




前文我们对RAID的概念和等级进行了简要的介绍,但是在RAID领域有很多专业术语,我们在前文并没有过多的介绍,本节我们将更加深入的介绍一下相关的内容。通过这些内容的介绍,大家对RAID会有更加深入的了解,并利于开发高性能的存储系统。
RAID等级(RAID level)
前文我们已经介绍过各种等级的RAID,RAID等级的概念最早出现在论文《A Case for Redundant Arrays of Inexpensive Disks (RAID)》中。RAID等级可以简单的理解为RAID的类型,不同类型的RAID的数据在各个物理硬盘的布局不同,对数据的保护能力有差异。比如RAID1将同样的数据放置到2块硬盘,可以容忍1块硬盘故障(多路RAID1可以是3块或者4块硬盘放相同的数据,这样可以容忍2块或者3块硬盘同时故障);RAID5除了数据外,还有一个校验数据,最多容许出现一个硬盘故障;RAID6有两个校验,最多容许同时出现两个硬盘故障。
成员盘和逻辑盘
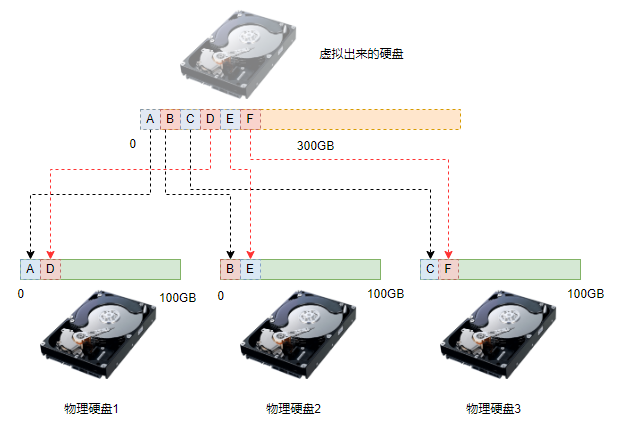
我们知道RAID的核心功能就是将多个物理硬盘构建为一个虚拟的硬盘。构成同一个RAID的多个物理硬盘称为成员盘,因为他是这个特定RAID的一个成员。虚拟出来的,可以被用户使用的硬盘称为逻辑盘或者虚拟盘,如下图是成员盘与逻辑盘的关系。

热备盘(Hot Disk)
热备盘是一个独立的物理硬盘,热备盘并不属于任何一个RAID实例,也就是不会存储任何数据和校验数据。如下图所示是热备盘与RAID成员盘的关系。热备盘就像候补队员一样,当RAID中的某个成员盘故障的情况下,RAID软件系统会自动将故障的硬盘替换为热备盘,并触发后续数据恢复流程。

盘序(Disk Order)
RAID是由多个物理硬盘构成,这些物理硬盘称为成员盘。在构建一个RAID的时候,成员盘之间的逻辑顺序称为盘序。对于条带化和具有校验功能的RAID,盘序是非常重要的,盘序的错乱会导致RAID数据不可用。如下图所示是3个物理硬盘构成的RAID0,虚拟盘的数据A、B、C … …是依照一定的规则放在3个物理盘上的。如果数据写入后物理盘的顺序发送变化,则会导致主机端读到错误的数据,从而导致数据错乱。
条带化(Striping)与条带(Stripe)
所谓条带化是将数据分割为固定大小的数据块,并将数据块分散到不同硬盘的技术。如下图所示的RAID0,逻辑盘中的数据被划分为6KB的数据库,以前6KB数据为例,其被分割为3块(分别为数据块0,1和2),每块的大小是2KB。3个数据块分别被定位到3个不同的物理盘上,其他数据块也依次类推。这样,当应用向逻辑盘写入6KB的数据时,实际上是由3个硬盘同时处理,这种方式自然可以提升性能。
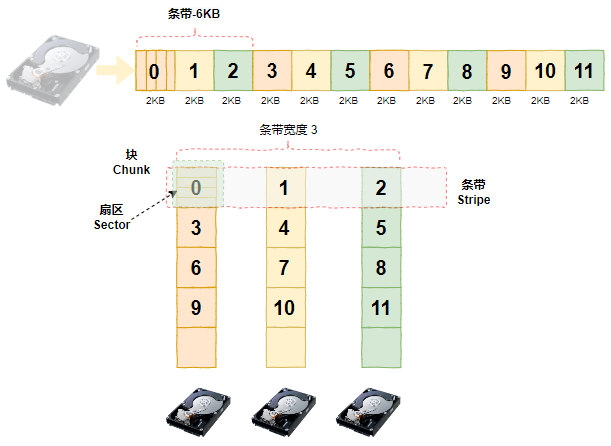
结合上图,上述被分割成的数据块称为条带(Stripe),对于一个创建好的RAID,条带的大小是固定的(本例为6KB)。对于一个条带,每个成员盘上的数据大小是相等的,条带在每个成员盘上的数据称为块(Chunk),也有的书上称为条带段(Stripe Segment)或者条带深度(Strip Size)。关于条带几个相关的概念简单解释如下:
条带大小(Stripe Size):条带大小通常是指被RAID软件划分的数据单元的大小,单位是字节。
条带宽度(Stripe Width):条带宽度是单个条带跨越的硬盘的数量,在传统RAID中实际就是组成RAID的数据硬盘的数量,在RAID2.0之后的RAID中则大概率不相同。通过上述定义可以看出条带宽度数据盘的数量有关,校验盘不计算在内。比如4块盘组成的RAID5,条带宽度应该是3,而不是4。
条带深度(Stripe Depth):条带深度是一个条带的数据在某一个硬盘上的大小。条带深度也称为条带块大小(Chunk Size或者Strip Size),具体而言,条带深度可以通过下面公式表示。
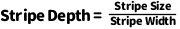
大家需要注意一下上文描述中两个英文拼写的差异,Stripe Size表示条带大小、而Strip Size则表示条带深度。以3块盘的RAID0为例,如果条带大小是6KB,那么条带深度是2KB。同理,对于4块盘的RAID5,由于其有1块校验盘,实际数据盘的数量为3,所以在条带大小为6KB的情况下,条带深度也是2KB。
注意: 对于“1块校验盘”的描述并不准确,这里只是为了让大家容易理解条带的相关概念。严格来说对于一个条带来说是包含1个校验盘和3个数据盘。但是,对于特定的硬盘来说,其中存储的数据既包含数据,又包含校验数据。大家可能有点迷惑,我们在后面介绍RAID5的时候会详细介绍这部分的内容。 |
上述参数对用户的业务性能影响非常明显,条带大小的设置必须考虑用户业务IO的模式。如果用户是视频类业务,比如视频播放或者监控视频等,由于以大IO为主,因此条带适合设置大一些。如果用户是数据库OLTP业务,条带大小适合设置小一些。原因在于,数据库OLTP业务以小IO为主,如果条带设置的太大,IO将落在一块硬盘上,无法发挥条带化的作用。
初始化
除了RAID0之外,其它RAID在创建成功后都需要有初始化的动作。最简单的RAID1,由于成员盘上的数据需要是一致的,因此RAID创建成功后,RAID服务会实现两个(或者多个)成员盘之间的数据同步,保证其数据的一致性。其它如RAID5和RAID6等具有校验功能的RAID等级也是如此,创建成功后RAID服务需要计算校验数据,然后写入校验数据的位置。
可以看出,如果计算校验数据并写入到相应的位置将会非常耗时。所以有的厂商在RAID初始化的时候并不真的进行数据同步,而是通过某种方式记录同步的进度。比如通过位图的方式记录哪些数据以及完成了同步,如果主机读取的数据是同步完的数据则可以直接读取,否则需要等待同步后才能返回给主机端。
降级模式(Degraded Mode)
对于有校验数据的RAID,如果出现硬盘故障,那么RAID通常仍然能过正常运行,此时称为RAID的降级模式。此时虽然RAID仍然能过运行,但是处于失去了冗余保护能力,、保护能力降低或者性能下降。
以RAID5为例,如果其中1块硬盘出现了故障,那么此时处于降级模式。此时上层依然可以读写数据,只是性能会有影响。这是因为,如果上层读取的正好是故障硬盘位置的数据则无法直接读取,必须通过其他硬盘数据计算得到,显然要比直接读取数据要慢一些。对于RAID6,丢失一块硬盘的情况下虽然还可以容忍另外一块硬盘故障,但是读性能也是会受影响的。
