




本文将重点介绍数据库高可用架构相关原理、优缺点及应用场景,其余三点将在下一篇文章介绍。
ps:在这篇文章即将发表,网络上传出阿里云新加坡可用区机房火灾故障,可见构建高可用架构重要性。详见:突发火灾!阿里云(新加坡节点)崩了

高可用(High Availability, HA)是指设计数据库系统以确保在预定的服务级别协议(SLA)内尽可能减少服务中断。在现代企业环境中,数据是至关重要的资产,任何计划外的停机都可能导致经济损失、客户满意度下降以及品牌信誉受损。
数据库架构有一般可以分为集中式、分布式,其中集中式又可分为单机、主从集群、共享集群。通过名称就能简单判断,单机就是单台机器。Google 有相关数据,服务器每百台年故障率大约在3台左右。因此,单机架构系统宕机是必然的。
业内常说的数据库高可用架构,主要包括:主从集群、共享集群、分布式集群以及云原生集群架构。
主从(Master Slave)是经典的高可用架构,主节点产生的事务日志在一个或多个从节点重放,通过两个及以上节点的数据冗余,从而实现高可用。
典型产品有 MySQL Master Slave、Oracle Data Gaurd、MongoDB Replica Set 等。MySQL 由于强大的社区,高可用架构特别丰富,早些年的MMM、MHA、PXC,以及这些年官方推出的MGR、Cluster,开源社区的Orch等等。
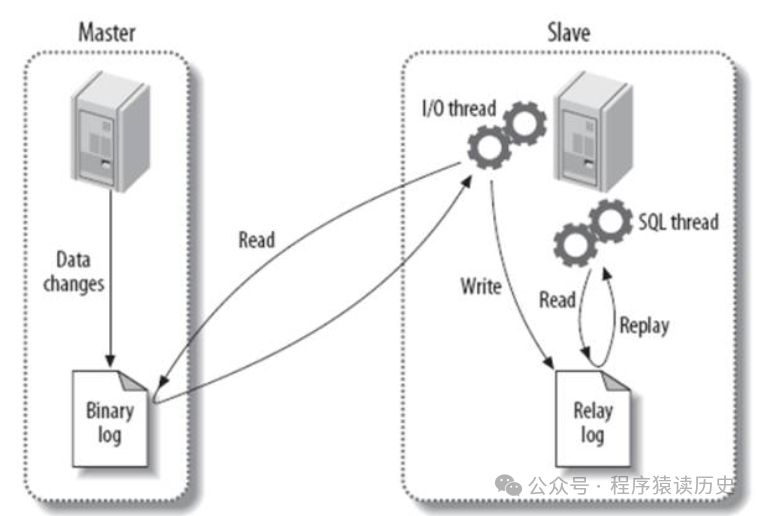
另外,主从架构不仅提高了可靠性,还能通过读写分离、降低主数据库的负载等。不过使用读写分离,需要在数据新鲜度和数据库响应时间需要做平衡。
本文讨论的分布式数据库是两大类,一类是中间件(包括 SDK 和 Proxy 两种形式)加传统关系数据库(如MySQL、Postgres等),这类架构有个更响亮称呼:分库分表架构。中间件代表产品有 TDDL、MyCAT、Sharding-Sphere等;另一类是基于分布式算法实现的 NewSQL数据库,代表产品有Spanner、YugabyteDB、CockRoachDB、TiDB、OceanBase等。(金篆科技的 GoldenDB、亚信科技的 AntDB 等产品,把中间件和传统关系型数据库合并为一体,本文将其归类为前者)
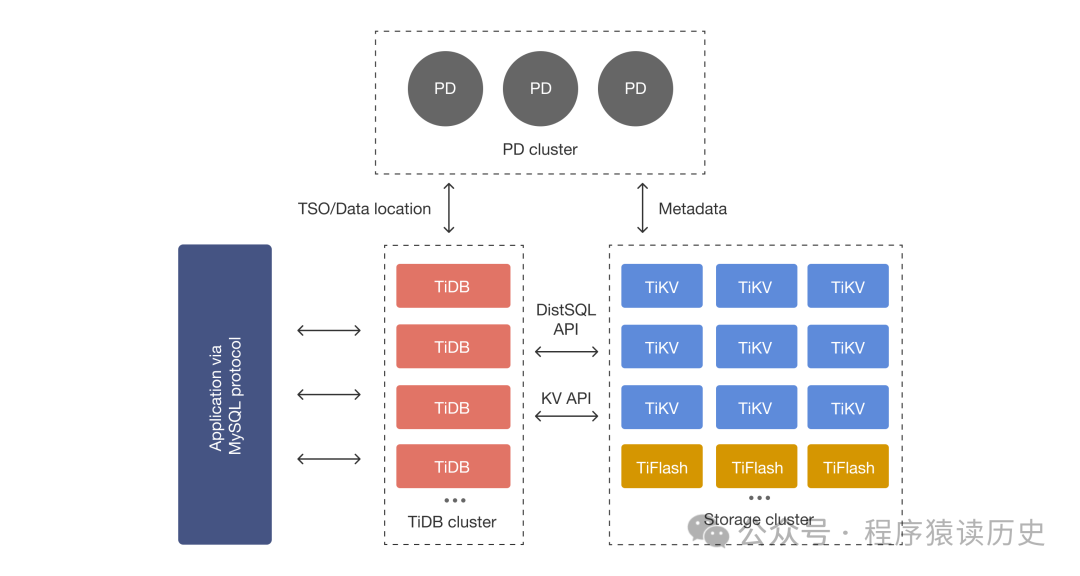
这两种架构有不少相同之处,比如都能进行横向扩展、都实现了分布式存储、都突破了单机性能瓶颈,有些同学误以为两者类似,实际上两者差距巨大。
中间件模式,传统数据库面向磁盘设计,基于内存的存储管理及并发控制,一般不如 NewSQL 高效。
