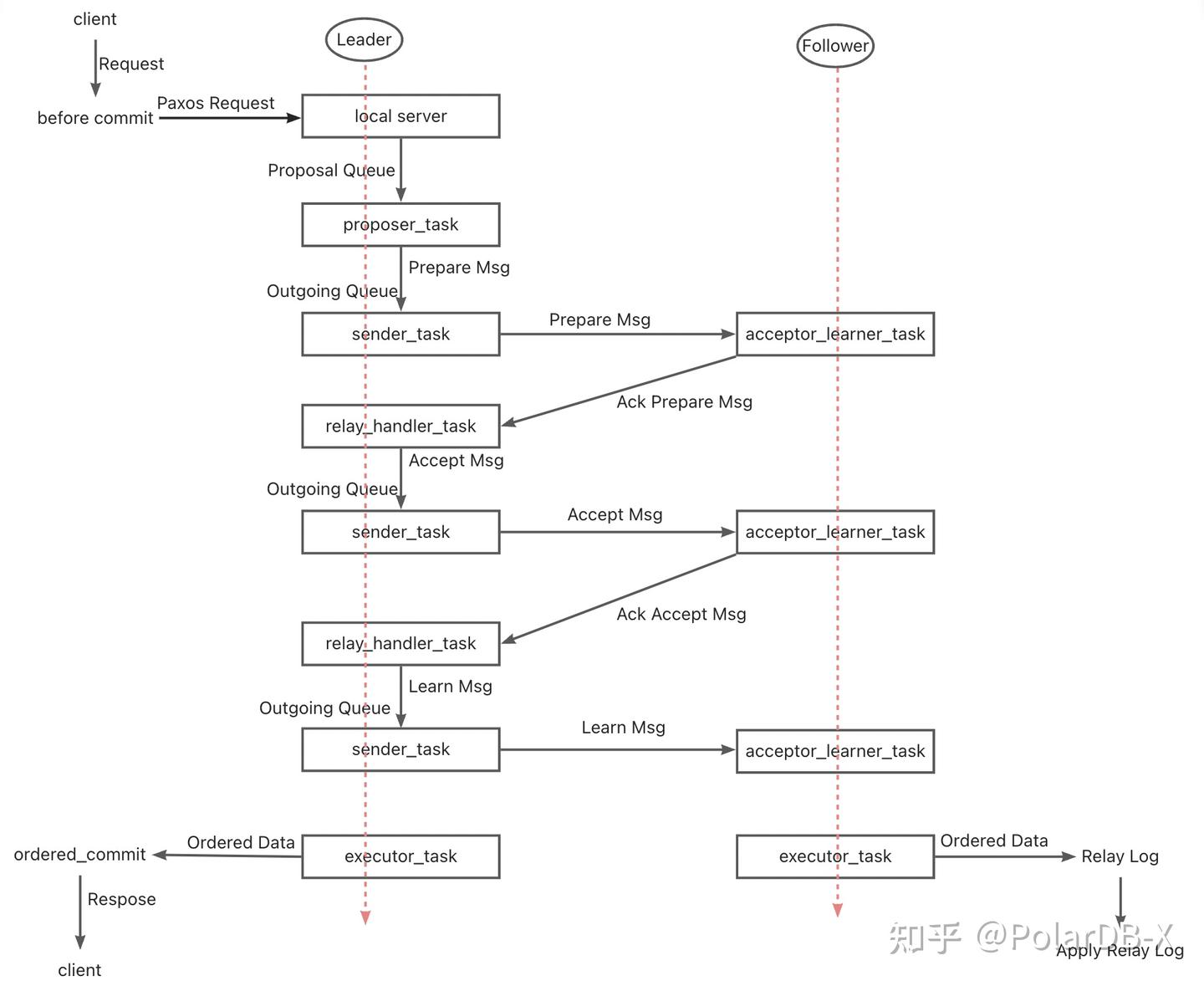
MGR
- MGR的Paxos协议基于Mencius协议实现,属于Multi-Paxos
理论,区别在于Mencius在降低主节点负载提高吞吐量上做了优化改进 - MGR的Paxos协议的由XCOM组件实现,支持多主和单主模式部署,单主模式时Leader 上 Binlog 向 Follower 节点的原子广播,每批消息(一个事务)的广播是标准的一次Multi-Paxos 过程
- 一个事务的多数派的满足,XCOM至少需要经历Accept+AckAccept+Learn三个报文交互,即至少1.5个RTT开销。最多需要经历Prepare+AckPrepare+Accept+AckAccept+Learn三个报文交互,即最多一共2.5个RTT开销
- 由于Paxos协议是在XCOM模块内高内聚完成的,MySQL复制系统不感知, 所以Leader必须等待完整的 Paxos 过程完毕才能进行事务本地提交,包括Binlog的持久化和组提交
- Follower在完成多数派提交后,会异步进行Events的持久化到Relay Log,然后由SQL Thread应用和组提交生产Binlog
- 由于Paxos同步的日志是进入组提交流程前没有排序的Binlog,所以Leader 上 Binlog Event 的顺序,和 Follower 节点上 Relay Log 的 Event 顺序未必相同
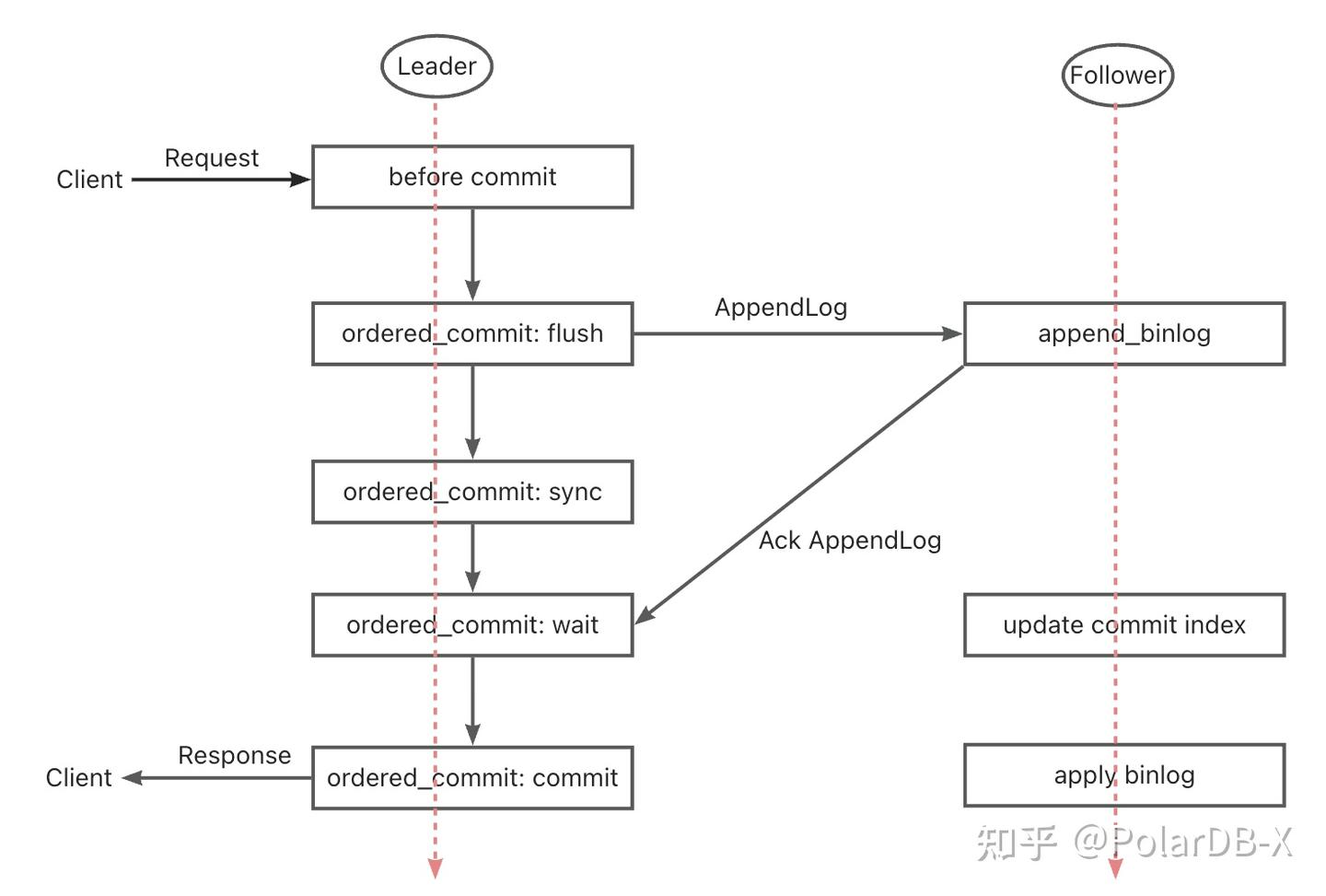
DN
- DN的Paxos协议是基于Raft协议
实现,也属于Multi-Paoxs理论,区别在于Raft协议更强Leadership保障和工程稳定性保证 - DN的Paxos协议由X-Paoxs组件完成,默认是单主模式,单主模式时Leader 上 Binlog 向 Follower 节点的原子广播,每批消息的广播是标准的一次 Raft过程。
- 一个事务的多数派的满足,X-Paoxs只需要经历Append+AckAppend 两个报文交互,只有1个RTT开销
- Leader 发给 Follower 日志后,只要多数派满足,它就提交事务,不等待第二阶段的 Commit Index 广播
- Follower在完成多数派提交的前提,需要要全部事务日志必须持久化,这点与MGR的XCOM有显著差别, MGR只需要在XCOM内存中接收到即可
- Commit Index 在后续消息和心跳消息中带过去,Follower在CommitIndex推高后,再进行Apply Event
- Leader 和 Follower 的 Binlog 内容顺序一致,Raft 日志无空洞,并且用 Batching/Pipeline机制加大日志复制吞吐量
