




在大数据时代,高效的数据分析引擎成为企业和研究者不可或缺的工具。传统的分析查询引擎通常由紧密集成的系统组成,例如Vertica、Spark 和 DuckDB。这类系统通过优化文件格式、内存布局和处理引擎之间的接口来实现最佳性能。然而,构建此类系统成本高昂。随着需求的变化,特别是在公共云环境中对资源的弹性扩展要求,和AI/机器学习数据管道的需求,开发一套全新的分析查询引擎显得不再必要。因此,如何通过模块化设计降低成本,同时满足不同需求,成为当前技术发展的关键。本次为大家带来数据库领域顶级会议SIGMOD 2024的文章《Apache Arrow DataFusion: a Fast, Embeddable, Modular Analytic Query Engine》。

一. 背景
传统的高性能分析查询引擎通常采用紧耦合设计,通过优化文件格式、内存布局和处理引擎之间的接口实现极致性能。然而,这种方式开发成本高昂,而且需要大量资金和工程投入。这种模式在早期大数据时代是可行的,因为当时数据分析需求相对单一,主要集中在数据仓库和批处理场景,企业和研究机构有能力投入巨资打造专用系统。但随着技术环境的变化,这种模式的局限性逐渐显现。具体而言:
1. 云计算要求系统支持动态资源分配,而传统引擎的封闭架构难以适应。
2. AI/机器学习需要快速集成多样化数据源并支持实时处理,紧耦合系统扩展性不足。
3. 开发成本成为中小团队的瓶颈,从零开始构建复杂引擎已不再可行。
基于已有研究和工业实践,可以知道子系统之间的最佳边界,例如文件格式、目录、语言前端和执行引擎。这意味着,与其每次都重新开发一套完整的查询引擎,不如基于已有的标准化组件,组装出满足特定需求的高效系统。基于这些原因,本文提出了DataFusion,它是一个使用ApachdeArrow作为内存模型,用Rust编写的快速、可嵌入、可扩展的查询引擎。在构建DataFusion的过程中,面临着一系列核心挑战:
·挑战 1:在众多开放标准中,如何筛选并利用合适的标准,实现高效的数据表示和处理,确保数据在各个组件之间能够快速、准确地流转和处理。
·挑战 2:怎样设计出一种模块化架构,既能够支持灵活的扩展,满足不同场景下的多样化需求,又能在扩展的同时保持高性能,不因为架构的复杂性而导致性能下降。
·挑战 3:在复杂多变的真实场景中,如何通过有效的方法验证 DataFusion 的性能与顶级引擎相当,让用户能够放心地使用。
二. 方法介绍
2.1 总体框架
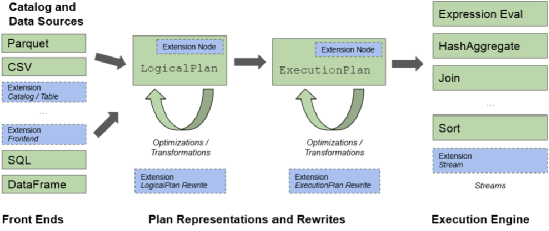
图1 DataFusion整体框架
DataFusion的设计围绕模块化和高性能展开,包括以下关键组件:
数据源与目录:
DataFusion 支持多种常见的数据格式,如 Parquet、CSV 等,这使得它能够处理来自不同数据源的数据。同时,通过 TableProvider API,它还具备集成自定义数据源的能力,为用户提供了极大的灵活性。无论是从本地文件系统读取数据,还是从远程数据源获取数据,DataFusion 都能轻松应对。
查询前端:
为了满足不同用户的使用习惯和需求,DataFusion 提供了 SQL、DataFrame 和 LogicalPlanBuilder 三种接口。SQL 接口方便熟悉 SQL 语言的用户进行数据查询操作;DataFrame 接口则借鉴了 pandas 的风格,对于习惯使用 Python 进行数据处理的用户来说,使用起来更加得心应手;而 LogicalPlanBuilder 接口则为那些有更高级需求,比如自定义查询语言的开发人员,提供了直接构建查询计划的途径。
执行引擎:
DataFusion 的执行引擎采用了基于拉取的流式模型,这种模型使得数据能够以一种高效的方式在各个操作符之间流动。同时,它还利用多核并行调度,充分发挥多核处理器的性能优势,通过Volcano风格的RepartitionExec和Tokio线程池实现了高效的任务调度,确保系统能够快速处理大规模的数据。
优化器:
DataFusion的优化器实现了投影下推、谓词下推等经典的优化技术。通过这些优化技术,能够减少数据处理过程中的冗余计算,提高查询执行的效率,使得 DataFusion 在处理复杂查询时也能保持良好的性能。
系统设计师可以通过扩展 API(图1中蓝色部分)来实现领域特定功能,而 DataFusion本身则提供了标准的OLAP技术(图1中绿色部分),这避免了开发人员重复开发一些通用的功能,大大提高了开发效率。
2.2 基础生态系统
·2.2.1 Apache Arrow
Apache Arrow 是一个数据存储和传输的标准,它通过使用一种内存中高效的数据布局(列式存储)来优化数据处理。这个标准统一了数据表示的细节,比如如何处理空值(NULL)、字节和字符数据的长度、列表和嵌套结构等,这样不同系统之间可以更容易地交换数据。
·2.2.2 Apache Parquet
· 2.2.3 Rust
2.3执行
流式执行:在DataFusion中,数据以RecordBatch(默认包含8192行数据)为单位进行增量流动,这一过程如图 2 所示。这种流式执行方式允许数据在处理过程中逐步输出结果,并且支持在内存不足时将数据溢写到磁盘,保证了系统在处理大规模数据时的稳定性和可靠性。

图2 流式执行
多核并行:DataFusion 通过Volcano风格的 RepartitionExec 操作符和 Tokio 线程池,实现了多核并行计算。这种设计使得系统能够充分利用多核处理器的计算资源,将任务分配到不同的核心上并行执行,从而提高整体的处理速度。在执行过程中,各个核心之间通过高效的调度机制协同工作,确保任务能够快速、准确地完成。
