




在城市信息学、大气科学和地理学等与地理相关的领域中,收集了大规模时空(ST)序列,用于监测和理解重要的时空现象。然而,由于时空序列的规模庞大、固有的动态性以及时空性质,可视化这些序列存在挑战。本次为大家带来TKDE 2023的文章《Visualizing Large-Scale Spatial Time Series with GeoChron》。

一. 背景
传统上,ST 序列首先以时间可视化方式呈现,例如折线图。然后,这些可视化结果要么根据其地理位置绘制在地图上,要么显示在与地图协调的独立视图中,从而将其关联回地理背景。这些方法被视为直接描绘策略,对于大规模ST序列而言并不高效。
另一种策略是通过总结ST序列来进行转换,例如连续记录的变化,或从中提取模式。然后,将这些模式而非大量原始ST序列进行可视化。然而,ST序列的趋势叙述和动态性——ST序列数据的基本特征——在转换过程中被破坏了。
每个ST序列通常在空间和时间上与其他序列相关,特别是在相邻时间段内,空间上接近的序列表现出相似趋势。文章将这种现象定义为演化模式,使得大规模ST 序列可以以模式感知和叙事保留的方式进行可视化。这种可视化允许用户同时查看多个相关序列,而不必逐个扫描,并且保持时间上的连续性。技术Storyline是一种用于构建和管理非线性、互动式叙事内容的技术。Storyline技术可以被应用于可视化ST序列,但需要解决两个挑战。
1. 演化模式挖掘:一个模式中的任意两个ST序列应满足以下条件:1)在模式的时间段内,具有相关的时间趋势;2)具有接近的地理位置,因为空间上接近的ST序列之间通常存在相关性。
2. 时空信息呈现:传统的Storyline无法展示细粒度的时间趋势和空间背景,且与时间(如折线图)和空间(如地图)可视化的整合存在困难。
基于此,作者提出了GeoChron,一种用于大规模ST序列的交互式可视化工具。
二.概述
2.1 术语
位置是在地理空间中的传感器。每个位置都有地理坐标。一个时间段是一个数据结构p,具有开始时间戳p.te和结束时间戳p.ts。即p=(ts,te)。时空序列(ST序列)是在位置集合中收集的时间序列。ST序列包含在位置li收集的按时间顺序排列的记录。这些记录在规则时间戳下收集的。作者使用Vi(p)表示属于时间段p的ST序列Vi,即。演化模式的特征是:1)一组地理位置上接近的ST序列并且 2)一个时间段p,使得Vi(p)中的所有序列都具有相关的趋势。
2.2 基于 Storyline 的解决方案
Storyline因其对动态关系的叙事表现而受到青睐。接下来介绍其核心概念。
