




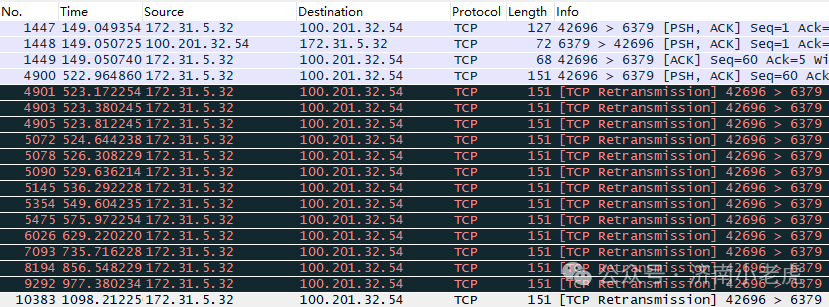
先说一个wireshark的图
关于TCP重传参数
tcp_retries1 :INTEGER
默认值是3
放弃回应一个TCP连接请求前﹐需要进行多少次重试。
RFC 规定最低的数值是3﹐这也是默认值﹐
根据RTO的值大约在3秒 - 8分钟之间。(注意:这个值同时还决定进入的syn连接)
tcp_retries2 :INTEGER
默认值为15
在丢弃激活(已建立通讯状况)的TCP连接之前﹐
需要进行多少次重试。默认值为15,
根据RTO的值来决定,相当于13-30分钟(RFC1122规定,必须大于100秒).
(这个值根据目前的网络设置,可以适当地改小,我的网络内修改为了5)
TCP重传的理解
1. 第一次重传是 4901: 大概是耗时 200ms 开始
2. 第二次重传是 4903: 与上次耗时 200ms 第一次重传间隔是200ms
3. 第三次重传是 4905: 与上次耗时 400ms 累计时间是 800ms
4. 第四次重传是 5072: 与上次耗时 800ms 累计时间是 1.6秒
5. 第五次重传是 5078: 与上次耗时 1.6秒 累计时间是 3.2秒
6. 第六次重传是 5090: 与上次耗时 3.2秒 累计时间是 6.4秒
7. 第七次重传是 5145: 与上次耗时 6.4秒 累计时间是 12.8秒
8. 第八次重传是 5354: 与上次耗时 12.8秒 累计时间是 25.6秒
9. 第九次重传是 5475: 与上次耗时 25.6秒 累计时间是 51.2秒
10. 第十次重传是 6026: 与上次耗时 51.2秒 累计时间是 102.4秒
11. 第十一次重传是 7093: 与上次耗时 102.4秒, 累计时间是 204.8秒
12. 第十二次重传是 8194: 与上次耗时 120秒, 累计时间是 324秒
13. 第十三次重传是 9292: 与上次耗时 120秒, 累计时间是 444秒
14. 第十四次重传是 10383: 与上次耗时 120秒, 累计时间是 564秒
因为没有截取到 第十五次重传, 理论上应该是 684秒左右.
也就是与上面参数的 13min 的显现保持一致.
需要说明, 所有的都需要增加上 RTT的时间, 我这边进行了忽略.
另外根据腾讯云上面的说明
第一次 200ms 其实不算是重传, 而只是第一次传输.
配置是15次, 到那时会出现 第16次的传输. 所以时间是
684+240=924秒.
也就是很多网站上面说的 15min.
如果没有 第十六次 就是 13min.
腾讯云的资料

关于与redisson的关系的推测
Redisson其实是有一个重传机制的.
他的机制在正常网络下应该是没有问题的.
但是如果经过了网闸, 防火墙, 以及其他网络设备.
TCP的keepalive的probe包被失效了, 那么就会存在较为严重的问题.
这个问题应该与redis cluster异常宕机存在相同的情况.
一个节点宕机, redis在retry之后应该会进行全新链接.
但是因为 有重传机制在, 不停的再重试,导致会浪费大约 13min.
又因为redisson的 3try 设置, 会浪费超过40min 才能恢复.
所以这一个 应该与Oracle的设置相仿, 最多设置到 5 , 避免linux内核重发次数过多.
导致问题.
tcp部分内核参数
From: https://blog.csdn.net/zhangxinrun/article/details/7621028
tcp_syn_retries :INTEGER
默认值是5
对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃。
不应该大于255,默认值是5,对应于180秒左右时间。
(对于大负载而物理通信良好的网络而言,这个值偏高,
可修改为2.这个值仅仅是针对对外的连接,对进来的连接,
是由tcp_retries1决定的)
cp_synack_retries :INTEGER
默认值是5
对于远端的连接请求SYN,内核会发送SYN + ACK数据报,
以确认收到上一个 SYN连接请求包。
这是所谓的三次握手( threeway handshake)机制的第二个步骤。
这里决定内核在放弃连接之前所送出的 SYN+ACK 数目。不应该大于255,
默认值是5,对应于180秒左右时间。
(可以根据上面的 tcp_syn_retries 来决定这个值)
tcp_keepalive_probes:INTEGER
默认值是9
TCP发送keepalive探测以确定该连接已经断开的次数。
(注意:保持连接仅在SO_KEEPALIVE套接字选项被打开是才发送.
