




前文分享 OB 日志流时主要说副本技术没讲分片技术。本文把这两个技术放在一起分析。为了便于理解这个设计,这里会从 MPP 数据库角度去看这个分布式技术。
MPP 数据库的历史
Massively Parallel Processing (MPP)
概念最早萌芽于高性能计算领域(1972年),那时候还依赖专有硬件,主要服务于军事与科研场景,所以不为大多数人所知。 MPP 的兴起是在软件行业。1992年 TeraData
发布首个商用 MPP 数据库,沃尔玛率先使用,实现 TB 级别数据分析,推动 MPP 在商业领域发展。2005 年开源数据库 PostgreSQL
衍生出首个开源 MPP 数据库 GreenPulm
,基于 x86 服务器部署,极大的降低了存储成本。2012年 Cloudera 发布了基于 Hadoop/HDFS 存储的 MPP 架构的实时 SQL 引擎 Impala。这个倒逼了传统 MPP 数据库进一步优化其实时分析能力。 2012 年 AWS 推出 Redshift (基于 ParAccel MPP 引擎),开启云数仓时代。同时诞生的还有 Snowflake ,推出计算存储分离架构颠覆了传统数仓一体化架构。同时兴起的还有向量化引擎能力。在国内兴起 MPP 架构的数据库还有 TiDB、 GBase 、ADB 、GaussDB for DWS、OceanBase 。
由于个人只接触了 YMatrixDB(基于GreenPulm
二次开发)、GBase 8a、TiDB、OceanBase,所以后面对比分析的是只在这四类数据库之间展开。个人观点,仅供参考,欢迎留言讨论。
分片或分布技术
分片和副本技术都属于分布式技术概念,不同文档里看到的术语可能相同或者相似。为了便于理解先解释一下术语。分片作为动词概念,术语有 partition
、distribute
等,作为名词概念时有 partition
、segment
等。本质都是将数据表拆分为更小的单位。
就拆分技术而言,又分物理层面拆分和逻辑层面拆分。当指代物理层面拆分的时候,用物理分布(distribution
)更为贴切,描述的是更细粒度的数据在存储层面上的分布特征。这个物理拆分后的分片,用 segment
描述最为精确。这个分布位置可能是单节点也可能是多节点,实际场景多是后者。分布特征具体是指按照某一列采取某种分布策略,分布策略有 HASH 分布、随机分布等。
以 GBase 8a MPP 数据库为例,建表如下:
CREATE TABLE"customer" (
"c_customer_sk" int(11) NOTNULL,
"c_customer_id" char(16) NOTNULL,
"c_current_cdemo_sk" int(11) DEFAULTNULL,
"c_current_hdemo_sk" int(11) DEFAULTNULL,
"c_current_addr_sk" int(11) DEFAULTNULL,
"c_first_shipto_date_sk" int(11) DEFAULTNULL,
"c_first_sales_date_sk" int(11) DEFAULTNULL,
"c_salutation" char(10) DEFAULTNULL,
"c_first_name" char(20) DEFAULTNULL,
"c_last_name" char(30) DEFAULTNULL,
"c_preferred_cust_flag" char(1) DEFAULTNULL,
"c_birth_day" int(11) DEFAULTNULL,
"c_birth_month" int(11) DEFAULTNULL,
"c_birth_year" int(11) DEFAULTNULL,
"c_birth_country" varchar(20) DEFAULTNULL,
"c_login"char(13) DEFAULTNULL,
"c_email_address" char(50) DEFAULTNULL,
"c_last_review_date" char(10) DEFAULTNULL,
PRIMARY KEY ("c_customer_sk")
) ENGINE=EXPRESS DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace' distributed by ('c_customer_sk');
GBase 把这种表成为分布表。分布表可以使数据按指定的策略分布存储在不同的主机上,从而实现分布式数据存储和分布式计算,解决大数据存储容量扩展和计算性能扩展的问题。分布策略支持 HASH 分布和 RANDOM 分布,默认创建的表是 RANDOM 分布表,每个节点上只保留部分数据。HASH 分布表关键字是 distributed by
。
GreenPulm