- 相比MGR,事务提交时Leader始终只有一次来回的延迟,对延迟敏感的分布式应用十分很关键
2.2. RPO
理论上 Paxos 和 Raft 都可以保证数据一致性,以及 Crash Recovery 后已经达成多数派的日志不丢失,但是在具体工程上还是有区别。
MGR
XCOM 完全封装了 Paxos 协议,而它的所有协议数据又都是先缓存在内存中,默认情况事务达成多数派不要求日志持久化。 在多数派宕机、Leader故障的情况下,在会有 RPO != 0严重问题。假设一极端场景:
- MGR集群由三个节点ABC组成, 其中AB同城独立机房,C是跨城。A是Leader, BC是Follower节点
- 在Leader A节点上发起事务001, Leader A将事务001的日志广播给BC节点,通过Paxos协议满足多数派即可认为事务可以提交。AB节构成了多数派,C节点由于跨城网络延迟并没有收到事务001的日志
- 下一个时刻,Leader A提交了事务001并返回Client 成功,此时表示事务001已经提交到数据库
- 此刻 B节点的Follower上,事务001的日志还在XCOM 缓存中,还没来得及刷到 RelayLog中;此刻C节点的Follower上仍然没有接收到A节点的Leader的发过来的事务001日志
- 此时,AB节点宕机, A节点故障长时间不能恢复,B节点很快重启恢复, BC两节点继续提供读写服务
- 由于宕机时事务001日志并没有持久化到节点B的RelayLog中,也没有被节点C接收到,因此此刻BC节点其实都已经丢失了事务001,并且无法找回
- 这种多数派宕机的场景下,导致了RPO!=0
社区默认参数下,事务达成多数派不要求日志持久化,不保证RPO=0,可以认为是XCOM工程实现中为了性能的取舍。要想保证绝对的RPO=0, 需要将控制读写一致性的参数group_replication_consistency配置为AFTER,但这样的话,事务达成多数派除了需要1.5个RTT网络开销外,还需要一次日志IO开销,性能会很差。
DN
PolarDB-X DN采用X-Paxos实现分布式协议, 与MySQL的Group Commit流程深度绑定,在一个事务进行提交时,强制要求多数派确认落盘持久化后,才能允许真正提交。这里多数派落盘是指主库的Binlog落盘,备库的IO线程接收到主库的日志并落盘持久化到自己Binlog中。因此即使在极端场景下所有节点故障,数据也不会丢失,也能保证RPO=0。
2.3. RTO
RTO时间与系统本身冷重启的时间开销密切相关,反映到具体基础功能上,就是:故障检测机制->崩溃恢复机制->选主机制->日志追平
