




作者 王康 https://catkang.github.io/2025/03/03/mysql-btree.html
InnoDB采用B+Tree来维护数据,处于非常核心的位置,可以说InnoDB中最重要的并发控制及故障恢复都是围绕着B+Tree来实现的。B+Tree本身是非常基础且成熟的数据结构,但在InnoDB这样一个成熟的工业产品里,面对的是复杂的用户场景,多样的需求,高性能高稳定的要求,以及长达几十年的代码积累,除此之外,InnoDB中的B+Tree在实现上并没有一个清晰的接口分层,这些都让这部分的代码显得复杂晦涩。本文希望从中剥茧抽丝,聚焦B+Tree本身的结构和访问来进行介绍,首先会简要介绍什么是B+Tree,之后介绍InnoDB中的B+Tree所处的位置和作用,然后介绍其数据组织方式,访问方式,以及并发控制。其余的,代码中交织在一起的诸如AHI (Adaptive Hash Index)、Change Buffer、RTree索引、Blob、代价估计等内容会先忽略掉。
B+Tree
对MySQL这种磁盘数据库来说,当要访问的数据不在内存中的时候,就需要从磁盘中进行加载。而内存和磁盘的访问速度是有几千甚至上万的差距的,那么作为磁盘数据库的索引,能不能有效的降低从磁盘中加载数据的次数就变得非常重要。1970年,Rudolf Bayer《Organization and Maintenance of Large Ordered Indices》一文中提出了BTree[1],之后在这个基础上演化出了B+Tree。B/B+Tree采用了多叉树的结构,显著的降低了数据的访问深度,尤其是B+Tree,通过限制所有的数据都只会存在于叶子节点,非叶子节点中只记录Key的信息,最大程度的压缩了索引的高度。这种索引结构的扁平化就意味着更少的磁盘访问,进而也意味这个更好得性能。因此,包括MySQL在内的大量主流的磁盘数据库都采用了B+Tree作为其索引的数据结构。如下图所示,是一个简单的B+Tree的示例:
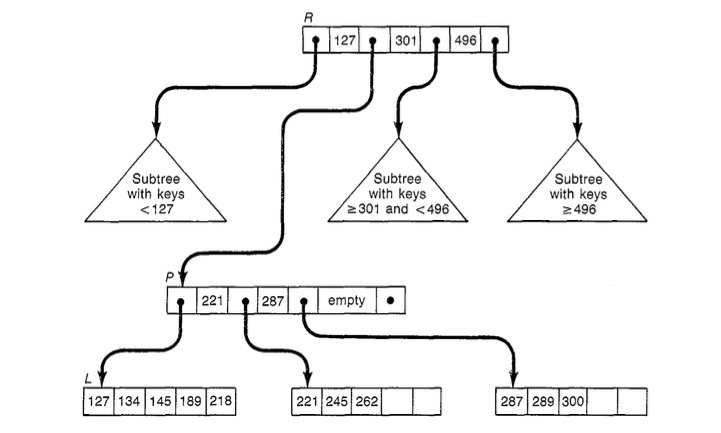
B+Tree这个多叉树中的每个节点中包含一组有序的key,介于两个连续的有序key,key+1中间的是指向一个子树的指针,而这个子树中包含了所有取值在[key, key+1)的记录。所有对B+Tree内容的填、删、改、查都需要先对操作的元素定位,这个定位过程需要从根节点出发,在每一层的节点中通过key的比较,找到需要的下一层节点,直到叶子节点。除此只外,为了方便遍历操作,叶子节点会通过右向指针串联在一起。
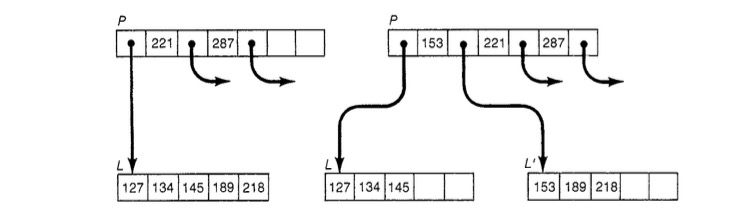
当叶子节点中的记录已经满的时候,新的插入会触发节点分裂,如上图所示,新的Key 153的插入导致原先已经满的节点L分裂成L和L’两个叶子节点。分裂会创建新的页面,将要分裂的页面的上部分数据迁移到这个新的节点上去,并将指向这个节点的指针及对应的边界key插入到父亲节点中去,同时,这次插入也有可能导致父节点的分裂,进而继续向上传导这个节点分裂动作。与之对应的是从B+Tree中删除数据后,叶子结点容量低于某个阈值(比如一半)时,会触发相邻节点的合并,同时需要从父节点中删除对应的Key及指针,因此合并操作也可能向更上层传导。所有的分裂和合并都是从叶子节点发起并向上传导的,只有根节点的分裂和合并会造成树高的变化。这也就保证了从Root到任意叶子的路径是相同的,从而保证了LogN的查找,插入以及删除复杂度。
InnoDB中的B+Tree
基于B+Tree的数据维护与访问
InnoDB中的每张表的都会维护一个包含所有数据的B+Tree,称为聚簇索引(Clustered Index)。通常聚簇索引这个B+Tree中的Key就是这张表的主键字段,需要保证唯一和非空,而Value就是完整的行数据。也就是说,表中所有完整的行数据是按照这个主键Key有序维护在这个聚簇索引这个B+Tree中的,因此指定一个有意义的不会频繁更新的主键字段是有好处的。