




本文对由麻省理工学院的Samuel Madden和芝加哥大学的Michael Franklin合著的《Databases Unbound:Querying All of the World’s Bytes with AI》进行解读。文章探讨了如何利用人工智能技术,特别是深度学习和生成式AI模型,来扩展数据库系统的功能,使其能够处理和查询所有类型的数据,包括非结构化数据。全文共约4626字,预计阅读时间约为15至25分钟。
关系型数据库的局限性:
关系型数据库模型在过去五十年中被广泛应用于处理结构化数据,并在分析、事务处理、图形处理和流处理等领域取得了成功。
然而,大多数世界上的数据是非结构化的,例如文本、图像和视频等。这些非结构化数据超出了传统关系型数据库系统的处理范围。
数据爆炸与多样性:
随着互联网、数字照片、视频和高速传感设备的普及,非结构化数据的数量和种类呈爆炸式增长。
这些数据的多样性和复杂性使得传统的关系型数据库系统难以有效处理和查询。
AI技术的进步:
深度学习和生成式人工智能模型的崛起为处理非结构化数据提供了新的可能性。
这些模型能够从各种类型的文档中提取语义信息,从而有望将数据库的查询功能扩展到所有类型的数据。
扩展数据库的查询能力:
传统的关系型数据库系统在处理非结构化数据时面临挑战,无法充分利用这些数据中的潜在价值。
通过引入AI技术,特别是深度学习和生成式AI模型,可以增强数据库系统的查询能力,使其能够处理和分析所有类型的数据。
提高数据利用效率:
非结构化数据中蕴含着大量有价值的信息,但由于缺乏有效的查询工具,这些信息往往被忽视或未被充分利用。
通过将AI技术与数据库系统相结合,可以提高数据的利用效率,帮助企业和研究人员从大量数据中提取有价值的洞察。
应对现实需求:
现代应用对数据处理的需求越来越高,特别是在需要处理大规模非结构化数据的场景中,如法律文件检索、医疗研究、金融分析等。
开发能够高效处理和查询非结构化数据的系统,将为这些应用提供强大的支持。
构建“无界数据库”不仅需要结合AI技术,还需要在系统架构、优化策略和用户界面等方面进行创新。
这为研究人员提供了丰富的研究课题和机遇,推动数据库技术向更广泛和复杂的应用场景发展。
论文的主要贡献在于提出了一种全新的数据库系统架构——“无界数据库”,该架构利用AI技术(如深度学习和生成式模型)来处理和查询包括非结构化数据(如文本、图像和视频)在内的所有类型的数据。论文强调了声明式编程范式在关系型数据库中的成功,并主张将其扩展到AI数据系统,使用户能够通过简洁的查询描述需求,而系统负责优化执行策略。为了验证这一概念,论文展示了多个实例系统(如VAAS和Palimpzest),这些系统在处理非结构化数据方面展现了巨大潜力。同时,论文深入探讨了构建“无界数据库”所面临的技术挑战(如可扩展性、正确性和可靠性),并提出了通过提示调优、模型选择和代码生成等优化技术来应对这些挑战的可能路径。最终,论文不仅为未来研究提供了明确的方向,还推动了数据库技术向更广泛和复杂应用场景的演进,旨在实现高效查询和处理全球范围内的所有数据。
