




作者: 张婧婧:腾讯微信数据科学家 熊吉祥:腾讯微信 OLAP 研发工程师、StarRocks Contributor
导读:
本文整理自微信工程师在 StarRocks 年度峰会上的分享,介绍了因果推断在业务中的应用,详细阐述了基于 StarRocks 构建因果推断分析工具的技术方案,通过高效算子的支持,大幅提升了计算效率。例如,t 检验在 6亿行数据上的执行时间仅需 1 秒。StarRocks 还实现了实时数据整合,支持多种数据源(如 Iceberg 和 Hive)的无缝访问,进一步增强了平台的灵活性与应用价值。
什么是因果推断
因果推断的核心概念是,从数据中推断一个变量对另一个变量的影响程度。简单来说,它帮助我们了解因果关系的存在和影响力。例如,如果我们上线了一个新的算法模型,能否提升 DAU(日活跃用户)?又或者一个新的产品UI能否增加点击率?这些问题本质上是在问:我们当前所采取的措施是否有效?做得是否正确?因果推断正是用来回答这些问题的,它帮助我们做出科学的决策。
那么,为什么需要使用因果推断呢?难道产品经理或者算法专家不清楚我们当前的做法是否合适吗?实际上,这种不确定性是存在的。根据一项统计数据,全球一些领先互联网公司的“上线成功改动率”远低于预期。具体来说,这些公司在进行大量的 A/B 实验后,最终能带来有效成果的策略比例通常只有10%左右。像必应、Google Ads、Netflix 等公司都呈现出类似的情况[1]。这意味着,实际上即便是行业内的专家,也无法完全确定某一策略是否能够产生预期效果,原因在于他们并非对产品和用户有足够深入的理解。
接下来,有人可能会问,既然如此,为什么不直接通过一些数字进行策略效果评估?例如,进行环比或同比分析,看看某一策略上线后,今天和昨天、或者上个周六和这个周六的数据对比,是否能够反映出该策略的实际效果?然而,这种方式显然存在问题。因为数据本身存在波动、周期性,且受到外界因素的影响,单纯的对比并不足以准确归因于该策略本身的影响。
此外,我们也可以使用时序模型来预测 DAU 的变化。如果没有引入新的模型,我们可以通过旧有的推荐系统模型来预测 DAU 的变化。然而,在实际应用中,即便是预测 DAU 的误差小于1%,也已经算是一个相对精准的模型了。但随着增长的逐渐放缓,单个策略的效果通常难以超过1%,这意味着模型的误差往往比实际增长还要大,因此很难依赖现有的模型来精确评估单一策略的效果。这时,因果推断就显得尤为重要。
什么是AB test?
什么是AB test?

