




TcaplusDB数据迁移方式分为有损搬迁和无损搬迁,有损是指数据迁移过程中对外服务有损。
1 应用场景
• 存储层扩容
• 存储层缩容
• 设备搬迁
• shard搬迁
2 TcaplusDB架构
2.1 数据分片模型
TcaplusDB会把每张表分成N个shard, shard分布在1个或多个tcapsvr节点上。
根据key计算hash得到对应的shardID。
计算方式:
hash_code = hash(keys) % 10000
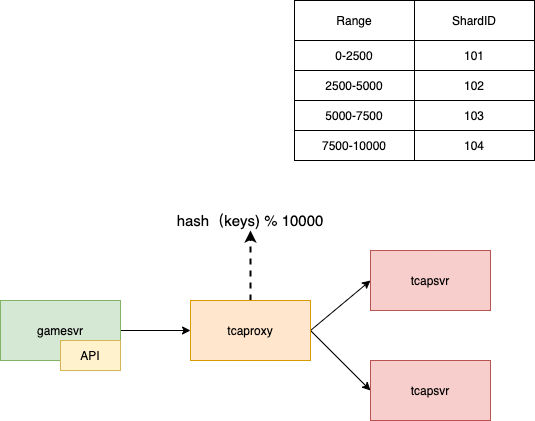
Range | ShardID |
0-2000 | 101 |
2001-4000 | 102 |
4001-6000 | 103 |
6001-8000 | 104 |
8001-10000 | 105 |
一个表通过hash分表,按照路由数组长度(默认为10000)进行取模运算分片(Mod Sharding),所以每张表最多可以分成10000个分片(Shard)。以下图为例,1个TcaplusDB表被分为5个shard文件分布到不同存储节点,每个节点分布有1个或多个分片的数据。
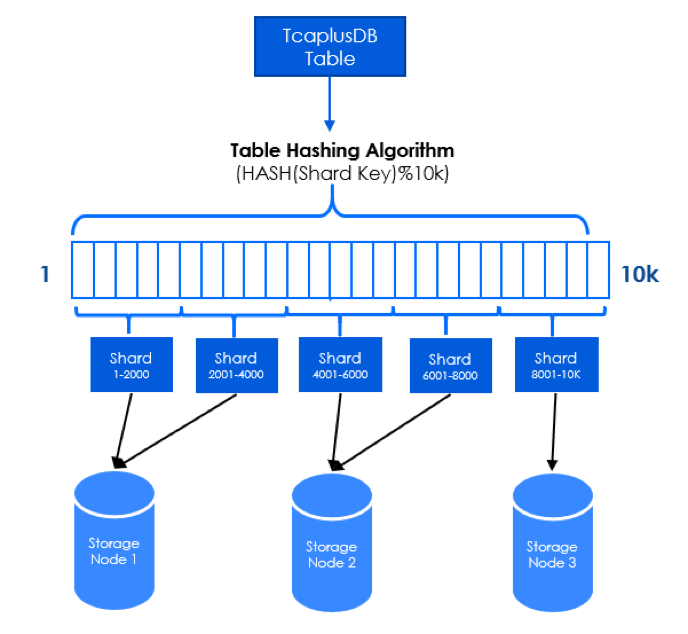
2.2 数据访问流程
GameSvr通过API访问tcaproxy,在tcaproxy中根据key计算出对应的hash值获取路由信息,把请求转发到对应的tcapsvr上。
3 搬迁方案
在业界中,主要有两种数据搬迁方案。
1、先搬迁数据,再切换路由信息。
2、先切换路由信息,再搬迁数据。
方式 | 优势 | 不足 | 难点 |
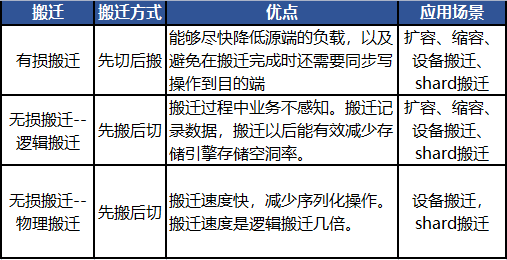
先搬后切 | 容错性强,状态一致,搬迁过程可随时回退,天然支持所有操作。 | 搬迁过程中不能很快降低源端的负载 | 搬迁过程中的写操作如何同步到目的端 |