无界数据库的架构由多个组件构成,如图一,这些组件协同工作,为用户提供统一的查询接口,支持对各种数据类型的访问和处理:
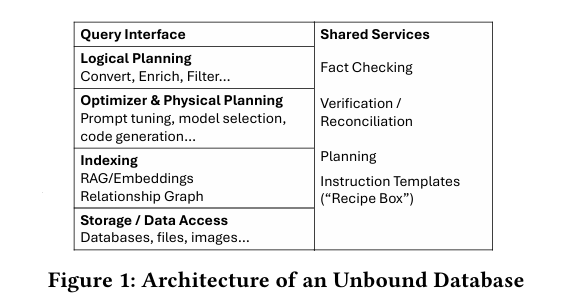
图1 无界数据库的架构
声明式接口层
用户通过这一层编写程序,描述他们的查询需求。
支持高级查询语言(类似于SQL),用户可以指定从数据中提取的内容,而无需关心底层模型、提示或阈值的具体实现细节。
这种声明式接口使得用户能够以简洁的方式表达复杂的任务,降低了使用门槛。
逻辑规划层
系统在此层构建查询的高级操作图或“计划”。
包括两个核心操作:
转换(Convert) :将数据从一种结构转换为另一种结构(例如,从文档到关系型表,或从图像到JSON记录)。
丰富(Enrich) :扩展现有数据集,通过添加列、行或从外部数据源获取额外信息。
用户只需描述高层次的任务,系统会自动选择最佳的实现策略。
优化器
负责选择最优的执行计划,包括模型选择、提示生成、批处理和并行化等。
需要在成本、时间和质量之间进行权衡,以满足用户的需求。
优化器是无界数据库的核心组件之一,其性能直接影响系统的效率和用户体验。
物理规划层
将逻辑操作转化为具体的执行策略。
包括选择合适的AI模型、生成提示、批处理和并行化等操作。
通过代码生成技术,替换昂贵的AI模型调用,从而提高执行效率。
索引层
提供基于嵌入(embeddings)和向量数据库的高效检索能力。
支持根据关键词或标准检索文档、图像等非结构化数据。
结合属性搜索和向量搜索,进一步提升检索性能。
存储层
负责访问和管理各种数据类型,包括文档、图像、视频和传统数据库。
处理数据的更新和插入,并确保数据的一致性和可靠性。
存储层需要适应不同类型数据的特性,提供高效的存储和访问机制。
共享服务
提供事实检查、验证和多数投票等功能,以提高系统的可靠性和准确性。
例如,通过多数投票机制减少AI模型的“幻觉”现象(即生成不准确或虚假的答案)。
VAAS是一个用于声明式视频查询的系统,旨在高效处理大规模视频数据集,并支持用户以高级声明式语言表达复杂的查询需求。其核心目标是通过优化技术减少昂贵的AI模型调用,同时最大化查询结果的质量和速度。
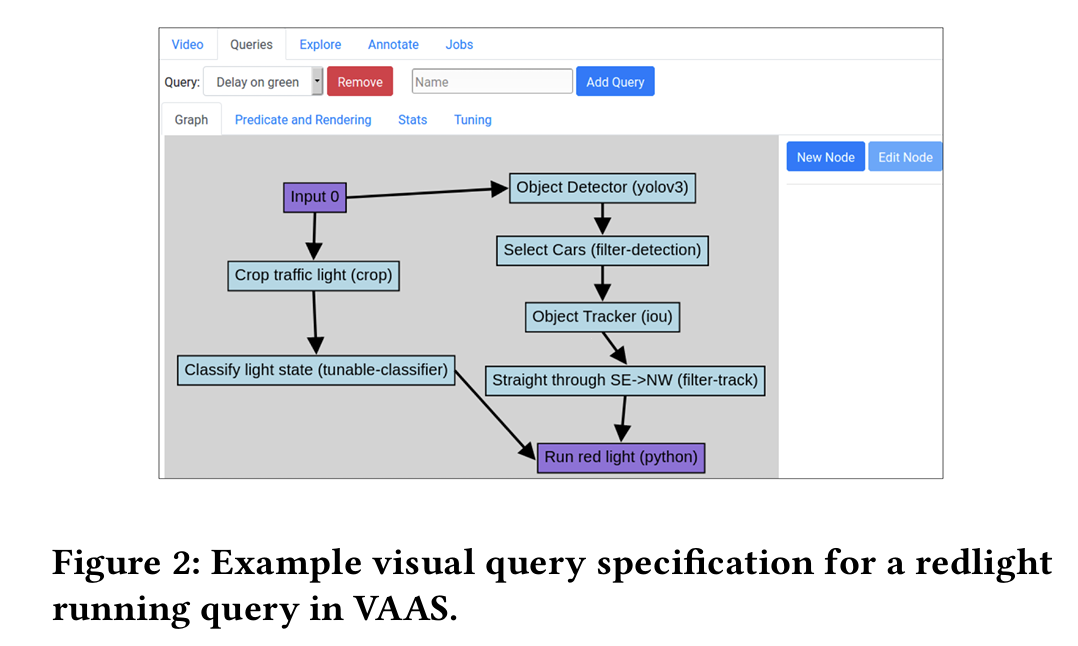
图2 VAAS示例
VAAS的设计适用于以下典型场景:
自动驾驶:从大量驾驶视频中识别具有挑战性的场景(如雪地中的自行车或逆行车辆),用于算法评估。
交通监控:分析城市交叉路口的摄像头数据,检测危险行为(如闯红灯),以指导交通管理措施。
生物学研究:从野生动物相机图像中识别特定动物或行为(如进食或交配)。
VAAS系统特点如下:
声明式查询接口
用户通过图形化界面指定查询逻辑,而不是直接定义执行计划。例如,用户可以描述“找到包含红灯和车辆穿过特定区域的视频片段”。
这种声明式接口允许系统自动优化查询执行策略,避免不必要的计算。
VAAS使用了帧率自适应调整,部分检测过滤,视图聚焦,谓词重排序等优化技术