中间件模式,中间件不具有底层数据的分布、统计信息,通常只负责SQL的解析、路由、重写,它的优化器效率并不高。另外,SQL 解析却在中间件与底层数据库重复工作,效率和性能相对较低。
NewSQL 数据库自动管理数据分片,数据的迁移、扩容都是自动化的,大大减轻了 DBA 的工作,同时对应用透明,无需在 SQL 指定分库分表键。
NewSQL 数据库存储基于分布式算法( Paxos或 Raft)多副本,相比于传统数据库主从模式(强/半同步转异步后也存在丢数问题),实现了真正的高可用(RTO<30s,RPO=0)。
NewSQL 数据库采用了更高效的算法和协议来降低分布式事务处理的性能损失,相比于传统数据库的 XA 分布式事务性能更高。
NewSQL 数据库存储引擎多采用 LSM,和 B+树相比,LSM 对磁盘的随机写变成顺序写,显著提高了数据库写入性能。
传统的中间件分库分表模式下,需要应用设计之初就要明确各表的拆分键、拆分方式、路由规则、拆分库表数量、扩容方式等,不仅给应用带来了很大侵入和复杂度,节点扩缩容也给DBA带来很大挑战。
NewSQL 数据库都是天生内置分片机制的,存储引擎根据每个分片的数据负载(磁盘使用率、写入速度等)自动识别热点,然后进行分片的分裂、迁移、合并,这些过程不仅应用无感知的,也省去了 DBA 的很多运维工作。
比如 Google Spanner 数据库是 split 为数据分散和复制的最小单元,当数据库检查到 split 频繁读写,负载过高,就会在不同节点间转移 split,以此平衡每个节点的负载,或者是将 split 再拆分为更小的 split ,从而实现平衡负载。国内 TiDB 数据库原来类似,它的数据分散和复制的最小单元是 Region,Region 到一定大小时,存储引擎会将 Region 自动进行迁移,以此解决数据库的负载均衡问题。
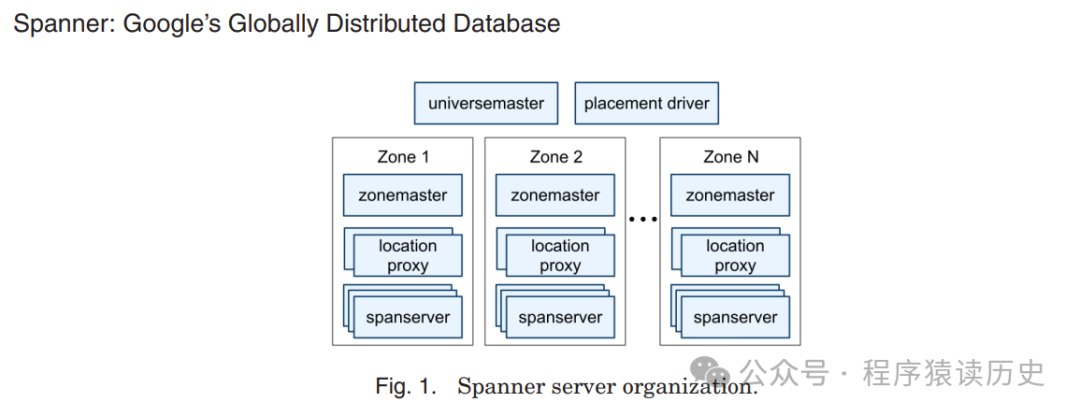
从系统可靠性、数据一致性看,主从模式并不是最优的方式,强同步、半同步复制在一些异常情况下通常会变为异步复制,比如网络异常、从节点离线等。如果不降为异步复制,应用必须等从节点确认接收到数据或者写入磁盘之后才算完成事务。而又因为相关故障,从节点已经无法正常运行,此时数据库将不会给应用反馈,那意味着系统不可用,显然这是不可接受的。而异步复制,意味着没有数据一致性可言。
对于数据一致性,业界公认更好的方案是基于 Paxos 分布式一致性协议或者其他类 Paxos, 如 Raft 方式。Spanner、YugabyteDB、CockRoachDB、TiDB、OceanBase等产品的分布式协议均是类 paxos 或者类 raft 协议。