2.3.1. 故障检测
MGR
- 每个节点周期性向其他节点发送心跳包检测其他节点是否健康,心跳周期固定是1s,无法调整
- 当前节点如果发现其他节点超过group_replication_member_expel_timeout(默认5s)后没有响应则视为失效节点,并从集群中踢出
- 像网络闪断或者异常重启这种异常,待网络恢复后,单个故障节点自己会尝试自动加入集群,然后追平日志
DN
- Leader节点周期性向其他节点发生心跳检包检查其他节点是否健康,心跳周期为选举超时时间的1/5。选举超时时间由参数consensus_election_timeout控制, 默认5s,所以Leader节点心跳周期默认1s
- Leader如果发现其他掉线了,仍然继续周期性想其他所有节点发送心跳包,以确保其他节点崩溃恢复后能及时接入。但是Leader节点不再向已经掉线的节点发送事务日志
- 非Leader节点不发送心跳检测包,但是非Leader节点如果发现超过consensus_election_timeout时间没有收到Leader节点的心跳,则触发重新选举
- 像网络闪断或者异常重启这种异常,待网络恢复后,故障节点自己会自动加入集群
- 因此在故障检测方面,DN提供了更多运维配置接口,对于跨城部署场景故障的识别度会更加准确
2.3.2. 崩溃恢复
MGR
- XCOM实现的Paxos协议是内存态,多数派的达成不要求持久化,协议状态以存活的多数派节点内存状态为准。如果所有节点都挂掉,也就无法恢复协议了,集群重启后此时需要人工介入进行恢复
- 如果只是单个节点崩溃恢复,但是Follower节点落后Leader节点较多事务日志,此刻Leader 上的 XCOM 缓存的事务日志已经清除了,就只能走Global Recovery 或 Clone流程
- XCOM缓存大小由group_replication_message_cache_size控制,默认1GB
- Global Recovery 是指节点重新加入集群时,通过从其他节点获取所需的缺失事务日志(Binary Log)来恢复数据。这个过程依赖于集群中至少有一个节点保留了所有需要的事务日志
- Clone依赖Clone Plugin,用于数据量较大或缺失较多日志时的恢复。它通过将整个数据库的快照复制到崩溃的节点,然后通过最新事务日志进行最终同步
- Global Recovery 和 Clone 流程通常是自动化的,但在某些特殊情况下,如网络问题或者其他两个节点XCOM缓存都清除了,这时需要人工介入解决
DN
- X-Paxos协议使用Binlog持久化,崩溃恢复时,会先完整恢复已提交事务。对于悬挂事务,需要等待XPaxos协议层先达成一致确定主备关系后,再进行提交或者回滚处理。 整个流程全自动化。即使如果所有节点都挂掉,集群重启也能自动恢复