先切后搬 | 快速分流,可以很快降低源端的负载。 | 容错性差,搬迁过程中不能回退 | 如何在搬迁过程中支持各种请求 |
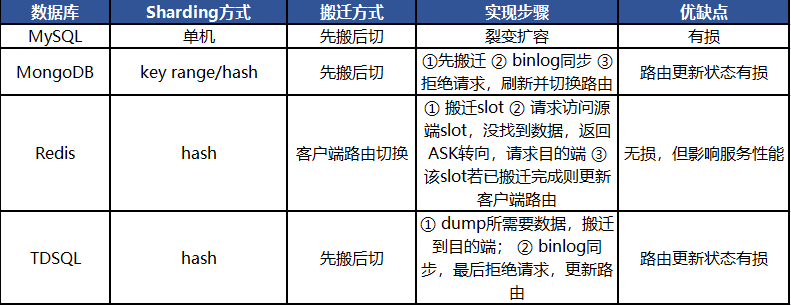
3.1 业界数据搬迁方式
3.2 TcaplusDB搬迁方式
4 有损搬迁
TcaplusDB的有损搬迁为了能够尽快降低源端的负载,以及避免在搬迁完成时还需要同步写操作到目的端,采用了先搬后切的方式。
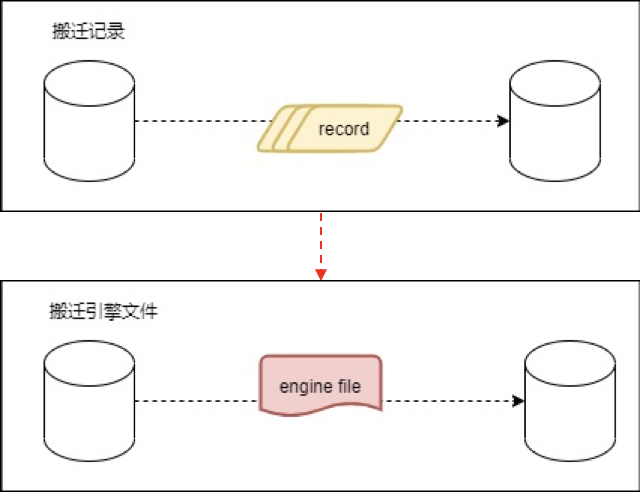
路由状态的转换由tcapcenter控制,并通知到tcaproxy,路由状态转换为:
normal--> wait --> reject --> sync --> normal
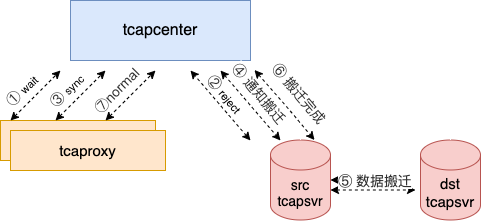
4.1 搬迁过程的路由状态
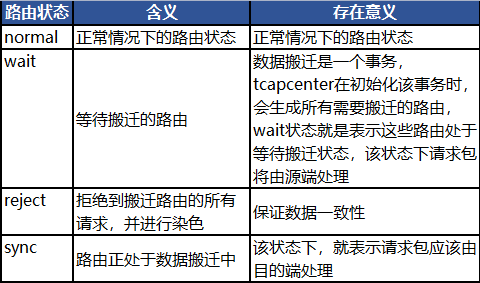
4.2 为什么需要Reject状态
假设由wait状态直接转变为sync状态,tcaproxy到源端svr的通道中仍然存在写请求未被处理:
1、源端svr将key对应的记录搬迁到目的端svr;
2、源端svr处理通道中的记录更新请求;
3、由于是sync状态,tcaproxy会到目的端svr获取;
按照该流程,如果没有reject状态的话,proxy会读取记录的旧数据。
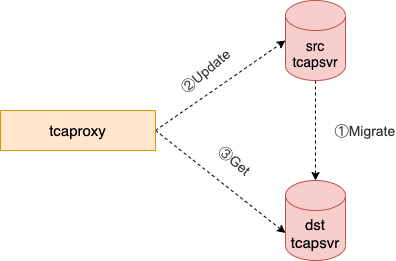
4.3搬迁过程的请求处理
1、tcaproxy收到请求包之后,检测所请求的记录是否在目的端tcapsvr,
若存在目的端tcapsvr,转 步骤4。
若不存在目的端tcapsvr, 转 步骤2。
2、tcaproxy向源端tcapsvr拉取所请求的记录。
