




3. 测试对比
MGR是MySQL 5.7.17开始引入的,但更多MGR相关特性都只在MySQL 8.0上才有,并且在MySQL 8.0.22及之后的版本,整体会更稳定可靠。因此我们选择双方的最新版8.0.32版本进行对比测试。
考虑到PolarDB-X DN和MySQL MGR在对比测试时,存在测试环境差异、编译方式差异、部署方式差异、运行参数差异、测试手段差异,进而可能导致测试对比数据不准确,本文在各项细节上采用如下方式进行:
| 测试准备 | PolarDB-X DN / MySQL MGR[1] |
| 硬件环境 | 使用同一台96C 754GB内存的物理机,SSD磁盘 |
| 操作系统 | Linux 4.9.168-019.ali3000.alios7.x86_64 |
| 内核版本 | 使用基于社区8.0.32版本的内核基线 |
| 编译方式 | 使用相同的RelWithDebInfo编译 |
| 运行参数 | 使用相同的PolarDB-X官网售卖32C128G规格相同参数 |
| 部署方式 | 单主模式 |
注:
- MGR默认开启了流控,而PolarDB-X DN默认关闭流控。因此对MGR的group_replication_flow_control_mode单独配置关闭,这样MGR的性能会是最好的
- 点查时MGR有明显so读取瓶颈,因此对MGR的replication_optimize_for_static_plugin_config单独配置开启,这样MGR的只读性能会是最好的
3.1. 性能
性能测试是大家在选型数据库时首先关注的一点。这里我们使用官方sysbench工具,构建16张表,每张表1千万数据,进行OLTP场景的性能测试,测试对比不同OLTP场景下不同并发时两者的表现。考虑到实际部署的不同情况, 我们分别模拟下面4种部署场景
- 同机房,一个机房内部署三节点,机器之间互相ping带0.1ms的网络延迟
- 同城三中心,同地域三个机房部署三节点,机房之间互相ping带1ms的网络延迟(比如:上海地域的三个机房)
- 两地三中心,两地三个机房部署三节点,同城机房之间ping带1ms的网络,同城和异地之间带30ms的网络延迟(比如:上海/上海/深圳)
- 三地三中心,三地三个机房部署三节点(比如:上海/杭州/深圳),杭州-上海之间ping带5ms左右的网络延迟,杭州/上海 到深圳距离最远的为30ms的网络延迟
说明:
a. 考虑4个部署场景性能的横向对比,两地三中心、三地三中心都采用3副本的部署模式,真实生产业务可以扩展到5副本的部署形态。
