




点击上方 蓝字 关注一臻数据👆
免费领取 DeepSeek➕数据AI知识库 🔗 一起共建共进
❝凌晨3点,线上日志系统分析突然告警,用户反馈交易失败!
运维小张急忙点开日志平台开始排查,输入几个关键词,等待结果...10秒...30秒...1分钟过去了,系统仍在"努力加载中"
小张叹了口气:"又要等到天亮了。"
"为什么查询日志这么慢?有没有更高效的解决方案?"
正巧,Apache Doris 从2.0版本开始推出了倒排索引技术,让日志查询速度大幅度提升,并且同样的原始数据,Doris 的存储成本只需要 Elasticsearch 的 20% 左右。
本文将带你深入了解Apache Doris倒排索引技术,从原理到实践,全方位掌握这把日志分析的利器。

Doris倒排索引:日志查询的超级加速器
一本厚厚的字典,如果你想查找包含某个字的所有页码,传统方式需要逐页翻找。但字典尾部的索引部分却能直接告诉你:这个字在第25、68、129页出现。这就倒排索引*的基本思想**。
倒排索引是什么?
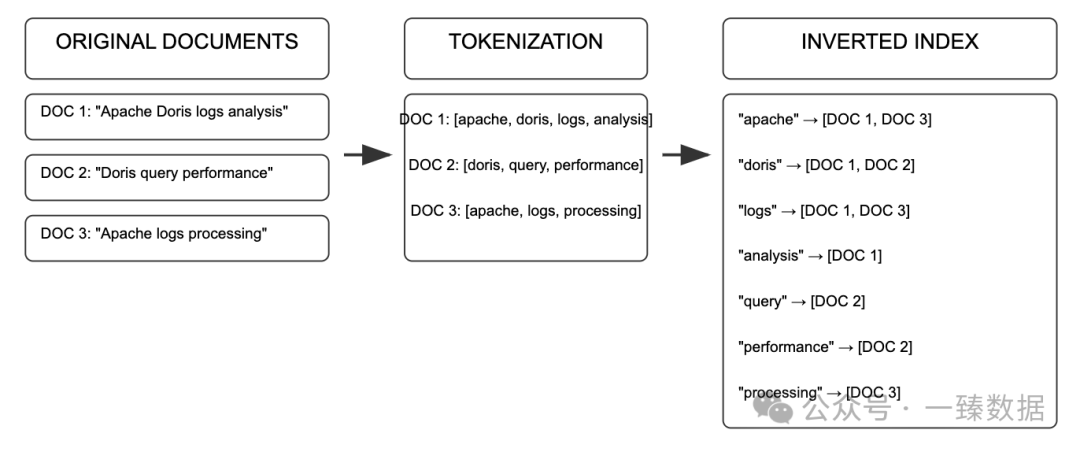
在Apache Doris中,倒排索引是一种存储结构,它建立了"词->行"的映射关系。与传统的正排索引(根据行ID找内容)相反,倒排索引允许你直接根据内容找到对应的行。
核心原理:
这种方式特别适合日志分析场景,因为日志查询通常是基于内容的过滤,如"查找所有包含'ERROR'的日志"。
什么样的查询能被加速?