1. 实体:实体指的是故事中的角色,并表示为从左到右发展的曲线(图 1A1)。
2. 关系:如果两个实体在同一场景中相互作用,则它们间存在关系(图 1C1),反之亦然。
3. 时间框架:时间框架指任何两个实体之间的关系发生变化的时间点(图 1B1)。
4. 会话:会话定义为多个实体在两个相邻时间框架之间的互动(图 1D1)。
作者开发了GeoChron,这是一种基于Storyline的方法,旨在解决研究问题,具体通过以下两个阶段进行。
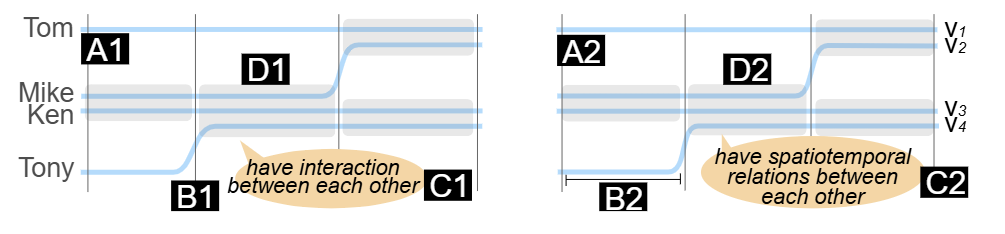
图1 类比说明
将ST序列转化为会话。作者首先将实体与ST序列进行类比(图1A2)。通过这种方式,由于某个事件导致实体在时间切片中相互之间具有时空关系的会话(图1C2)正是一个演化模式(图1D2)。利用这一类比,Storyline提供了一种叙事保留的方式来可视化演化模式。
三.演化模式挖掘
本节介绍了GeoChron中用于从大规模ST序列中检测演化模式的挖掘框架。该框架应当具备以下两个功能:1)捕捉稳定且可靠的相关关系,2)融合地理背景和时间特征。
步骤 1:切分时间跨度
第一步是将连续的时间维度转换为离散的时间切片。检测每个切片的会话后,可以应用Storyline。文章的框架将时间跨度均匀地切分为T个切片,表示为{s1, . . . , sT},每个切片的大小相等。每个时间切片s=(ts,te)都有一个时间段结构。较小的切片大小不足以捕捉显著特征,而较大的切片大小可能错过动态变化。之后,执行下面的步骤2-4来处理每个时间切片。
步骤 2:确定时间切片中的相关性
皮尔逊相关系数是最常用的相关性度量。在时间切片si中,两个ST序列Va和Vb之间的相关性可以通过计算它们在该时间切片内子部分的皮尔逊相关系数 r(Va(si),Vb(si))来直接得出。如果r(Va(si),Vb(si))大于给定的阈值thr,则认为Va和Vb是相关的。
为了捕捉显著模式并生成可读的可视化,文章通过基于滑动窗口的包裹窗口策略平滑ST序列间的相关关系。通过三切片大小的窗口沿时间滑动,生成包裹窗口{w2, . . . , w_{n-1}},每个窗口包裹一个聚焦切片和两个相邻切片。在图3B中,时间窗口 wi包裹了si,si-1和 si+1。如果ra,b,i=r(Va(wi),Vb(wi))>thr,则认为Va和Vb在si中相关。若 ra,b,i相较于ra,b,i−1和ra,b,i+1突然变化,则通过替换为ra,b,i−1或ra,b,i+1来平滑。通过这种方式,文章在考虑更多观测结果的同时,保持时间切片粒度上的分析。文章避免使用大小自适应的滑动窗口,因为过多的观测值可能会削弱某个时间切片下的相关性,从而导致不准确的结果。