b. 考虑到实际使用高可用数据库产品时对RPO=0的严格限制,但是MGR默认配置RPO<>0,这里在各部署场景下,我们继续增加MGR RPO<>0和RPO=0的对比测试。
- MGR_0 表示 MGR RPO = 0 情况的数据
- MGR_1 表示 MGR RPO <> 0 情况的数据
- DN 表示 DN RPO = 0 情况的数据
3.1.1. 同机房
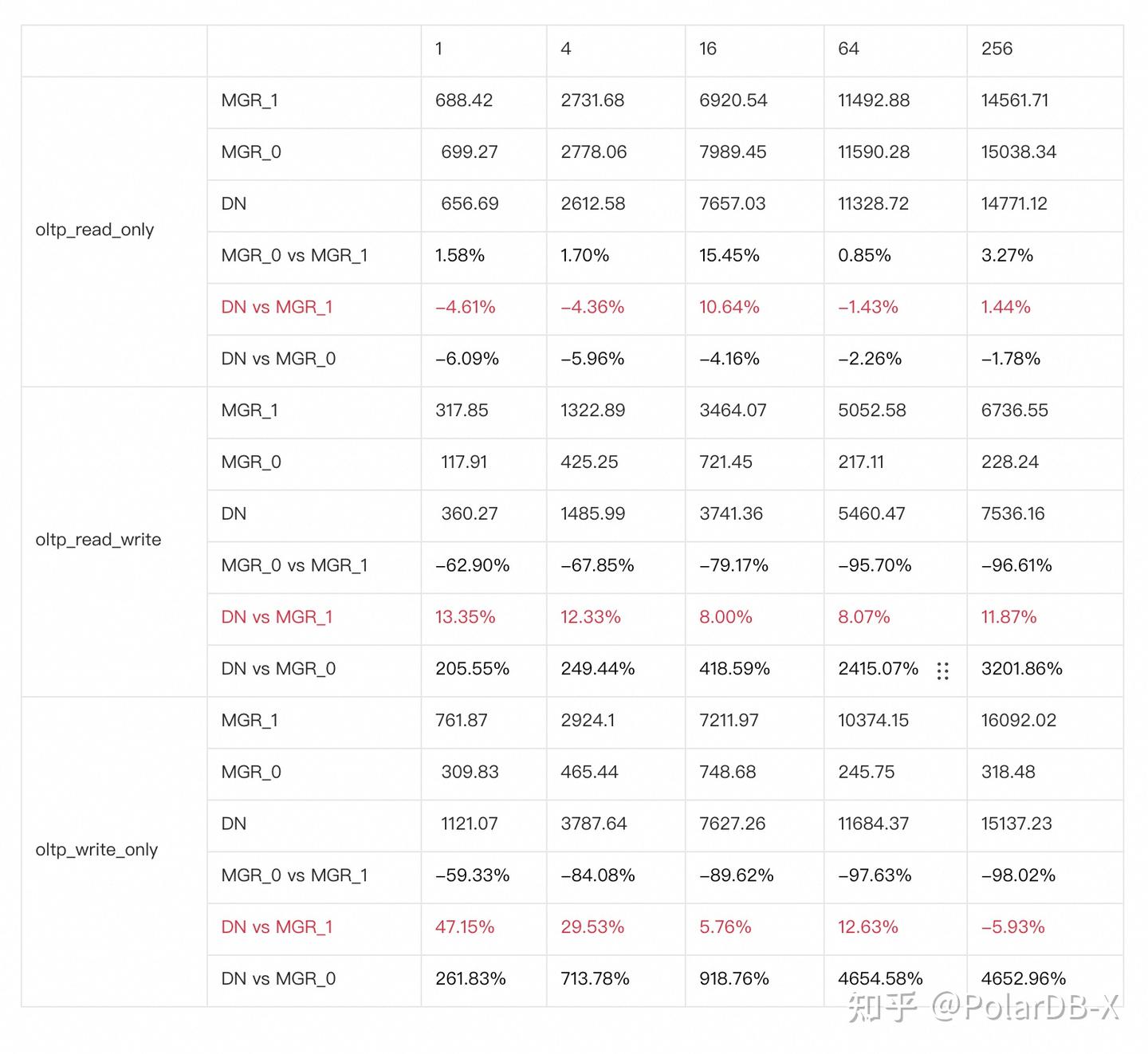
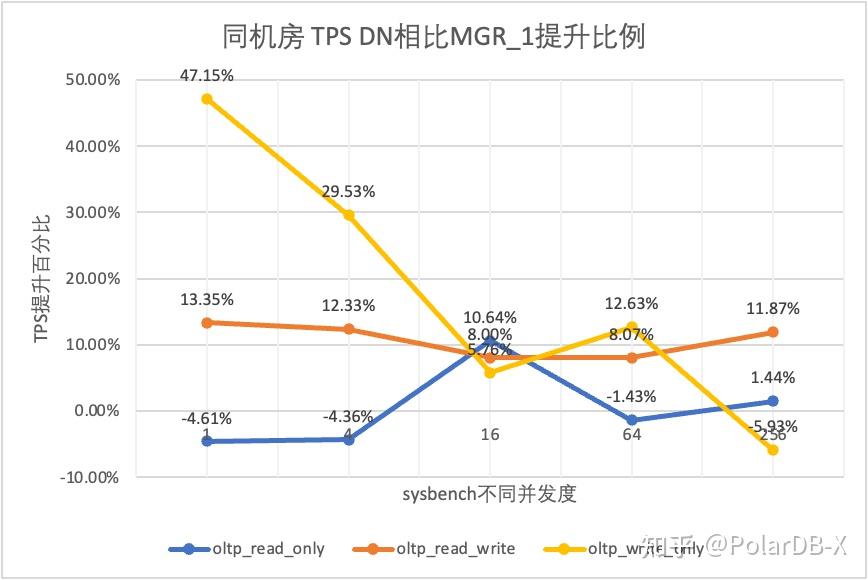
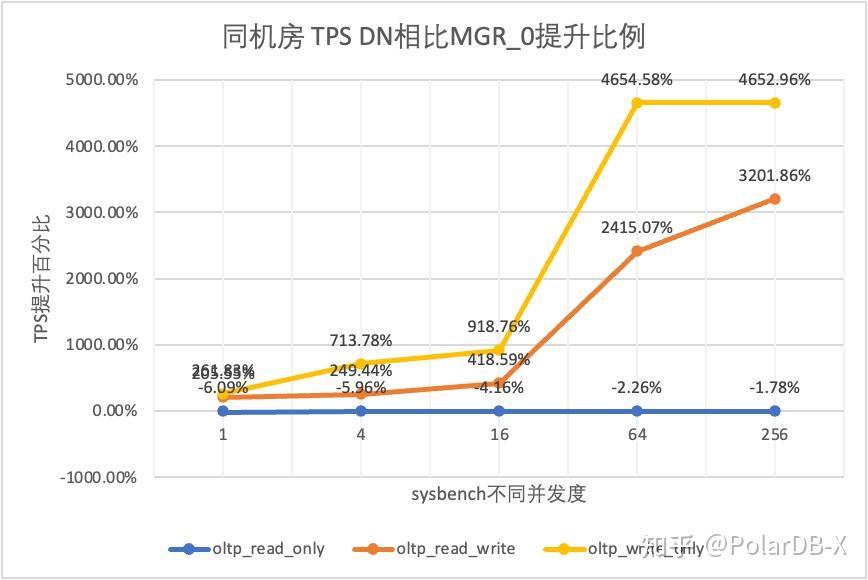
从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-5%~10%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了5%~47%,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了2倍-46倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.2. 同城三中心
