




点击上方 蓝字 关注一臻数据👆
免费领取 DeepSeek➕数据AI知识库 🔗 一起共建共进
❝夜深人静,结束了一天的忙碌,打开电脑,浏览了下上周发布的
3分钟!教会你用Doris+DeepSeek搭建RAG知识库(喂饭级教程)
,收到了很多正反馈。虽然大多小伙伴都基于
喂饭级教程
快速地运行起来了,但也遗留了诸多后续,例如:"怎么进一步实现ChatBI?"
"好滴,安排!"
正巧,老崔最近也在整Doris+AI的项目。
于是,一起整了个Doris+DeepSeek实现ChatBI的快速体验版(
Hello Doris ChatBI
)。
前言
小华是市场部的业务员,对SQL一窍不通。以前要分析数据,他只能提需求给数据团队,然后苦等几天。
现在,他只需对着ChatBI说:"帮我看看上个月各渠道获客成本与转化率的关系
"。
于是,ChatBI
系统立刻启动了四大引擎
:
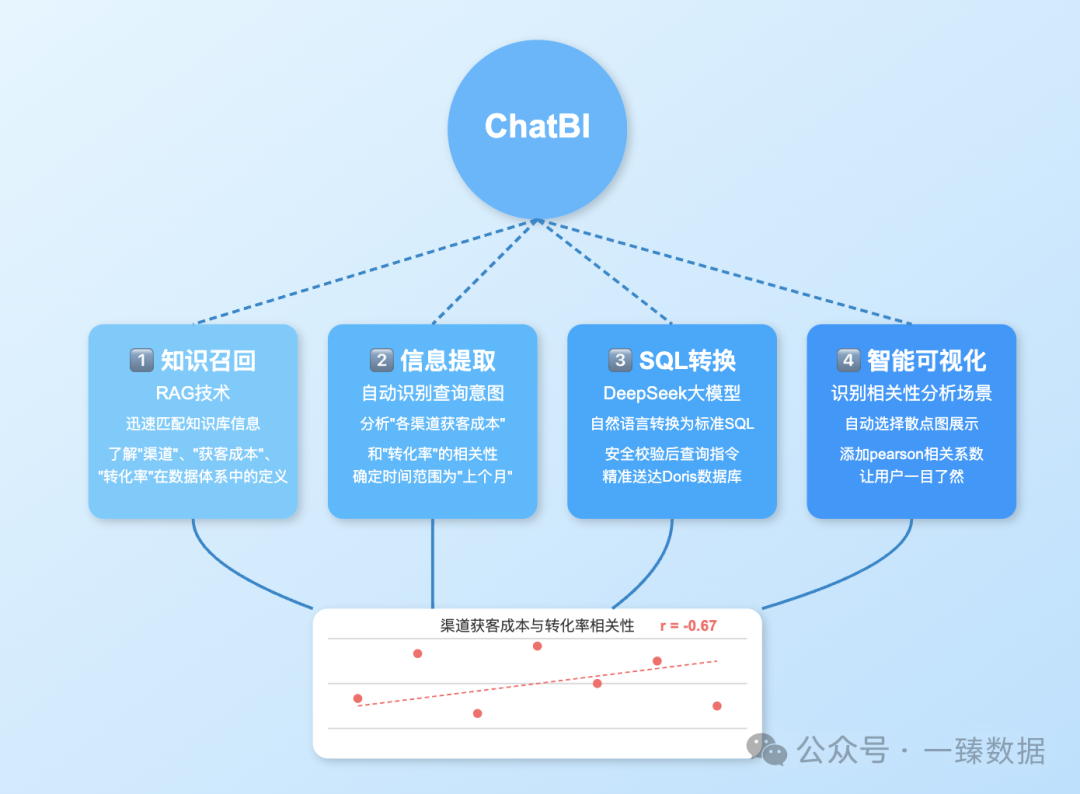
1️⃣ 知识召回:RAG(检索增强⽣成)技术迅速从知识库中匹配相关信息,了解"渠道"、"获客成本"、"转化率"在公司数据体系中的定义和存储位置。
2️⃣ 信息提取:系统自动识别出查询意图是要分析"各渠道获客成本"和"转化率"的相关性,并确定时间范围为"上个月"。
3️⃣ SQL转换:DeepSeek大模型将自然语言转换为标准SQL,安全校验后,查询指令精准送达Doris数据库。
4️⃣ 智能可视化:系统判断这是典型的相关性分析场景,自动选择散点图展示,并在右侧添加了pearson相关系数,让小张一目了然。
整个过程不到一分钟,小张惊讶地看着面前生成的数据图表,不禁感叹:"这简直是数据世界的翻译官
啊!"
