






一、背景
ADB MySQL的存储引擎数据模型如下:
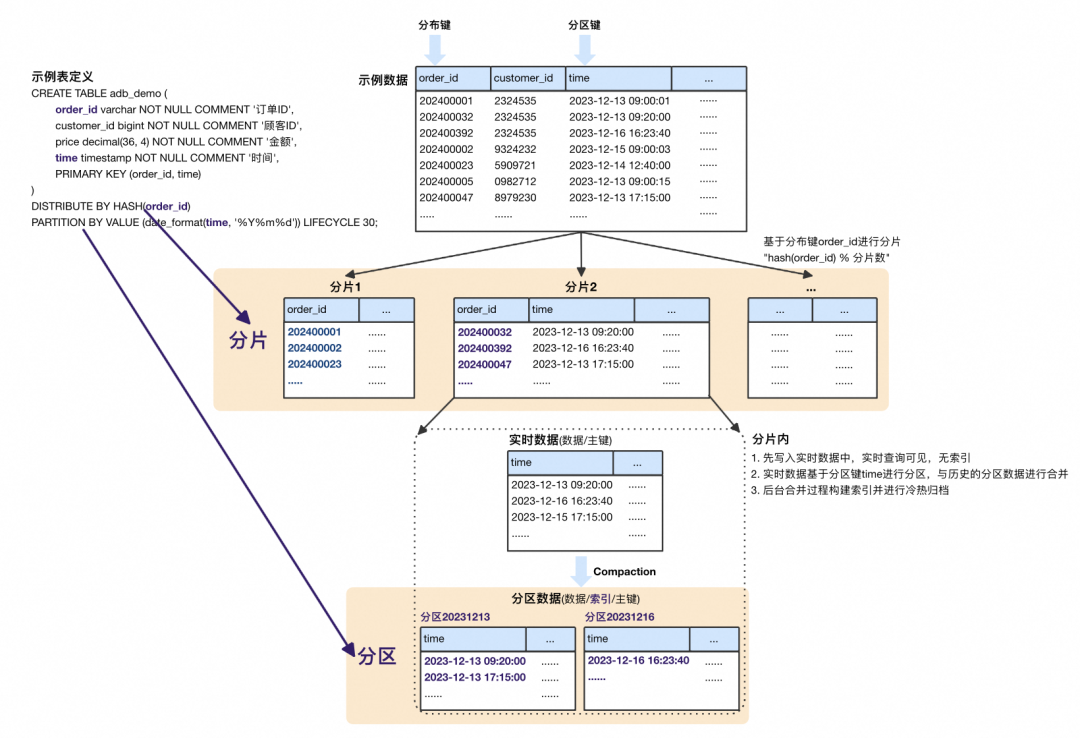
表数据首先基于分布键order_id进行分片,将整张表数据打散成N份。分片内部基于分区键time按天进行分区,首先写入到实时数据中对用户查询可见,后台Compaction时与历史分区进行合并,构建索引并以分区为粒度做冷热归档。模型示意如下:
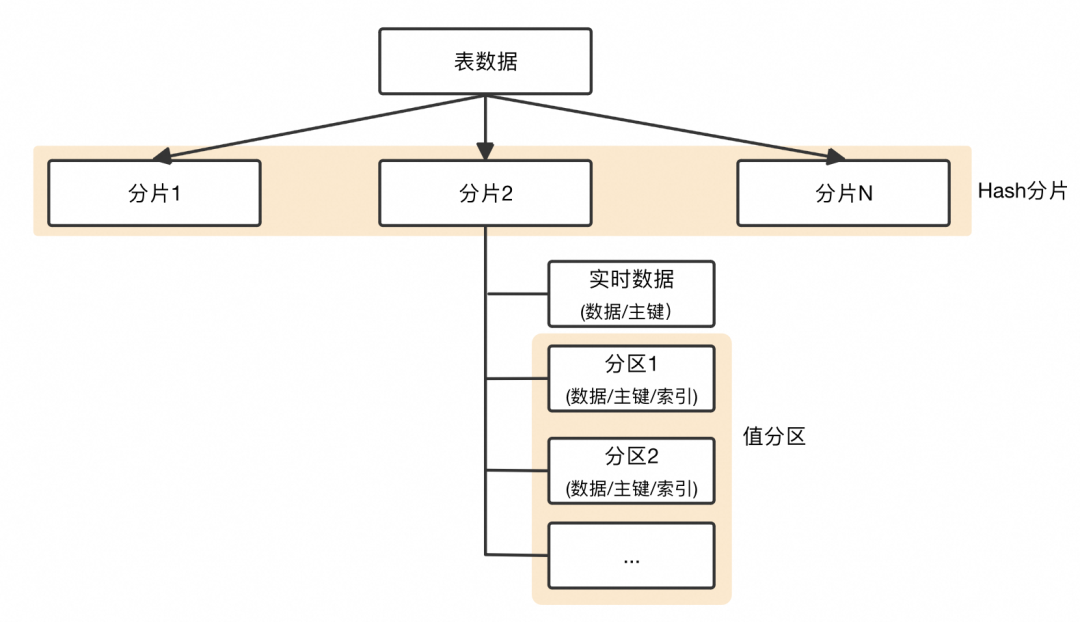
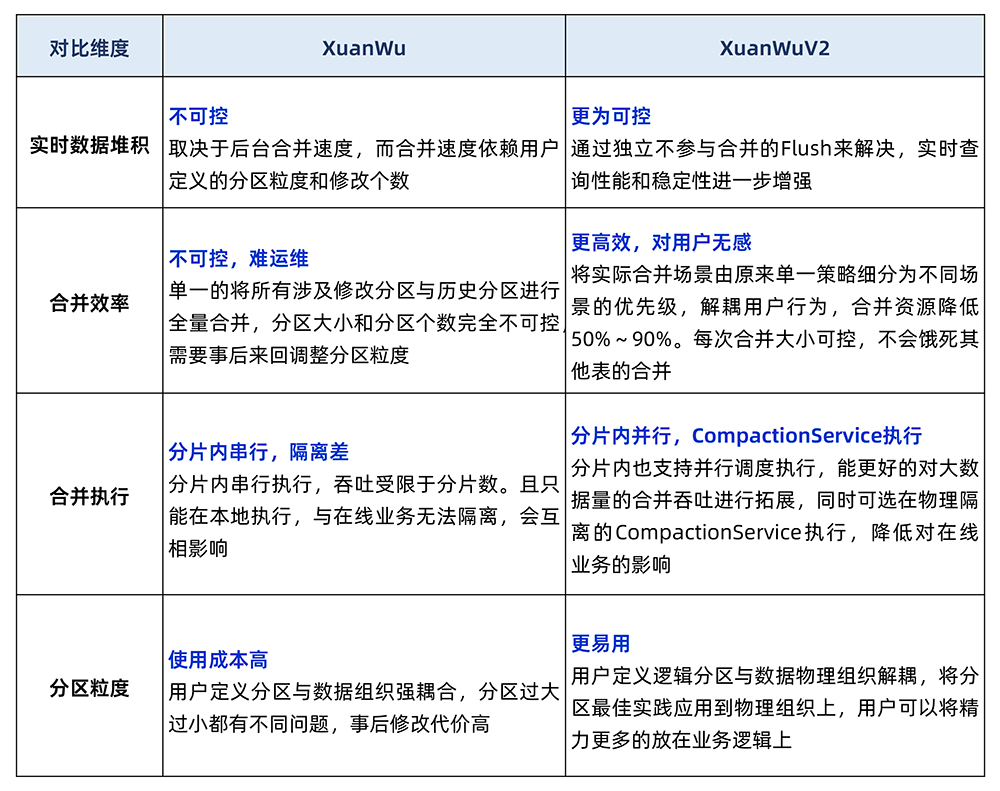
实时数据堆积。分片内实时数据在合并到分区前没有索引,而合并由于数据组织的原因只能串行。当写入速度大于后台合并速度时实时数据会积压,会导致典型查询慢问题。 分区粒度不可控。