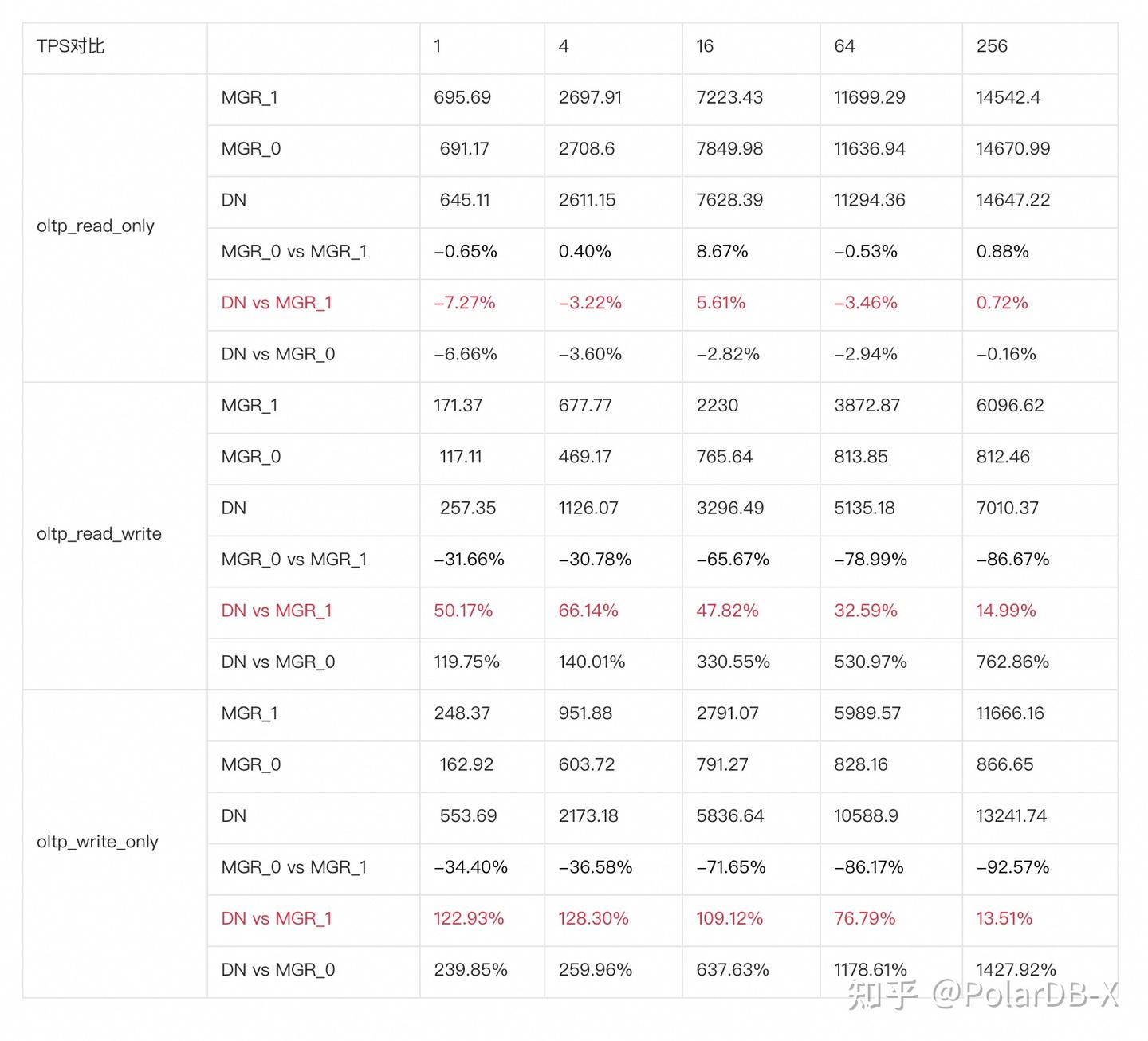
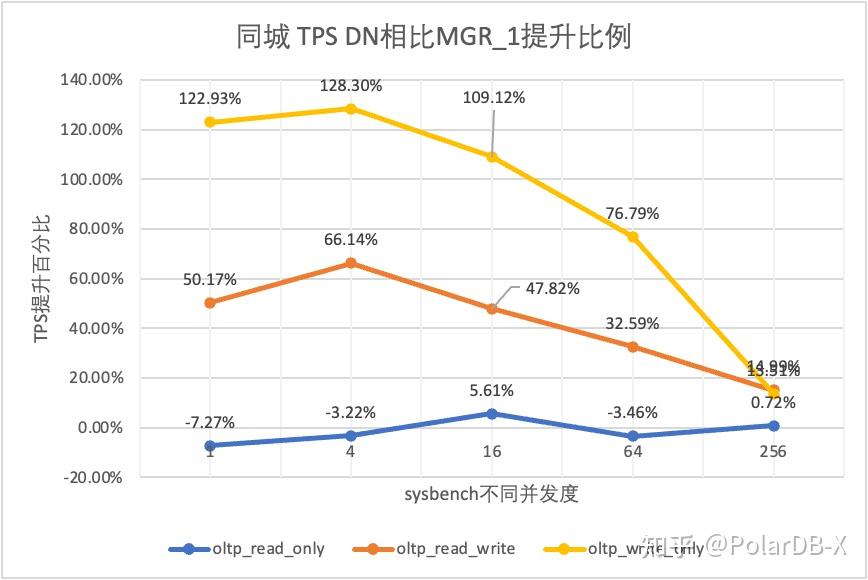
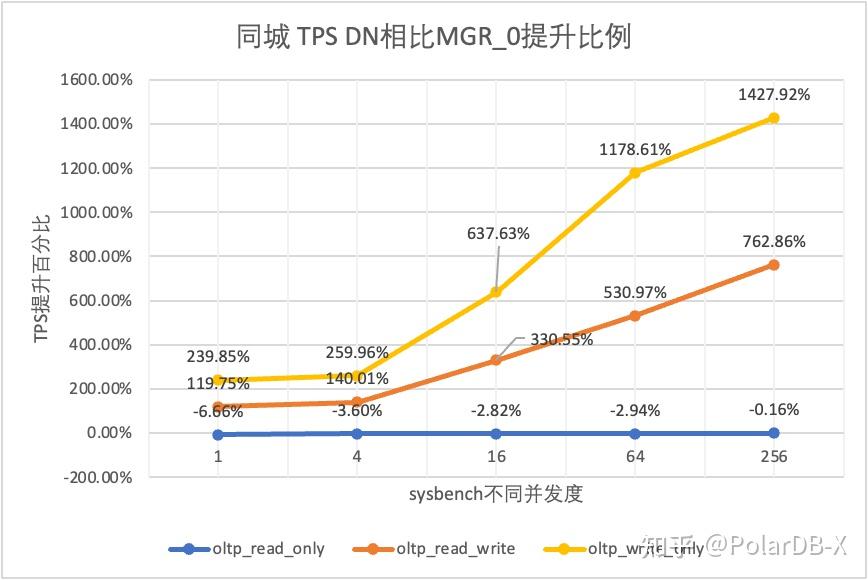
从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-7%~5%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了30%~120%,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了1倍-14倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.3. 两地三中心
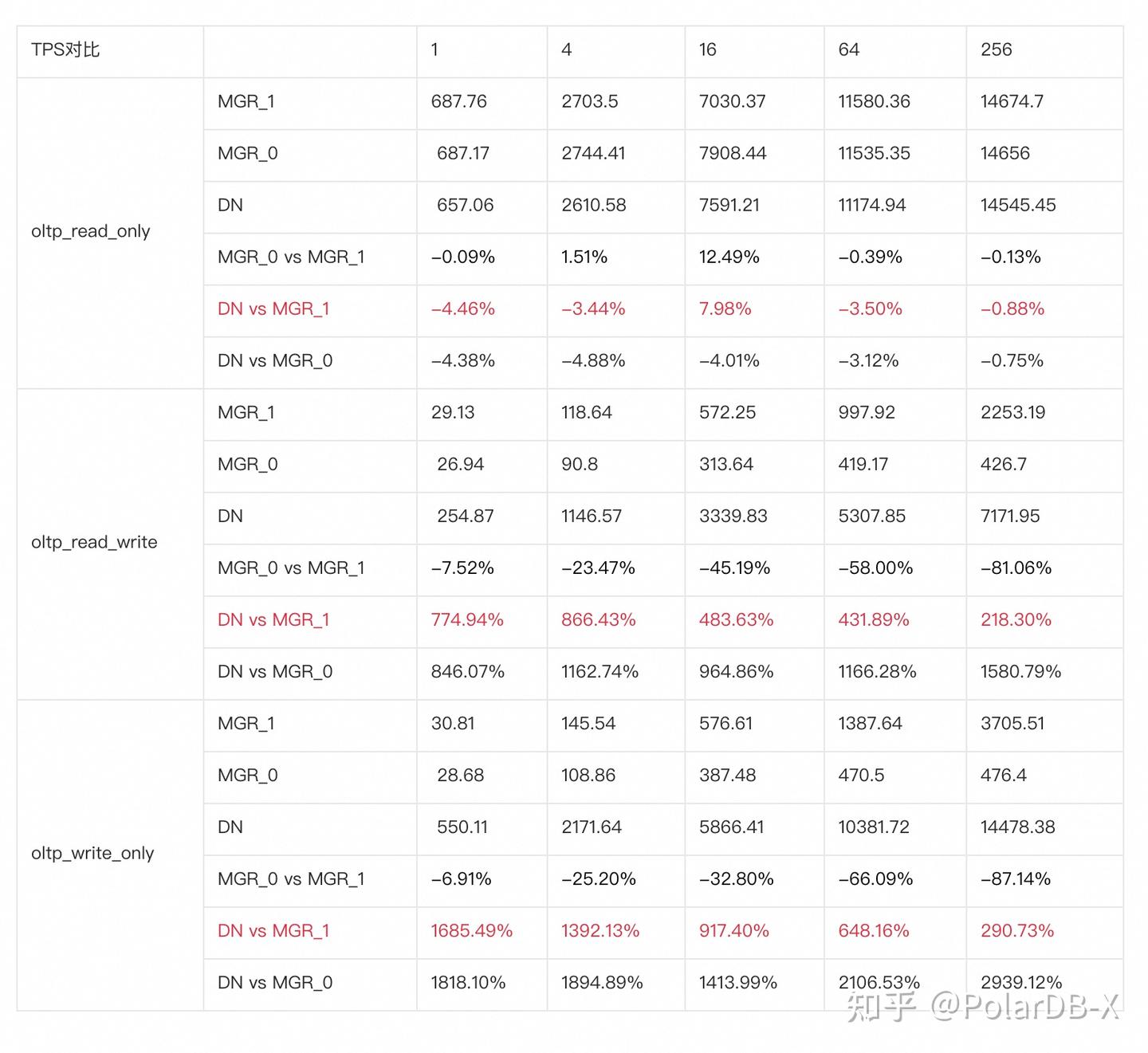
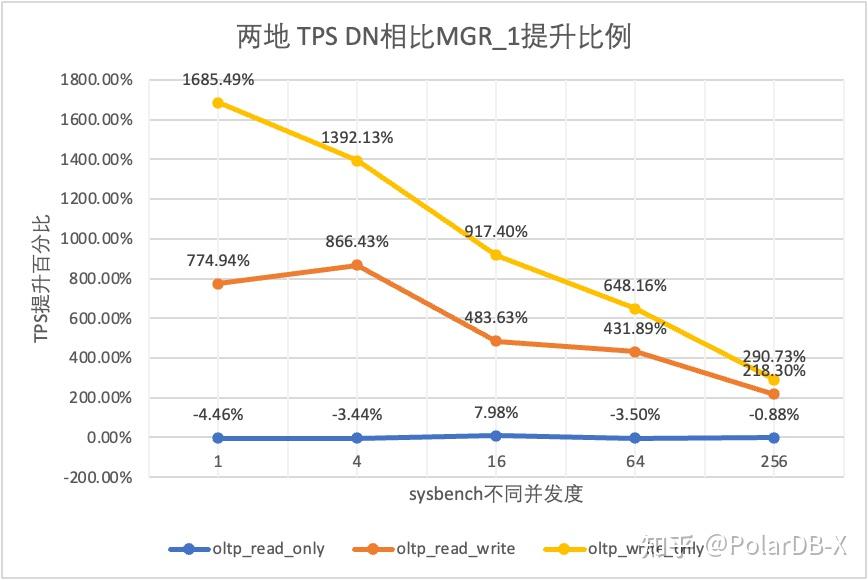
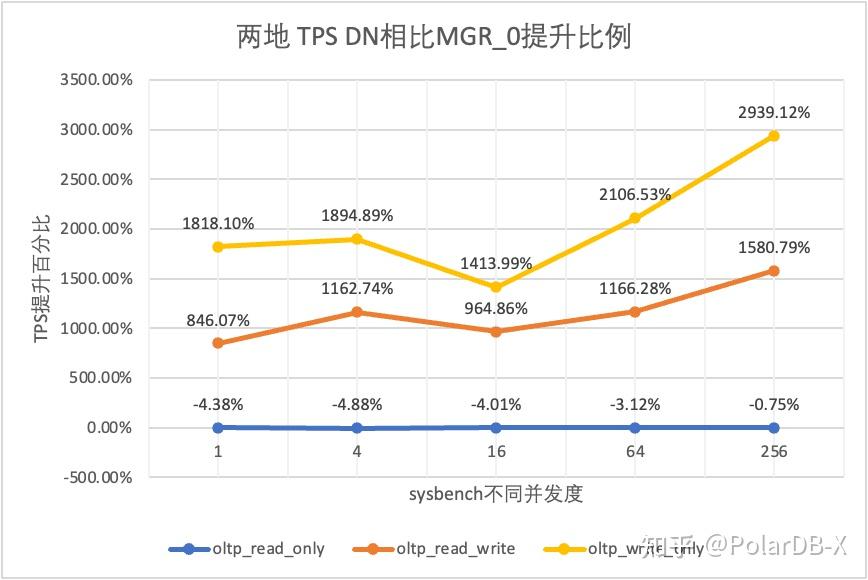