3、tcaproxy将拉取回来的记录写入到目的端。
4、tcaproxy将gamesvr的请求发送给目的端tcapsvr进行处理。
4.4 搬迁速度控制
搬迁过程中使用滑动窗口的方式控制搬迁速度:
• pending buffer默认长度为1000,实际表征了并发量;
• 指定时间内无ack则重传;
• 目的端返回busy,则按照重试策略重试;

4.5 时间分段
宏观时间
• 23:00 - 07:00, 业务低峰期,搬迁速度可以提高
• 07:00 - 23:00, 业务主要服务时间,搬迁速度可以降低。
微观时间
• 以10ms作为粒度,将每秒速度平均分配到100个10ms,从而使搬迁速度更加平滑。
5 无损搬迁
有损搬迁搬迁过程中会导致部分key读写不可用,并且只能在业务低峰期进行搬迁(搬迁过程服务有损)。因此需要无损搬迁作为补充。
无损搬迁采用先搬后切的路由方式,搬迁过程中业务不感知。
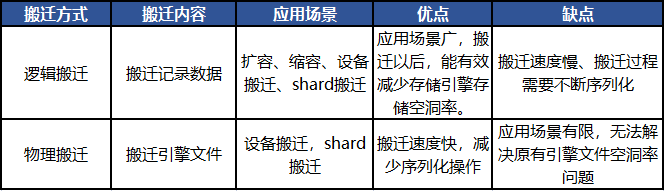
无损搬迁分为逻辑搬迁和物理搬迁,逻辑搬迁--搬迁记录数据,物理搬迁--搬迁引擎文件。
5.1 搬迁方式差异
无损搬迁的路由状态:
normal-->wait-->move-->cache-->normal
5.2 逻辑搬迁
5.2.1 数据搬迁-move状态
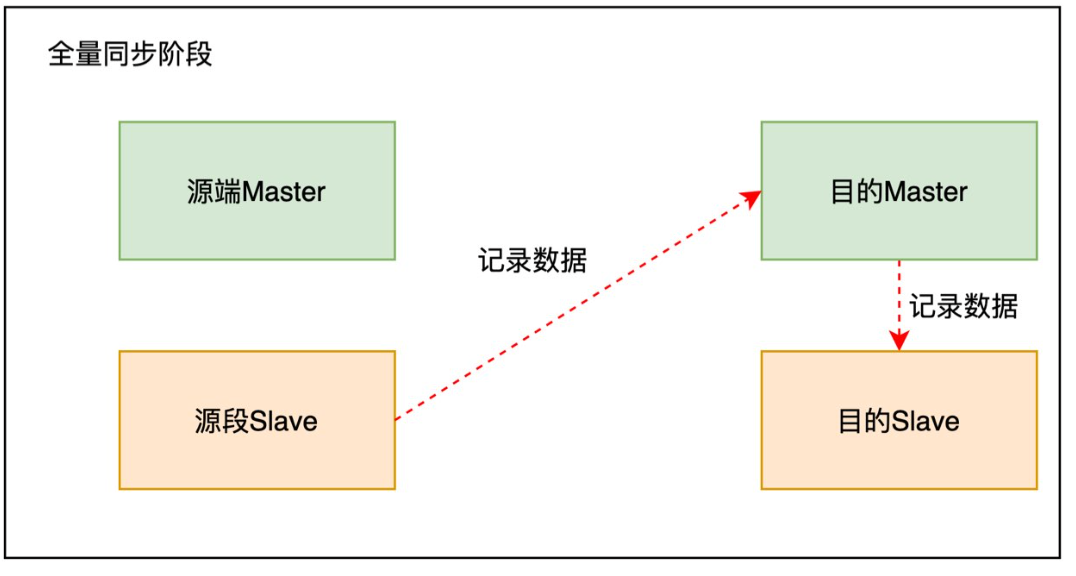
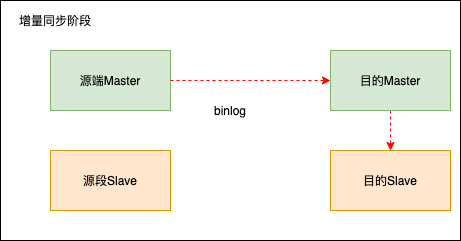
数据搬迁过程分为全量同步阶段和增量同步阶段。全量同步主要同步某一时刻的全量数据,增量同步主要同步搬迁过程中产生的新数据,使源端和目的端的数据一致。
全量同步由源端slave发起,将记录数据从源端slave同步到目的端master。目的端master写入数据以后,会通过binlog的方式同步到目的端slave。
