




点击上方蓝色字体,选择“设为星标”

01 从RabbitMQ集群中剔除一个节点
1、假设一个前提
以 node1、 node2 和 node3 组成的集群为例,这里有两种方式将 node2 剥离出当前集群。
#关闭node2的rabbitmq服务
rabbitmqctl stop_app
#重置当前节点
rabbitmqctl reset
#本步骤可有可无,起来后的节点是个单点了,node2已经被剔除
rabbitmqctl start_app
#通过查看状态查看是否已经被剔除
rabbitmqctl cluster_status
3、node2已经挂了的情况下,如何剔除node2
此种情况下,可以在两外两个存活的节点上,执行如下命令,比如在node1上执行:
[root@node1 ~]# rabbitmqctl forget_cluster_node rabbit@node2
Removing node rabbit@node2 from cluster
注意:
如果一个节点故障了,不要盲目的重启,盲目重启可能会引起脑裂(网络分区),先在好的节点上执行: rabbitmqctl forget_cluster_node rabbit@故障节点 , 删除故障节点的mnesia数据,在重启.
4、所有节点都故障了,剔除node2才能重启
[root@node1 ~]# rabbitmqctl forget_cluster_node rabbit@node2 –offline
Removing node rabbit@node2 from cluster
* Impersonating node: rabbit@node1... done
* Mnesia directory : /opt/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@node1
[root@node1 ~]# rabbitmq-server -detached
Warning: PID file not written; -detached was passed.
[root@node1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node1
[{nodes,[{disc,[rabbit@node1,rabbit@node3]}]},
{running_nodes,[rabbit@node1]},
{cluster_name,<<"rabbit@node2">>},
{partitions,[]},
{alarms,[{rabbit@node1,[]}]}]
注意:
02 RabbitMQ的日志
1、RabbitMQ的日志种类
RabbitMQ的日志有两种类型,如下图:

2、日志展示
如果使用rabbitmqctl stop_app命令关闭的RabbitMQ应用服务,那么在使用rabbitmqctl start_app命令开启RabbitMQ应用服务时的启动日志和rabbitmq-server的启动日志相同.
如果使用rabbitmqctl stop命令,会将Erlang虚拟机一同关闭,而rabbitmqctl stop_app只关闭RabbitMQ应用服务,在关闭的时候要多家注意他们的区别.
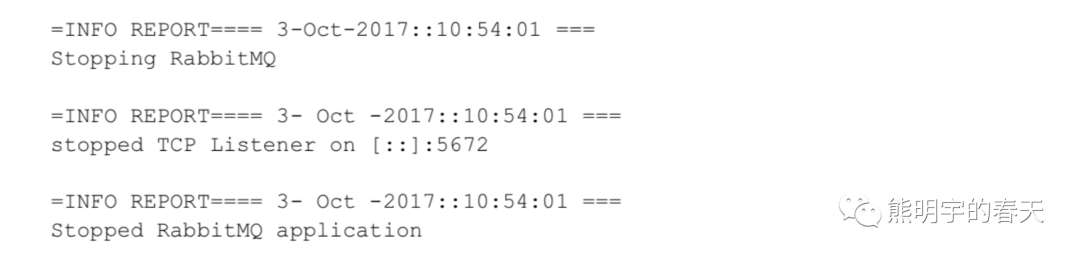

在RabbitMQ中,查看服务日志的方式不止有人工查看:RABBITMQ_NODE-sasl.log.下面介绍如何通过程序化的方式来查看相应的日志,RabbitMQ默认会创建一些交换器,其中 amq.rabbitmq.log就是用来收集RabbitMQ日志,集群中所有的服务日志都会往这个交换器中.这个交换器的类型为topic,可以收集如前面所说的debug、info、warning和error这4个级别的日志.