从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-4%~7%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了2倍~16倍,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了8倍-29倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.4. 三地三中心
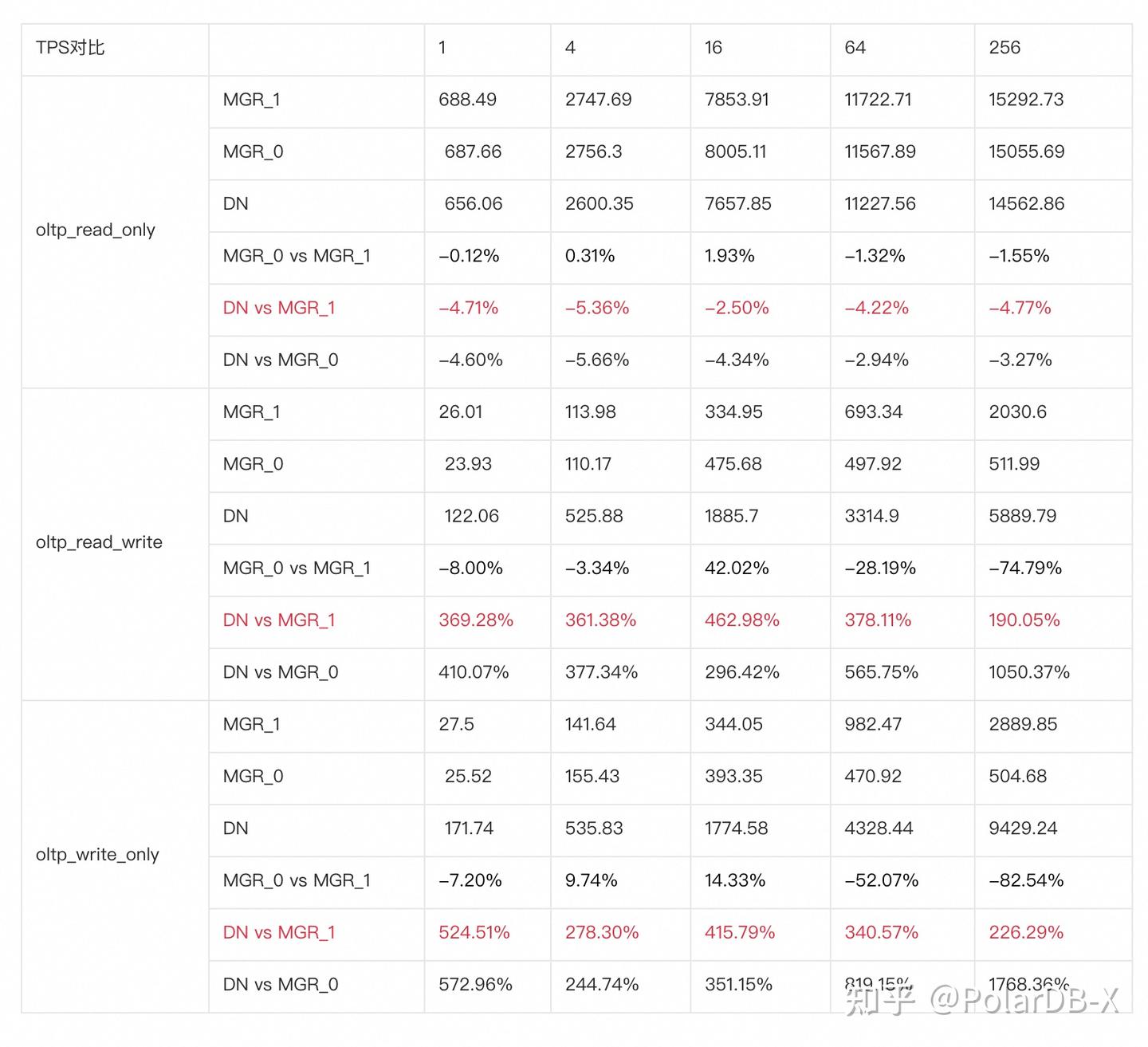
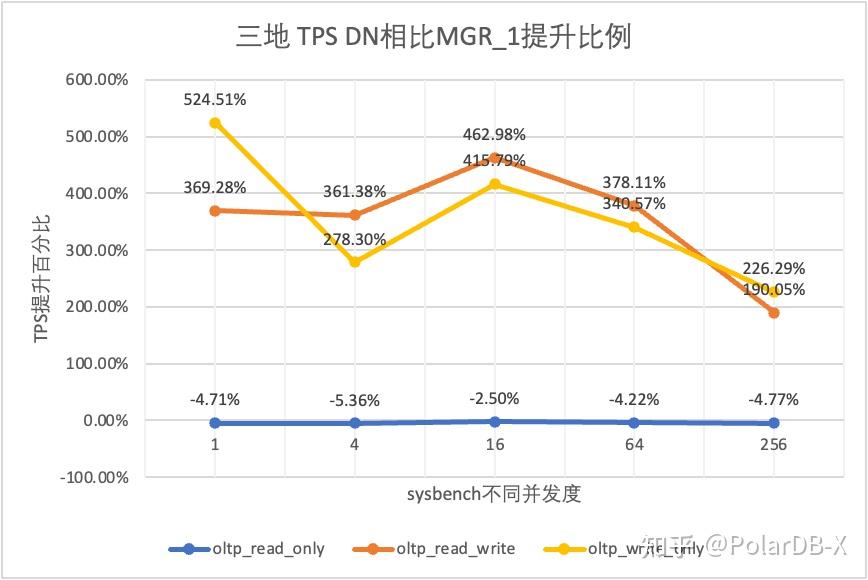
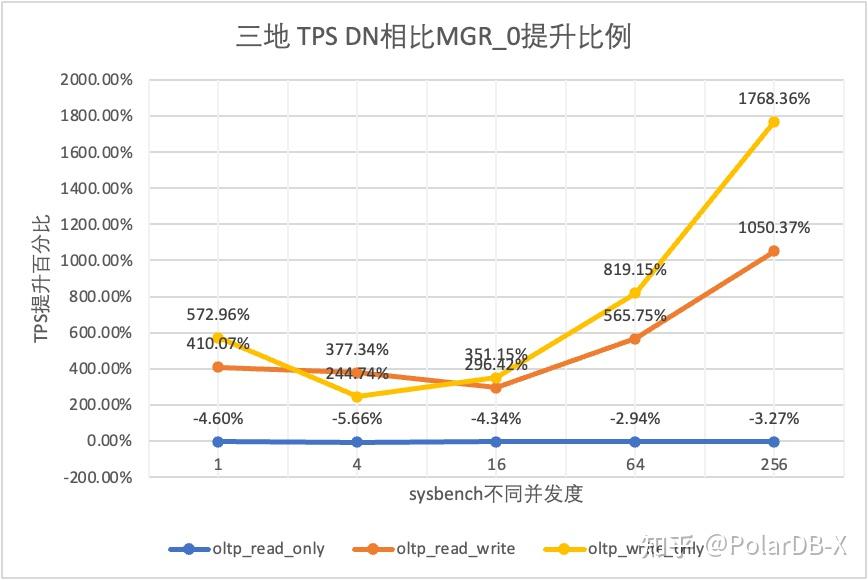
从测试结果可以看出:
- 在只读场景,无论是对比MGR_1(RPO<>0)还是MGR_0(RPO=0),DN与MGR之间的差异稳定在-5%~0%之间,可以认为基本相同。RPO是否等于0对只读事务不影响
- 在读写混合、只写事务场景,在DN(RPO=0)相比MGR_1时(RPO<>0)性能提升了2倍~5倍,并且呈现低并发时DN性能优势明显,高并发时优势不明显的特点。 这是由于低并发时DN的协议效率更高,但高并发下DN和MGR的性能热点都在刷脏上所致