增量同步由源端master发起,将新增的记录数据从源端master同步到目的端slave。目的端master写入数据以后,会通过binlog的方式同步到目的端slave。
5.2.2 请求缓存-cache状态
为了能够实现无损切换,proxy需要增加如下机制:
• 需要增加缓存机制,用于缓存请求;
• 需要增加染色机制,确保数据的一致性;
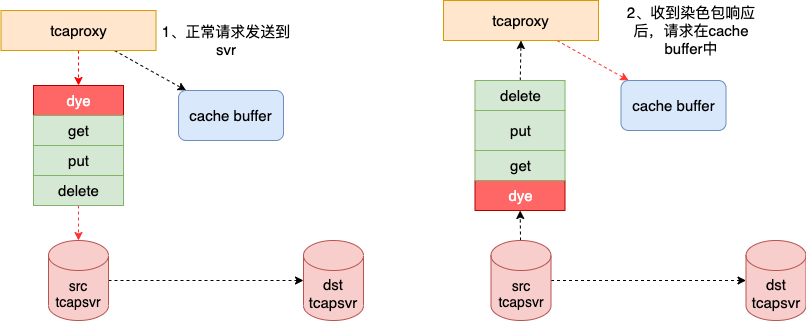
当路由状态变成request_cache状态之后,跟路由相关的所有请求就被缓存起来了,因此,从发送染色包之后,就不会再有路由相关的请求被发到源端tcapsvr了。
染色操作之所以可以避免出现数据不一致,主要是为了防止tbus通道里,还存在相关路由的写操作,如果没有染色操作这个步骤,那么当路由状态从request_cache变成normal之后,所有的访问都将在目的端tcapsvr进行,这时,如果源端tcapsvr再处理tbus通道里的写操作,就会出现数据不一致性了,因为有一部分写操作是在源端完成的,而这些写操作是不会再同步给目的端tcapsvr。
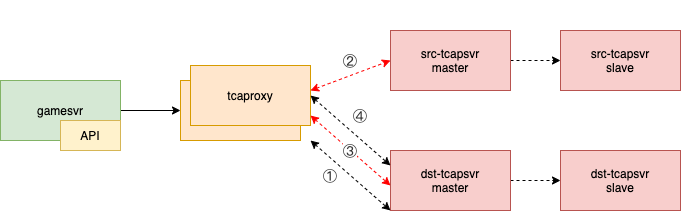
5.2.3 路由切换
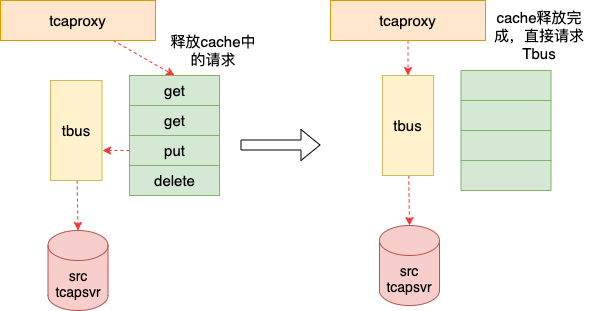
当所有请求都被proxy缓存的时候,可以进行路由切换,将对应的shard号段指向新的tcapsvr。在路由切换的过程中,还需要将proxy缓存的请求释放。当请求缓存为空时,tcaproxy直接通过通信组件tbus进行通信,路由切换完成。
5.2.4 数据一致性保证
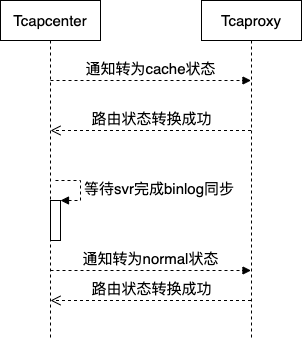
• 染色包机制确保请求cache后无pending的请求。