建表也支持 HASH 分布和 RANDOM 分布,并且要求建表时必须指定具体的分布策略。下面是 GreenPulm
建表语法示例。
r_db=# create table t2(id bigint,c1 varchar(50));
psql: NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
r_db=# create table t2(id bigint,c1 varchar(50)) DISTRIBUTED RANDOMLY;
CREATE TABLE
GreenPulm 默认分布策略是 HASH,关键字 distributed by
。如果是随机分布就是 distributed randomly
。
在分布策略上,Gbase 8a
跟 GreenPulm
都支持建表时指定分布策略,只是后者是强制指定。分布策略都有 random
和指定列 hash
分布。具体选择就要结合业务 SQL 特点选择。一般来说业务上高频查询条件列以及列值区分度很高的字段,适合选择用来做 hash
分布列。随机分布的好处是数据随机打散,大批量数据查询的时候可以多个节点并发查询,性能很可能会好很多。但是数据过于分散有时候在少量数据查询上可能还不如不分散。hash
分布就是给了开发者一种根据业务特点选择分布策略的机会,属于高级用法。
TiDB
的做法又不同。TiDB
是计算存储分离架构(GBase 8a
也是,这个不是重点),其存储节点是由 TiKV
组件实现。TiKV
是分布式存储引擎,其数据分布策略是动态范围分片,建表时不能也不需要指定分布策略。这个分片单位叫 Region
,默认大小约 96MB~144MB
(早期版本要小一些),有自动分裂功能。这个分布策略估计跟前面的随机分布特点一样。TiKV
的这个特点也反映了其定位,让开发者不用关心分布式细节。其在 OLAP 场景下性能还不错(还有其他技术的原因),但在 OLTP 场景下这个分布策略导致有时候查询性能可能会下降。
过度的分布式设计,可能导致大量跨节点请求,节点间网络通讯流量相对比较高,网络延时也很难降下去。所有分布式数据库产品软件都会面临这个挑战。
前面讲的都是物理层面拆分,分布式数据库还支持逻辑层面拆分。逻辑拆分技术指的就是分区表技术,根据某一列按照某种分区策略将业务大表划分为更小的逻辑单位(叫分区,partition
)。分区技术不指定存储的分布策略,那是由分布策略去控制。分区技术关心的是数据的逻辑切分。在数据仓库里分区的好处非常大。一般业务流水大表按照流水时间做范围分区。每个时间段(比如说一个月)是一个逻辑分区。当查询这个月数据的时候,数据库只需要扫描特定的一个分区即可,不用做全表扫描。这个叫分区裁剪功能。此外大表历史数据归档清理的时候,分区表只要删除最早的分区即可,这个性能比用 delete
语法删除历史数据要高效的多,并且事务小对数据库影响最低。这就是为什么上面三类 MPP 数据库除了支持存储分布策略外还支持分区表功能。分区表的分区策略相比物理存储分布策略要丰富的多,支持 hash
、range
、list
以及这三者的组合(又叫组合分区)。
逻辑层拆分跟物理层的拆分并不冲突,二者会一起发挥作用。比如说 GBase 8a
里的分区表,每个分区的物理分布又遵循分布策略。如果没有指定就是随机分布。即分区表的所有分区的数据又分散到 GBase 8a
所有节点上(严格说是虚拟集群的所有节点)。 但是这两个拆分技术的叠加后的效果的好坏并不一定好。
分布式技术的优势是能整合多级资源并行处理。大批量数据读取的时候,如果集群多机资源很丰富,这种并行处理会带来性能的提升;如果集群多机资源已出现短板(瓶颈),则可能会出现有些查询性能下降。这里出现短板的资源可能是 CPU、内存、存储或者网络。所以 MPP 数据库部署前,要尽可能最大化主机硬件能力、网络能力等。多核CPU、大内存(1TB+)、NVMe SSD、10Gb
或 25Gb
网络等,都可以提升 MPP 数据库的性能。MPP 数据库上线后就做好集群节点资源的监控。
在 OLAP 场景里,并发的查询不会很高,单次查询的数据量会很大。有些实践经验会建议分区策略跟分布策略避免用同一个列做hash
分布,其目的就是最大化并行能力。 此外数据库 SQL 引擎里一般还有并行的语义(parallel hint
),这能进一步增加并行的数量(有可能遭遇 CPU 瓶颈)。 在 OLTP 场景里,并发的查询会很高,单次查询的数据量不大。单次查询过度的并行化对查询性能可能会适得其反。在这个场景里最佳实践是单次查询尽可能避免分布式,并行的会话数可以非常大。数据分散到多个节点上,就可以将这些数据的查询会话分散到多个节点上。分布式数据库自身又有很好的扩展性,所以能满足的业务会话数和 QPS 非常高。这里关键点就是分区和分布策略中的列的选择(随机分布策略就不友好了)。
两种场景特点和优化思路不完全相同,局部可能还有些冲突,所以一个数据库要满足两种场景(即通常说的混合负载,HTAP
)挑战非常大。像 GreenPulm
、GBase 8a