- 而在相同的RPO=0的前提下,在读写混合、只写事务场景,在DN相比MGR_0性能提升了2倍-17倍,并且随着并发提高,DN性能优势加强的特点。也难怪MGR默认也要为了性能而舍弃RPO=0
3.1.5. 部署对比
为了明显对比不同部署方式下性能的变化差异,我们选择上述测试中oltp_write_only场景256并发下不同部署方式下的MGR和DN的TPS数据,以机房测试数据为基线,计算对比不同部署方式时TPS数据相比基线的比例,以此感知跨城部署时性能变化差异
| MGR_1 (256并发) | DN (256并发) | DN相比于MGR的性能优势 | |
| 同机房 | 16092.02 | 15137.23 | -5.93% |
| 同城三中心 | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| 两地三中心 | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| 三地三中心 | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
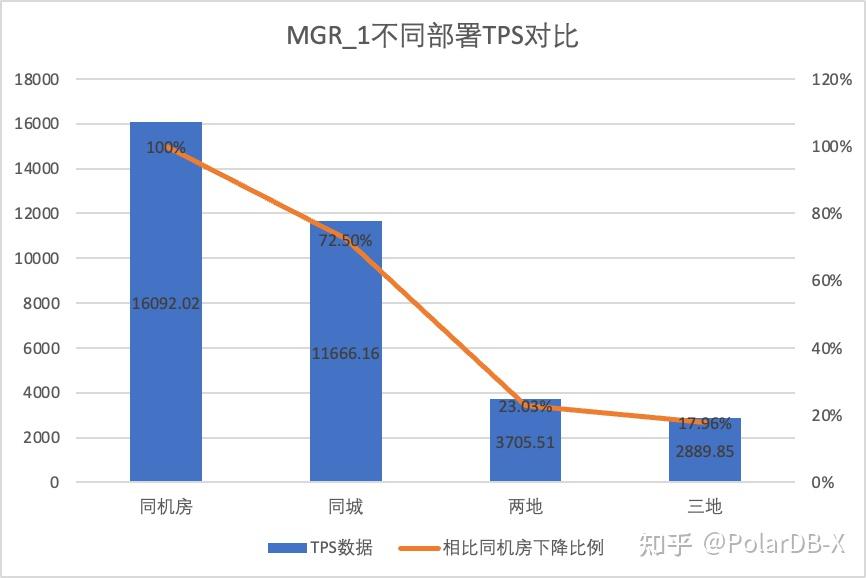
