




个人知识库,简单来说就是通过AI技术将零散的文档、笔记、数据等结构化存储,并实现智能检索、推理和应用的系统。
个人知识库的核心优势在于:
1. 隐私与掌控感:数据完全本地化,避免云端泄露风险;
2. 效率革命:通过RAG(检索增强生成)技术,AI能结合知识库内容生成针对性回答,而非依赖通用模型“空想”;
3. 长期价值:知识库可随个人成长持续迭代,成为职业发展的“数字资产”。
但需警惕:当前许多教程将知识库包装成“万能神器”,却避谈实际使用中信息整理耗时、模型推理偏差等问题,本质是蹭AI的流量红利。
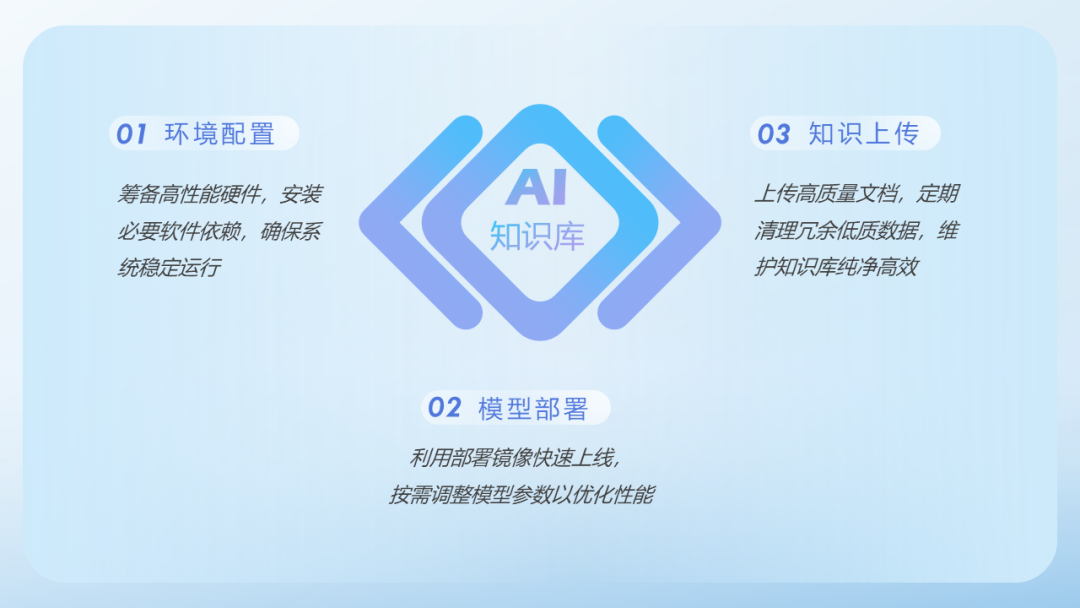
1. 准备阶段:硬件与软件的博弈
硬件门槛:至少16GB内存+支持虚拟化的CPU(否则连Docker都跑不动);
软件依赖:Docker、Python环境、ollama模型加载工具是基础。
注:部分教程宣称“零基础10分钟搞定”,实则忽略环境冲突、镜像下载失败等高频问题。
2. 部署实战:Docker不是万能药
按教程部署DeepSeek和RAGFlow镜像后,需重点修改.env文件中的本地路径和模型参数,否则可能出现“知识库加载但AI不认”的尴尬;
首次运行建议从PDF、TXT等简单格式上传测试,避免直接导入复杂数据导致解析失败。
3. 知识管理:AI不是保姆
上传文档后需人工添加标签、分段标识符,否则AI可能将《公司财报》和《育儿指南》混为一谈;
定期清理低质量数据(如重复文件、过期信息),否则知识库会变成“数字垃圾场”。
1. 优势:定向推理能力亮眼
在限定领域(如法律条款、医学文献)中,AI结合知识库的回答准确率显著高于通用模型;
支持多轮追问,例如从“合同违约条款”延伸到“相似案例判决”,适合深度研究场景。
2. 槽点:想省心?不存在的!
幻觉问题:AI可能捏造知识库中不存在的内容(尤其在数据量不足时);
维护成本:知识库需定期更新,否则遇到“2025年数据训练2023年政策”的漏洞;
复杂场景乏力:涉及跨领域推理或多模态数据(如图表+文本)时,效果大打折扣。
批判视角:许多教程用“保姆级”“手把手”吸引点击,却对上述问题轻描淡写,本质是牺牲深度换流量。

1. 持续优化策略
数据层面:优先上传高信噪比内容(如权威论文、结构化报表),减少碎片化文本;
模型层面:通过调整RAGFlow的“Top-K”参数(控制检索范围)和温度值(降低回答随机性)提升精度。
2. 应用场景推荐
学术研究:构建文献库,快速定位实验方法、数据结论;
自媒体创作:将爆款文案、用户反馈归档,辅助生成选题灵感;
垂直行业:律师、医生等职业可定制专属知识库,但需警惕AI不可替代专业判断。
3. 理性看待技术边界
个人知识库不是“一劳永逸”的解决方案,而是需要持续投入的“数字基建”。与其盲目跟风搭建,不如先问自己:我的数据是否足够优质?我的需求是否真需AI介入?
结语
DeepSeek+RAGFlow的组合为个人知识管理提供了新可能,但技术的真实价值不在于“搭得快”,而在于“用得好”。拒绝流量焦虑,回归需求本质,才是对抗信息爆炸时代的终极答案。

多云环境灾备 | 云迁移 | 数据管理
及解决方案提供商