今天,我们就一起来实现一个简易版的ChatBI四大引擎
,快速体验其中的纷纷扰扰 ⬇️
第一步|定方案
传统数据分析的三座大
困扰着无数企业:技术门槛高、分析效率低、洞察转化难
。数据仓库建好了,业务人员却不会用;报表做出来了,洞察难以直观表达;分析结果有了,决策者还要等半天!
Doris+DeepSeek V3组合拳的出现,正如一把利剑,直指这些痛点。
你还记得那些等待Hive查询结果喝完一整杯咖啡的日子?而Doris让数据查询速度提升了10倍以上,同时保持了优秀的扩展性,支持PB级数据分析
。其独特的向量化执行引擎和智能索引技术
,让复杂查询也能在亚秒级完成,这正是ChatBI对话式体验的基础保障
。即使面对千亿级数据,分析依然如丝般顺滑。
那么,这会就会有小伙伴提出疑问,为啥不选用DeepSeek R1?因为:

这套组合不仅技术先进,更是极致性价比的体现,并且都以开源著称:
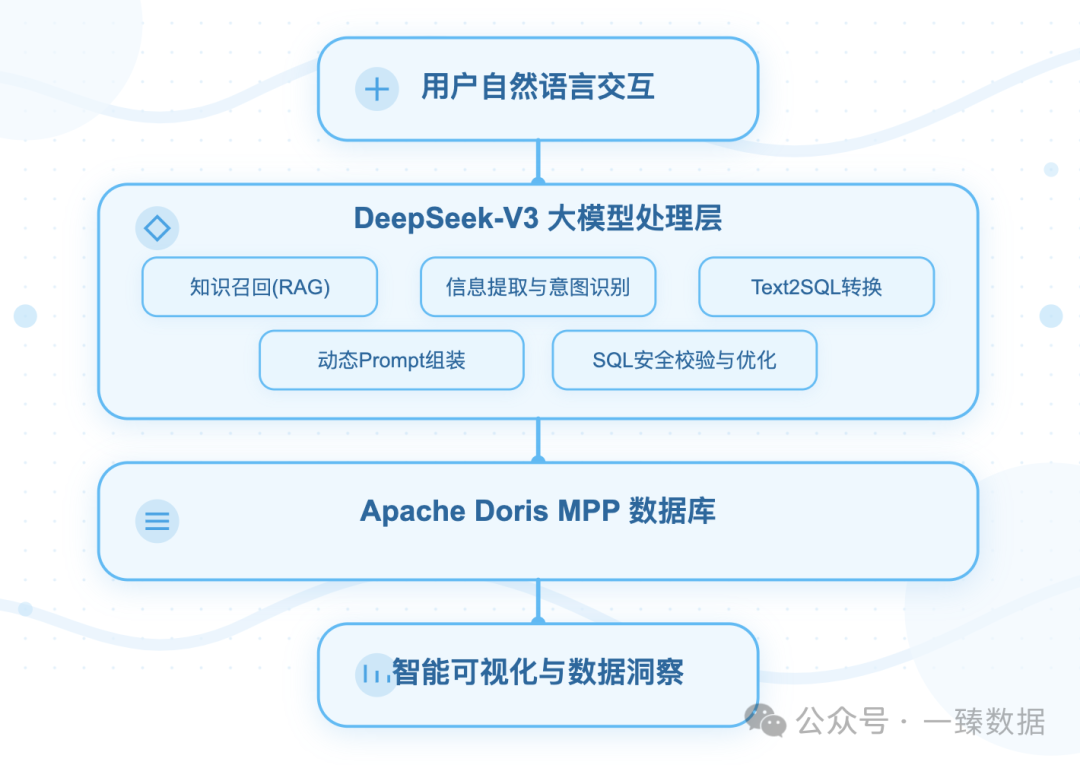
方案主要分为4个模块:
1. 用户自然语言交互层
你说人话,系统能听懂。
就好比和真人聊天一样,可以直接用大白话提问。比如:“XXX这个库有多少张表
”,系统不需要你写代码或记指令,你说人话它就能接住。
2. DeepSeek V3 模型处理层
系统的翻译官+安全员
。这个大脑主要干5件事:
1️⃣ 知识召回:先翻自己的知识库,比如“销售额”对应数据库里的哪个字段
2️⃣ 理解意图:拆解你的问题,知道你想查“最高”而不是“平均”
3️⃣ Text2SQL:把问题翻译成数据库能懂的查询语句(比如生成 SELECT MAX(sales) FROM table
)
4️⃣ 动态Prompt组装:灵活调整问题的提问模板
,好比智能秘书
,把零散的信息(用户话术+数据库知识
)打包成清晰的指令,让大模型干活不懵圈
5️⃣ 安全把关:检查生成的SQL会不会拖垮数据库,或者有没有危险操作,像保安一样守门
3. Apache Doris数据层
超能的大仓库:
1️⃣ 专门存海量数据(比如亿条销售记录),支持实时快速查询
。
2️⃣ 类似Excel但更强大,几十人同时问“不同区域销量”也能秒回结果
。
3️⃣ 适合实时分析
,老板临时要报表也不卡壳。
4. 智能可视化BI层
数据变成看得懂的图表
:
1️⃣ 把冷冰冰的数据变成柱状图、折线图,一眼看懂趋势
2️⃣ 自动标注重点,比如高亮显示异常下跌的月份
3️⃣ 像智能助手一样告诉你:“华南区Q1增长300%,建议增加库存”
第二步|撕代码
确定好方案后,即刻开撕代码。
环境准备
1. Doris环境
如果已经有Doris集群,直接用即可。
若当前还没Doris环境,可以参考Doris官方文档,基于Docker或本地化快速部署搭建一套Doris集群 🔗 :https://doris.apache.org/zh-CN/docs/dev/gettingStarted/quick-start
2. DeepSeeek环境
由于DeepSeek V3本地Ollama部署只有671b
,故而选择了用API形式。
本文选用的是火山引擎平台(免费额度,个人基本够用
):参与入口:https://volcengine.com/L/i5aqYFPT/ 邀请码:VRGDULS6
3. Python环境
本次使用的Python版本是3.8.17
,相关的包都可以畅通无阻的install(建议用conda管理py环境):
pip install langchain
pip install langchain-community
pip install -qU langchain-community
pip install sqlalchemy
pip install --upgrade --quiet pymysql
pip install streamlit
pip install dbutils
pip install faiss-cpu
4. Ollama环境
本次用到的embeddings model依旧是bge-m3
。
需要本地安装Ollama,然后进行启动并安装对应包即可:ollama pull bge-m3
代码实现