优化技术:DataFusion集成了一系列优化技术,涵盖查询重写、排序、分组、连接和窗口函数等多个方面。在查询重写阶段,通过投影下推、谓词下推等操作,减少中间结果的数据量,提高查询效率;在排序操作中,采用了优化的算法,提升排序速度;分组和连接操作也经过了精心优化,能够快速处理大量数据;对于窗口函数,通过合理的算法设计,减少不必要的排序操作,提高计算效率。这些优化技术相互配合,确保了DataFusion在性能上具备强大的竞争力。
2.4 优化
DataFusion的优化技术并非全新发明,而是对学术研究和工业实践中广为人知的策略进行了开源、高质量的实现。DataFusion的贡献在于提供可扩展的开源实现,避免新系统重复开发这些成本高昂的功能。
1.查询重写:DataFusion 针对 LogicalPlans 和 ExecutionPlans 执行多种查询重写操作。在逻辑计划方面,它通过投影下推、filter下推、limit下推,减少中间结果数据量和计算量;表达式简化、公共子表达式消除等操作,实现对查询逻辑的优化。执行计划层面,它通过消除不必要排序,最大化并行执行,选择最佳连接算法来提升执行效率。
2.排序优化:排序采用优化算法,借助RowFormat,实现高效元素比较和内存访问。DataFusion支持内存不足时磁盘溢写,对 LIMIT 操作专门优化,快速获取 “Top K” 结果。
3.分组和聚合优化:运用两阶段并行分区哈希分组,实现向量化执行,内存不足时可溢写磁盘。针对不同分组键类型特殊处理,提升分组和聚合性能。
4.连接优化:处理多表连接时,自动识别相等谓词,依据统计信息调整连接顺序,下推谓词,选择合适连接算法,支持多种连接类型,持续改进连接性能。
5.窗口函数优化:窗口函数复用已有排序顺序,必要时才排序。采用增量计算,数据满足窗口条件时立即计算输出。
6.其他优化:利用 Normalized Sort Keys RowFormat 优化行操作,充分利用数据排序顺序优化相关操作。支持投影、LIMIT 和谓词下推,靠近数据源进行操作,减少数据处理量,采用延迟物化技术,避免不必要列解码,提升查询性能。
三.实验
3.1实验设置
为了全面评估 DataFusion(版本 32.0.0)的性能,本文选择了与 DuckDB(版本 0.9.1)进行对比实验。实验采用了以下几种具有代表性的基准测试:
·ClickBench:使用一个大小为 14GB 的 Parquet 数据集,该数据集包含 100 个文件,主要用于模拟网页分析场景,考验系统在处理大规模、复杂数据时的性能表现。