步骤 3:在时间切片中建模关系网络
对于每个时间切片,作者基于相关关系构建关系网络(图2C)。引入一个阈值thd来过滤掉那些距离较远的ST序列对。经过过滤后,剩余的ST序列对自然地构成一个关系网络,其中连接的节点在空间上接近并在时间切片中相关。
步骤 4:检测演化模式
如果 ST 序列在时间切片中相关,并且在地理空间上彼此接近,那么这些ST序列属于同一个会话。这样的ST序列在关系网络中正好形成一个社区。因此,文章应用 Louvain算法。每个ST序列只能属于一个社区。在同一模式中,一个ST序列与大多数其他ST序列具有相关关系。框架为每个时间切片检测到多个社区(例如,图 2D)。这些社区然后被视为Storyline中的会话(例如,图 2E)。检测模块的时间复杂度为O(|L|2 T),其中|L|2来源于Louvain算法。
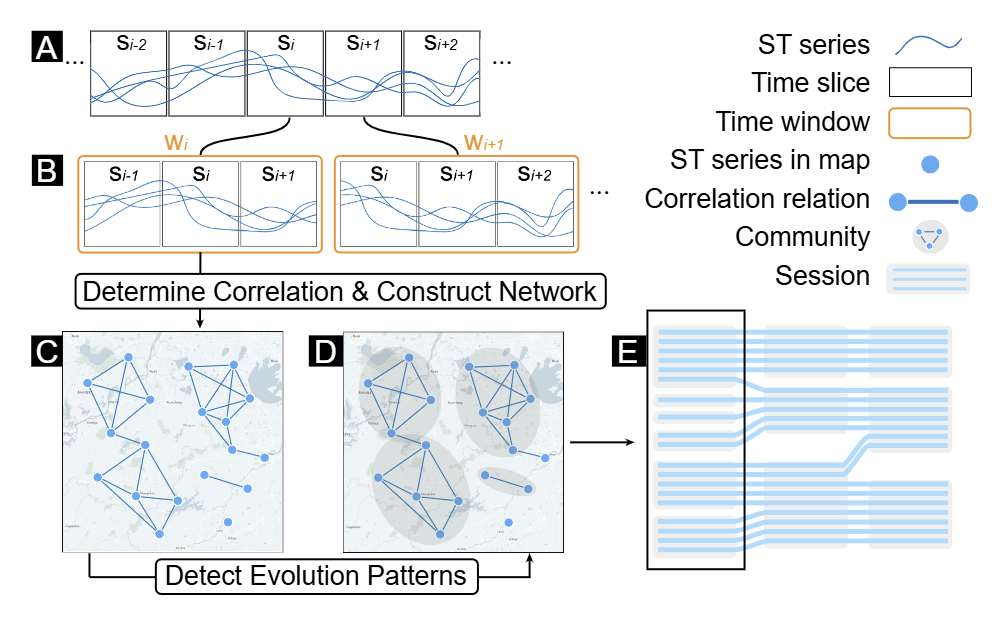
图2 演化模式挖掘框架
四.原始Storyline布局方法
在现有的Storyline 布局方法中,作者选择了StoryFlow。StoryFlow的时间复杂度为。下面简要介绍StoryFlow步骤。
步骤 1:排序
StoryFlow首先将会话转化为分层图。每个时间切片视为一个层,每个会话视为一个节点。如果两个会话有至少一个实体是共同的,则节点之间存在一条边。StoryFlow将跨时间切片排序会话的问题表述为寻找图的分层布局,其中边的交叉最少。
步骤 2:对齐
此步骤旨在通过对齐相邻时间切片中的会话和实体来最小化曲线的摆动。StoryFlow将在si和si+1中对齐会话的问题表述为加权最长公共子序列(LCS)问题。如果两个会话在实体上有足够的重合,StoryFlow 会倾向于对齐它们,同时尽量最大化所有对齐会话中公共实体的总和。
步骤 3:定位
同一会话中的两个相邻实体应当有一定的间距din,而两个相邻会话之间应当有更大的间距dout(图 4E)。且dout> din。会话和实体应当在上述约束下紧凑地定位。
首先,s0中的实体按从上到下的顺序依次定位。其次,si可以作为si+1的位置参考(向前扫动)。si中的一个实体可以确定其在si+1中对齐实体的位置以及包含该对齐实体的会话。如果si+1中剩余的实体无法在上述约束下插入,则扩展 si+1中对齐实体之间的空间,以便所有实体都能被定位(图 3A)。此时,si、si-1、...、s0中的实体需要重新定位(向后扫动),并以si+1为参考进行调整。
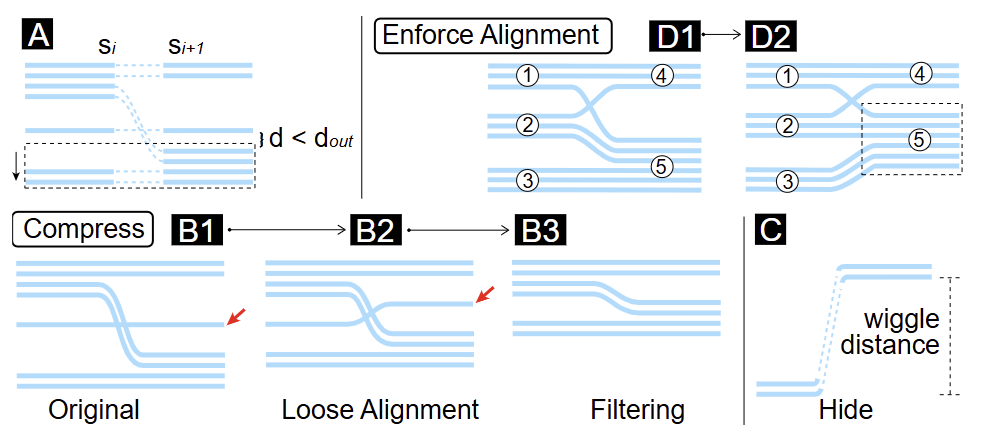