经过一臻和老崔七七四十九秒的编写调试,完整代码如下:
"""
Doris BI Intelligent Analysis Assistant Demo - Streamlit app that combines vector embeddings
and LLM to query a Doris database and local knowledge base.
"""
import os
import logging
from typing import List, Dict, Any, Union, Optional
import pymysql
import streamlit as st
from dbutils.pooled_db import PooledDB
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import FAISS
from langchain.agents import Tool, initialize_agent, AgentType
from langchain.tools import BaseTool
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_core.agents import AgentAction, AgentFinish
from langchain_core.callbacks import BaseCallbackHandler
from langchain_text_splitters import CharacterTextSplitter
# Configure logging and constants
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
INPUT_DIR = "./INPUT_DIR"
KNOWLEDGE_BASE_PATH = "./KNOWLEDGE_BASE_PATH"
DB_CONFIG = {'user': '{待补齐user}', 'password': '{待补齐password}', 'host': '{待补齐host}', 'port': 9030,
'database': '{待补齐database}', 'charset': 'utf8'}
LLM_CONFIG = {'base_url': 'https://ark.cn-beijing.volces.com/api/v3',
'api_key': "{待补齐api_key}",
'model': '{待补齐model}'}
# Initialize embeddings model
embeddings = OllamaEmbeddings(model="bge-m3")
class CustomCallbackHandler(BaseCallbackHandler):
"""Handler to track agent thinking process and results."""
def __init__(self):
self.thoughts = []
self.final_result = None
def on_agent_action(self, action: AgentAction, **kwargs):
self.thoughts.append(f"Thought: {action.log}")
def on_agent_finish(self, finish: AgentFinish, **kwargs):
self.final_result = finish.return_values["output"]
class KnowledgeBaseTool(BaseTool):
"""Tool to query the knowledge base."""
name = "Knowledge Base"
description = "Use this tool to answer questions based on the local knowledge base."
