排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
QWQ 32B真的那么神奇吗?
QWQ 32B真的那么神奇吗?
白鳝的洞穴
2025-03-10
785
最近阿里发布了QWQ 32B,网上一片赞誉之词,吊打满血deepseek-r1是看到最多的说法。真的如此吗?DBAIOPS社区的同学听说这个消息之后也十分兴奋,搞离线模型部署应用的人,谁不希望有一个体量小、输出速度快、推理性能好的开源模型呢?在试用了两天后我们谈谈对QWQ的感受。
QwQ 是 Qwen系列模型中的推理模型,QwQ-32B 是中型推理模型,能够实现与最先进的推理模型(如 DeepSeek-R1、o1-mini)相似的性能。试用了一些场景后,这个模型让人感觉是惊喜与惊吓并存。首先模型的输出速度之快令人咂舌,这是让人最为感到惊喜的地方,比起deepseek-r1:32b来,输出速度可以说是飞速。其次是推理的能力也十分强,正常的时候输出结果靠谱指数也还算挺高的。
问题来了,QwQ 32B真的以32B的中型模型的规模达到了671B这样的大型模型的推理性能了吗?这一点按照常识来想,是不太可能的。事实上这些年号称吊打ChatGPT的中小型模型事实上都是吃牛逼,而参数较少的模型在复杂推理和长文本处理上有天然的弱点,因此测试长文本对话才能真正看出QwQ的弱点。
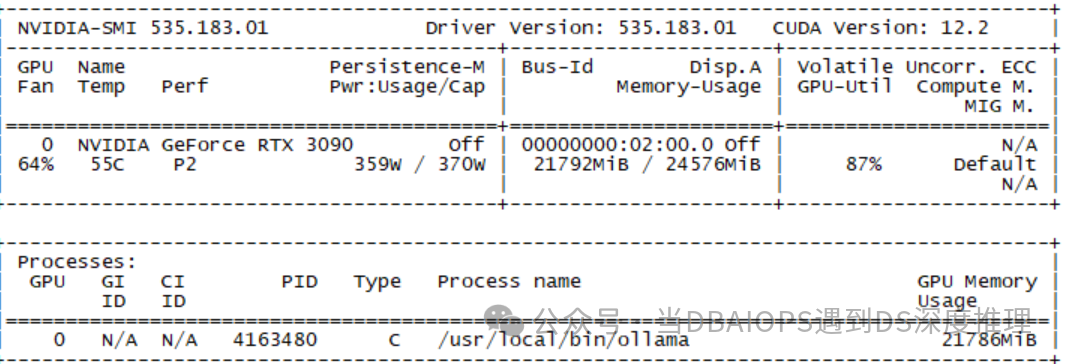
在内存使用上,其实QwQ并没有体现出很多测试者发现的比DS-R1 32b 更节约显存的特点,类似的参数规模(都是32.8B),同样4bit量化,其大小差不太多。
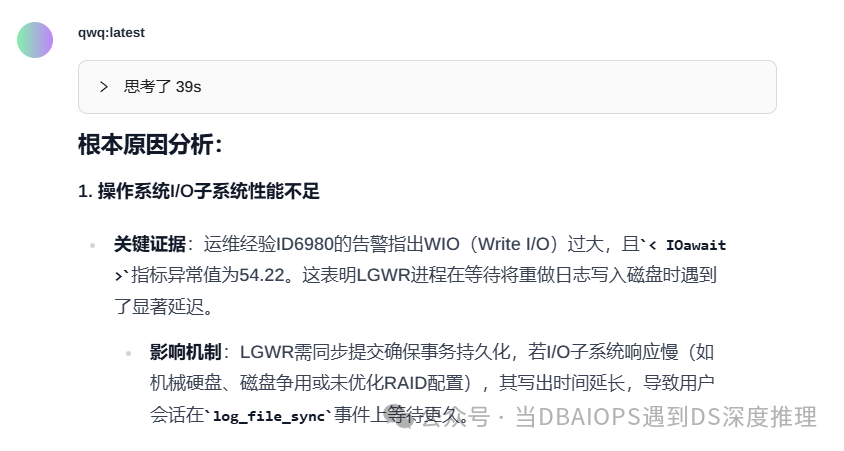
在速度上,大家在测试的时候会发现QwQ输出速度特别快,所以觉得QwQ速度比deepseek-r1:32b要好,其实这是一个错觉。实际上当时的输出都是思考过程,QwQ在思考时输出的内容很多,通过观察思考过程,我们发现QwQ是不断通过自我对话来完善输出的,其思考模式与DeepSeek-r1不同,经过多轮对话,QwQ不断完善输出,最后获得一个最满意的版本来输出。一个问题QwQ思考了39秒,同样的问题我们测试了多次,思考时间差不多,都在三十多秒范围内。
完全相同的问题,在相同的硬件上,Deepseek-r1:32b花了16秒的思考时间,得到的推理结果与QwQ差不多,从这个比较来看,QwQ只是输出速度更快,输出的推理过程更加丰富,真正的思考速度并不比DeepSeek-r1:32b更快。
下面我们来测试一个语义逻辑上不是太严谨,存在可能误解的场景,在满血DeepSeek-r1上,表现出了很好的性能,输出结果十分完美。不过在DeepSeek-r1:32b上表现不如人意,虽然思考时间差不多也是不到20秒,但是输出结果中出现了明显的误判。
在周五的测试中,这个问题是陷入死循环的,输出了几十分钟,还没有完成思考。周六早上重新下载了最新版后,死循环的问题解决了。不过思考了51秒之后,QwQ给出了与DS 32B类似的错误结论。同样的问题,DS 32B的思考时间是15秒。
最终的测试结果与我们的预期基本类似。参数较小的中型模型与大参数的671B模型相比,在长文本复杂问题的推理上,还是存在较大的差距的,最大的问题是远距离语料之间的推理性能较差,如果两个语料之间隔得比较远,那么在后面得推理中很可能无法识别前面的内容,因此需要在推理中的时候将逻辑关系比较相近的数据放在一起,否则容易出现幻觉。
刚开始测试QwQ的时候,应该也是大量赞誉网文发出的时候,QwQ在我们的场景中就像一个任性的弱智一样,不但胡思乱想,而且不听劝,无论我们如何通过提示想消除它的幻觉,它都不听劝。当时我们甚至已经决定完全放弃QwQ了,不过更新了最新版本后,我们发现QwQ还是可用的,其性能与DeepSeek-r1:32B相当,思考时间大约是3倍左右的时间。QwQ还在不断进步,我想今后会越来越好的。做离线部署LLM应用的人,又多了一个不错的武器。不过也仅此而已了,说吊打满血DS的人,大多数是看了跑分结果,没有自己去做认真测试就下结论的。跑分这玩意,也就看看吧,不同的任务场景下,对模型的要求也是不同的,就像某些数据库说吊打Oracle一样,也许某个场景确实如此,但是换个场景,可能就完全不同了。
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