图3 布局优化
五.可视化设计
5.1 设计目标
文章总结以下五个设计目标:
G1 使会话分析成为可能、 G2 支持有效的跟踪、G3 可视化时间趋势、G4 关联空间和时间信息、G5 提供多层次分析工作流
接下来从两个方面介绍设计:即布局优化和两层可视化。
5.2 布局优化
松散对齐
将大量会话输入Storyline布局算法可能会产生难以阅读的可视化表示。为了解决这个问题,文章丢弃那些共同实体数少于阈值thc的会话对。例如,与图3B1相比,图3B2更加节省空间,因为红色箭头指向的曲线并没有被对齐。
会话过滤
过多的会话可能导致信息超载。因此,文章过滤掉那些 1) 大小小于阈值 ths的会话,以及 2) 其包含的实体没有进入在相邻两个切片中大小 ≥ ths的会话中。通过这种方式,图 3B2 被转换为图 3B3。
曲线隐藏
曲线的摆动无法完全避免。令人难以忍受的是曲线因摆动而导致的上下移动。为此,如果摆动距离大于阈值thw,隐藏曲线的主要垂直部分(图 3C)。
这些方法可以提高可读性,但也会带来不同程度的信息丢失。GeoChron允许用户通过滑块指定参数。
强制会话对齐
之前的方法允许用户拉直他们感兴趣的实体的曲线。文章将这一思想从实体层面扩展到会话层面 (G1)。在用户点击一个会话后,对于每个时间切片,首先找到与所点击会话有最大交集的会话,即目标会话。然后,步骤 2:对齐将重新执行:
对于相邻的两个时间切片si和si+1,首先,如果满足松散对齐约束,文章将分别对齐si和si+1中的两个目标会话。然后si和si+1中的会话根据目标会话分为上部和下部。文章使用基于 LCS 的方法分别对上部和下部的会话进行对齐。
5.3 两级可视化
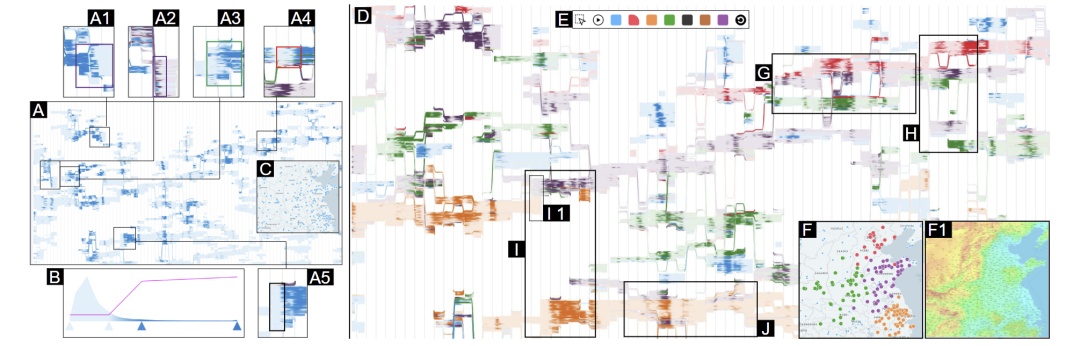
图4 跟踪整体演化模式
跟踪整体演化模式
在第一层,作者修改了Storyline中的视觉编码,并为Storyline添加了新的编码,以从宏观角度展示演化模式(图 4A和D)。用户可以获取ST序列的概览,并定位感兴趣的时间段或模式。
可视化时间序列趋势 (G3):文章通过曲线的阴影编码趋势。例如,选择浅蓝色和深蓝色并生成线性插值,用户通过图4B界面指定shade(v)函数,将时间序列值映射到0到1的阴影值。根据阴影值生成介于浅蓝和深蓝之间的颜色,为每条曲线生成渐变色笔触,反映时间序列的趋势。
将空间背景与 Storyline 连接 (G4):文章实现了一个地理地图,将每个ST序列根据其地理位置绘制为点(图4C),并将这些点与Storyline中的曲线关联。重点放在演化模式(会话)上,而非单个ST序列。图4D展示了为不同会话着色后的Storyline,图4F显示了已着色实体的地理分布。着色过程应由用户自行发现视觉模式,难以自动化。