def _run(self, query: str) -> str:
try:
vector_store = FAISS.load_local(KNOWLEDGE_BASE_PATH, embeddings,
allow_dangerous_deserialization=True)
docs = vector_store.similarity_search(query, k=3)
return"\n".join([doc.page_content for doc in docs])
except Exception as e:
returnf"Error querying knowledge base: {str(e)}"
asyncdef _arun(self, query: str) -> str:
raise NotImplementedError("Async not supported")
class DorisQueryTool(BaseTool):
"""Tool to query the Doris database."""
name = "Doris Query"
description = "Use this tool to query the Doris database for specific data."
def _run(self, query: str) -> Union[List[Dict[Any, Any]], str]:
conn = cursor = None
try:
pool = PooledDB(creator=pymysql, blocking=True, maxconnections=30,
mincached=10, **DB_CONFIG)
conn = pool.connection()
cursor = conn.cursor()
cursor.execute(query)
columns = [col[0] for col in cursor.description]
return [dict(zip(columns, row)) for row in cursor.fetchall()]
except Exception as e:
returnf"Error executing SQL query: {str(e)}"
finally:
if cursor: cursor.close()
if conn: conn.close()
asyncdef _arun(self, query: str) -> str:
raise NotImplementedError("Async not supported")
def initialize_agent_tools():
"""Initialize the agent with required tools."""
try:
tools = [
Tool(name="Knowledge Base", func=KnowledgeBaseTool()._run,
description="Use this tool to answer questions based on the local knowledge base."),
Tool(name="Doris Query", func=DorisQueryTool()._run,
description="Use this tool to query the Doris database for specific data.")
]
return initialize_agent(tools=tools, llm=ChatOpenAI(**LLM_CONFIG),
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True, verbose=False)
except Exception as e:
logger.error(f"Failed to initialize agent: {e}")
raise
def create_streamlit_interface():
"""Create the Streamlit user interface."""
st.title("Doris BI 智能分析小助手")
with st.expander("Hello Doris ChatBI", expanded=True):
user_question = st.text_input("请在对话框内输入您的问题")
prompt_template = """
你是Doris BI小助手,请遵循以下规则进行回答:
1. 首先判断用户问题意图,不允许说脏话,委婉拒绝不良问题并中断处理
2. 根据用户问题,确定数据源,生成SQL,将结果按用户要求格式化
3. 生成SQL前检查知识库内容,确认参数无错别字,SQL必须包含库名
4. 只根据知识库内容回答,未知问题回答不知道
5. 输出格式精美,使用适当的分隔符、表情和符号美化
"""
query = f"{user_question}\n{prompt_template}"
# Initialize session state
if"callback_handler"notin st.session_state:
st.session_state.callback_handler = CustomCallbackHandler()
if"agent"notin st.session_state:
try:
st.session_state.agent = initialize_agent_tools()
except Exception as e:
st.error(f"初始化失败: {str(e)}")
return
# Process query
if user_question:
try:
st.session_state.agent.run(query, callbacks=[st.session_state.callback_handler])
st.write("思考过程如下: \n")
for thought in st.session_state.callback_handler.thoughts:
st.write(f" {thought}")
st.write("最终结果如下: \n")
if st.session_state.callback_handler.final_result:
st.write(st.session_state.callback_handler.final_result)
else:
st.write("处理过程中出现问题,未能生成结果。")
except Exception as e:
st.error(f"处理问题时出错: {str(e)}")
else:
st.write("Waiting for your question....")
def load_documents_to_vector_store(input_dir: str, output_dir: str) -> None:
"""Load documents, create embeddings, save to FAISS index."""
try:
documents = []
for filename in os.listdir(input_dir):
if filename.endswith(".txt"):
loader = TextLoader(os.path.join(input_dir, filename), encoding="utf-8")
documents.extend(loader.load())
ifnot documents:
logger.warning("No documents were loaded.")
return
texts = CharacterTextSplitter(chunk_size=500, chunk_overlap=50).split_documents(documents)
vector_store = FAISS.from_documents(texts, embeddings)
os.makedirs(output_dir, exist_ok=True)
vector_store.save_local(output_dir)
logger.info(f"FAISS index saved to {output_dir}")
except Exception as e:
logger.error(f"Error creating vector store: {e}")
raise
def main():
"""Main entry point."""