除此之外,为了加速访问,通常会在表上创建一个或多个二级索引,每个二级索引也会对应维护成一个B+Tree,二级索引的B+Tree中的Key是这个索引字段,而Value是对应的聚簇索引上的Key。通过二级索引查找后,如果需要更多信息就需要用这个获取到的聚簇索引Key,再回到聚簇索引的B+Tree上做查找,这个就是我们常说的回表过程。如下图所示是一张MySQL表对应的数据结构,包含一个聚簇索引B+Tree,和多个二级索引B+Tree。
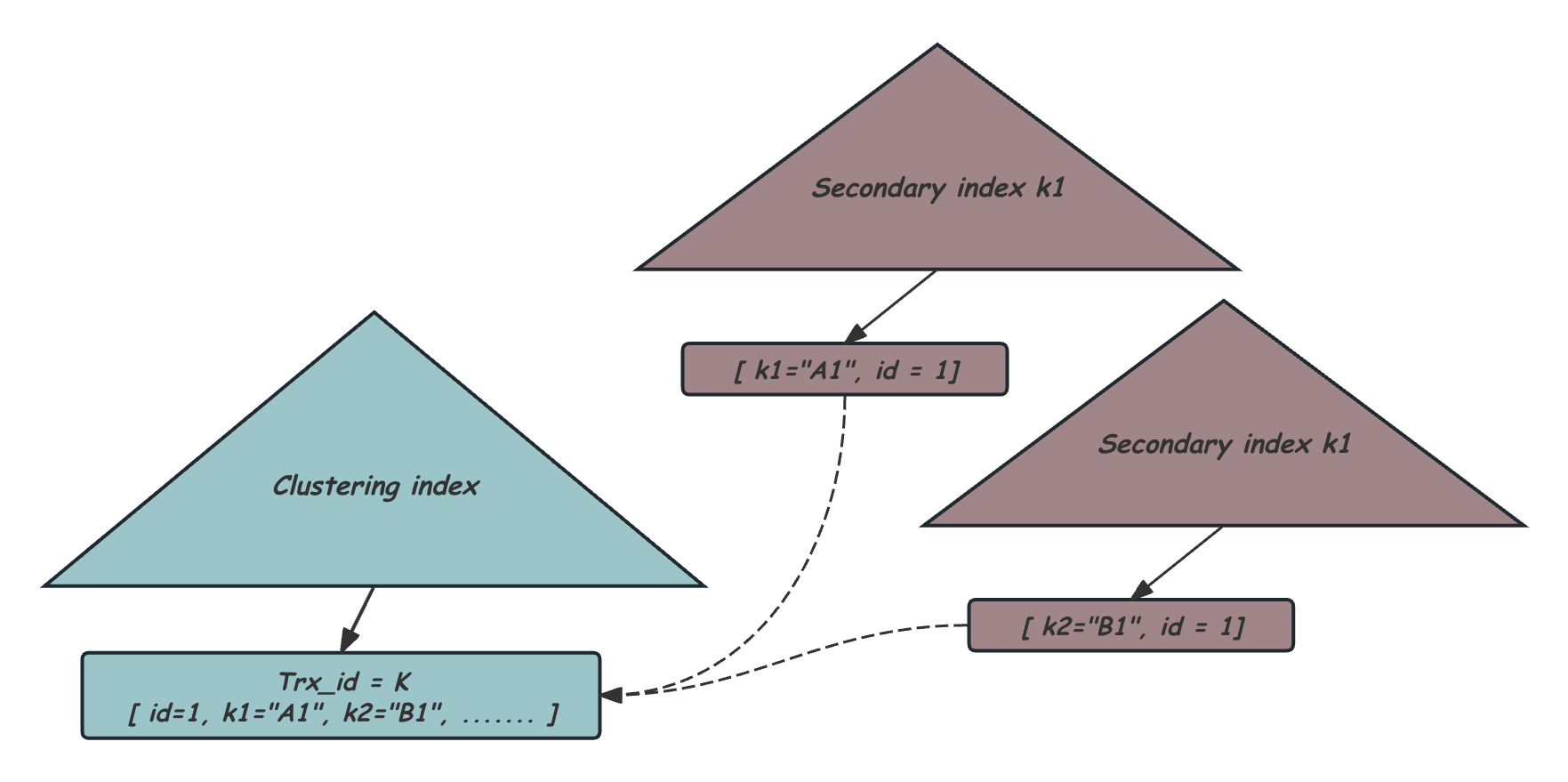
对MySQL数据库的增删改查请求,会在Server层通过优化器的代价估算,选择看起来最优的索引生成执行计划,最终转化为对对应的B+Tree的访问,从Root节点一路沿着B+Tree下降,这个过程中访问的Page如果不在Buffer Pool都需要先从磁盘中加载到Buffer Pool中,直到找到需要访问的Record所在的Page,并对其操作。
基于B+Tree的并发控制
数据库的并发控制是为了保证事务之间隔离性而设置的访问机制,《浅析数据库并发控制机制》[2]一文中曾经对常见的并发控制机制做过简单的介绍和分类。InnoDB中的并发控制采用的的Lock + MVCC的方式,也就是采用MVCC来避免读写之间的冲突,但在写写之间采用了悲观的Lock的并发控制方式。
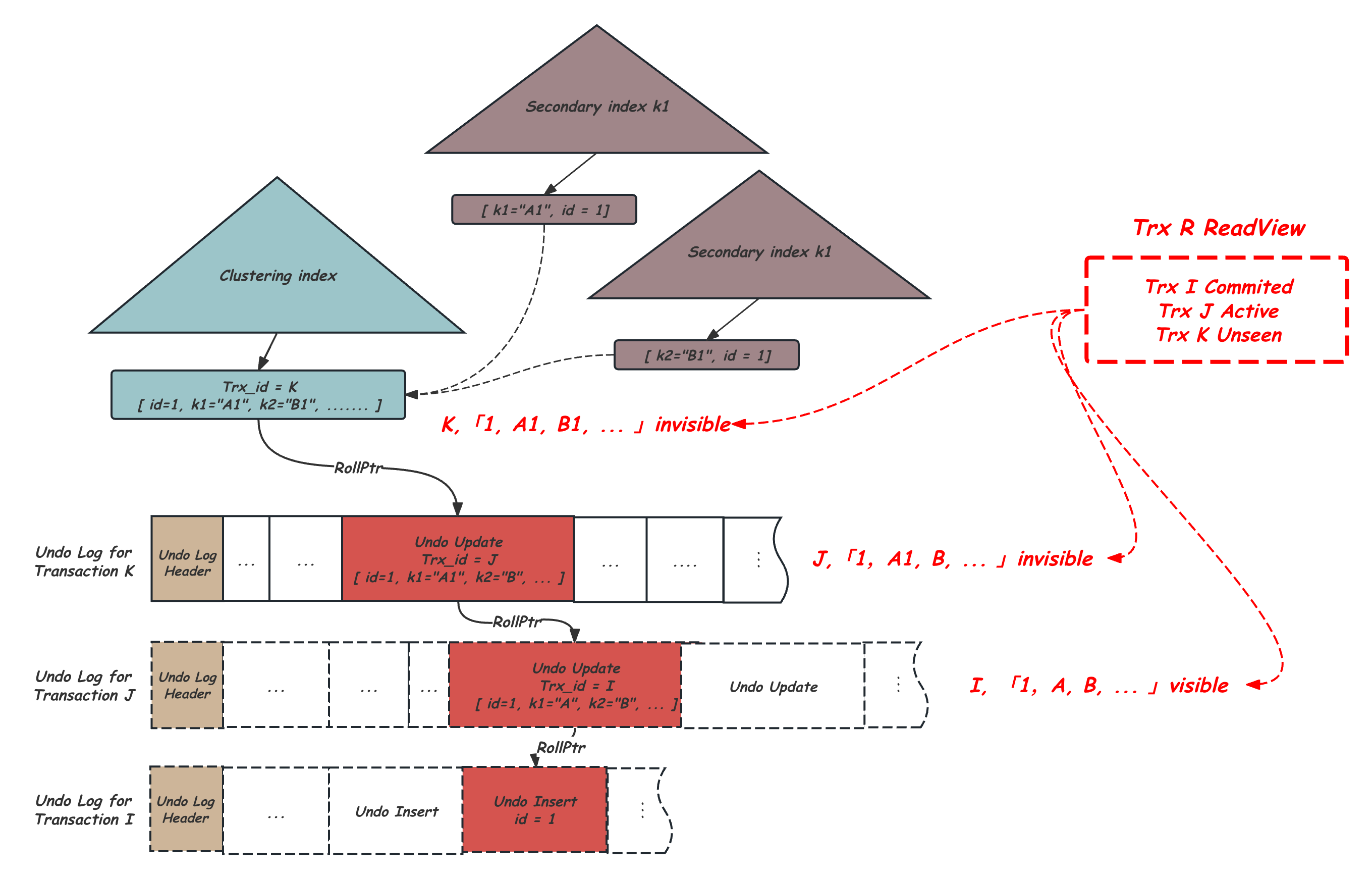
InnoDB的MVCC的实现是以来Undo Log来做的[3],在聚簇索引上除了用户数据外,还会记录一些隐藏字段,包括最近修改的事务ID,以及指向历史版本的Roll Ptr指针,指向Undo日志中该行的历史版本,快照读会根据配置的隔离级别持有ReadView,ReadView中记录获取ReadView时的活跃事务状态,通过对比聚簇索引上或UNDO Log上的事务ID和所持有ReadView中记录的活跃事务状态,就可以判断当前的版本是不是可见的,如果不可见就沿着Roll Ptr寻找正确的可见的版本。