Doris的倒排索引支持多种查询类型:
MATCH_ANY(匹配任一词)、
MATCH_ALL(匹配所有词)、
MATCH_PHRASE(短语匹配)
=、
!=>、
>=、
<、
<=相比传统的LIKE '%keyword%'
模糊匹配,倒排索引的全文检索能提供N倍以上的性能提升。
Doris倒排索引的技术突破
为什么Apache Doris的倒排索引在处理日志查询时如此高效?这得益于其多项技术创新。
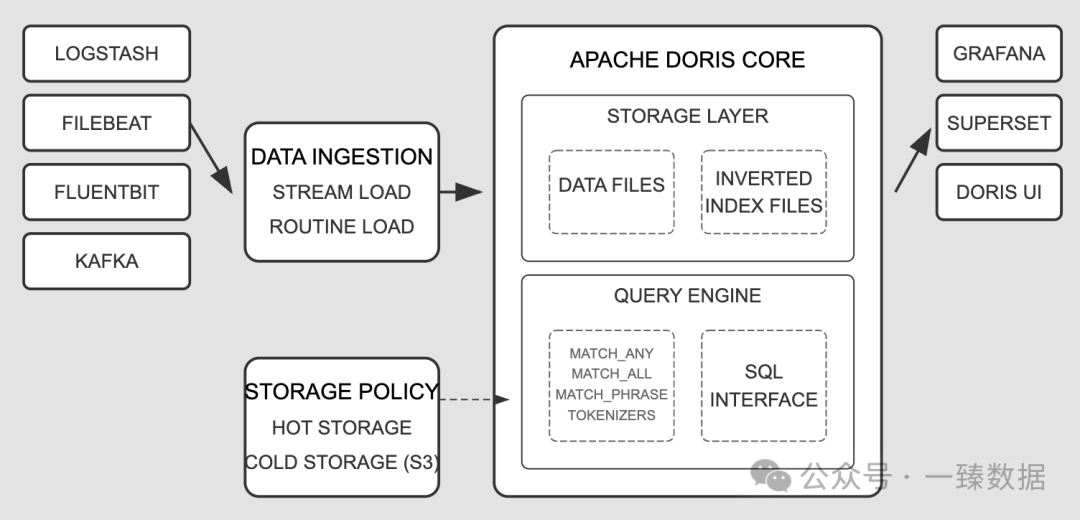
1. 高性能写入
传统日志系统如Elasticsearch在高速写入时常遇到瓶颈,主要源于两点:
Doris针对这些问题做了巧妙优化:
综合这些优化,Apache Doris的写入性能比Elasticsearch高3-5倍,即使面对每秒GB级别的日志流量也能稳定处理。
2. 低成本存储
日志数据通常体积庞大,存储成本是一个不容忽视的问题。
Doris通过多项技术大幅降低存储成本:
实际生产环境中,同样数据量下Doris的存储成本只有Elasticsearch的20%左右。
3. 超快检索分析
Doris对日志场景的查询做了专门优化:
4. 灵活Schema
日志数据的结构经常变化,新字段不断添加。
Doris通过以下技术支持这种灵活性:
相比Elasticsearch的Dynamic Mapping,Doris的方案更灵活,允许一个字段有多种类型,减少冲突。
实战指南:构建高性能日志分析平台
接下来,我们跟着小张,一起来看看:基于Apache Doris的倒排索引如何构建一个高性能低成本的日志分析平台:
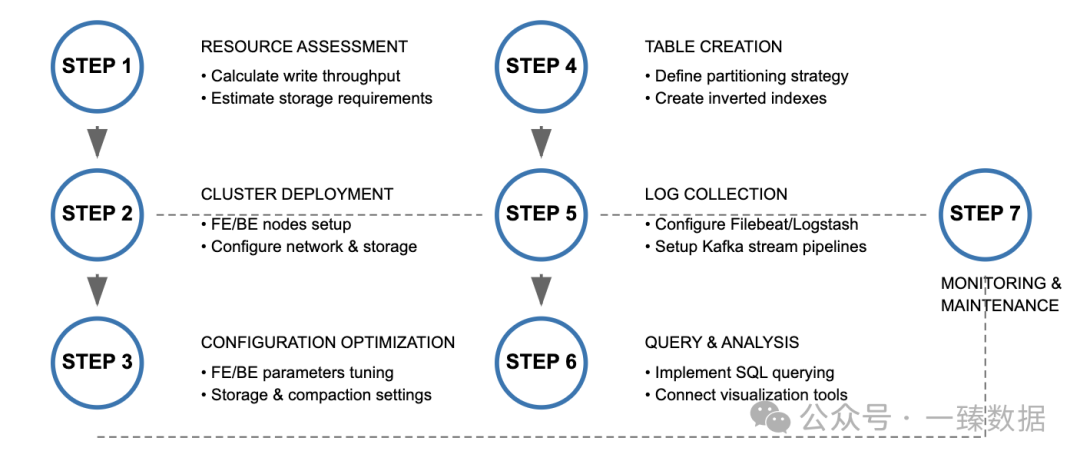
Step 1:需求分析与资源评估 - "算算你的日志有多重"
小张负责一个电商平台的日志系统迁移,每天日志量约100TB。
他首先计算了资源需求:
日平均写入吞吐 = 100TB/86400s ≈ 1.2GB/s
考虑峰值系数2倍,峰值写入 ≈ 2.4GB/s
估算单核写入性能10MB/s,需要约240核心专用于数据写入
存储需求:
假设压缩比5:1,每天20TB压缩后的数据
热数据保留3天,需要60TB存储
冷数据保留30天,需要600TB对象存储
根据这些数据,小张规划了15台BE节点(32核256GB内存,10块600GB SSD盘)和3台FE节点。
Step 2:集群部署 - "搭建你的日志大本营"
小张使用物理机部署集群,特意选择了本地SSD而非云盘,因为测试显示前者随机I/O性能至少高3倍。
"集群搭建看似简单,但有个小技巧,"小张说,"我们把FE和BE放在不同机器上,避免资源争抢。另外,把网络调整为万兆,这样数据传输不会成为瓶颈。"
Step 3:参数优化 - "调教你的引擎"
这一步极为关键,小张根据日志场景特点调整了大量参数:
FE配置优化:
max_running_txn_num_per_db = 10000 # 支持高并发导入
enable_round_robin_create_tablet = true # 均匀分布数据
BE配置优化:
write_buffer_size = 1073741824 # 1GB写缓冲,减少小文件
disable_storage_page_cache = true # 日志数据太大,关闭页缓存
inverted_index_searcher_cache_limit = 30% # 增加索引缓存
"有一次半夜系统写入变慢,"小张回忆道,"排查后发现是默认的BE心跳容忍次数太低,导致临时网络抖动就误判BE宕机。