重构(Rebuild)
前文提到过热备盘的概念,知道当RAID中有一个硬盘故障的情况下,热备盘会替换掉故障硬盘,并自动完成数据恢复的过程。上述数据恢复的过程,也就是故障硬盘数据重新构建的过程,简称重构。RAID成员盘的数据重构是根据正常成员盘的数据计算得到故障硬盘数据的过程。在重构的过程中,RAID算法会逐条带的重新构建故障硬盘的数据,并写入新的成员盘中,这个新的成员盘可以是热备盘,或者是管理员替换的新硬盘。
预拷贝(Pre-Copy)
我们知道硬盘都有一定的寿命,当一个RAID使用若干年后,大多数成员盘都接近其寿命极限了。为了避免出现数据丢失的情况,我们通常需要提前将所有接近寿命极限的硬盘都换掉。如果我们使用的是RAID5,由于其只能容易一个硬盘故障,因此我们只能挨个(一次只能替换一个)替换硬盘。当完成被替换硬盘的数据的重构后,我们才能替换另外一个成员盘。由于RAID5数据重构是涉及计算过程的,这个过程同时需要从其它所有正常的成员盘中读取数据,显然,重构会对存储系统的性能产生一定的影响。
因为需要集中时间批量替换成员盘,显然基于RAID重构的方式替换成员盘并不合适。目前业界普遍采用一种称为预拷贝的方式替换成员盘。所谓预拷贝是指,在进行成员盘替换的时候,源成员盘并不拔掉,而是与新的成员盘并存,在后台直接将成员盘的数据拷贝到新的成员盘。当完成数据拷贝后,将源成员盘从RAID中剔除,并用新的硬盘作为正式的成员盘。
除了上述硬盘寿命到期的场景,在一些高级的存储系统中还有硬盘故障预测的能力。当存储系统预测到硬盘故障的时候,可以在该硬盘真正故障之前提前将数据拷贝到热备盘中,然后计划内的实现热备盘与成员盘的转换。由于整个过程中不会触发重构的流程,因此不存在降级的问题,用户的业务也不会有明显的影响。
在线扩容
RAID的在线扩容是指增加RAID成员盘的过程,比如一个RAID5原来是4块硬盘,在容量紧张的情况下我们可以通过添加新硬盘的方式增加存储容量。以Linux内核支持的RAID为例,我们可以通过下面命令进行扩容。
mdadm --add dev/md0 /dev/sdx mdadm --grow /dev/md0 --raid-devices=5 |
由于增加了新的硬盘,数据布局将发生变化,因此涉及原始数据布局到新数据布局转换的过程,这些都是有RAID软件在后台完成的。
等级转换
RAID的等级转换时指RAID从一个等级转换为另外一个等级,比如从RAID1转换为RAID5。由于用户业务属性的变化,可能需要不同的保护等级,通过等级转换可以在不中断业务的情况下转换为期望的RAID等级。
比如用户有个非常重要的业务,原来使用的是RAID1,后来由于硬盘容量不够,需要考虑扩容。此时可以将该RAID转换为RAID5或者RAID6,这样机进行了扩容,又可以通过校验保证数据的可靠性。以Linux内核支持的RAID为例,我们可以通过如下命令完成从RAID1到RAID5的转换。
mdadm --add /dev/md0 /dev/sdx mdadm --grow /dev/md0 --level=5 --raid-devices=3 |
至此,我们介绍了RAID中最常见的概念及与数据访问相关的几个概念。后续章节我们将深入到每种RAID类型(等级),介绍更多原理和代码实现细节。