就只能用于 OLAP
场景。有的数据库据说能满足两种场景,可能用的是两个数据库产品分别去满足对应业务场景。这种做法还需要在数据库外部做数据同步(从交易库同步到数据仓库,类似传统数仓架构)。TiDB
也能满足两种场景,关键就是数据按照不同格式存储了两份。 OLTP
查询数据从 TiKV
引擎读写(使用的是行存),OLAP
查询数据从 Tiflash
引擎读(使用的是列存)。TiKV
到 Tiflash
的数据同步是 TiDB
内部机制(使用Raft
协议),这个不用运维介入处理,就比外部同步体感要好很多)。列存是提升 OLAP
查询的技术,此外还有向量化引擎、物化视图等等很多技术,不是本文重点就不展开了。
还有一种特殊的分布策略不是拆分,而是数据复制到所有节点,这个叫复制表。GBase 8a 和 GreenPulm 都支持这种用法,关键字 distributed replicated 。这也是一种特殊场景用法,适合维度表等变化不频繁但又被很多大表关联查询的情形,属于用空间换性能的思路。
有关分布策略的介绍就到这里,这里没法给出一个具体的方法去评判哪种方案好。在做选型的时候需要根据业务特点具体问题具体分析。
副本以及分布特征
前面讲的是数据拆分,现在来说数据多副本。拆分解决的是性能、扩展性方面的问题,多副本解决的是高可用、容灾多活的问题。
分布式数据库为了高可用都有多副本,以应对节点故障时数据可用性问题。MPP 数据库也同理。 一般 OLAP 业务场景对可用性要求也不是很高,但是长时间故障也不能接受。虽然备份恢复可以应对故障,但是数据仓库节点数据量往往非常庞大(TB
级别),恢复的时间可能会比较久。所以 MPP 数据库肯定会有多副本。区别只是副本的数量和分布位置。
副本的数量关系到硬件成本,OLAP 数据库本来就非常大,数据冗余一份,存储投入就翻倍。GreenPulm
的副本数量是在部署数据库的时候就确定了。GreenPulm
文档里并不称之为副本,而是镜像(mirror
)。一般数据存储节点需要两台,那么这两台可以配置为镜像节点。这个跟传统的主备库有点相似但又不完全相同。GreenPulm
只支持一个主节点(priamry
)和一个镜像节点,并且镜像节点不支持写也不支持读。镜像节点的定位就是灾备,在主节点故障的时候会自动切换到镜像节点(角色变为primary
)。有趣的是主节点如果没有故障,是不能做在线切换。
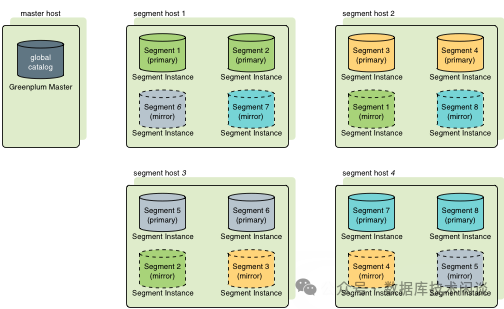
GreenPulm单机多实例部署下的镜像
虽然 GreenPulm
的镜像节点不提供读写服务,用户可以选择在主机上启动多个 GreenPulm
实例,其中主节点和镜像节点角色错开使用,也可以实现所有服务器都提供读写服务,进而提升机器资源利用率。下面是一个真实案例。
SELECT
dbid, -- 数据库实例编号
content, -- Segment 的内容标识(相同的 content 表示主备关系)
role, -- 角色 (p=Primary主节点, m=Mirror镜像)
hostname, -- 所在主机名
address, -- IP地址
port, -- 监听端口
datadir -- 数据存储路径
FROM gp_segment_configuration
ORDERBYcontent, role;
dbid | content | role | hostname | address | port | datadir
------+---------+------+----------+----------+------+---------------------------------------------
26 | -1 | m | gpserver02 | gpserver02 | 5432 | data/gpdata_2023/master/mxseg-1
1 | -1 | p | gpserver01 | gpserver01 | 5432 | data/gpdata_2023/master/mxseg-1
14 | 0 | m | gpserver03 | gpserver03 | 6006 | data/gpdata_2023/mirror/mxseg0
2 | 0 | p | gpserver02 | gpserver02 | 6000 | data/gpdata_2023/primary/mxseg0
15 | 1 | m | gpserver03 | gpserver03 | 6007 | data/gpdata_2023/mirror/mxseg1
3 | 1 | p | gpserver02 | gpserver02 | 6001 | data/gpdata_2023/primary/mxseg1
16 | 2 | m | gpserver03 | gpserver03 | 6008 | data/gpdata_2023/mirror/mxseg2
