




热衷于分享各种干货知识,大家有想看或者想学的可以评论区留言,秉承着“开源知识来源于互联网,回归于互联网”的理念,分享一些日常工作中能用到或者比较重要的内容,希望大家能够喜欢,不足之处请大家多提宝贵地意见,我们一起提升,守住自己的饭碗。
正文开始

一、工具定位与核心能力
1. RagFlow:检索增强生成(RAG)专用流水线工具
核心能力:
✅ 端到端的RAG流程标准化管理
✅ 多源数据接入与向量化处理
✅ 检索结果可解释性分析
✅ 支持私有化部署和行业知识库定制典型场景:
📍 企业级知识库问答系统搭建
📍 法律/医疗等专业领域智能检索
📍 需要严格数据隔离的敏感场景
2. Dify:通用型AI应用开发平台
核心能力:
✅ 零代码可视化编排AI工作流
✅ 支持多模态模型接入(文/图/语音)
✅ 内置Prompt工程优化工具
✅ 提供API快速部署能力典型场景:
📍 快速构建智能客服/文案生成工具
📍 多模型混合编排实验
📍 初创团队敏捷开发验证
二、关键对比维度
| 对比项 | RagFlow | Dify |
|---|---|---|
| 技术门槛 | ||
| 数据处理 | ||
| 模型支持 | ||
| 部署方式 | ||
| 安全合规 | ||
| 成本模型 |
三、选择决策树
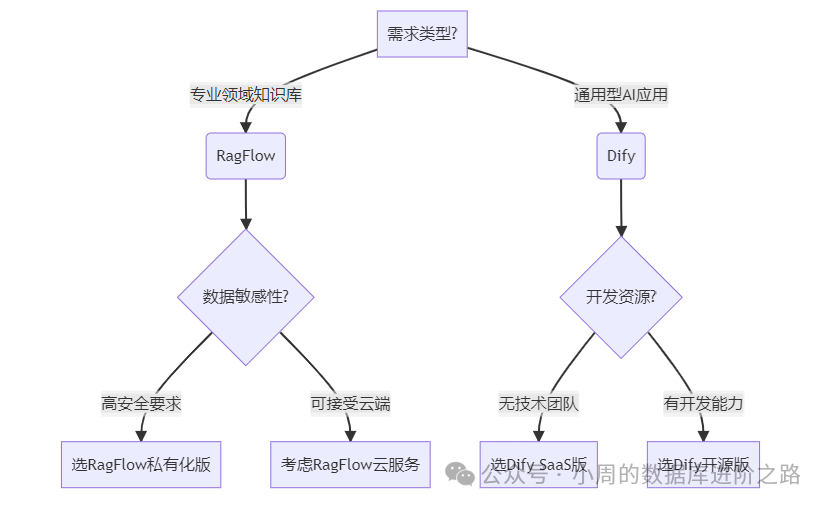
四、实践建议
选择RagFlow的3个信号:
需要处理大量行业专有知识文档 对检索准确率要求>95% 存在数据出境合规限制
选择Dify的3个信号:
需要快速验证多个AI应用场景 团队缺乏机器学习工程师 业务需求涉及多模态交互
五、进阶组合方案
混合架构示例:
RagFlow(知识库管理)
↓
Dify(应用层交互)
↓
企业微信/Web终端
优势:既保障核心知识资产安全,又快速实现业务应用落地
“特别提示: 2023年Gartner报告显示,78%的RAG项目失败源于工具选型不当。建议:
先用Dify制作原型验证需求 数据规模超千万级时迁移到RagFlow 关键系统建议双平台AB测试
文中的概念来源于互联网,如有侵权,请联系我删除。
欢迎关注公众号:小周的数据库进阶之路,一起交流数据库、中间件和云计算等技术。如果觉得读完本文有收获,可以转发给其他朋友,大家一起学习进步!感兴趣的朋友可以加我微信,拉您进群与业界的大佬们一起交流学习。
文章转载自小周的数据库进阶之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