调整max_backend_heartbeat_failure_tolerance_count
后,系统稳如泰山。"
Step 4:创建表结构 - "定义你的日志模型"
小张设计了一个优化的表结构:
CREATE TABLE log_table
(
`ts` DATETIME,
`host`TEXT,
`path`TEXT,
`message`TEXT,
INDEX idx_host (`host`) USING INVERTED,
INDEX idx_path (`path`) USING INVERTED,
INDEX idx_message (`message`) USING INVERTED PROPERTIES("parser" = "unicode", "support_phrase" = "true")
)
ENGINE = OLAP
DUPLICATEKEY(`ts`)
PARTITIONBYRANGE(`ts`) ()
DISTRIBUTEDBY RANDOM BUCKETS 60
PROPERTIES (
"compression" = "zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-30",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "60",
"storage_policy" = "log_policy_3day"-- 存算分离不需要
);
这个设计包含几个关键要点:
小张解释道:"我们最初没用support_phrase
,结果用户抱怨短语搜索慢。
加上这个参数后,搜索'server error'这种短语的速度提升了8倍,虽然占用更多空间,但绝对值得。"
Step 5:日志采集 - "让数据流动起来"
小张团队使用Filebeat采集应用日志,通过Stream Load API直接写入Doris:
filebeat.inputs:
-type:log
enabled:true
paths:
-/path/to/your/log
multiline:
pattern:'^[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate:true
match:after
output.doris:
fenodes:["http://fehost1:http_port"]
user:"your_username"
password:"your_password"
database:"your_db"
table:"log_table"
headers:
format:"json"
read_json_by_line:"true"
load_to_single_tablet:"true"
"采集环节有个坑,"小张说,"如果不设置load_to_single_tablet
,会导致大量小文件,压缩效率低下。
修改后写入性能提升了3倍,还节省了35%的空间。"
Step 6:查询分析 - "让数据会说话"
平台上线后,用户通过SQL查询日志,比如:
-- 查找包含错误关键词的最新日志
SELECT ts, host, message
FROM log_table
WHERE message MATCH_ANY 'error exception failed'
ORDERBY ts DESCLIMIT100;
-- 查找特定IP在特定时间段的访问日志