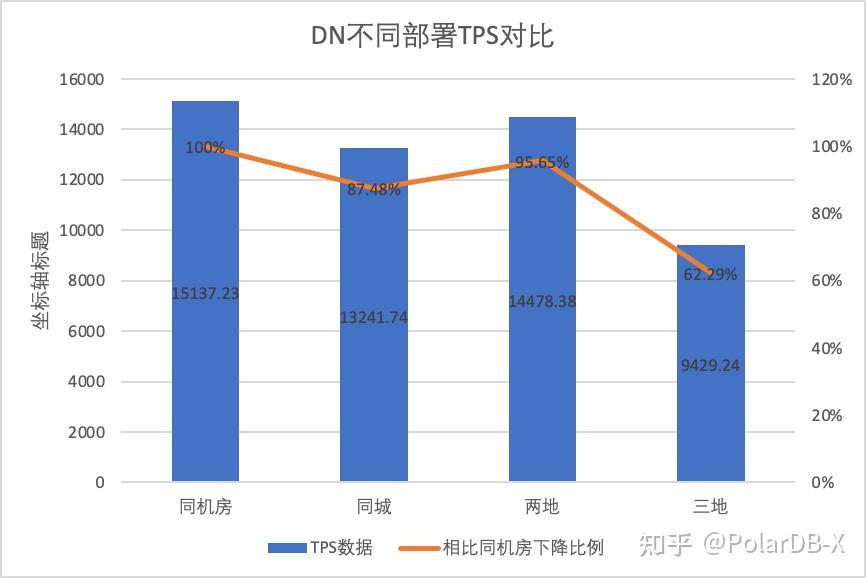
从测试结果可以看出:
- 随着部署方式的扩大化,MGR_1(RPO<>0)的TPS下降明显,相比同机房部署,同城跨机房部署性能下降27.5%, 跨城(两地三中心、三地三中心)部署性能下降77%~82%,这是由于跨城部署RT增加导致
- 而DN(RTO=0)则相对稳定,相比同机房部署,同城跨机房、两地三中心部署性能下降4%~12%, 三地三中心在高网络延迟下部署时性能下降37%,这也是由于跨城部署RT增加导致。不过得益于DN的Batch&Pipeline机制,跨城带来的影响可以通过提高并发的来解决,比如三地三中心架构下在>=512并发下基本可以对齐同城、两地三中心下的性能吞吐
- 由此可见跨城部署对MGR_1(RPO<>0)的影响很大
3.1.6. 性能抖动
实际使用中,我们不仅关注性能数据如何,还需要关注性能抖动情况。毕竟如果抖动像过山车一样,对实际用户的体验也非常差。我们对TPS实时输出数据监控展示,考虑到sysbenc工具本身不支持输出性能抖动的监测数据,于是采用数学上的变异系数作为对比指标:
- 变异系数(Coefficient of Variation, CV): 变异系数是标准差除以平均值,通常用来比较不同数据集的波动情况,尤其是当平均值差异较大时。CV 越大,数据相对于平均值的波动越大
以256并发下oltp_read_write场景为例,我们统计分析MGR_1(RPO<>0)、DN(RPO=0)在同机房、同城三中心、两地三中心、三地三中心五种部署模式下的TPS抖动情况。 实际抖动图如下,实际各场景抖动指标数据如下
| CV | 同机房 | 同城三中心 | 两地三中心 | 三地三中心 |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| DN | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |

从测试结果可以看出:
- MGR在oltp_read_write场景下TPS呈现不稳定的状态,中间竟然无缘无故猛跌现象,在多个部署场景多次试验中均发现这个现象。 相比下DN就十分稳定
- 计算变异系数CV, MGR的CV很大6%~10%,同机房延迟最小的情况时竟然还达到最大值10%,而DN的CV为比较稳定2%~4%, DN比MGR的性能稳定性基本高到2倍
- 由此可见MGR_1(RPO<>0)的性能抖动比较大