分片内的每次合并,都要将实时中涉及到的历史分区全量合并,产成新的分区数据。在分区由用户定义的前提下,定义分区很小时,会导致大量小文件,而定义分区很大时,合并开销又大大增加,进一步导致实时数据堆积问题。这些都只能事后运维干预,开销极大。
横向拓展不轻量。扩缩容等操作时需要搬迁本地热分区数据,扩缩容速度受限于本地热数据大小。典型云上用户大多数据都是需要分析的热数据,无法体会到快速扩缩容的云原生使用体感。
为了能更好的解决这类问题,满足线上各类用户的使用场景,我们设计开发了新的单机引擎XuanWuV2,数据全OnDFS,更精细的数据组织、更稳定高效的IO和更轻量的横向拓展性。
二、XuanWuV2引擎
1. 数据模型
针对在XuanWu中碰到的问题,我们参考业界经典LSM结构,并结合自身数据分布特点,设计了新的数据组织模型。分片内示意如下:
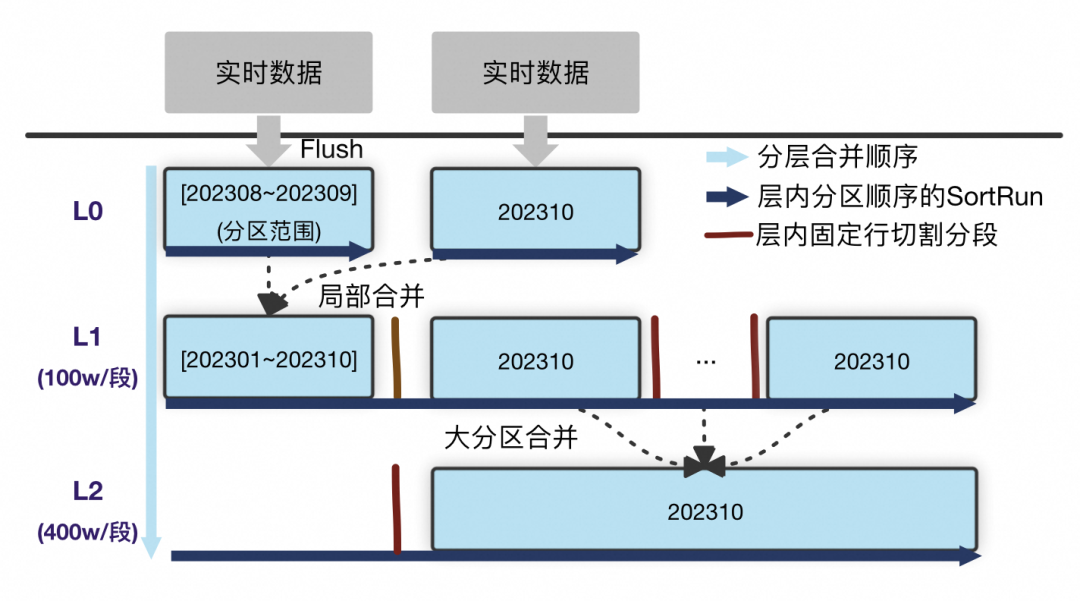
L0。来自实时数据的Flush产生物理文件,物理文件内按用户定义逻辑分区有序组织。因此L0的每一个物理文件都是按分区顺序的SortRun; L1及以下层。来自上层的局部合并,整层是一个逻辑SortRun,按分区有序。SortRun按固定行切割为物理文件进行组织,层级间大小相差一个系数。
L0 Flush。实时数据最高优Flush到L0,转换为读友好数据提供查询,不参与历史分区的合并。解决实时数据堆积问题;
L1局部合并。L0中数据在分区维度上选择L1中有分区重叠的物理文件,局部合并到L1中,从算法角度最大化降低实时写入的合并放大;
大分区合并。上一层的大分区跨多个物理文件时会有额外的读放大,以更低优的策略合并到下一层优化为大的物理文件。