如下图所示,需要注意的是在InnoDB的实现中,只有聚簇索引B+Tree的记录中包含事务ID,这也导致二级索引上的可见性判断需求都必须回表到聚簇索引来满足,这也导致比如通过二级索引的查询、二级索引上的隐式锁判断、二级索引的Purge等场景的一些性能问题。
而对于Lock的实现,在《B+树数据库加锁历史》[4]一文中曾经介绍过,基于B+Tree的并发控制发展一直遵循着降低锁粒度的方向,直到ARIES/KVL将逻辑内容和物理内容分离,由Lock和Latch分别保护,并提供了一套相对完善的对Record Lock的实现算法,基本形成了现代B+Tree数据库的通用解法,InnoDB就是其中之一。InnoDB中维护了专门的Lock Manager模块来处理事务之间的加锁、阻塞、死锁检测等,这部分内容会在后续文章中做详细介绍。这里主要关注的是其跟B+Tree的关系,Lock Manager中的加锁对象可以简单的理解为聚簇索引或二级索引B+Tree叶子结点上的某个Key的物理位置。因此,在完成加锁之前,需要先在对应的B+Tree上定位需要的的记录。另外值得一提的是,InnoDB采用了文中提到的Ghost Record实现,也就是所有的删除操作,只会对记录设置Delete Mark标记,而将真正的删除操作推迟到后台Undo Purge中进行。从而将Delete操作转换为记录的原地Update操作,减少对区间Lock的需要。
另外,依照ARIES/KVL[5]的设计,InnoDB中采用Latch来保护B+Tree本身物理结构在多线程访问下的正确,比如正在修改的Page不应该被其他线程看到,又比如一个分裂操作中的中间状态不应该被其他线程看到。在本文后面的并发控制章节会对这个部分详细讨论。
基于B+Tree的故障恢复