一个经典的例子来自于谷歌的 Gmail 广告优化[2]。最初,谷歌在确定广告中蓝色小链接的颜色时,采用的是传统的方法,即由首席设计师或营销总监拍板决定选用哪种颜色。然而,随着 A/B 测试的引入,谷歌改变了这一做法。他们决定测试 40 种不同的蓝色,来找出哪个蓝色能获得最高的点击率。在实验中,每个颜色方案会被展示给 1% 的用户,经过对比测试,他们最终发现,一种带有轻微紫色调的蓝色,比带有绿色调的蓝色点击率更高。如此细微的调整,竟然为谷歌带来了每年增加2亿美元的广告收入。
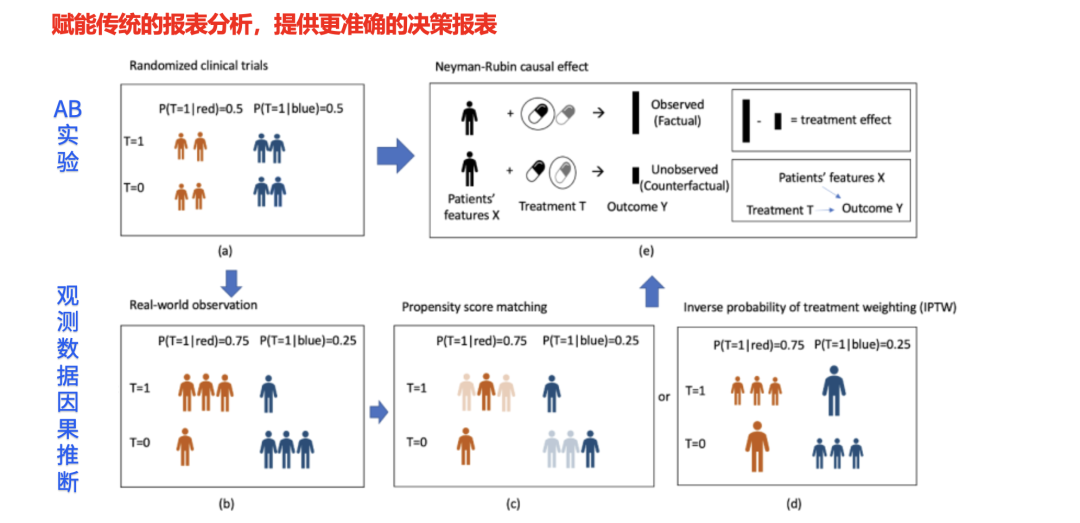
总结来说,因果推断相较于传统的报表分析,能够提供更为准确的决策支持。之前提到的 A/B 测试,就是因果推断中最经典的应用之一。因为 A/B 测试能够通过将用户分为两个完全同质的群体,从而有效地评估策略的影响力。然而,在某些情况下,我们无法进行实验,这时只能依赖离线推断和观测性因果推断的方法,尽量通过数据纠偏,得到尽可能准确的结果。
具体的案例分享,将会在下文进行详细讲解。接下来,讨论一下因果推断与 StarRocks 的结合。为什么我们需要借助 StarRocks 来进行因果推断呢?关键在于我们目前缺乏一种实时且分布式的计算能力。
在互联网应用场景下,数据量通常非常庞大。例如,微信的日活跃用户数就达到了上亿级别。在这种数据量巨大的情况下,现有的因果推断工具大多数是基于单机计算的,通常依赖 Python 等工具进行样本抽样计算。虽然单机模式在某些小规模数据的分析中可以工作,但面对如此庞大的数据量时,单机处理就会面临很大的问题。首先,它会大大降低因果推断的效果,具体体现在两个方面:
互联网场景下,面临大数据量的因果推断,目前的单机采样损失效果。
Power(统计检验显著性)在因果推断中,“Power” 代表的是进行统计检验时,策略有效果的时候能够检验出显著差异的能力。如果检验的 Power 较低,我们就可能无法确认策略的效果是否真实有效。举个例子,如果某一指标的差异为 0.1%,而我们用 1 万样本进行检验,检验的能力只有 0.04,这意味着只有 4% 的概率能发现显著差异。而如果我们使用 1 亿样本进行检验,可以百分之百检验出来。这就显示出样本量对检验结果的影响,单机处理时样本量小、计算能力有限,可能无法准确地发现显著差异。 MSE(模型预估精度)单机计算会影响因果推断模型的预估精度,尤其是在因果推断与机器学习模型相结合时。以因果树模型为例,我们用它来估算每个用户对策略的敏感度。如果我们使用 1 万样本进行训练,估算得到的策略敏感度的误差大约是 2.32。而如果我们使用 1 亿样本,误差可以降低到 0.02,差距达到 100 倍。因此,样本量不足会极大地影响因果推断的精度,单机模式无法满足这一需求。

因果推断模型也需要复杂调参过程,需要实时分析能力
此外,因果推断模型的调参过程也非常复杂。例如,在进行观测性因果推断时,我们需要选择哪些关键的协变量进行匹配,并且匹配粒度的选择也会影响结果的准确性。匹配之后,还需要进行鲁棒性检验,确保结果的稳健性。整个过程涉及许多超参数的调节。如果我们使用的模型每次训练需要 20 分钟,而每次都需要反复调整参数,这样的分析可能需要一整天才能完成,这无疑是非常低效且难以接受的。因此,我们迫切需要一种实时且高效的分析能力,这是我们开发这个项目的初衷。
我们的愿景:ALL in SQL
我们的愿景:ALL in SQL

目前,我们的整个项目已经沉淀为一个名为 Fast Causal Inference 的工具包,旨在提供高效的因果推断功能。这个工具包已被开源,用户可以通过 Python 代码进行调用,使用起来非常便捷。同时,为了提升灵活性,我们还提供了类似于 Spark SQL 的 SQL 查询接口。
该工具包的底层架构基于 OLAP 引擎 和 SQL 解析,支持对海量数据进行高效计算。例如,对于一个包含 6 亿行数据的集,我们可以在秒级别内完成 t 检验(均值检验),计算时间仅需 0.32 秒,速度非常快。此外,该工具包涵盖了多种常用的因果推断模型,能够满足大多数因果分析的需求。
总体架构
总体架构