- 对于Follower节点落后Leader节点很多事务日志场景,只要Leader上Binlog文件没有删除,Follower节点就一定追上
- 因此在崩溃恢复方面,DN是完全不需要人工介入的
2.3.3. 选主
单主模式下, MGR的XCOM和DN X-Paxos 这种强 Leader 模式的选主,所遵循的基本原则是一样的--集群已共识的日志不能回退。 但是到未共识的日志时,存在差异
MGR
- 选主更多意义上是接下来哪个节点充当 Leader 服务,这个 Leader 当选时不一定拥有最新的共识日志,所以它需要从集群的其他节点同步最新日志,待日志追平后提供读写服务
- 这样的好处是,Leader 本身的选择是个策略化的产物,比如权重,比如顺序。 MGR通过group_replication_member_weight参数控制各节点权重
- 劣处是新当选的Leader本身可能复制延迟较多,需要继续追平日志,或者应用延迟较多,需要继续追平日志应用,才能提供读写服务。这会导致RTO时间较长
DN
- 选主就是协议意义上的,哪个节点拥有集群全部多数派的日志,它就可以当选 Leader,所以这个节点之前可能是 Follower,也可能是 Logger
- 而 Logger 是不能提供读写服务的,等它把日志同步给其他节点后,自己就主动让出 Leader 角色
- 为了能确保指定节点成为Leader,DN使用乐观权重策略+强制权重策略来限定当主顺序,使用策略化多数派机制确保新主零延迟立刻能提供读写服务
- 因此在选主方面,DN不仅支持与MGR一样的策略化选择,还支持强制权重策略
2.3.4. 日志追平
日志追平是指主备之间日志存在日志复制延迟,备库需要追平日志。对于重启恢复的节点,通常都是以备库开始恢复,并且已经和主库产生了比较的的日志复制延迟,需要向主库追平日志。对于那些和 Leader 物理距离较远的节点,多数派达成通常和它们没关系,它们总是存在复制日志延迟一直在追平日志。这些情况都需要具体工程实现来确保日志复制延迟的及时解决。
MGR
- 事务日志都在 XCOM 缓存中,而缓存默认只有1G,所以复制落后很多的 Follower 节点请求日志的时候,很容易缓存早已被清理
- 此时这个落后的 Follower 会自动踢出集群,然后以前面崩溃恢复提到Global Recovery 或 Clone流程,追平后再自动加入集群。如果遇到如网络问题,或者其他两个节点XCOM缓存都清除的情况,这时需要人工介入解决
- 为什么一定要先踢出集群,因为多写模式故障节点极大影响性能,且 Leader 的缓存对它没有任何作用,异步追平后再加进来