帧率自适应调整:根据查询需求动态降低视频帧率,从而减少处理量。
部分检测过滤:提前排除不可能满足查询条件的部分检测结果(如轨迹片段)。
视图聚焦:仅关注视频帧中与查询相关的区域,进一步节省计算资源。
谓词重排序:根据查询逻辑重新排列操作顺序,优先执行成本低但过滤效果显著的操作。例如,在“红灯+车辆轨迹”查询中,先检测红灯再查找车辆轨迹。
存储与索引:
由于直接处理原始视频数据效率低下,VAAS使用预检测技术提取视频中的对象和轨迹,并将其嵌入到向量数据库中,以便快速检索。
这种索引机制显著提高了查询性能,尤其是在涉及大规模视频数据时。
实际效果
VAAS的优化技术使得系统能够在经济性和用户体验之间取得平衡。例如,在处理数百个摄像头一个月的视频数据时,通过智能筛选和优化,大幅降低了计算成本和时间开销,同时保持了高质量的结果。
Palimpzest是一个面向文本和图像查询的声明式编程工具,旨在让工程师能够像操作关系型数据库一样高效处理非结构化数据。它支持多种工作负载,包括大规模信息提取、数据集成、医学和科学文献挖掘、图像理解以及多模态分析。

图3 Palimpzest示例
Palimpzest的设计适用于以下任务:
法律发现:从电子邮件中提取与欺诈行为相关的内容。
医学研究:从 PDF文档中提取癌症相关数据并生成汇总表。
跨模态分析:结合文本和图像数据进行联合查询。
Palimpzest的系统特点如下:
声明式编程接口
用户编写简洁的声明式代码,描述高层次的任务逻辑,而无需关心底层实现细节。
例如,在法律发现任务中,用户可以通过几行代码定义如何过滤和提取与欺诈投资相关的电子邮件。
核心操作:转换(Convert)
Palimpzest的核心操作是 转换(Convert) ,即将一种用户定义的模式(schema)转换为另一种模式。例如:
将PDF文档转换为结构化表格。
将图像中的文本提取为JSON记录。
转换操作由多种方法实现,通常基于基础模型(foundation models),使系统能够灵活处理不同类型的非结构化数据。
优化框架:Palimpzest内置了一个强大的优化框架,能够自动选择最佳的执行计划。具体优化包括:
提示调优(Prompt Tuning):优化提示内容,选择合适的提示策略(如零样本学习、少样本学习或链式思维)。
模型选择(Model Selection):根据任务需求选择最合适的模型(如轻量级模型用于简单任务,GPT-4用于复杂任务)。
代码生成(Code Synthesis):将部分任务替换为生成的代码,以避免昂贵的 LLM调用。
组合优化:合并多个任务以提高 GPU缓存利用率,同时避免超出LLM的上下文限制。
运行时选择:
用户可以在运行时指定优化目标(如成本、时间或质量),系统会根据这些偏好生成最优的执行计划。
例如,在医学数据提取任务中,Palimpzest自动生成的计划比使用GPT-4的方案成本低80%,同时实现了更高的准确性和更快的运行时间。
实际效果