2. 数据、元数据与索引
除了数据模型和合并的变化外,我们还在原来按固定行组织列级IO块的基础上,增加了按固定大小的IO块组织。相应的也增加了IO寻址用的OrdinalIndex,并对这类元数据进行分层管理,以解决大数据规模下的元数据内存占用问题。
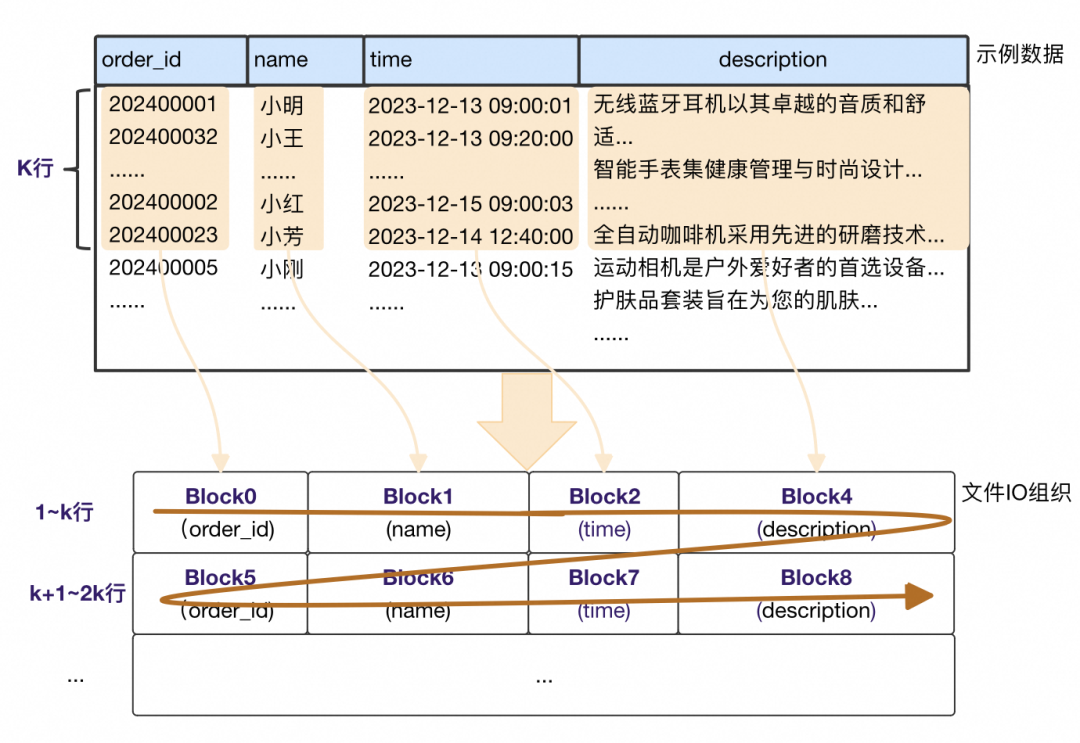
b. 大小对齐
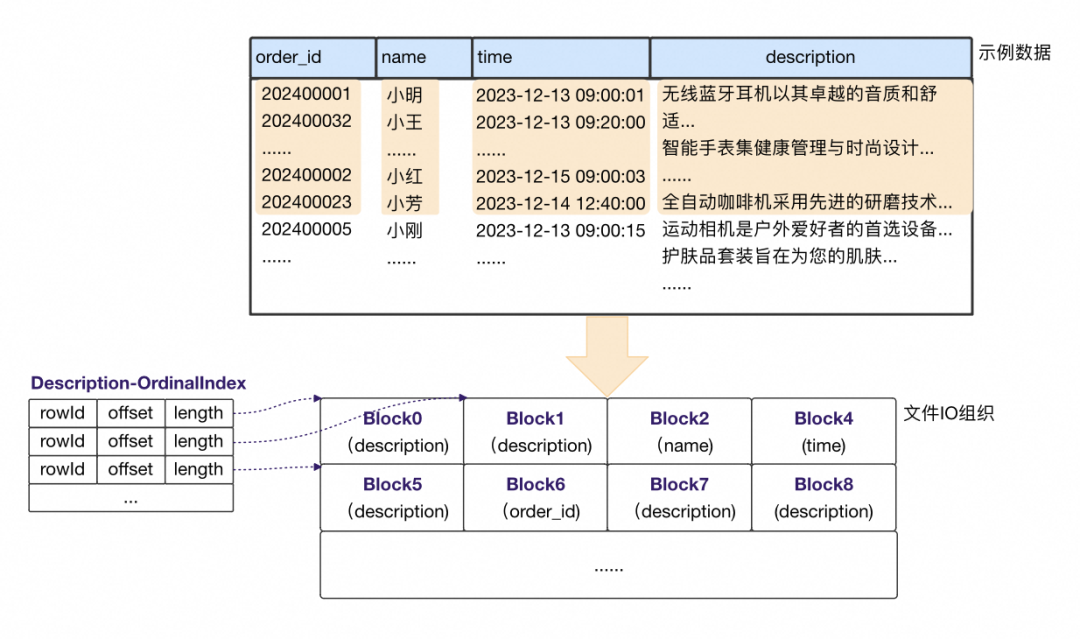
对比XuanWu的按行IO组织:
不同列IO块大小(压缩前)是固定的。对比固定行IO组织下,description列由于单条记录过大,单IO块比其他列大的多。 多了额外的辅助结构OrdinalIndex。