SELECT * FROM log_table
WHERE host = '10.0.0.123'
AND ts BETWEEN'2023-06-01'AND'2023-06-02'
ANDpath MATCH_PHRASE '/api/payment';
小张团队还将Doris与Grafana集成,创建了实时监控面板(也可以直接使用Doris Manager对Doris集群进行运维管理,自带监控告警体系)。
"以前分析一个bug可能需要一整天导出日志、筛选分析,"一位开发说,"现在直接一条SQL,几秒钟就能定位问题根源。"
性能对比,数据说话
小张团队对比了迁移前后的性能数据:
"数据不会撒谎,"小张说,"Doris的倒排索引技术确实改变了我们处理日志的方式。"
实用技巧与陷阱避坑
基于团队血泪经验,小张总结了几点建议:
1. 索引不是越多越好:每个倒排索引都会增加写入负担和存储空间,只为真正需要快速检索的字段建索引
2. 分词器选择很重要:
3. 避免范围过滤的坑:不要用MATCH_ANY
做范围过滤,如message MATCH_ANY '>= 500'
,这会匹配包含">="或"500"的所有记录,而非大于500的值
4. 添加冷数据策略:
CREATE RESOURCE"log_s3" PROPERTIES(
"type" = "s3",
"s3.endpoint" = "your_endpoint",
"s3.bucket" = "your_bucket"
);
CREATESTORAGEPOLICY log_policy_3day PROPERTIES(
"storage_resource" = "log_s3",
"cooldown_ttl" = "259200"
);
实际应用案例
Apache Doris倒排索引技术在多个行业找到了用武之地:
1. 电商网站:实时监控订单异常,例如"支付超时"类错误,通过MATCH_PHRASE
快速定位问题
2. 金融系统:追踪交易日志中的可疑模式,如message MATCH_ALL 'transfer failed suspicious'
3. IoT平台:分析设备报错日志,识别批量故障模式
4. 游戏服务:监控玩家行为日志,检测作弊行为
...
结语:让日志不再是负担
随着数字化转型加速,日志数据的重要性与日俱增,但传统解决方案往往让人望而却步——成本高,性能差,维护累。
Apache Doris的倒排索引技术改变了这一现状,让日志分析变得简单、高效且经济。不必再担心凌晨三点的系统告警,不必再为高昂的存储费用而头疼,也不必再面对动辄数分钟的查询等待。
正如一位用户所说:"Doris不只是提升了我们的日志分析能力,它还把我们从数据的奴隶变成了数据的主人。"
下期,我们将一起探讨其它更有趣有用有价值的内容,敬请期待!

完
一臻数据致力于大数据AI时代的前沿内容分享,会持续分享更多有趣有用有态度的知识。同时也欢迎大家投稿,共建共进,帮助圈友们冲破认知壁垒,实现自我提升!
另外,整理了份 一臻数据知识库 ,其中包含 Apache Doris和 Data+AI 的学习资料、学习课程、白皮书、研究报告、行业标准 和 实践指南 等内容,会持续更新,欢迎关注公众号,免费领取。
🔗 欢迎扫描下方二维码 ⬇️ 备注 666 免费领取资料  加入Doris官方群和全球最活跃的PowerData数据社区❗️
加入Doris官方群和全球最活跃的PowerData数据社区❗️

往期推荐

点击下方蓝字关注一臻数据