- 为什么不能使用直接读取Leader本地的Binlog文件,因为前面提到的XCOM协议是全内存态,Binlog 和 Relay Log 中没有任何关于 XCOM 的协议信息
DN
- 数据都在 Binlog 文件上,只要 Binlog 没有清理,那按需发送就好了,不存在踢出集群的情况
- 为了降低主库从Binlog文件中读取老的事务日志带来的IO抖动,DN优先从FIFO Cache中读取最近缓存的事务日志, FIFO Cache由参数consensus_log_cache_size控制,默认64M
- 如果FIFO Cache中老的事务日志已经更新的事务日志淘汰掉了,DN会尝试从Prefetch Cache中读取之前缓存的事务日志,Prefetch Cache有参数consensus_prefetch_cache_size控制,默认64M
- 如果Prefetch Cache中也没有需要的老的事务日志,DN会尝试发起异步IO任务,批量从Binlog文件中读取指定事务日志前后若干连续的日志,放置在Prefetch Cache中,等待DN下一次重试读取
- 因此在追平日志方面,DN完全不需要人工介入
2.4. 备库回放延迟
备库回放延迟是同一个事务在主库完成提交的时刻与在备库完成事务应用的时刻之间的延迟,这里考验的是备库Apply应用日志的性能。它影响的是异常发生时,备库成为新主后需要多久才能自身数据应用完毕可以提供读写服务。
MGR
- MGR备库从主库接收落盘的是RelayLog文件,Apply应用时需要重新将RelayLog读取,经历完整两阶段组提交流程,生产对应的数据和Binlog文件
- 这里事务应用效率与主库上事务提交效率相同,默认的双一配置(innodb_flush_log_at_trx_commit、sync_binlog)会导致备库应用同样资源开销较大
DN
- DN备库从主库接收落盘的就是Binlog文件,应用时需要重新将Binlog读取,只需要经历一阶段组提交流程,生产对应的数据即可
- 由于DN支持完整的Crash Recover,备库应用不需要开启innodb_flush_log_at_trx_commit=1,因此实际上不受双一配置的影响
- 因此在备库回放延迟方面,DN备库回放效率会远大于MGR
2.5. 大事务影响
大事务不仅影响普通事务提交,在分布式系统中还影响整个分布式协议运行的稳定性,严重情况下一个大事务就会导致整个集群较长时间的不可用。
MGR
- MGR对大事务的支持没有任何优化, 只是增加了参数group_replication_transaction_size_limit控制大事务上限,默认143M,最大2GB
- 当事务日志超过大事务限制后,会直接报错,事务无法提交