如图,我们创建4个日志队列:queue.debug、queue.info、queue.warning和queue.error,分别采用debug、info、warning和error这4个路由键来绑定amq.rabbitmq.log.如果要使用一个队列来收集所有级别的日志,可以使用“#”这个路由键:
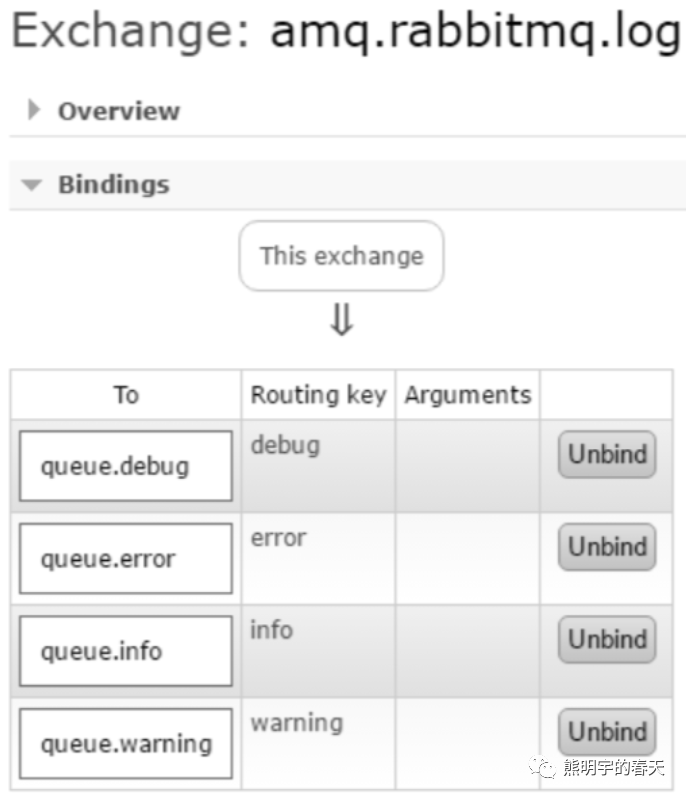
如果RabbitMQ集群中只有一个节点,那么这个4个日志队列可以收到此节点的所有日志.对于集群中有多个节点的情况同样适用,值得注意的是:对于每个级别的日志队列来说,比如queue.info,它会收到每个节点的info级别的日志,不过这些日志是交错的,不能区分是哪个具体节点的日志.代码如下:

03 RabbitMQ之单点故障
04 RabbitMQ之其它迁移方案总结
前面讲过一个方案:RabbitMQ之机房迁移,现在在讲一个方案:
a、步骤1
在新机房创建与老机房等实例(包括内存和磁盘节点)RabbitMQ集群集群,创建方式,见:RabbitMQ之安装部署
b、步骤2
1、迁移之前先停止在老集群中创建元数据(包括exchange、queue、vhost、user等);
2、通过老集群的RabbitMQ管理平台,导出元数据metadata.json, 在新集群中导入metadata.json,这样新集群就有了元数据;