Palimpzest的优化能力在多个任务中得到了验证。例如,在从多个PDF中提取癌症数据并生成汇总表的任务中,系统生成了多个候选计划,并选择了成本最低且质量最高的方案。实验结果表明,Palimpzest的计划不仅成本更低,而且在准确性和运行时间上均优于单纯依赖GPT-4的方法。
无界数据库(Unbounded Database)作为一种新型的数据库系统,旨在通过结合AI技术和声明式编程范式处理所有类型的数据(包括非结构化数据如文本、图像和视频)。然而,构建这样的系统既面临重大挑战,也带来了许多研究和应用的机遇。一方面,无界数据库需要满足可扩展性,正确性和可靠性:
可扩展性要求系统能够高效处理大规模数据集,同时保持性能;
正确性则需要解决AI模型容易产生“幻觉”现象的问题,确保查询结果的可靠性;
可靠性涉及在数据更新和插入时维护一致性和正确性,这在AI驱动的系统中尤为复杂。
然而,这些挑战也带来了巨大的机遇:通过开发新的抽象、原则和最佳实践,可以支持多样化应用场景(如法律发现、医学研究和跨模态数据分析);通过智能化优化技术(如提示调优、模型选择和代码生成),可以显著降低成本和延迟,同时提高结果质量;此外,适应性查询处理和事实检查机制的研究将进一步提升系统的准确性和用户体验。总之,无界数据库不仅拓展了传统数据库的能力边界,还为未来数据系统的发展提供了广阔的研究方向和技术潜力:
开发新的抽象、原则和最佳实践
需要为AI数据系统开发新的抽象和原则,以支持系统的构建和优化。例如,设计高阶逻辑操作符(如转换和丰富)来简化复杂任务的实现。
研究如何将现有的关系型数据库技术(如SQL优化器)扩展到AI数据系统中。
多目标优化
在成本、质量和性能之间进行权衡,研究如何让用户表达优化目标。例如,用户可以选择优先考虑低成本、高质量或快速响应,系统需要根据这些偏好动态调整优化策略。
示例:Palimpzest系统允许用户选择成本优化、时间优化或质量优化策略,从而生成满足需求的执行计划。
探索新的优化技术
提示调优(Prompt Tuning):优化提示内容,选择合适的提示策略(如零样本学习、少样本学习或链式思维)。
模型选择(Model Selection):根据任务需求选择最合适的模型(如轻量级模型用于简单任务,高性能模型用于复杂任务)。
代码生成(Code Generation):用生成的代码替换昂贵的AI模型调用,以提高效率。
缓存(Caching):通过缓存结果减少重复计算,特别是对于昂贵的模型调用。
适应性查询处理
由于AI模型的质量难以预测,需要在实际数据上进行试验和优化。研究如何设计自适应的查询处理机制,以应对不同数据和任务的不确定性。
事实检查与一致性
研究如何通过事实检查、验证和多数投票等机制提高系统的可靠性,避免“幻觉”现象。例如,设计技术让模型互相验证答案,或通过多次重复处理输入以估计不一致性。
跨模态数据处理
研究如何统一处理文本、图像、视频等多种模态的数据,提供一致的查询接口和优化策略。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