接下来介绍一下如何通过 StarRocks 实现实时的因果推断能力。在我们的架构中,StarRocks 能够统一整合来自多种数据源的数据,包括 Iceberg 和 Hive 等。通过指定一个 Catalog,用户可以轻松地访问这些不同的数据源。
在 StarRocks 中,我们还提供了高效的因果推断算子,涵盖假设检验、因果森林、匹配算法和回归方法等。借助这些算子,我们可以在海量数据中快速完成因果推断计算。例如,针对6亿行数据,t 检验可以在一秒内完成。
All in SQL:针对最常用的因果模型,我们将其封装为 SQL 查询,用户无需深入了解复杂的查询逻辑,即可快速获得所需结果。 All in DataFrame:对于更高阶的需求,用户可以通过 DataFrame API 定制复杂的因果推断模型,满足个性化的分析需求。
基于这些能力,我们打造了 Fast Causal Inference 项目,使得用户能够在各种场景中应用因果推断,例如异质性分析、观测性分析及实验分析等,为数据探索与决策提供强有力的支持。
Fast-Causal-Inference:实时因果推断的基座
Fast-Causal-Inference:实时因果推断的基座
在 StarRocks 上,我们实现了多种高效的因果推断 UDF,并逐步贡献给社区。这些算子涵盖了广泛的分析需求,包括:
假设检验:t 检验、SRM、permutation 检验、bootstrap 方法、deltamethod、方差估计、非参检验、k-s 检验、分位线检验等。 Uplift 分析:因果树、因果森林、Uplift 曲线等。 匹配分析:Caliper Matching、Exact Matching、SMD Joint Variable Importance Plot等。 回归分析:OLS/WLS、DID、Logistic 回归、AUC 等。

在实现这些因果推断算子的过程中,我们采用了高效的步骤。例如,以 OLS(普通最小二乘法) 为例,我们将核心算法部分(如矩阵乘法)提取出来,作为 UDF 在 StarRocks 中高效实现。以矩阵乘法为例,通过将矩阵的转置与乘法操作优化为聚合函数,能够大大提升计算效率。
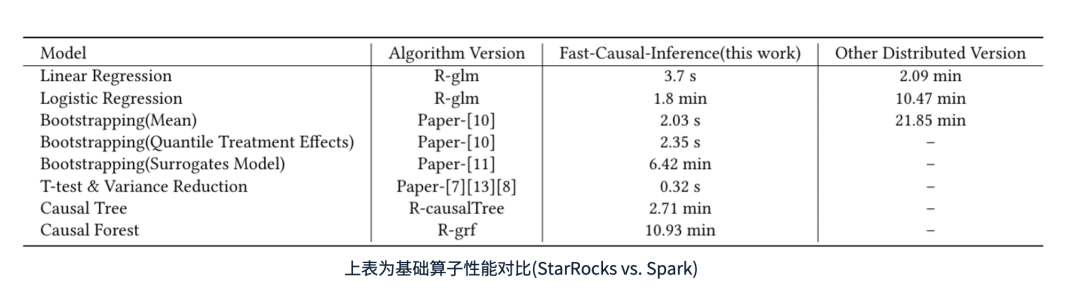
在实现这些因果推断算子后,我们在 StarRocks 上进行了性能测试。下方的表格展示了测试结果,表明我们的 Fast Causal Inference 相较于 Spark 具有显著的性能提升。
某些复杂模型(如 CausalForest 和长短期记忆学习模型)难以用单一的 UDF 或 SQL 直接表达; 公司内部的大数据组件广泛采用标准 SQL 语法。为了降低用户的使用和学习成本,我们开发了 Causal Compiler,使用户可以通过简单的 SQL 函数表达复杂的因果推断模型。
Causal Compiler 负责将用户编写的 SQL 自动展开为 StarRocks 可直接执行的高效 SQL。例如,在 OLS(普通最小二乘法) 训练过程中,编译器会将其拆解为一系列矩阵运算,并最终执行优化后的计算过程。下图展示了该转换的示例。

在 All in SQL 方案的基础上,我们进一步为高阶数据分析师提供了更加便捷的 API,推出了 All in DataFrame。这一方案旨在简化数据操作,提高开发效率和生产力。
以 PSM(倾向性得分匹配) 为例,其典型的处理流程如下:
数据预处理 计算倾向性得分 进行匹配 结果检验