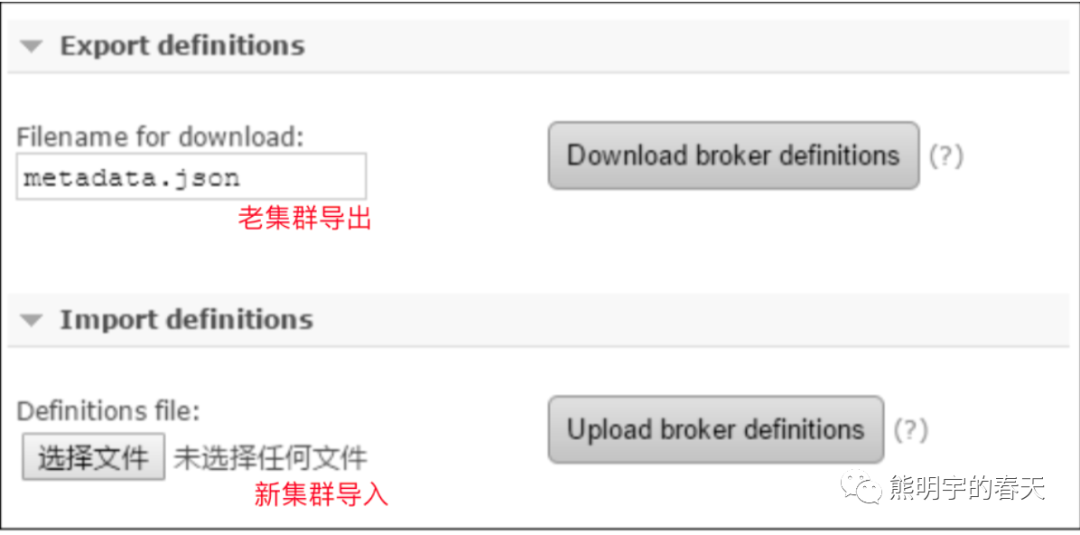
注意:
这个地方会有问题,因为导入只能在一个节点导入,导入后元数据的主节点(master)都是这个节点,当前节点会有压力,(可以通过解析metadata.json的通过http api写入,这样就随机放到一个节点)
3、这个地方可以改进:可以考虑程序读取json文件,调用HTTP API随机写入某个节点,如下图:
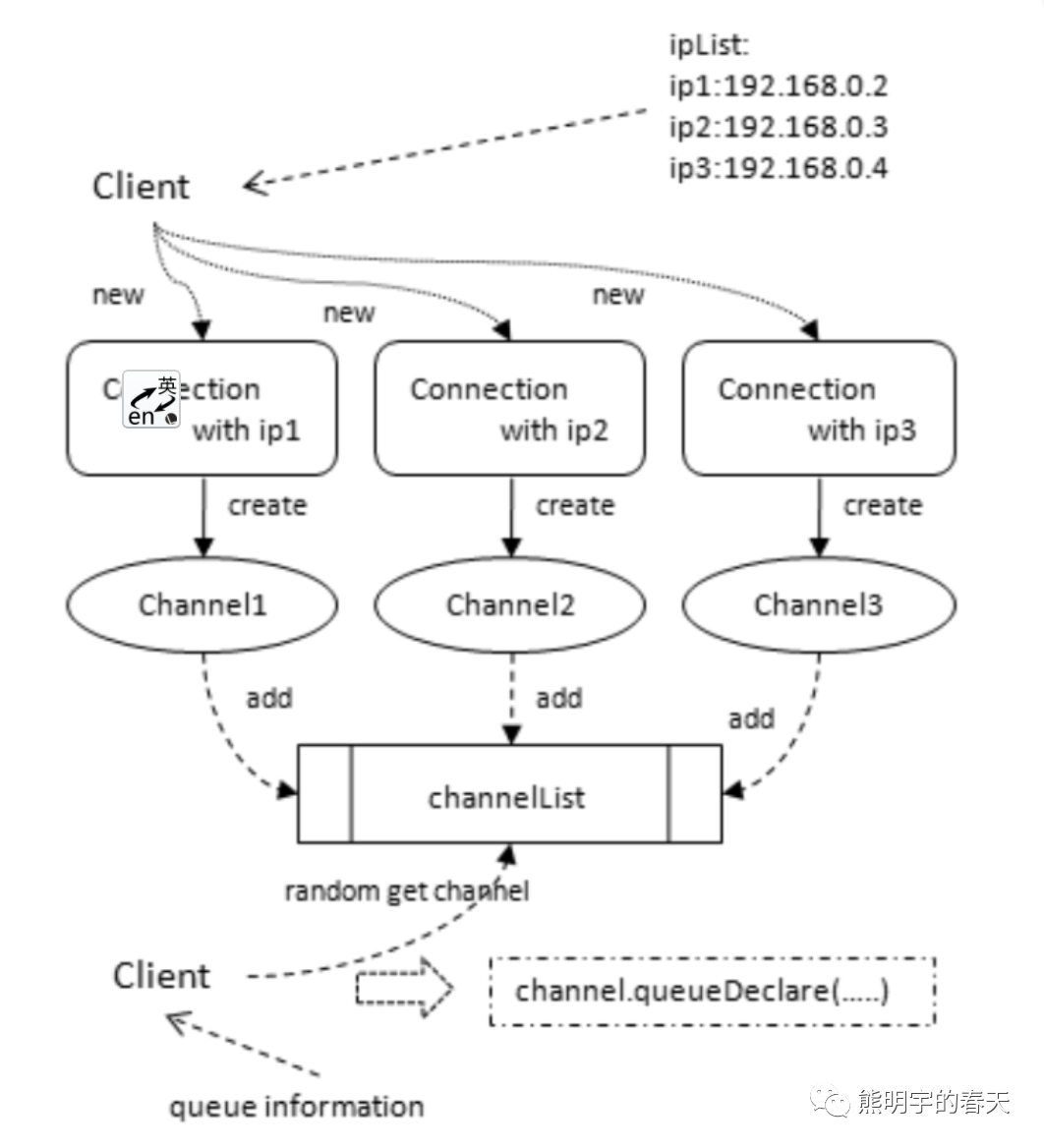
c、步骤3
数据迁移的主要原理 是先从原集群中将数据消费出来,然后存入一个缓存区中,另一个线程读取缓存区中的消息再发布到新的集群中,如此完成了数据迁移的动作,我们称之为:RabbitMQ ForwardMaker
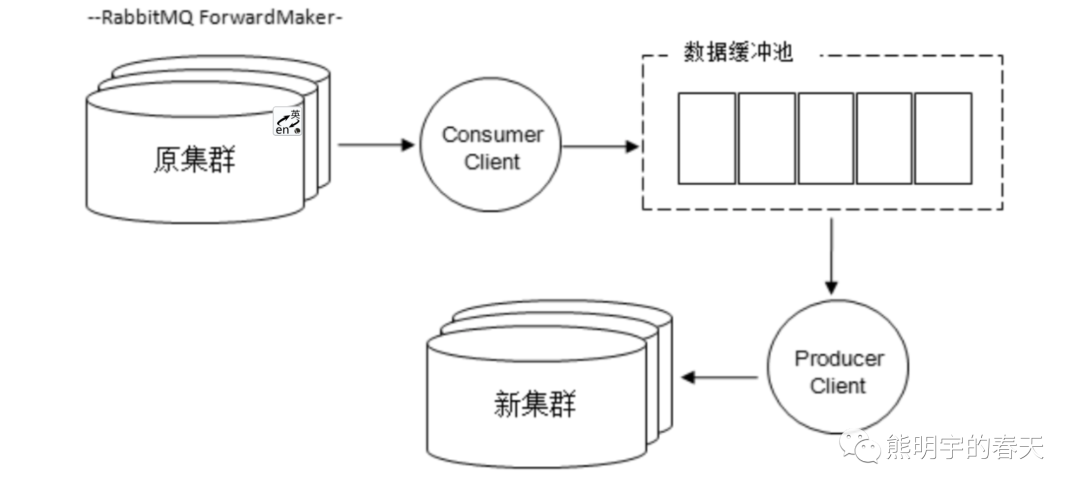
1、可以自己去写脚本实现两个集群的数据同步;
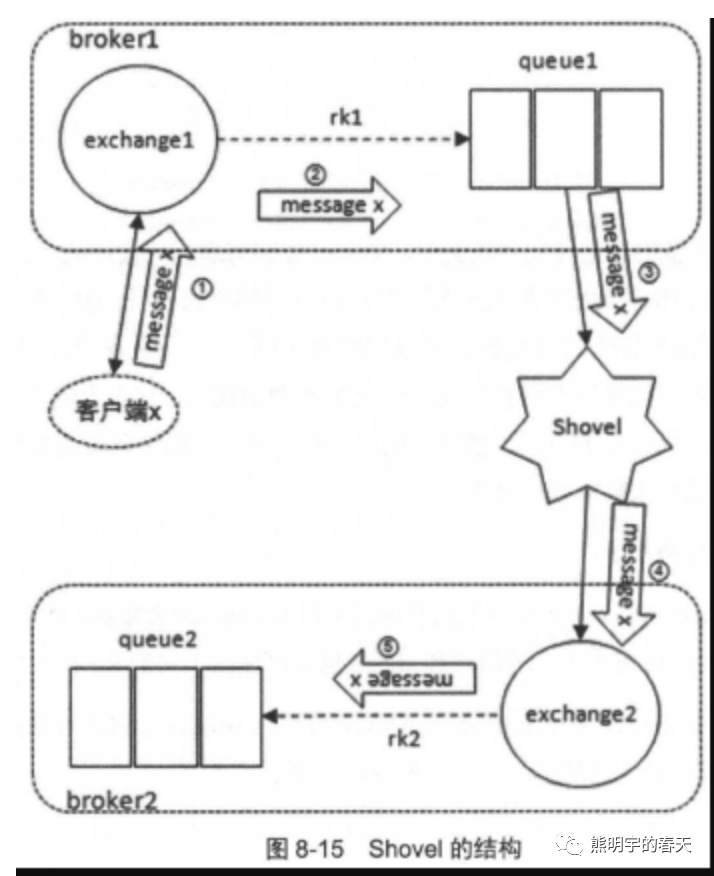
2、使用RabbitMQ的插件Shovel实现来给你个集群的数据同步,把在使用的队列在新老集群之间配置同步,shovel原理 : https://www.jianshu.com/p/280c2e2e1c53;
d、步骤4
切换负载均衡服务
注意:
此种方式只是一种选择,如果一个集群有很多的exchanges和queues,这种方式要创建很多shovel显然不合适.
05 RabbitMQ的元数据
Queue metadata—Queue names and their properties (are they durable or auto-delete?)
Exchange metadata—The exchange’s name, the type of exchange it is, and what the properties are (durable and so on)
Binding metadata—A simple table showing how to route messages to queues
Vhost metadata—Namespacing and security attributes for the queues, exchanges,and bindings within a vhost
Rabbit node location
单节点的情况,RabbitMQ会在内存中维护一份元数据信息,并把标记为Durable的Queue和Exchange(以及相关bingding)持久化到磁盘.
引入了集群之后,会新增几种元数据信息:集群节点位置信息(Erlang节点名包含这部分信息),以及节点之间的关系信息.集群环境中你还会面临一个选择是存储元数据到RAM Only还是Disk 磁盘,在单节点情况由于没有额外的数据冗余存在所以这个选择默认是持久化到磁盘.