4 | 2 | p | gpserver02 | gpserver02 | 6002 | data/gpdata_2023/primary/mxseg2
17 | 3 | m | gpserver03 | gpserver03 | 6009 | data/gpdata_2023/mirror/mxseg3
5 | 3 | p | gpserver02 | gpserver02 | 6003 | data/gpdata_2023/primary/mxseg3
18 | 4 | m | gpserver03 | gpserver03 | 6010 | data/gpdata_2023/mirror/mxseg4
6 | 4 | p | gpserver02 | gpserver02 | 6004 | data/gpdata_2023/primary/mxseg4
19 | 5 | m | gpserver03 | gpserver03 | 6011 | data/gpdata_2023/mirror/mxseg5
7 | 5 | p | gpserver02 | gpserver02 | 6005 | data/gpdata_2023/primary/mxseg5
20 | 6 | m | gpserver02 | gpserver02 | 6011 | data/gpdata_2023/mirror/mxseg6
8 | 6 | p | gpserver03 | gpserver03 | 6000 | data/gpdata_2023/primary/mxseg6
21 | 7 | m | gpserver02 | gpserver02 | 6006 | data/gpdata_2023/mirror/mxseg7
9 | 7 | p | gpserver03 | gpserver03 | 6001 | data/gpdata_2023/primary/mxseg7
22 | 8 | m | gpserver02 | gpserver02 | 6007 | data/gpdata_2023/mirror/mxseg8
10 | 8 | p | gpserver03 | gpserver03 | 6002 | data/gpdata_2023/primary/mxseg8
23 | 9 | m | gpserver02 | gpserver02 | 6008 | data/gpdata_2023/mirror/mxseg9
11 | 9 | p | gpserver03 | gpserver03 | 6003 | data/gpdata_2023/primary/mxseg9
24 | 10 | m | gpserver02 | gpserver02 | 6009 | data/gpdata_2023/mirror/mxseg10
12 | 10 | p | gpserver03 | gpserver03 | 6004 | data/gpdata_2023/primary/mxseg10
25 | 11 | m | gpserver02 | gpserver02 | 6010 | data/gpdata_2023/mirror/mxseg11
13 | 11 | p | gpserver03 | gpserver03 | 6005 | data/gpdata_2023/primary/mxseg11
(26 rows)
GBase 8a
数据库的副本策略更丰富,在创建虚拟集群后可以为数据库指定副本数。备副本数可以是 1
也可以是 2
,取决于高可用能力和存储成本方面的考虑。但是 GBase 8a
跟前面不同,所有节点里都有主副本。前面说了 GBase 8a
的表物理分布就是分散到虚拟集群的所有节点,每个数据分片就是一个 segment
。那么每个 segement
还可以有多个副本。这个是虚拟集群全局层面的设置。复杂的地方在不同 segment
的备副本或主副本一定不在一起。GBase 8a
在为每个节点上的主副本挑选备副本节点的时候,并不是选择下一个机架的对等节点,而是可以选择下一个机架对等节点的相邻下一个节点以及上一个机架对等节点的上一个节点。这个听起来有点别扭。简单说一下部署 GBase 8a
之前的机器摆放。假设有 9
台服务器,计划用 3
副本策略,那么机器摆放最佳实践是分为三组,分别放到三个机柜,每个机柜三台,且三台都处于机柜的同一个位置。同一个位置称之为对等位置。前面说的这种分布策略要求同一个数据的三副本(1
主2
备)对应的机器分在三个机架,但是不在同一个水平位置。当观察全部数据的主备对应关系就会发现各种交叉,很是复杂。当然复杂是相对而言,也是有规律而言。下面是一个测试环境示例。
[gbase@server061 ~]$ gcadmin distribution gcChangeInfo_vc0.xml p 1 d 2 pattern 1
gcadmin generate distribution ...