如果使用 SQL 实现该流程,需要构造多个 CTE(公共表表达式),逐层进行处理。例如:先进行数据预处理,再划分训练集,计算倾向性得分,最后进行 t 检验。这种方式虽然可以完成计算,但 SQL 语句较为复杂,不易调试。往往需要运行较长时间后才发现错误,修改和重试的成本较高。

实验自助分析-均值检验和方差削减
实验自助分析-均值检验和方差削减
1.1 均值检验(t 检验)
1.2 方差削减(Variance Reduction)

实验分析中的一大挑战在于:指标噪声较大,而策略收益往往较小,导致显著性难以判断。随着实验规模的扩大,这一问题愈发突出。方差削减的核心思想是利用实验前的协变量(如用户特征、用户标签)降低指标噪声,使得原本波动较大的指标更加稳定,进而提升统计显著性。
CUPED 方差削减:类似于回归模型,利用实验前的数据预测实验期间的指标,并用残差替换原始指标,从而降低方差。 后分层方差削减:先根据协变量对用户进行分层分组,在每个组内计算均值,并加权合成整体指标,从而减少数据波动。
示例: 假设某项人均指标的方差为 0.7,应用方差削减后,方差降至 0.22,显著性的概率大幅提升。

1.3 高阶检验(非参检验)
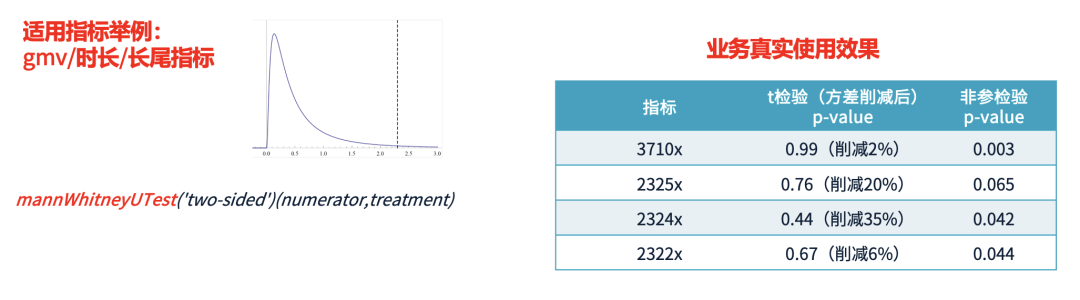

少数用户贡献极高的指标值(如 Top 1% > 100 万),但90%用户集中在较低范围(如 0-1000)。 分布极端不均衡,导致均值检验的方差过大,难以显著。
计算实验组用户的平均排名,并与对照组对比,而非直接对比均值。 这种方法在 StarRocks 内部依赖全样本快速排序,并提供高效计算函数。
采用 t 检验时,某指标的 p 值 > 0.05(不显著),表明实验策略可能无效。 采用非参检验后,p 值 < 0.05(显著),证明该策略确实带来了正向收益。
异质性分析
异质性分析
2.1 典型应用场景
正向用户:收到推送后,愿意回来使用产品,召回成功。
负向用户:觉得推送太烦,甚至卸载 App,带来负面影响。
高敏感作者:得到流量后,投稿量显著增加。 低敏感作者:即使有流量扶持,创作意愿变化不大。
异质性分析可以帮助识别对流量扶持最敏感的作者,优先给他们曝光,从而最大化策略的总收益。
2.2 技术挑战与优化方案
为了更精准地进行异质性分析,我们提供了因果建模工具,包括因果树(Causal Tree)和因果森林(Causal Forest)两种方法。
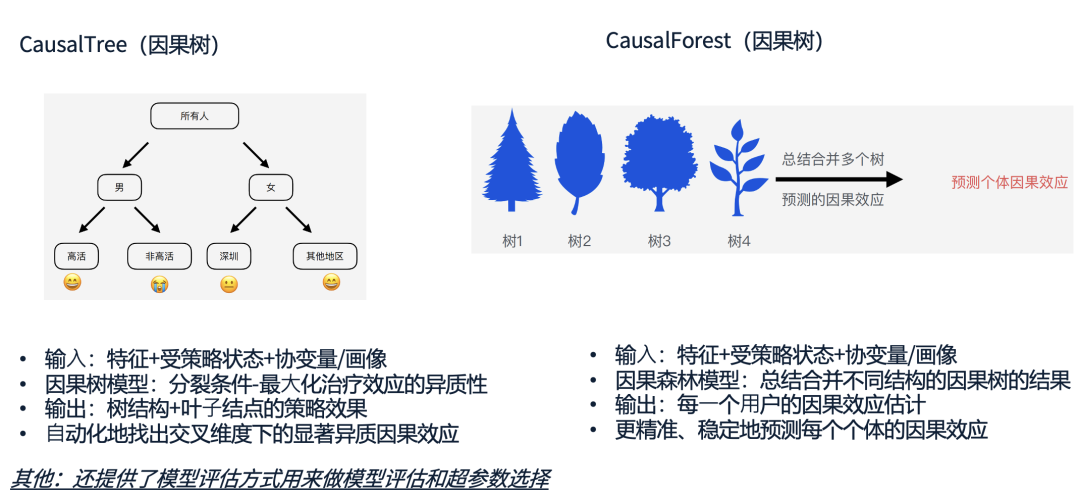
因果树的核心思路是,通过用户的历史画像进行建模,自动划分出对策略最敏感的用户群体。例如,在推送实验中,因果树可能会得出如下结论:最近7天内活跃过的用户更容易被推送召回,而最近30天未活跃的用户则对推送不敏感。这样的分析结果非常直观,业务人员可以直接据此优化投放策略。(上述图片中的画像均为构造举例)
相比之下,因果森林则是一种更鲁棒的建模方式。它会集成多棵因果树,并综合它们的结论,提供更稳定的个体化策略预测。虽然因果森林的结果不如因果树直观,但它可以提供更准确的个体化策略效果估计。