类似于并发控制,在故障恢复上InnoDB也区分了逻辑和物理两层[6],简单的说,逻辑层的故障恢复需要保证的是在发生故障重启后,已经提交的事务依然存在,未提交的事务的任何修改都不存在,也就是我们常说的ACID中的Failure Atomic及Durability,在InnoDB中,这一点是靠Redo和Undo Log来实现的。本文这里主要关注的是跟B+Tree更相关的物理层的故障恢复,也就是如何保证在数据库重启后,B+Tree可以恢复到正确的位置,而不是一个树结构变更的中间状态。InnoDB中有一个很关键的数据结构:Min-transaction(Mtr),也就是《B+树数据库故障恢复概述》[6]中提到的System Transaction的实现。
InnoDB中针对B+Tree结构变更的操作,例如节点的分裂或者合并,会涉及到多个兄弟节点以及其祖先节点的修改,Mtr中会持有需要的节点及索引锁,并且将这些修改产生的Redo Record记录到私有的Redo Buffer中,只有当所有这些修改都完成后,收集到所有Redo Record的Mtr才会进入Commit阶段,这时会在这组Redo的末尾添加MLOG_MULTI_REC_END的特殊类型的日志,等待这些Redo Records从私有的Redo Buffer中连续拷贝到全局Redo Buffer并写入磁盘。在这之后该Mtr才能完成Commit,对应的脏页才能落盘。如下图所示,Page S分裂成S和S’的过程同时造成了父节点P,兄弟节点N的修改,这个过程对应操作被记录在连续的Redo日志中:
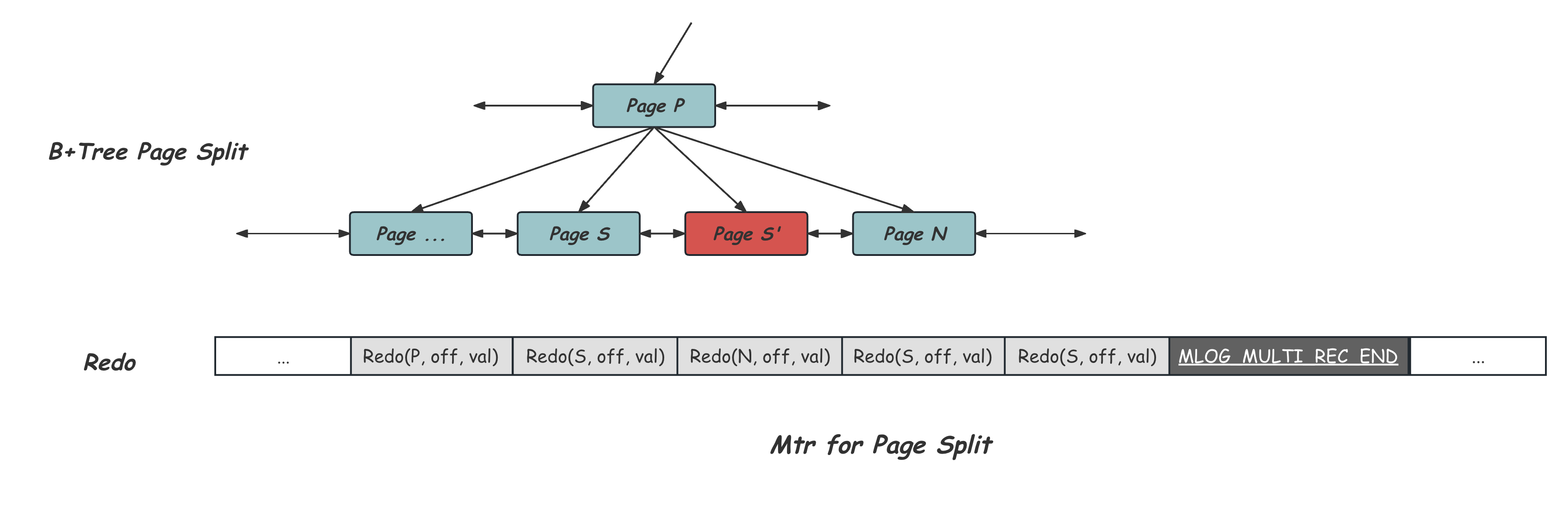
当发生故障重启的时候,在真正做Redo重放之前,Redo Parse过程会先尝试去找MLOG_MULTI_REC_END日志,如果看到这个标记,那么这段连续的Redo才能被重放,否则这个Mtr中的所有redo都不能重放。从而保证在重启后,这个B+Tree结构变更导致的多节点的修改,要不都存在,要不都不存在,以此来保证B+Tree本身结构的正确。