同样IO大小下,不同列能容纳的行数是不一样的,基于行号去随机寻址IO块需要辅助结构,记录每个IO块的开始rowId和IO块信息,如上Description列的OrdinalIndex每条记录对应每个Block的信息。
从不同维度对比下:
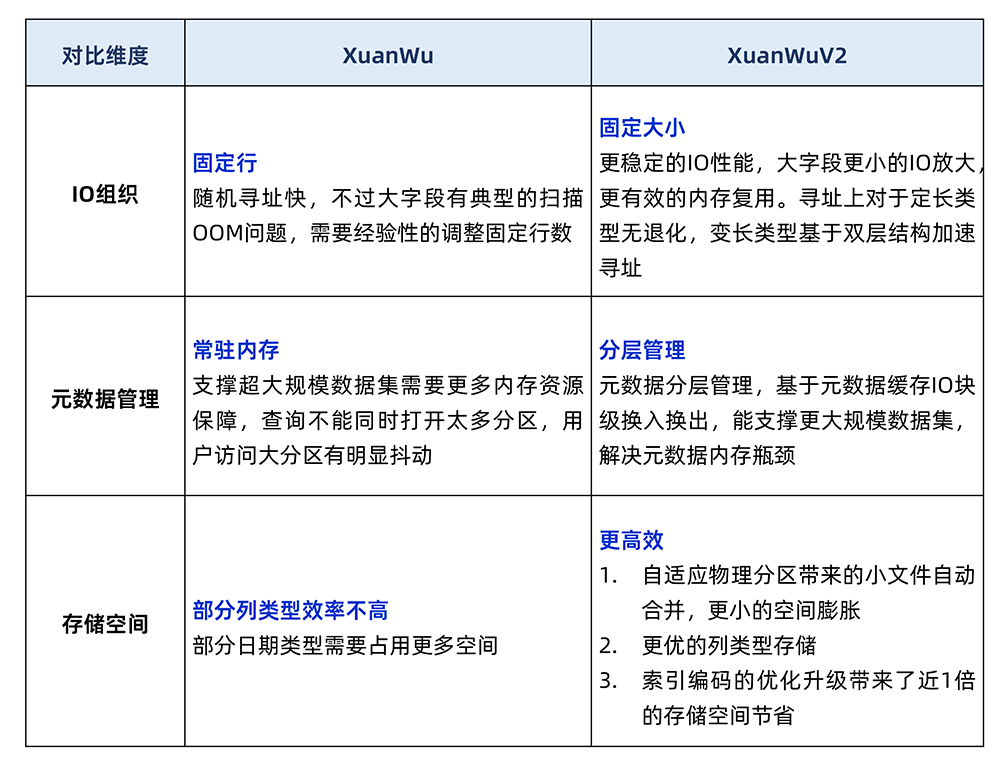
3. 云原生
在内核之上,我们基于XuanWuV2的多版本管理做了更彻底的存算分离,分区数据全OnDFS,热分区Pin到本地缓存中加速查询。通过计算资源组的不同访问模式来满足在离线查询的不同需求,典型的:
在线(交互式)查询,访问本地Pin的热分区数据,满足较为敏感的延迟需求;
离线(吞吐型)查询,直接访问DFS,能做到更好的并发控制和计算资源的横向拓展。
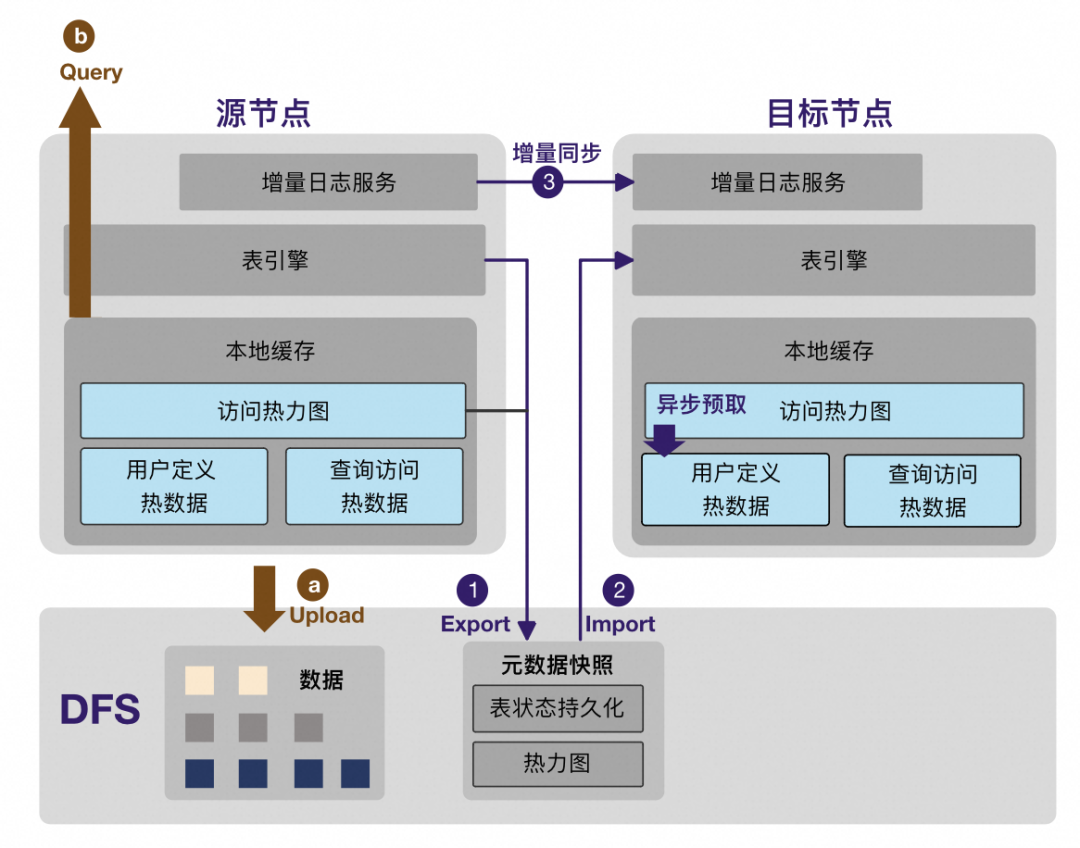
产生的分区数据上传到DFS中,同时将用户定义热数据Pin到本地缓存提供查询;
查询透过表引擎访问,本地缓存中记录数据访问热力图。
扩缩容活动:
源节点Export出去表在DFS上快照版本信息,作为恢复元数据。同时Export源节点访问热力图; 目标节点Import快照版本信息,恢复表引擎状态。同时Import热力图启动高频访问数据的异步加载; 源节点从快照位点开始增量同步到目标节点,追齐后切换提供查询。
对于源节点访问的本地热数据,目标节点在热力图异步预取成功前会直接访问DFS,针对此类场景我们基于每个查询的具体结果集,以Batch的方式提前并发异步预读访问的数据,加速冷数据的访问。
三、总结
👇点击文末「阅读原文」查看XuanWuV2官方文档,即可了解更多内容。




点击查看 XuanWuV2引擎介绍