try:
# Initialize vector store if needed
if os.path.exists(KNOWLEDGE_BASE_PATH):
load_documents_to_vector_store(INPUT_DIR, KNOWLEDGE_BASE_PATH)
create_streamlit_interface()
except Exception as e:
logger.critical(f"应用启动失败: {e}")
st.error(f"应用启动失败: {str(e)}")
if __name__ == "__main__":
main()
代码解析
代码经过精简,很多block没有进行过多地细化深入。主要是为了让大家能够快速熟悉Doris+DeepSeek V3体验ChatBI的完整流程,后续可以结合自己需求,按模块进行调整应用。
代码主流程如下:
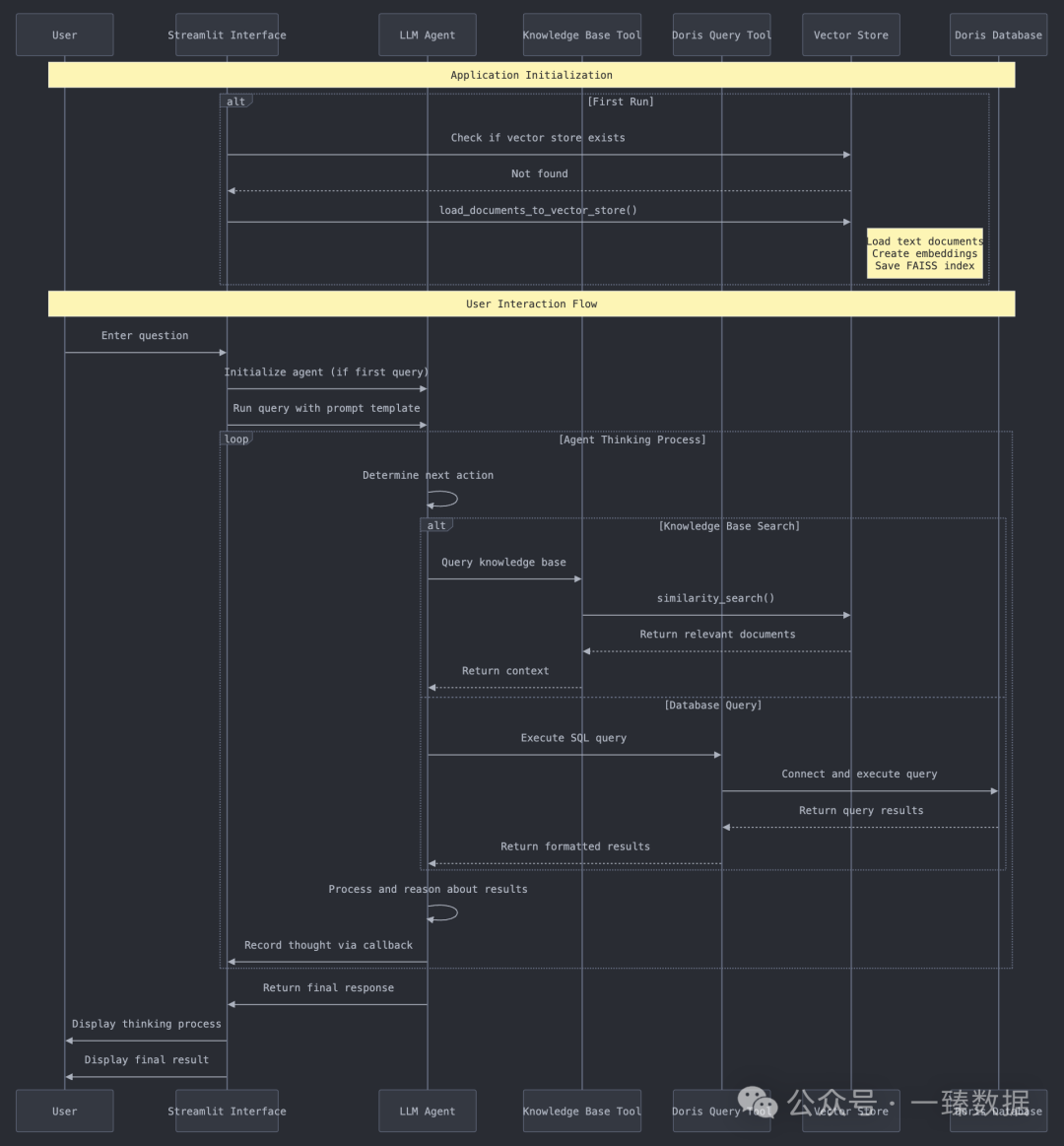
主要分为Application Initialization
和User Interaction Flow
。
1. Application Initialization
主要行为:
1️⃣ os.path.exists
确认向量化知识库路径是否正常
2️⃣ load_documents_to_vector_store
作用好比是一个智能的文档整理员,它的工作流程可以简单理解为:收集文档 -> 拆分内容 -> 转换格式(embeddings
) -> 建立索引(基于本地向量化数据库Faiss
)。
整个过程相当于:把零散的本地文档资料 → 整理成标准格式 → 转换成机器语言 → 建成可快速检索的知识库
。这样后续问答时,LLM就能像图书管理员一样快速找到相关知识了!