深入分析演化模式
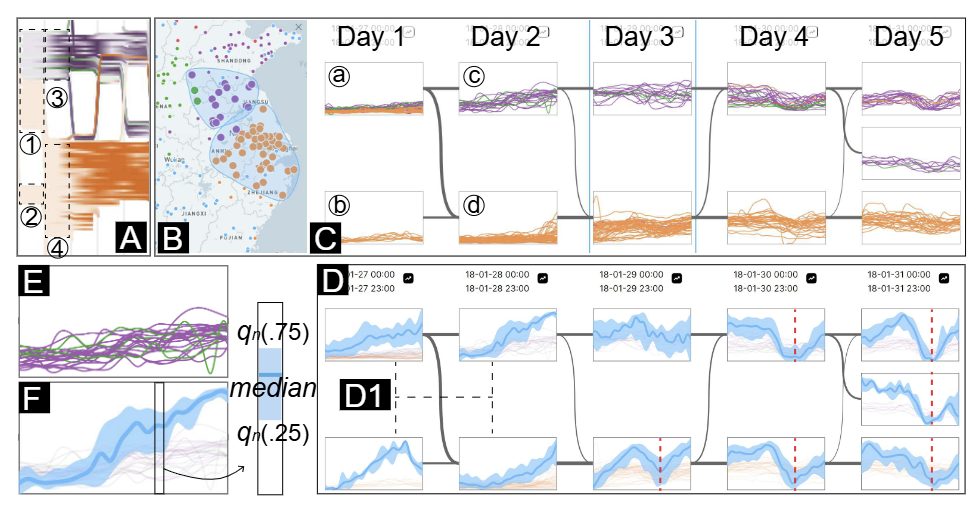
图5 长三角空气质量演化
在定位了感兴趣的时间段和会话后,用户可以深入进行详细分析。文章设计了一个 EvoLens(如图 5C 所示)来支持详细分析。
展示详细的时间趋势 (G3):EvoLens(如图5C)放大所选会话(如图5A)。每个会话被替换为折线图,ST序列以相同颜色的折线显示,y轴表示所有记录的值范围。为了揭示相关趋势,设计了趋势模式(如图5F)。通过归一化ST序列子部分,计算每个时间戳的四分位数,形成中位数线,并与区域重叠构成趋势模式。
保持模式之间的叙事:为保留演化模式的叙事(G2),文章保持实体转变和会话对齐的上下文。折线图根据Storyline中会话的位置定位:如果会话对齐,则图表水平对齐;如果属于同一时间切片,则垂直对齐;同一切片中的图表按顺序排列。若实体穿过两个会话,图表通过贝塞尔曲线连接,曲线宽度表示穿过的实体数量。
在时空中调查演化模式:EvoLens与地图(G4)协同工作。当用户悬停在某个时间切片时,地图会显示该时间切片中每个会话的地理分布(图5B)。具体来说,作者为地图上的每个会话生成一个凸包,以覆盖该会话所包含的点。这个视图中的会话数量少于Storyline中的数量,以便可以在地图上叠加视觉元素。
六.评估
6.1 案例研究
6.1.1 中国空气质量
在第一个案例研究中,文章分析了中国空气质量的演变。
数据集:
该数据集包含448个ST序列,覆盖几乎整个中国。每个ST序列记录了2018年1月1日至7月3日的某个地区的空气质量指数(AQI),时间粒度为每小时。
参数:
经过实验验证,论文参数设置:thd=300 km,thr=0.7,thc=3,ths=7,thw=140 px。
深入分析演化模式
中国北方的空气质量:在图4H中,作者观察到一组ST序列随着时间的推移逐渐分裂为四个模式,其中红色、绿色和紫色的ST序列表现出上升趋势,特别是红色ST序列覆盖北京。图6A放大了图4H,进一步将图6A1涂上紫色,图6A2涂上黑色,得到图6B和6C的空间分布。通过刷选图6B,得到了图1D、1E和1F中的细节。紫色和绿色ST序列在前三天内相关增加,达到了较高的污染水平(图 6E和F)。之后,它们开始不相关,分裂成左边和右边的区域。黑色ST序列的相关性较低,且污染水平较低(图 6E1)。红色ST序列在第三天出现下降,接着上升,其他序列则维持下降趋势(图 6E和F)。有假设认为,在最后三天,可能有额外污染源影响了北京-天津-河北地区。