• 请求proxy切换路由到cache状态,如果部分失败需及时回滚到move状态。
• proxy切换路由到cache状态后,如果binlog同步失败需及时回滚到move状态。
• 一旦发起proxy切换normal动作后,即使部分失败也不能再回滚路由。
5.3 物理搬迁
物理搬迁和逻辑搬迁最大的差异就是在全量同步阶段,物理搬迁传输的是引擎文件。
• 采取物理的方式进行shard搬迁,所谓物理方式指的是,数据迁移时不再按照记录进行搬迁,而是按照文件进行迁移,即按照字节流方式进行迁移。
• 直接搬迁引擎数据文件,减少序列化和反序列化的开销。
全量同步阶段物理搬迁从源端slave中传输引擎文件块到目的端master和目的端slave。
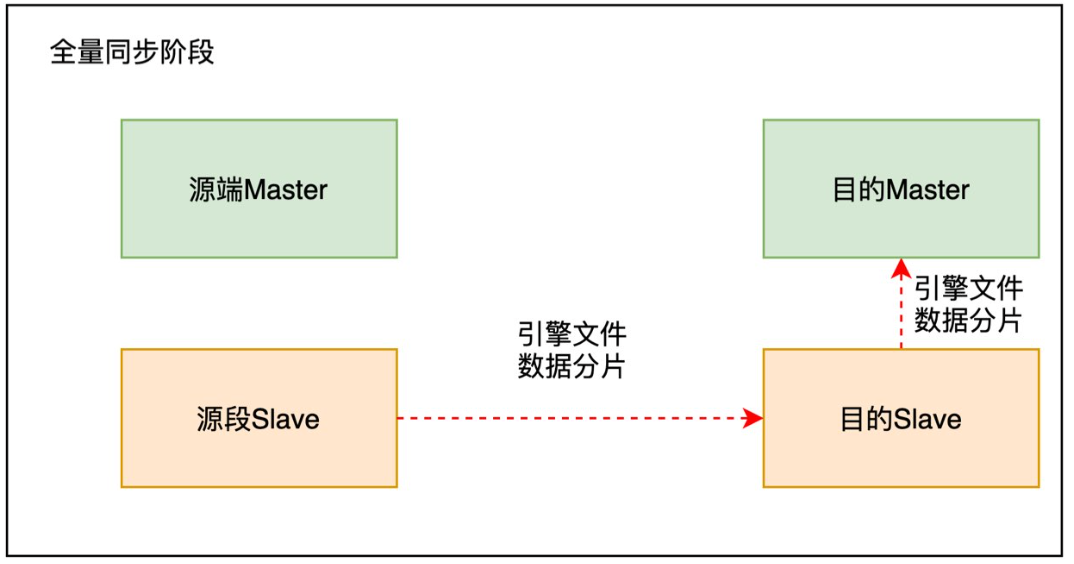
5.3.1 物理搬迁的优化
针对机器间时延大,调整tcp发送和接收窗口,提高网络吞吐量。
使用tcp多连接和异步发送的方式发送数据分片,提高文件发送效率。
使用aio避免同步等待读完成,释放cpu资源用于处理网络收发包和CRC计算。使用aio发送速度相对稳定。使用系统同步读接口如果发生系统缺页的话,需要读取磁盘。引擎文件数据分片可能在系统缓存或者磁盘,导致发送速度不稳定。
使用流水线的方式发送数据分片。数据分片从源端slave发送到目的slave,目的端slave再发送到目的端master。
5.3.2 搬迁过程对外服务可用
物理搬迁需要的是某一时刻的存储引擎文件,但是搬迁需要一定的时间并且需要对外提供服务。在存储层主要采用两个存储引擎作为切换。物理搬迁前,提前创建一个临时的存储引擎文件,将搬迁过程中产生的写数据都存储在临时的存储引擎中,并且原来的存储引擎文件对外提供读服务。
物理搬迁完成后,需要将搬迁过程中写入临时存储引擎文件的数据进行数据合并。在此过程中,临时存储引擎对外提供读服务。

扫码关注获取更多资讯!