gcadmin generate distribution successful
[gbase@server061 ~]$ gcadmin showdistribution
Distribution ID: 2 | State: new | Total segment num: 9
Primary Segment Node IP Segment ID Duplicate Segment node IP
========================================================================================================================
| 10.0.0.61 | 1 | 10.0.0.72 |
| | | 10.0.0.79 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.71 | 2 | 10.0.0.78 |
| | | 10.0.0.63 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.77 | 3 | 10.0.0.62 |
| | | 10.0.0.73 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.62 | 4 | 10.0.0.73 |
| | | 10.0.0.77 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.72 | 5 | 10.0.0.79 |
| | | 10.0.0.61 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.78 | 6 | 10.0.0.63 |
| | | 10.0.0.71 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.63 | 7 | 10.0.0.71 |
| | | 10.0.0.78 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.73 | 8 | 10.0.0.77 |
| | | 10.0.0.62 |
------------------------------------------------------------------------------------------------------------------------
| 10.0.0.79 | 9 | 10.0.0.61 |
| | | 10.0.0.72 |
========================================================================================================================
然后上面还只是两种备副本分布策略中的一种。这里了解一下这种分布特征特点即可。目前我还不是很确认为什么要这么复杂,可能是想让各个节点的负载尽可能均衡一些。
GBase 8a
的主备副本复制协议估计跟传统数据库一样,有异步复制。所以副本数可以是 2
或 3
。TiKV
就不一样,总的数据副本数最好是奇数(偶数没有意义),所以常用的是 2
个备副本。同样所有副本分散到不同机架的服务器上。不一样的地方是 TiKV
