




Kafka是一个开源的分布式流处理平台,最初由LinkedIn开发,后来成为了Apache软件基金会的顶级项目。Kafka主要用于构建实时数据管道和流应用,它在大规模数据处理和实时分析领域有着广泛的应用。
基础架构
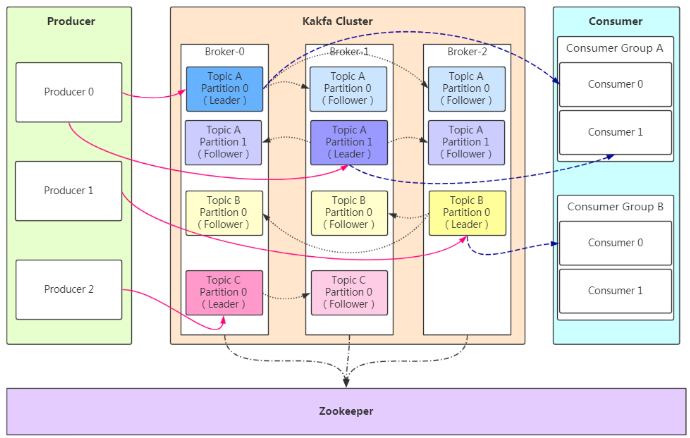
特点
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
集群部署
| 服务器IP地址 | 节点名称 |
|---|---|
| 192.168.124.171 | kafka1 |
| 192.168.124.172 | kafka2 |
| 192.168.124.173 | kafka3 |
在3.5版本发布后,Zookeeper已被标记为弃用并推荐使用KRaft模式部署kakfa集群,但是官方手册也提到了KRaft中仍有一小部分功能有待实现,所以个人还是推荐在生产环境中使用zookeeper模式部署kafka集群。
With the release of Apache Kafka 3.5, Zookeeper is now marked deprecated. Removal of ZooKeeper is planned in the next major release of Apache Kafka (version 4.0), which is scheduled to happen no sooner than April 2024. During the deprecation phase, ZooKeeper is still supported for metadata management of Kafka clusters, but it is not recommended for new deployments. There is a small subset of features that remain to be implemented in KRaft see current missing features for more information.
Zookeeper安装
JDK安装
# 解压
tar -zxvf jdk-8u341-linux-x64.tar.gz
# 移动目录
mv jdk1.8.0_341 /usr/local/java
# 配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 生效环境变量
source /etc/profile
下载并安装zk
官方地址:https://zookeeper.apache.org/releases.html。生产环境建议选择stable release版本
cd /soft wget https://archive.apache.org/dist/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz tar -zxvf apache-zookeeper-3.8.8-bin.tar.gz mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper
设置环境变量
vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
# 生效环境变量
source /etc/profile
修改zoo.cfg文件
# cd /usr/local/zookeeper/config
# cp zoo_sample.cfg zoo.cfg
# vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
clientPort=2181
dataLogDir=/data/zookeeper/log
server.1=192.168.124.171:2888:3888 #添加集群节点
server.2=192.168.124.172:2888:3888
server.3=192.168.124.173:2888:3888
创建目录和myid
根据zoo.cfg中的server.N配置项,各节点创建各自myid文件
# mkdir -p /data/zookeeper/{data,log}
# cd /data/zookeeper/data
# echo 1 > myid #这里是server.1的配置
创建zookeeper服务
# vim /usr/lib/systemd/system/zookeeper.service
[Unit]
Description=zookeeper.service
After=network.target
[Service]
Type=forking
WorkingDirectory=/usr/local/zookeeper #zookeeper路径
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start #zookeeper执行文件
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
User=root
Group=root
Restart=always
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload
# systemctl enable zookeeper.service
# systemctl start zookeeper.service
查看状态
# zkServer.sh status

Kafka安装
下载并安装kafka
官方地址:https://kafka.apache.org/downloads.html
# cd /soft
# wget https://archive.apache.org/dist/kafka/3.8.1/kafka_2.13-3.8.1.tgz
# tar zxvf kafka_2.13-3.8.1.tgz
# mv kafka_2.13-3.8.1 /usr/local/kafka
设置环境变量
# vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
# source /etc/profile
修改配置文件
# cd /usr/local/kafka/config/
# cp server.properties{,.bak}
# vim server.properties
broker.id=2 # 每个节点的id必须唯一
listeners=PLAINTEXT://192.168.124.172:9092 #监听的ip地址
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/logs #日志保存路径
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
og.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.124.171:2181,192.168.124.172:2181,192.168.124.173:2181 # zookeeper集群连接地址
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
创建目录
mkdir -p /data/kafka/logs
创建kafka服务
# vim /usr/lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka Server
After=network.target remote-fs.target kafka-zookeeper.service
[Service]
Type=forking
User=root
Group=root
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload
# systemctl start kafka.service
# systemctl enable kafka.service
测试
创建topic(分区为3,副本为3)
# kafka-topics.sh --bootstrap-server 192.168.124.171:9092,192.168.124.172:9092,192.168.124.173:9092 --create --topic zntest --partitions 3 --replication-factor 3
查看topic
# kafka-topics.sh --describe --bootstrap-server 192.168.124.171:9092 --topic zntest