除了这些建模工具,我们还提供了完整的模型评估与优化工具,帮助业务团队选择最优的建模方式。
观测性分析--无法做实验
观测性分析--无法做实验
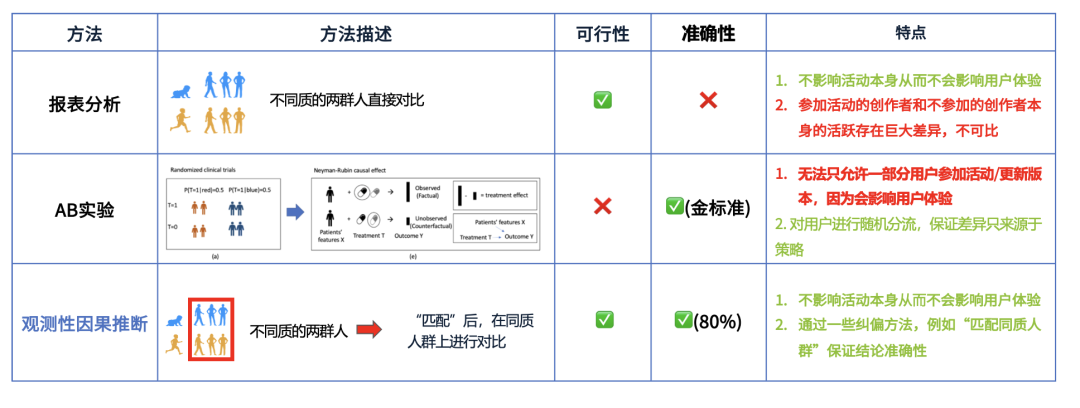
在实际业务中,我们经常会遇到无法进行 A/B 实验的情况。例如,当微信发布新版本时,我们希望评估新版本是否存在 Bug 或者是否对用户行为产生影响。然而,我们不可能让一半用户强制更新,而另一半用户不允许更新,因为这种做法不仅影响用户体验,还可能导致负面反馈。
同样的情况也会出现在运营活动分析中。例如,我们希望评估某个创作者激励活动是否有效,但无法随机分配创作者参加或不参加活动。因为本身愿意参加活动的创作者往往更活跃,而不参加活动的创作者可能创作意愿就较低。如果直接对比这两组创作者的收入变化,结论很可能是有偏的,并不能真实反映活动的影响。
在这种情况下,传统的 A/B 实验无法实施,而直接的报表分析也存在明显偏差。那么,我们应该如何进行合理的评估呢?这时候就要用到观测性因果推断的方法。
观测性因果推断的核心思想可以简单理解为:虽然用户的特征各不相同,但我们可以通过历史数据找到尽可能相似的用户,然后在这些相似的用户之间进行对比。
在腾讯的实践中,我们已经将观测性因果推断的方法应用到微信版本更新的分析中,并且实现了例行化工程,用于检测新版本是否存在潜在问题。例如,每当微信发布一个新的版本,我们都会利用这套方法去分析这个版本是否存在 Bug,比如数据丢失或其他异常情况。具体而言,我们需要先对特征进行预处理,采用Joint Variable Importance Plot的方法去筛选出影响T又影响Y的重要混淆变量,并采用匹配的方法进行平衡混淆变量,最后,需要去验证重要的协变量是否被平衡好,通常会去看SMD或者是直接做T检验看是否显著。
如何验证这套方法是否有效?
AA 版本(无 Bug 版本):这些版本我们已经知道是没有问题的,因此在分析时,我们的检测方法不应该发现显著差异。 AB 版本(存在 Bug 版本):这些版本确实有已知的 Bug,比如数据丢失等异常,因此我们的检测方法应该能够识别出明显的差异。
通过这种方式,我们可以验证:如果在 AA 版本中,分析方法没有错误地检测出差异,而在 AB 版本中,它能够正确地发现 Bug,那么这套方法在当前场景下就是有效的。当然,除了这种方式,我们还做了大量的验证,以确保方法的鲁棒性。
这种因果推断分析不仅适用于微信版本更新,还可以推广到各种运营活动的评估。
协变量筛选
平衡力度的控制
鲁棒性检验
挑选已经验证有效的分析案例,并进行详细的拆解。 将这些案例的分析流程封装成标准化的分析 Pipeline,让业务团队能够直接复用,降低滥用风险
我们目前与社区有着紧密的合作,已经贡献了大量的 StarRocks 算子,并且计划在未来继续将更多的 StarRocks 底层 UDF(用户定义函数)贡献给开源社区。这不仅能增强社区的生态,也能够为更多开发者提供有价值的工具和解决方案。