2. User Interaction Flow
def create_streamlit_interface
好比BI端,负责:搭建对话窗口 -> 设置应答规则 -> 记忆管理
-> 组装AI助手
-> 智能问答,其中核心:
1️⃣ 记忆管理 CustomCallbackHandler
,主要是记录思考on_agent_action
过程并捕捉最终答案on_agent_finish
。
2️⃣ 组装AI助手 initialize_agent_tools
,主要是基于LLM Agent机制准备工具包KnowledgeBaseTool
和DorisQueryTool
,再把工具包和LLM组装成具备决策能力的AI助手。
相当于给LLM装了个"工具选择器":遇到问题时,先自动判断该查知识库还是查数据库,再调用相应工具获取信息,最后整理成人类能理解的回答。
其它说明
1. 测试文件
主要导入了1个md文件(下载完后,需要改为txt格式,本次测试的demo为txt
):
🔗 Doris版本最新发布文档:https://github.com/apache/doris-website/blob/master/i18n/zh-CN/docusaurus-plugin-content-docs/current/releasenotes/all-release.md
2. 提示词
构建agent chain时,prompt提示词这块值得一提:
prompt_template = """
你是Doris BI小助手,请遵循以下规则进行回答:
1. 首先判断用户问题意图,不允许说脏话,委婉拒绝不良问题并中断处理
2. 根据用户问题,确定数据源,生成SQL,将结果按用户要求格式化
3. 生成SQL前检查知识库内容,确认参数无错别字,SQL必须包含库名
4. 只根据知识库内容回答,未知问题回答不知道
5. 输出格式精美,使用适当的分隔符、表情和符号美化
"""
大家结合应用时可以个性化调整 ⬆️
3. ChatBI应用场景
