




本文对论文《SEED: Domain-Specific Data Curation With Large Language Models》进行解读,全文共5286字,预计阅读需要15至25分钟
在当今数据驱动的时代,高效的数据策管成为解锁数据价值的关键。然而,传统方法难以满足多样化需求,导致效率低下。此文介绍的SEED系统,通过利用大型语言模型(LLMs),为数据策管提供了一种创新、高效且自动化的解决方案,显著提升了数据处理的效率和准确性。
(一)数据策管的现状与挑战
数据策管:数据策管(Data Curation)是将数据转化为可操作见解的关键任务,涵盖了数据的发现、提取、转换、清洗和整合等环节。然而,由于不同领域对数据策管的需求差异巨大,通用的工具往往无法满足特定需求。
解决方案:因此,数据科学家通常需要为每个数据集和任务定制特定领域的解决方案,例如编写领域特定的代码或在大量标注数据上训练机器学习模型。这一过程不仅耗时费力,而且难以复用,导致企业在数据策管上投入巨大成本。
(二)大型语言模型(LLMs)的潜力
LLMs能力:近年来,大型语言模型(LLMs)在自然语言处理(NLP)领域取得了显著进展,展示了在多种任务中的强大能力。LLMs不仅能够生成高质量的文本,还能进行复杂的推理和语义理解。这些能力使得LLMs在数据策管任务中具有巨大的潜力,尤其是在需要语义理解和复杂逻辑处理的场景中。
问题:然而,直接将LLMs应用于数据策管任务也存在一些问题,例如高成本、低效率以及对大规模标注数据的依赖。为了解决这些问题,此文提出了SEED(Simple, Efficient, and Effective Data Management via Large Language Models),这是一个利用LLMs作为编译器的系统,能够自动生成特定领域的数据策管解决方案。
(三)SEED的核心思想
核心思想:SEED的核心思想是利用LLMs的强大能力,通过自然语言描述任务、输入数据和期望输出,自动生成一个混合执行管道。
管道优势:这个管道结合了LLM查询和更具成本效益的替代方案,例如基于向量的缓存、LLM生成的代码以及在LLM标注数据上训练的小型模型。通过这种方式,SEED不仅能够提高数据策管任务的效率,还能显著降低对LLM的依赖,从而降低成本。
(一)SEED的总体架构
SEED架构
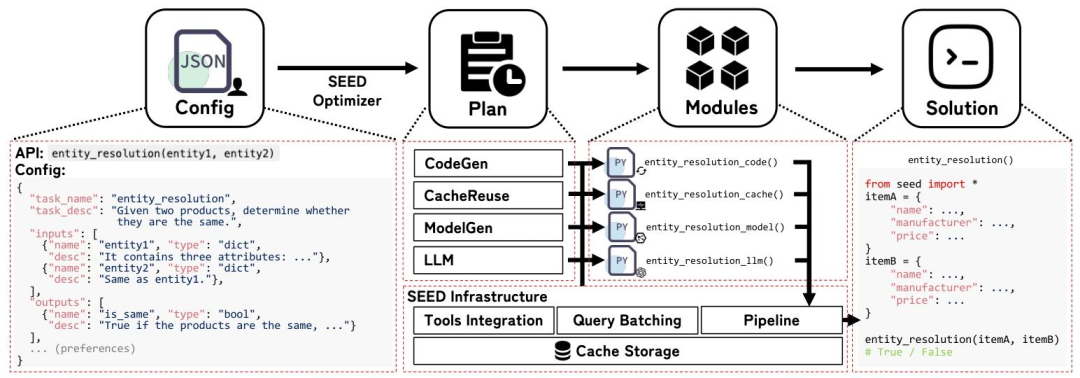
SEED的总体架构包括三个主要部分:模块(Modules)、基础设施(Infrastructure)和优化器(Optimizer)。这些组件协同工作,为用户提供高效、灵活且可扩展的数据策管解决方案。
模块(Modules):模块是SEED的核心组件,对应于不同类型的物理操作符。通过组合这些模块,SEED能够为特定的数据策管任务生成优化的解决方案。SEED目前支持四种模块:
CodeGen(代码生成):利用LLMs生成代码以处理数据。
CacheReuse(缓存复用):通过缓存LLM的查询结果,直接回答新的查询。
ModelGen(模型生成):使用LLM标注的数据训练小型机器学习模型。
LLM(直接调用LLM):直接调用LLM来处理数据,适用于需要语义理解的复杂任务。
基础设施(Infrastructure):基础设施为SEED提供了通用的功能支持,包括调度器、缓存存储和一些通用优化功能。这些组件共同提高了模块的效率和效果。
调度器:控制数据流,将数据路由到合适的模块,并聚合所有模块的结果以生成最终答案。
缓存存储:缓存LLM的查询结果和模块的输入输出对,支持模块高效利用缓存数据。
查询批处理:通过将多个查询合并为一个批处理查询,减少LLM调用次数,提高效率。
工具集成:允许用户提供的工具与LLM交互,动态选择工具以解决复杂问题。
优化器(Optimizer):优化器是SEED的核心组件之一,类似于数据库查询优化器。它根据数据策管任务的规范,自动选择使用哪些模块、配置模块的超参数,并将这些模块排序成执行管道。优化器的目标是在保证准确性的前提下,最小化执行成本。