目前,Fast-Causal-Inference 已经开源,并且已经在 GitHub 上提供了完整的代码和文档。为了更好地展示我们的技术成果,我们特别搭建了一个在线服务。如果希望将代码部署到本地的用户,我们也提供了简单的部署方式。只需要将相关包下载到本地,按照文档的说明操作,就可以开始尝试和使用我们的工具。
开源地址: https://github.com/Tencent/fast-causal-inference
安装:提供了Linux/MacOS/Windows环境的安装镜像;用户可以一键部署,并用notebook环境体验,我们提供了测试数据集和使用示例。
(1)代码部署:git clone https://github.com/Tencent/fast-causal-inference
(2)代码示例参考:https://tencent.github.io/fast-causal-inference/index.html
[2]https://www.theguardian.com/technology/2014/feb/05/why-google-engineers-designers
其他阅读推荐:微信基于 StarRocks 的湖仓一体实践
关于 StarRocks
StarRocks 是隶属于 Linux Foundation 的开源 Lakehouse 引擎 ,采用 Apache License v2.0 许可证。StarRocks 全球社区蓬勃发展,聚集数万活跃用户,GitHub 星标数已突破 9600,贡献者超过 450 人,并吸引数十家行业领先企业共建开源生态。
StarRocks Lakehouse 架构让企业能基于一份数据,满足 BI 报表、Ad-hoc 查询、Customer-facing 分析等不同场景的数据分析需求,实现 "One Data,All Analytics" 的业务价值。StarRocks 已被全球超过 500 家市值 70 亿元人民币以上的顶尖企业选择,包括中国民生银行、沃尔玛、携程、腾讯、美的、理想汽车、Pinterest、Shopee 等,覆盖金融、零售、在线旅游、游戏、制造等领域。


行业优秀实践案例
泛金融:中国民生银行|平安银行|中信银行|四川银行|南京银行|宁波银行|中原银行|中信建投|苏商银行|微众银行|杭银消费金融|马上消费金融|中信建投|申万宏源|西南证券|中泰证券|国泰君安证券|广发证券|国投证券|中欧财富|创金合信基金|泰康资产|人保财险
互联网:微信|小红书|滴滴|B站|携程|同程旅行|芒果TV|得物|贝壳|汽车之家|腾讯大数据|腾讯音乐|饿了么|七猫|金山办公|Pinterest|欢聚集团|美团餐饮|58同城|网易邮箱|360|腾讯游戏|波克城市|37手游|游族网络|喜马拉雅|Shopee|Demandbase|爱奇艺
新经济:蔚来汽车|理想汽车|吉利汽车|顺丰|京东物流|跨越速运|沃尔玛|屈臣氏|麦当劳|大润发|华润集团|TCL |万物新生|百草味|多点 DMALL|酷开科技|vivo|聚水潭|泸州老窖|中免集团|蓝月亮|立白|美的|伊利|公牛