Paxos算法的目标是在一个由多个节点组成的分布式系统中,就某个值达成一致性,基本思想是通过多个阶段的提议和接受来达成一致性。算法中的节点分为提议者(proposer)、接受者(acceptor)和学习者(learner)。提议者负责提出值的提案,接受者负责接受提案并投票,学习者负责学习已经达成一致的值。
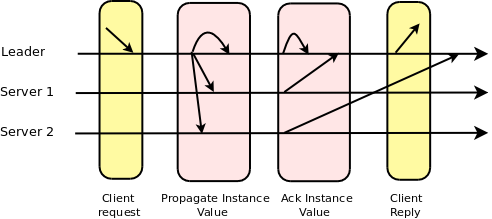
执行过程可以简要概括为以下几个步骤:
1. 提案阶段(Prepare):提议者向接受者发送准备请求,接受者根据请求的编号决定是否接受该提案。
2. 接受阶段(Accept):如果接受者接受了提案,它会向其他接受者发送接受请求,请求包含了接受的提案编号和值。
3. 学习阶段(Learn):一旦一个提案被足够多的接受者接受,学习者就可以学习到该提案的值。
从上可知对于一个多节点的分布式数据库,Paxos 虽然并不保证系统任何时刻处在一致的状态,但由于其达成共识至少需要超过一半的节点参与,因此整个系统最终会有一致性结果。另外,如果提案者在提案过程中出现故障,可以通过超时机制来处理。
NewSQL 厂商宣传基于 Paxos 或 Raft 协议可以实现异地多活,这需要异地之间网络延迟不能太高为前提。以金融、运营商等行业“两地三中心”为例,异地之间多相隔数千里,加上两地网络设备的跳转,网络延时达到数十毫秒。在这种情况下,要实现异地多活,就需异地副本节点也参与数据库日志过半确认,而这样高的延时几乎没有 高并发的 OLTP 系统可以接受。
数据库层面做异地多活是个美好的愿景,但物理空间距离导致的延时是无法忽视的因素。
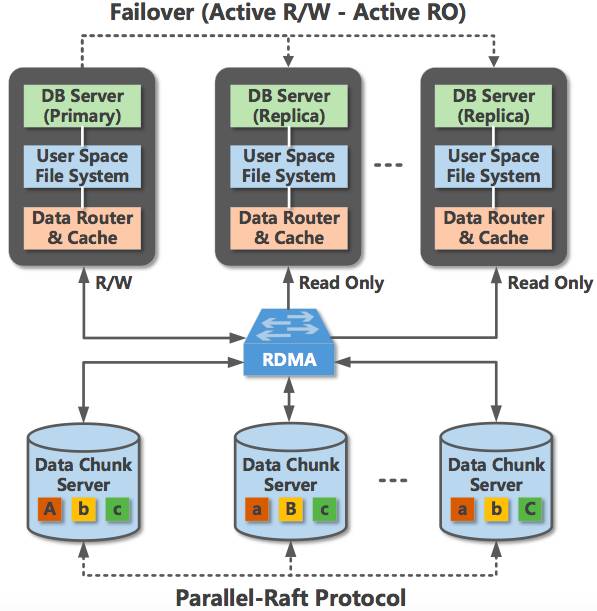
云原生数据库是由公有云厂商基于云计算能力推出新型数据库,它特点:首先是完全存储计算分离,存储使用跨多区、多AZ的共享存储;其次计算节点支持一写多读或者多写(前两者是不是很眼熟);第三充分利用云计算资源、能力,实现服务的极致弹性和扩展性。云原生数据库代表产品有亚马逊的 Aurora、阿里云的PolarDB。
云数据库的理念是,在云计算能力加持下,数据库的最大瓶颈不在是计算或者是存储资源,而是网络。Aurora 、PolarDB 就是基于存算分离、“日志即数据库”(The log is the database)的架构,两者都将日志处理下推到分布式存储层,从架构上解决网络瓶颈。
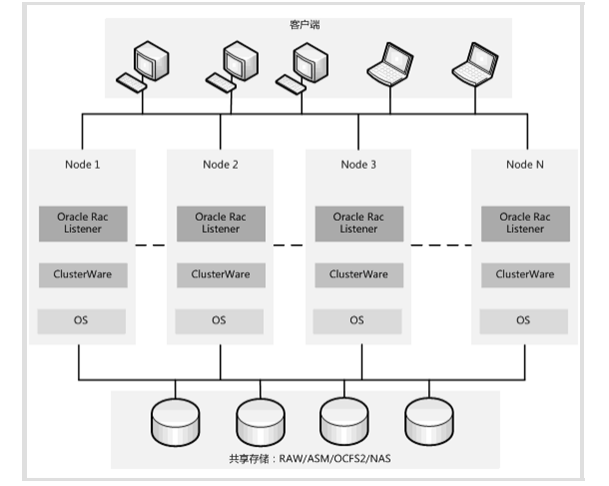
Oracle RAC 是典型的基于共享存储资源实现数据库高可用的架构,全称是 Oracle Real Application Cluster,是Oracle 公司提供的一个高可用架构。

作者介绍

01
02
03

END