次数默认不需要修改,当然根据情形也可以适当地缩短此值.
设置为5比较合适)
tcp_keepalive_intvl:INTEGER
默认值为75
探测消息发送的频率,乘以tcp_keepalive_probes
就得到对于从开始探测以来没有响应的连接杀除的时间。
默认值为75秒,也就是没有活动的连接将在大约11分钟以后将被丢弃。
(对于普通应用来说,这个值有一些偏大,可以根据需要改小.
特别是web类服务器需要改小该值,15是个比较合适的值)
重要参数:
tcp_retries1 :INTEGER
默认值是3
放弃回应一个TCP连接请求前﹐需要进行多少次重试。
RFC 规定最低的数值是3﹐这也是默认值﹐
根据RTO的值大约在3秒 - 8分钟之间。(注意:这个值同时还决定进入的syn连接)
tcp_retries2 :INTEGER
默认值为15
在丢弃激活(已建立通讯状况)的TCP连接之前﹐
需要进行多少次重试。默认值为15,
根据RTO的值来决定,相当于13-30分钟(RFC1122规定,必须大于100秒).
(这个值根据目前的网络设置,可以适当地改小,我的网络内修改为了5)
tcp_orphan_retries :INTEGER
默认值是7
在近端丢弃TCP连接之前﹐要进行多少次重试。
默认值是7个﹐相当于 50秒 - 16分钟﹐
视 RTO 而定。如果您的系统是负载很大的web服务器﹐
那么也许需要降低该值﹐这类 sockets 可能会耗费大量的资源。
另外参的考 tcp_max_orphans 。
(事实上做NAT的时候,降低该值也是好处显著的,我本人的网络环境中降低该值为3)
tcp_fin_timeout :INTEGER
默认值是 60
对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间。
对方可能会断开连接或一直不结束连接或不可预料的进程死亡。默认值为 60 秒。
过去在2.2版本的内核中是 180 秒。您可以设置该值﹐
但需要注意﹐如果您的机器为负载很重的web服务器﹐
您可能要冒内存被大量无效数据报填满的风险﹐
FIN-WAIT-2 sockets 的危险性低于 FIN-WAIT-1 ﹐因为它们最多只吃 1.5K 的内存﹐
但是它们存在时间更长。另外参考 tcp_max_orphans。
(事实上做NAT的时候,降低该值也是好处显著的,我本人的网络环境中降低该值为30)
tcp_max_tw_buckets :INTEGER
默认值是180000
系 统在同时所处理的最大 timewait sockets 数目。如果超过此数的话﹐
time-wait socket 会被立即砍除并且显示警告信息。之所以要设定这个限制﹐
纯粹为了抵御那些简单的 DoS 攻击﹐千万不要人为的降低这个限制﹐不过﹐
如果网络条件需要比默认值更多﹐则可以提高它(或许还要增加内存)。
(事实上做NAT的时候最好可以适当地增加该值)
tcp_tw_recycle :BOOLEAN
默认值是0
打开快速 TIME-WAIT sockets 回收。除非得到技术专家的建议或要求﹐
请不要随意修改这个值。(做NAT的时候,建议打开它)
tcp_tw_reuse:BOOLEAN
默认值是0
该文件表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接
这个对快速重启动某些服务,而启动后提示端口已经被使用的情形非常有帮助)
tcp_max_orphans :INTEGER
缺省值是8192
系统所能处理不属于任何进程的TCP sockets最大数量。假如超过这个数量﹐
那么不属于任何进程的连接会被立即reset,并同时显示警告信息。
之所以要设定这个限制﹐纯粹为了抵御那些简单的 DoS 攻击﹐
千万不要依赖这个或是人为的降低这个限制
(这个值Redhat AS版本中设置为32768,但是很多防火墙修改的时候,建议该值修改为2000)
tcp_abort_on_overflow :BOOLEAN
缺省值是0
当守护进程太忙而不能接受新的连接,就象对方发送reset消息,默认值是false
。这意味着当溢出的原因是因为一个偶然的猝发,那么连接将恢复状态。
只有在你确信守护进程真的不能完成连接请求时才打开该选项,该选项会影响客户的使用。
(对待已经满载的sendmail,apache这类服务的时候,这个可以很快让客户端终止连接,
可以给予服务程序处理已有连接的缓冲机会,所以很多防火墙上推荐打开它)
文章转载自济南小老虎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