(二)SEED的模块设计
CodeGen模块:
功能:CodeGen模块利用LLMs生成代码以处理数据。对于需要复杂逻辑的任务,CodeGen模块通过进化算法生成一组代码片段,这些代码片段可以相互补充,共同解决问题。
实现:CodeGen模块首先通过LLMs生成初始代码片段,然后通过进化算法逐步优化这些代码片段。进化算法包括代码分支生成和代码过滤两个阶段。代码分支生成通过不同的工具、提示重述、多样化建议和不同测试用例生成多个版本的代码片段。代码过滤则通过评估代码片段的准确性和成本,筛选出最有效的代码片段。
优势:CodeGen模块能够处理复杂的逻辑任务,生成的代码片段可以显著减少对LLM的依赖,从而降低成本。
2.CacheReuse模块:
功能:CacheReuse模块通过缓存LLM的查询结果,直接回答新的查询。这避免了重复调用LLM,从而显著提高了系统的效率。
实现:CacheReuse模块使用向量索引技术,将查询结果缓存到一个高效的索引结构中。当新的查询到达时,模块通过计算查询与缓存结果的相似度,直接返回最相似的结果。
优势:CacheReuse模块能够显著减少LLM调用次数,尤其在数据分布较为集中的任务中,能够大幅提高系统的效率和可扩展性。
3.ModelGen模块:
功能:ModelGen模块使用LLM标注的数据训练小型机器学习模型。这些模型可以用于处理数据策管任务,尤其是在需要语义理解和推理的场景中。
实现:ModelGen模块首先通过LLMs生成标注数据,然后使用这些数据训练小型模型。这些模型可以是分类器、回归器或生成器,具体取决于任务的需求。
优势:ModelGen模块能够利用LLM生成的伪标签进行训练,从而减少对大规模标注数据的依赖。同时,小型模型在推理阶段的效率更高,能够显著提高系统的整体性能。
LLM模块:
功能:LLM模块直接调用LLM来处理数据,适用于需要语义理解的复杂任务。
实现:LLM模块通过自然语言描述任务,将查询发送给LLM,并接收LLM的响应。为了提高效率,LLM模块可以结合工具集成,动态选择工具以解决复杂问题。
优势:LLM模块能够处理复杂的语义理解和推理任务,提供强大的推理能力。同时,通过工具集成,LLM模块能够更高效地解决问题。
(一)优化器的关键特性
动态规划与Skyline方法:
SEED优化器使用动态规划减少搜索空间,并通过Skyline方法存储可能成为最终计划一部分的子计划。Skyline方法通过评估子计划的代价和效果,筛选出最优的子计划。
动态规划通过逐步构建计划,避免了重复计算子计划,从而显著提高了优化器的效率。
模块优先级排序:
SEED优化器通过分析模块的执行成本和回退概率,能够高效地确定模块的优先级顺序。优先级排序使得优化器能够更高效地选择模块,从而减少LLM调用次数。
例如,在实体解析任务中,优化器通过优先级排序,优先选择CodeGen和CacheReuse模块,从而显著减少了LLM模块的调用次数。
动态优化:
随着SEED在执行过程中积累更多数据,优化器会动态重新优化执行计划,以适应数据分布的变化。动态优化使得SEED能够根据实际数据情况,逐步调整执行计划,从而提高系统的整体性能。
例如,在数据填充任务中,优化器在初始阶段仅使用CodeGen模块,随着缓存数据的增加,逐步引入ModelGen模块,进一步减少了LLM调用次数。
(一)实验设置
SEED任务:SEED的实验设计旨在验证其在多种数据策管任务中的性能和效率。实验涵盖了9个数据集和5种数据策管任务,包括实体解析(Entity Resolution)、数据填充(Data Imputation)、数据提取(Data Extraction)、数据标注(Data Annotation)和数据发现(Data Discovery)。这些任务不仅覆盖了SEED中所有类型的模块,还展示了SEED在不同场景下的适用性和效率。