的备副本分布策略有自己的特征。
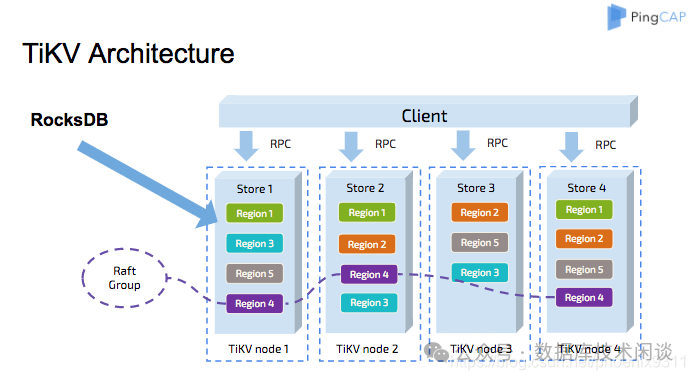
像上面这个图,tikv 节点数可以是 4
台,每个数据分片(图中的region
的副本数量是3
个。至于这3
副本如何在4
节点里分布,看起来也是没有规律的,至少跟前面提到的不一样。不过这个只是表象,关于机器的摆放多副本位置的分布在 TiKV
里也是很有讲究,具体就是容灾隔离范围。TiKV
对运行环境定义了几个名词:可用区 zone
、数据中心 idc
、机架 rack
和主机host
。在 TiKV
部署配置文件里可以通过标签 label
来控制 TiKV
和 TiFlash
的节点属性。跟前面数据库一样,这种复杂的分布策略都是高级用法,都有其特殊的场景。
OB 的分片和多副本
最后再来说说 OceanBase 的设计。OceanBase 是分布式数据库,有些架构和技术原理跟 MPP 数据库特征一样,所以说 OceanBase 是 MPP 架构问题也不大(只是不止于此)。OceanBase 的版本已经发展到了 V4 版本,V1 到 V2/V3, V3 到 V4 架构上都有很大的改进,特别是 V4 版本。
先说 OB 的分片技术。从 V1版本开始 OB 就支持分区表技术(跟 ORACLE 和 MySQL 保持兼容)。在存储层面,比表更小的粒度就是分区。在 V4 以前的版本,比分区粒度更小的概念是 SSTable
(数据的转储和合并可能导致同一个数据存在多个SSTable
里),每个 SSTable
细分为很多宏块(MacroBlock
),每个宏块又由多个微块(MicroBlock
)组成。宏块层面看表数据分布是行存格式,微块层面看数据分布是类似列存模式,所以 V4 以前的版本介绍存储特性的时候说是行列混合。列存不是本文重点这里就不展开说明了。V4 以后的版本,架构有局部重构,事务层跟存储层可能有做一些解耦,新增了 tablet
概念,目前每个分区对应一个tablet
,每个tablet
再对应 sstable
,然后再是宏块、微块。tablet
的设计也是日志流实现的关键。这些是内核代码层面的考虑,对用户是透明的。
OB V4 版本还会继续演进。就目前而言,每个分区的数据还只能在一个节点上,OB 主要靠逻辑层面拆分实现大表数据分散到多个节点。在存储层面推测后续版本还是要支持分区数据分散到多个节点,可能 tablet
设计就是为此准备。这里估计(并不确定)将来一个分区可能可以对应多个 tablet
,而 tablet
会被约束在一个节点内部。
OB 的副本最小粒度前文说是分区,按照文档说来现在要改为是 tablet
(目前二者还是一一对应的)。 OB 每个 tablet
的多副本分布特征非常工整,可以说强迫症用户看了会感觉非常舒服。OB 的备副本可以提供只读服务,所以解决方案里可以做读写分离。此外,OB 也有自己的复制表方案,上一篇介绍过就不赘述了。
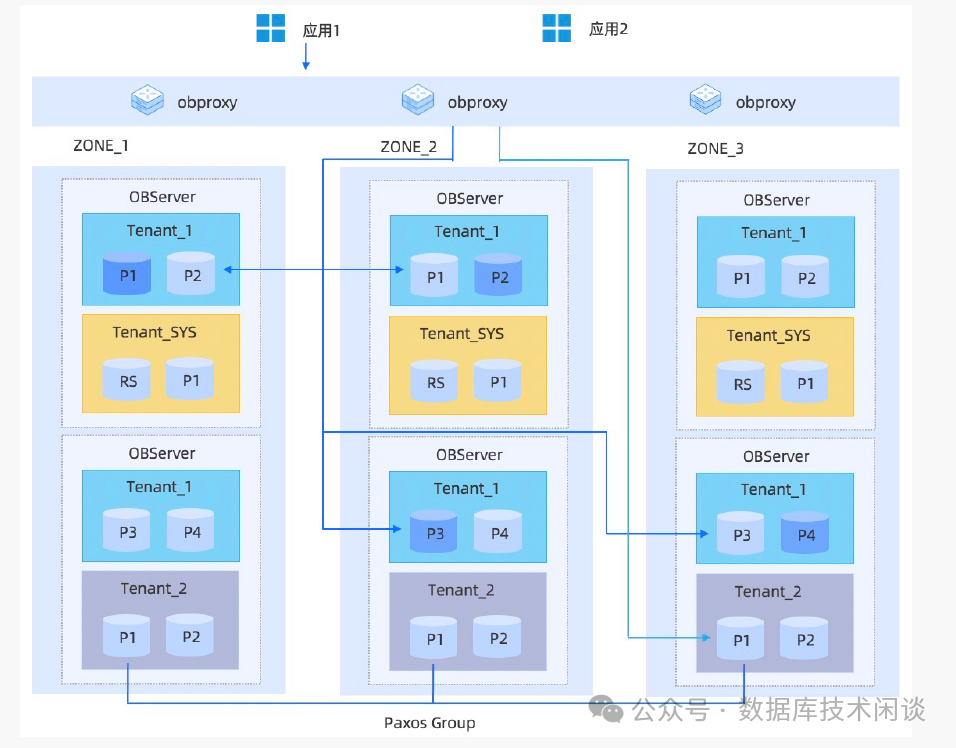
OB V4 主打 HTAP 场景,要同时经受两种场景的挑战,这个会考验 OB 的 SQL 引擎、存储引擎能力。OB 的存储架构还在演进,OB 公有云上已经在试点分布式共享存储了。OB 也在 SQL 引擎里大量应用向量化引擎算子。下个版本会带给我们怎样的惊喜,让我们拭目以待。
对这种数据库拆分和多副本理论感兴趣的朋友,推荐看下面这本书
更多阅读