ChatBI的企业级应用,通常可以归纳为三个递进式的智能场景:
1️⃣ 智能问答查数据:好比给大家配了个"数据助手",用户用大白话提问(比如"上个月哪个区域卖得最好?"),系统通过知识图谱
的语义理解能力,自动关联数据库中的区域、销售额等字段,秒级生成精准查询结果。这层能力覆盖了80%的日常数据需求,让不会写代码的业务人员也能自助查数。
2️⃣ 对话式做报表:在查数基础上,系统会像设计师一样主动给建议——知识图谱能识别"销售额趋势"需要折线图,"区域对比"适合柱状图。用户只需在自动生成的图表草稿上微调颜色、排序,就能快速组装出可视化看板
。这种"AI推荐+人工润色
"的模式,比传统拖拽式BI效率提升5倍以上。
3️⃣ 深度分析找规律:当用户追问"为什么某区域销量突降?",知识图谱会联动供应链、市场活动等多维数据,自动生成归因报告。更高级的场景还能预测下季度业绩、识别异常波动风险。这相当于给企业配备了24小时在线的"数据分析师",用AI挖掘人工难以察觉的数据关联
。
本文Demo只实现了1️⃣ 智能问答查数据 中的部分模块。真正去企业级落地,还需要结合知识图谱
,类比为一种语言到结构化存储
的映射机制,但两者的对应关系并非简单的库表结构,而是通过语义网络实现的深层知识关联。简而言之,需要实现:
实体映射:自然语言中的名词 → 知识图谱的节点(类似数据库主表)⬇️
关系映射:自然语言中的谓语 → 知识图谱的边(类似关系型数据库外键)⬇️
语境映射:语言隐含逻辑 → 图谱的子图结构(类似数据库视图)⬇️
知识更新:语言的新表述 → 图谱的Schema扩展(类似DDL语句)⬇️
验证机制:语言生成结果 → 图谱的约束检查(类似数据库事务)✅
第三步|验结果
代码编写调试完后,来对比下结果。
首先,由于借助了streamlit
进行UI化,所以在启动程序的时候,需要在终端输入如下命令进行启动:streamlit run {补齐对应的py完整文件名|xxx.py}
执行对应的streamlit run