模块:实验中,SEED使用了GPT-4作为LLM后端,温度参数设置为0,以确保生成结果的确定性。对于ModelGen模块,SEED使用了预训练的t5-small模型,并在1024个未标注的验证数据上进行微调,使用LLM生成的伪标签来模拟实际部署环境。CodeGen模块的分支数量从1或4中选择,其中4表示生成4个代码片段。
(二)实验结果
实体解析(Entity Resolution):
数据集:Amazon-Google和Abt-Buy。
评估指标:F1分数。
结果:
在Amazon-Google数据集上,SEED达到了79.2的F1分数,仅使用22.4%的LLM调用。
在Abt-Buy数据集上,SEED达到了92.8的F1分数,仅使用27.1%的LLM调用。
与仅使用LLM的解决方案相比,SEED显著减少了LLM调用次数,同时保持了较高的准确性。
数据填充(Data Imputation):
数据集:Buy和Restaurant。
评估指标:填充准确率。
结果:
在Buy数据集上,SEED达到了91.9的准确率,仅使用39.3%的LLM调用。
在Restaurant数据集上,SEED仅使用CodeGen模块,完全不调用LLM,准确率仅比LLM-only解决方案低5%。
SEED在少样本情况下表现出色,接近于使用数千个标注样本训练的监督学习方法。
数据提取(Data Extraction):
数据集:Wiki NBA。
评估指标:Token F1分数。
结果:
SEED在Wiki NBA数据集上达到了88.6的F1分数,仅使用22.5%的LLM调用。
SEED的表现优于现有的预训练模型(如DOM-LM)和纯LLM方法(如EVAPORATE-DIRECT)。
数据标注(Data Annotation):
数据集:OS。
评估指标:分类准确率。
结果:
SEED在OS数据集上达到了88.3的准确率,仅使用31.1%的LLM调用。
与少样本学习方法(如EFL和FT)相比,SEED显著提高了准确率,同时减少了LLM调用次数。
数据发现(Data Discovery):
数据集:Spider、OTT-QA和KaggleDBQA。
评估指标:F1分数。
结果:
SEED在Spider数据集上达到了85.7的F1分数,在OTT-QA数据集上达到了67.8的F1分数,在KaggleDBQA数据集上达到了63.5的F1分数。
SEED的表现优于传统的信息检索方法(如BM25和DrQA),尤其是在Spider和KaggleDBQA数据集上。
(三)优化器性能的深入分析
方法:SEED优化器通过动态规划和Skyline方法,能够在保证准确性的前提下,显著减少LLM调用次数。
高效准确:实验中,优化器生成的计划仅使用10.4%的LLM调用,同时F1分数仅比最优计划低2.9%。这表明优化器在选择模块和配置超参数时具有较高的效率和准确性。
动态调整:此外,优化器还能够动态调整执行计划,随着缓存数据的积累,逐步提高性能。例如,在实体解析任务中,优化器在初始阶段仅使用LLM和CodeGen模块,随着缓存数据的增加,逐步引入CacheReuse和ModelGen模块,进一步减少了LLM调用次数。
(四)模块性能的深入分析
SEED的各个模块在实验中表现出色,以下是对每个模块的详细分析:
CodeGen模块:
功能:CodeGen模块通过进化算法生成的代码片段能够有效处理复杂逻辑任务。例如,在数据提取任务中,CodeGen模块生成的代码片段能够解析HTML结构并提取所需信息。
实现:CodeGen模块首先通过LLMs生成初始代码片段,然后通过进化算法逐步优化这些代码片段。进化算法包括代码分支生成和代码过滤两个阶段。代码分支生成通过不同的工具、提示重述、多样化建议和不同测试用例生成多个版本的代码片段。代码过滤则通过评估代码片段的准确性和成本,筛选出最有效的代码片段。
优势:CodeGen模块能够处理复杂的逻辑任务,生成的代码片段可以显著减少对LLM的依赖,从而降低成本。
CacheReuse模块:
功能:CacheReuse模块通过缓存LLM的查询结果,直接回答新的查询。这避免了重复调用LLM,从而显著提高了系统的效率。
实现:CacheReuse模块使用向量索引技术,将查询结果缓存到一个高效的索引结构中。当新的查询到达时,模块通过计算查询与缓存结果的相似度,直接返回最相似的结果。
优势:CacheReuse模块能够显著减少LLM调用次数,尤其在数据分布较为集中的任务中,能够大幅提高系统的效率和可扩展性。
ModelGen模块:
功能:ModelGen模块使用LLM标注的数据训练小型机器学习模型。这些模型可以用于处理数据策管任务,尤其是在需要语义理解和推理的场景中。
实现:ModelGen模块首先通过LLMs生成标注数据,然后使用这些数据训练小型模型。这些模型可以是分类器、回归器或生成器,具体取决于任务的需求。
优势:ModelGen模块能够利用LLM生成的伪标签进行训练,从而减少对大规模标注数据的依赖。同时,小型模型在推理阶段的效率更高,能够显著提高系统的整体性能。
LLM模块:
功能:LLM模块直接调用LLM来处理数据,适用于需要语义理解的复杂任务。
实现:LLM模块通过自然语言描述任务,将查询发送给LLM,并接收LLM的响应。为了提高效率,LLM模块可以结合工具集成,动态选择工具以解决复杂问题。
优势:LLM模块能够处理复杂的语义理解和推理任务,提供强大的推理能力。同时,通过工具集成,LLM模块能够更高效地解决问题。
(一)LLMs在数据策管中的应用
SEED应用:近年来,LLMs在数据策管任务中的应用逐渐受到关注。许多研究尝试直接利用LLMs解决特定任务,例如实体解析、数据提取和数据标注。然而,这些方法主要集中在设计合适的提示(prompts)以提高LLMs在特定任务中的效果,而SEED则提供了一个通用框架,能够自动生成特定领域的数据策管解决方案。
举例:例如,EVAPORATE利用LLMs生成代码以解决数据提取任务,Chameleon利用LLMs与工具结合以解决问答任务。这些研究主要集中在如何通过LLMs解决特定任务,而SEED则提供了一个通用框架,能够自动生成特定领域的数据策管解决方案。
(二)应用型LLMs项目
除了学术研究,一些开源项目(如LangChain)也试图将LLMs集成到一个统一的平台上。然而,这些项目主要提供了一个实现平台,用户需要自行利用现有技术开发基于LLMs的应用程序。SEED则通过优化器和模块设计,解决了LLMs在数据策管中的效率和可扩展性问题。
(三)LLMs与工具集成的最新进展
工具结合:近年来,随着LLMs的快速发展,越来越多的研究开始探索LLMs与工具的结合。例如,HuggingGPT利用LLMs选择HuggingFace检查点,Chameleon将LLMs与网络搜索和程序执行工具结合,StructGPT利用LLMs生成函数调用参数。这些研究主要集中在如何通过工具集成提高LLMs的性能和效率。
SEED集成:SEED在工具集成方面更进一步,通过动态选择工具和反馈机制,使LLMs能够更高效地解决复杂问题。例如,在数据发现任务中,SEED通过LLM模块与工具集成,能够动态选择工具并逐步解决问题,显著提高了系统的性能和效率。
SEED优势:SEED通过利用LLMs的强大能力,提供了一个通用框架,能够自动生成特定领域的数据策管解决方案。实验结果表明,SEED在多种数据策管任务中表现出色,显著减少了LLM调用次数,同时保持了较高的准确性。SEED的优化器和模块设计不仅提高了系统的效率和可扩展性,还为数据策管任务提供了灵活的解决方案。
未来展望:未来,SEED可以进一步扩展其模块和优化器的功能,以支持更多类型的数据策管任务。此外,SEED还可以探索与其他技术(如强化学习和元学习)的结合,以进一步提高系统的性能和适应性。总之,SEED为利用LLMs进行数据策管提供了一个新的视角,有望在未来的数据管理领域发挥重要作用。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





