




针对通联数据特有的多层次结构和高频时序特征,DolphinDB 推出了高效数据导入解决方案 —— ImportTLData 模块。该模块通过结构化数据处理流水线,能够实现多品种金融数据的高效导入,为 Alpha 挖掘、风险建模等场景提供高质量的基础数据支撑。今天就带大家了解一下 DolphinDB 通联历史数据导入模块的实现过程。
通联历史数据导入模块涵盖了哪些数据?
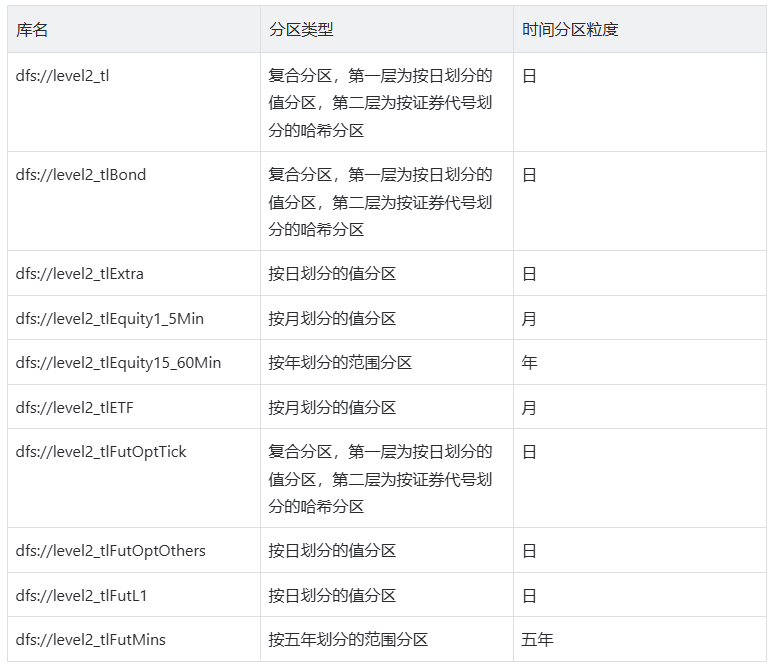
证券基础行情:涵盖沪深市场股票、债券、可转债逐笔委托/成交数据及行情快照 衍生品数据:包含期货期权 L2 行情快照及期货 L1 行情快照 时序聚合数据:权益、债券、指数等品种 1-60 分钟多粒度 K 线数据 特色数据集:深交所 ETF 实时申赎行情、指数盘后数据
如何导入数据?
下载通联数据导入模块 ImportTLData,将其同步到服务器的相应目录上 使用 DolphinDB 脚本调用该模块 通过 ImportTLData 定义符合自有环境的数据导入函数 设定需要导入数据的起止时间,调用定义的导入函数,执行数据导入任务,即通过前台任务、后台任务、定时任务等方式来导入历史数据和增量数据
// 导入模块use ImportTLData::loadTLEntrust// 定义数据导入函数def loadEntrustStock(startDate, endDate, loadType){// 设定参数, 需根据实际情况改动userName = "admin"password = "123456"dbname = "dfs://level2_tl"tableName = "entrust"filePath = "/hdd/hdd3/customer/tlData/"// 增量导入if(loadType == "daily"){idate = today()infoTb = loadTLEntrustStock(userName, password, idate, idate, dbname, tableName, filePath, loadType)}// 批量导入else if (loadType == "batch"){infoTb = loadTLEntrustStock(userName, password, date(startDate), date(endDate), dbname, tableName, filePath, loadType)}return infoTb}
导入常见问题
Q1:是否可以并发执行同一时间段多个数据导入任务?
Q2:是否可以根据时间段的不同,
并发执行同一数据导入任务?
Q3:如何获取具体数据导入任务的运行信息?
infoTb = loadSZTradeStat(startDate, endDate, loadType)
获取后台任务的状态
getRecentJobs()
通过以上函数返回的结果查询所需的 jobId ,再通过以下函数获取相应的运行信息 getJobMessage(jobId) :以字符串形式返回运行信息 getJobReturn(jobId) :以表的形式返回运行信息


文章转载自DolphinDB智臾科技,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