命令后,程序会在电脑默认浏览器中打开一个BI交互端:
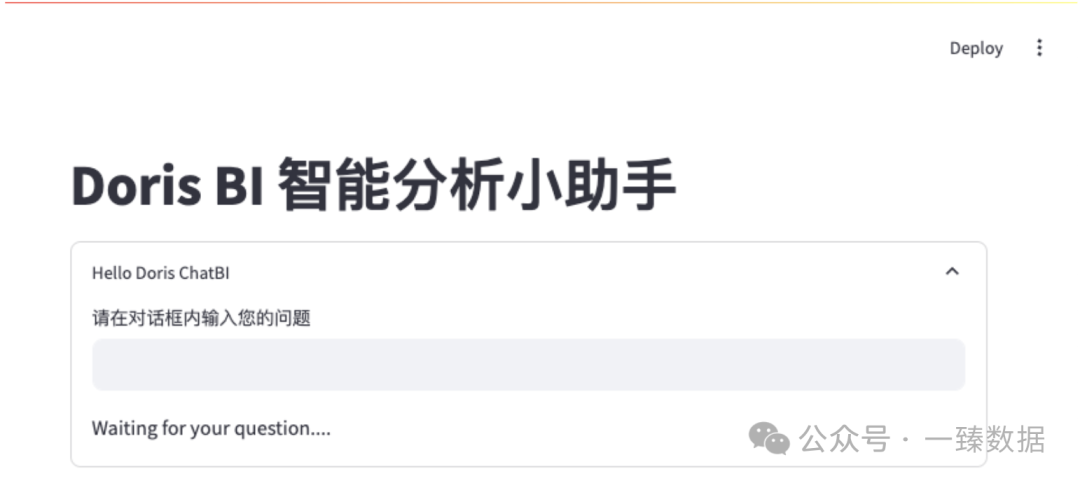
随后,我们先基于测试的本地文件all-release.txt
进行一个简单测试:
doris最新的版本是多少
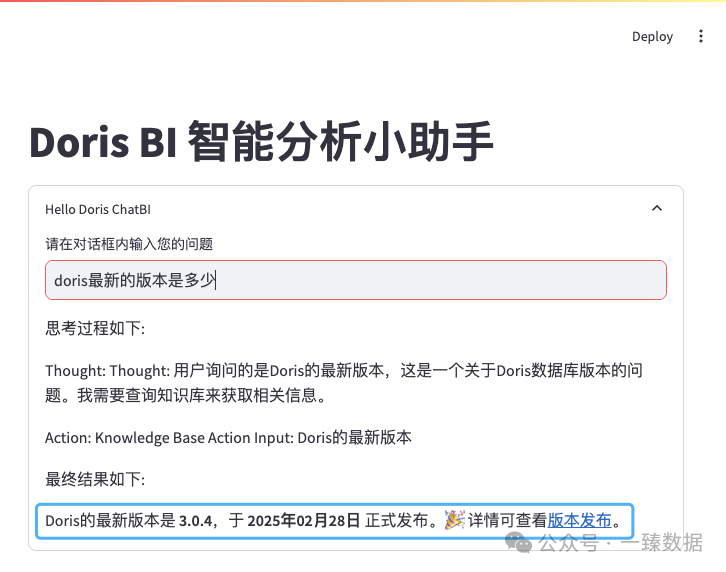
结果正确,和Doris官方文档介绍的一样。
接着,我们来试试简易版Text2SQL
的场景:
请问zbh_test这个db里哪张表的数据量最大,一共有多少条记录
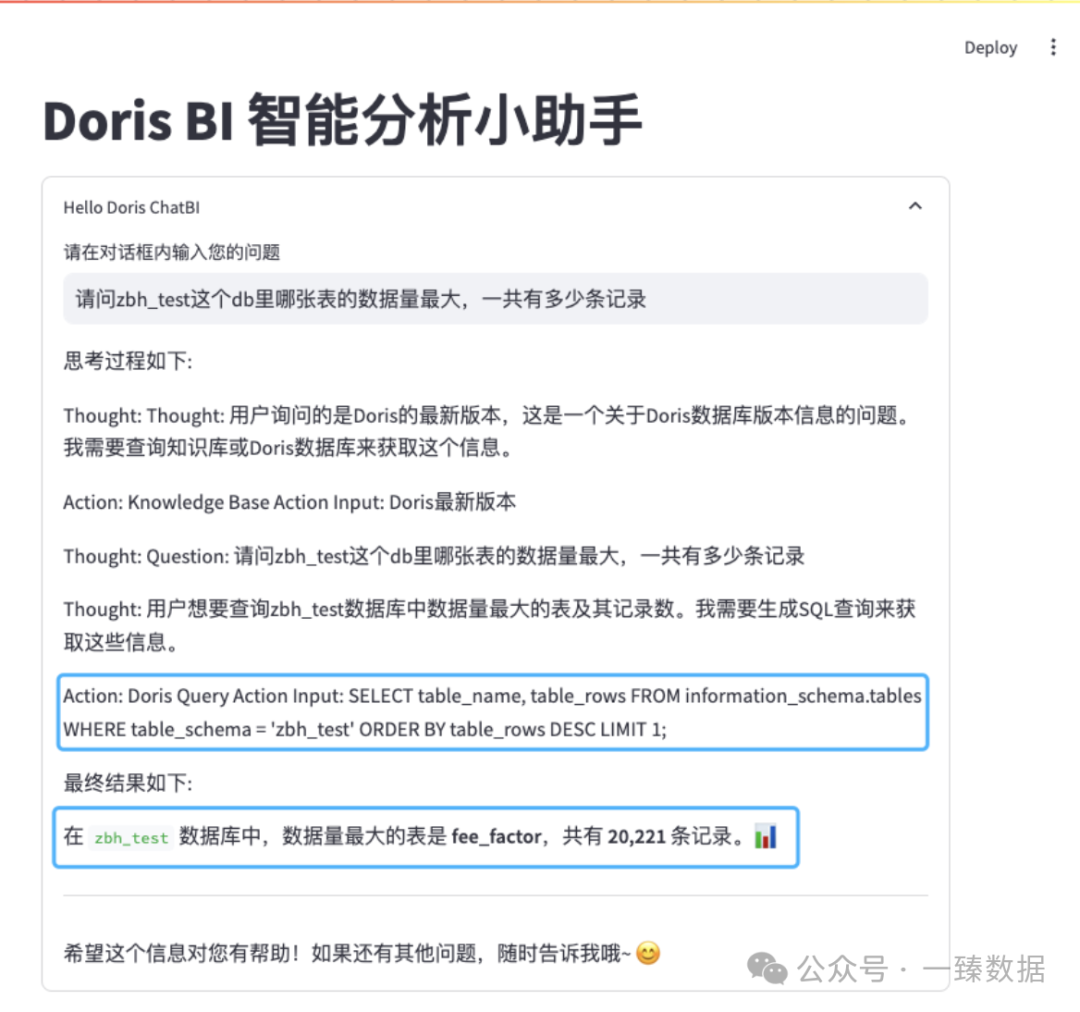
结果正确,和Doris的库表信息一致!
结语
当Doris的极速分析能力遇上DeepSeek的强大推理能力
,数据分析的大门向所有人敞开。从此,数据不再是技术专家的专属领地,而是每位成员的智能助手。
曾经,我们苦苦等待报表生成,辛苦解读数据含义;如今,我们只需一句话,数据便会主动讲述它的故事
。
下次当你还在为复杂SQL挠头时,不妨想想:也许是时候让AI成为你的数据分析搭档了。毕竟,科技的意义,不就是让工作更简单,让创意更自由吗
?
至此,Hello Doris ChatBI
体验完成。后续将会结合知识图谱
,发布Doris ChatBI企业应用级的完整版,敬请期待!

完
一臻数据致力于大数据AI时代的前沿内容分享,会持续分享更多有趣有用有态度的知识。同时也欢迎大家投稿,共建共进,帮助圈友们冲破认知壁垒,实现自我提升!
另外,整理了份 一臻数据知识库 ,其中包含 Apache Doris和 Data+AI 的学习资料、学习课程、白皮书、研究报告、行业标准 和 实践指南 等内容,会持续更新,欢迎关注公众号,免费领取。
🔗 欢迎扫描下方二维码 ⬇️ 备注 666 免费领取资料  加入Doris官方群和全球最活跃的PowerData数据社区❗️
加入Doris官方群和全球最活跃的PowerData数据社区❗️

往期推荐

点击下方蓝字关注一臻数据