·TPC-H:选择了 Scale Factor 为 10 的数据集,大小约为 2.5GB,用于模拟经典的数据仓库场景,测试系统在复杂查询和多表连接情况下的性能。
·H2O-G:采用一个 488MB 的 CSV 文件,专注于数据科学分组任务,评估系统在数据科学领域常见操作中的性能。
3.2 性能分析
1.单核效率:
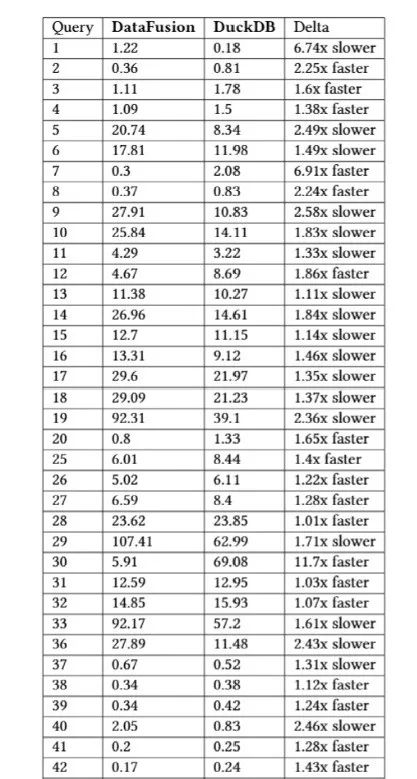
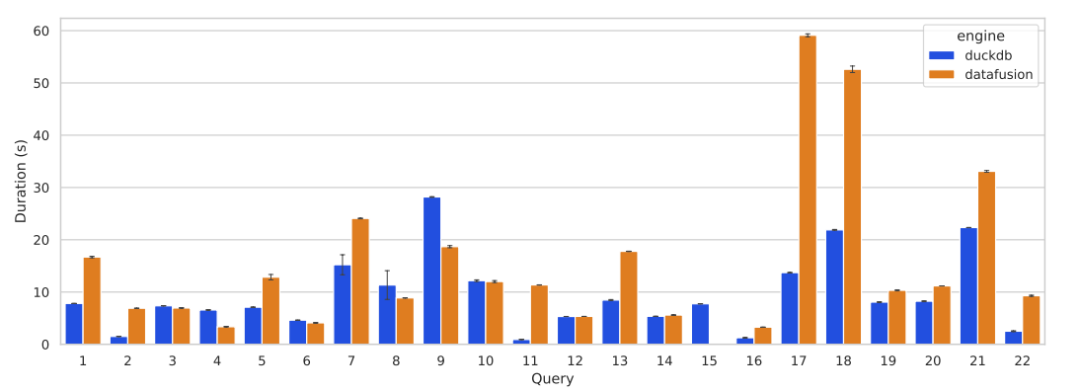
图4 TPC-H测试结果
H2O-G测试(见图 5)结果表明,DataFusion 在多数查询中略胜一筹,这主要得益于 Apache Arrow 高效的 CSV 解析效率。
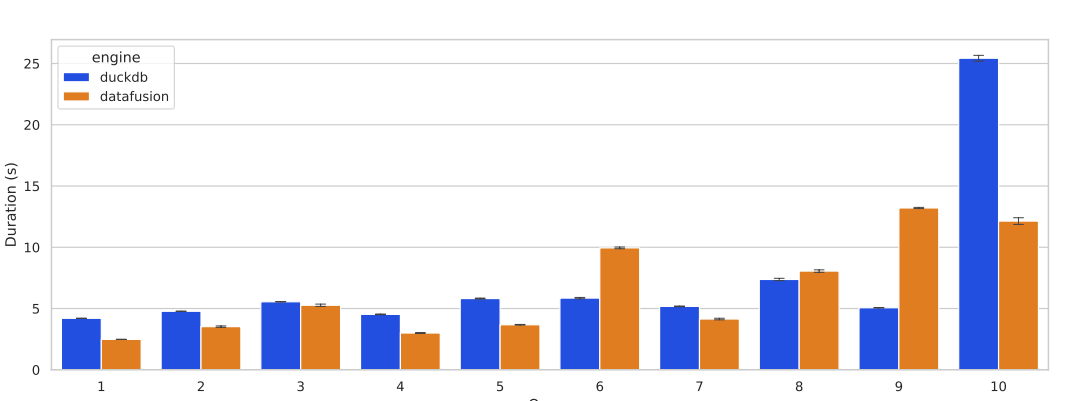
图5 H2O-G测试结果
2. 多核扩展性:
在多核扩展性测试(见图 6)中,当核心数在 1 - 32 核范围内时,DataFusion 和 DuckDB都呈现出近线性加速的良好表现,说明它们都能够较好地利用多核资源。当核心数增加到 64 - 192 核时,对于像 Q28 这样包含中等分组操作的查询,随着核心数的增加,性能持续优化;而对于如 Q11 这类具有高协调开销的查询,两个系统的查询时间都明显增加,即性能变慢。即在高核心数情况下,系统的性能受到任务协调开销等多种因素的影响。本文解释性能差距更多源于工程投入而非架构限制,社区已在改进薄弱环节(如连接顺序)。
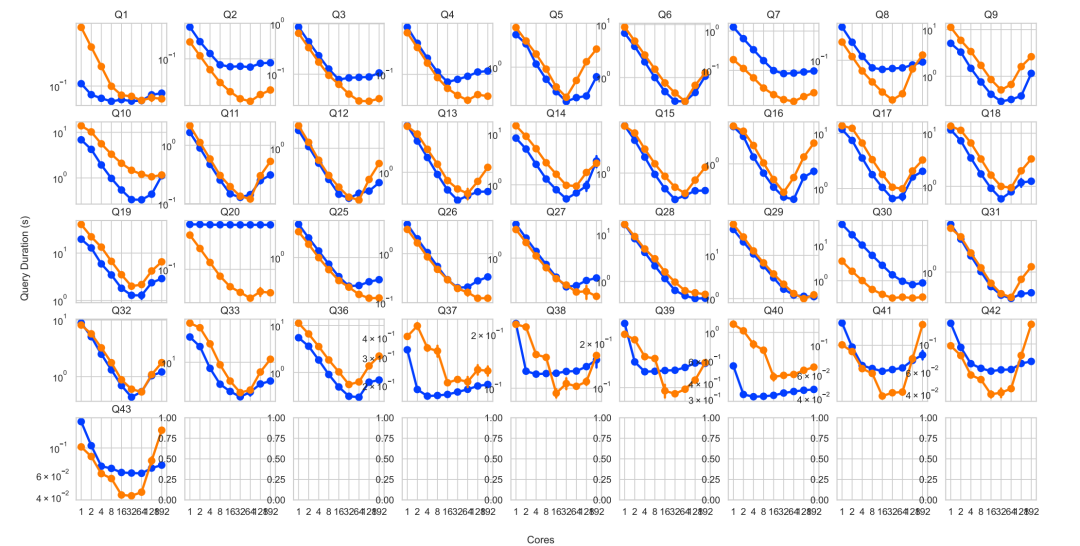
图6 多核扩展性测试结果
四.总结
DataFusion 作为一种快速、可嵌入、模块化的分析查询引擎,巧妙地利用Apache Arrow、Parquet 和 Rust 等基础技术,借助开放标准和丰富的扩展接口,成功解决了传统紧耦合分析系统开发成本高昂、扩展性不足的难题。其模块化的架构设计,不仅满足了公共云环境下弹性扩展的需求,也为 AI 与机器学习场景提供了强大的实时数据处理能力。实验通过 ClickBench、TPC-H 和 H2O-G 三个基准测试证明了 DataFusion 在多数典型查询场景中具备与业内一流水平相当甚至更优的性能表现。DataFusion 在 InfluxDB 3.0、Synnada 等实际项目中的成功应用也展示了其在生产环境中的可用性与稳定性。DataFusion 的出现不仅有效降低了构建高性能分析引擎的门槛,更推动了数据库领域从传统紧耦合架构向模块化开放架构的演进。随着社区生态的持续发展和优化,未来 DataFusion 将有望进一步提升分析查询的性能边界,成为推动大数据分析技术创新和产业变革的重要引擎。
 |

图文|袁如意
校稿|李佳俊
编辑|李佳俊
审核|李瑞远
审核|杨广超