DN
- 针对大事务带来的分布式系统的不稳定问题, DN采取大事务拆分+大对象拆分的方案进行根治, DN会将大事务的事务日志进行逻辑拆分+物理拆分的方式拆分为一个个小块的的事务日志,每个小块的事务日志使用完整的Paxos提交保证
- 基于大事务拆分的方案,DN对大事务的大小不做任何限制,用户可以随意使用, 同样能保证RPO=0
- 详细说明见《PolarDB-X 存储引擎核心技术 | 大事务优化》
- 因此在大事务问题的处理上,DN能做到不受大事务影响
2.6. 部署形态
MGR
- MGR支持单主、多主的部署模式,多主模式下每个节点可读可写,单主模式时主库可读可写,备库只能只读
- MGR高可用部署至少三节点部署,也即至少三份数据和日志, 不支持日志副本Logger形态
- MGR不支持只读节点的扩展,但是支持MGR+主从复制模式的组合,实现类似拓扑扩展
DN
- DN支持单主模式部署,单主模式时单主模式时主库可读可写,备库只能只读
- DN高可用部署至少三节点部署,但支持日志副本Logger形态,也即Leader、Follower都是全功能副本,Logger相比缺少只有日志没有数据,并且没有被选举权。 这样的话三节点高可用部署只需要2份数据+3份日志的存储开销,低成本部署
- DN支持只读节点部署,支持只读副本Learner形态,相比全功能副本仅是不具备投票权,通过Learner副本实现下游对主库的订阅消费
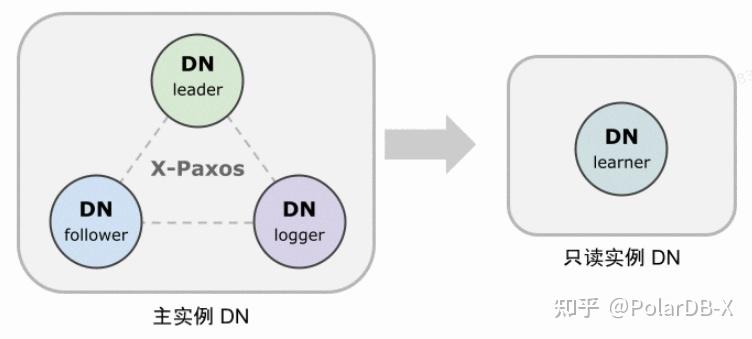
2.7. 特性小结
| 大项 | 子项 | MGR | DN |
| 协议效率 | 事务提交耗时 | 1.5~2.5 RTT | 1个 RTT |
| 多数派持久化方式 | XCOM内存保存 | Binlog持久化 | |
| 可靠性 | RPO=0 | 默认不保证 | 完全保证 |
| 故障检测 | 所有节点相互检查,网络负载高心跳周期无法调整 | 主节点周期检查其他节点心跳周期参数可调 | |
| 多数派崩溃恢复 | 人工介入 | 自动恢复 | |
| 少数派崩溃恢复 | 大部分自动恢复,特殊情况人工介入 | 自动恢复 | |
| 选主 | 自由指定选主顺序 | 自由指定选主顺序 | |
| 日志追平 | 落后日志不能超过XCOM 1GB缓存 | BInlog文件不删除 | |
| 备库回放延迟 | 两阶段+双一,很慢 | 一阶段+双零,较快 | |
| 大事务 | 默认限制不超过143MB | 无大小限制 | |
| 形态 | 高可用成本 | 全功能三副本,3份数据存储开销 | Logger日志副本,2份数据存储 |
| 只读节点 | 借助主从复制实现 | 协议自带Leaner只读副本实现 |