长江三角洲的空气质量:在图 4I期间,长江三角洲及其北部发生了严重污染。作者对会话进行强制对齐,得到图4A布局。橙色和紫色ST序列在初期相关,后因橙色序列出现轻微下降而分裂,导致橙色序列比紫色晚一天达到高污染水平。最后三天,橙色和紫色序列呈现不同趋势,约下午4点出现细微下降。这表明污染可能从北向南传播,两个地区的波动/下降趋势不同,可能与工业结构和污染净化能力差异有关。历史天气数据表明,长江三角洲接收了北方强冷空气,带来了暴风雪和污染物。
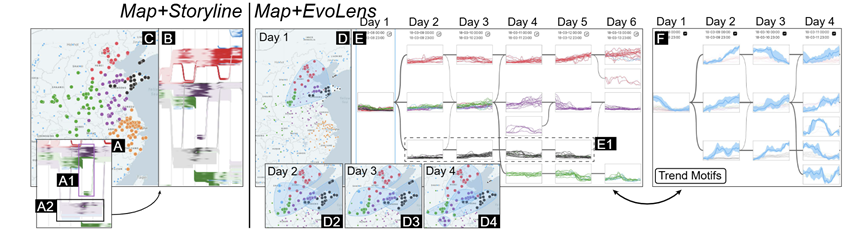
图6 GeoChron中的两级可视化
6.1.2 中国的温度
在第二个案例中,文章可视化了中国的温度时间序列。
数据集
该数据集包含393个ST序列,覆盖几乎整个中国。每个序列记录了2020年1月1日至12月29日某地区的温度,时间粒度为每天。
参数
将时间切片的大小设置为7天。文章参数为 thc=4和 thw=280 px。
分析整体演化模式
夏季(图7A中部)模式较少,因季风带来降水。图7A右上角的实体变亮,标志初冬。图7B显示温度周期性波动,图7B2中温度两周内显著下降。冬季季风引发大范围降温,导致ST序列相关,主要分布在中国北方(图7C和7D)。
深入分析模式
图7E或F显示了图7C1的详细信息。ST序列相关关系稳定,第一周波动无明显下降,第二周除黑色序列外,其他序列下降约10°C(图7E1)。这种趋势在图7F1中得到验证。中国气象局将此冷锋列为2020年十大天气气候事件之一。

图7 中国的温度
6.2 消融研究与参数分析
作者基于第8.1.1节的数据集,分析这些方法如何影响布局。文章通过消融研究测试了曲线隐藏和滑动窗口。
首先,作者将 thw=+∞,禁用曲线隐藏。图9A展示了结果的快照。几乎垂直的曲线在屏幕上上下弹跳,导致视觉干扰。此外,一些应保持视觉连续的对齐会话被这些曲线打断(如图8B)。thw值越小,杂乱程度越低。
作者直接使用时间切片中的相关系数,去除了渐变阴影,生成图8C布局。与图4D相比,ST序列的相关关系更加动态。图8D和E中的虚线椭圆高亮了曲线偏差,这些偏差影响了视觉清晰度,表明滑动窗口提高了可视化的可读性。
通过分析ths和thc参数,作者研究了它们对GeoChron布局的影响。较小的参数导致较高的布局(图9F),增大参数使布局紧凑。增加thc会导致松散对齐(图9G),增加ths会减少显示的会话(图9B)。
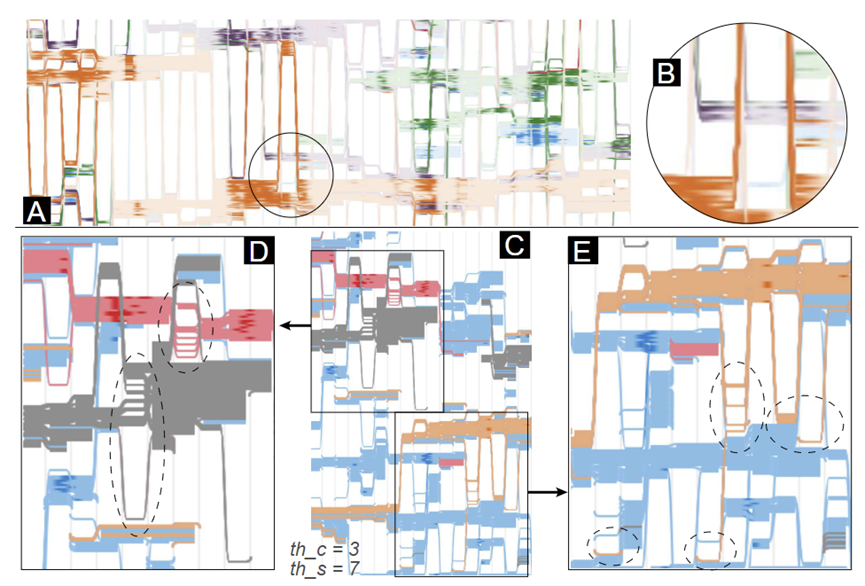
图8 消融(A,B)隐藏曲线和(C,D,E)滑动窗
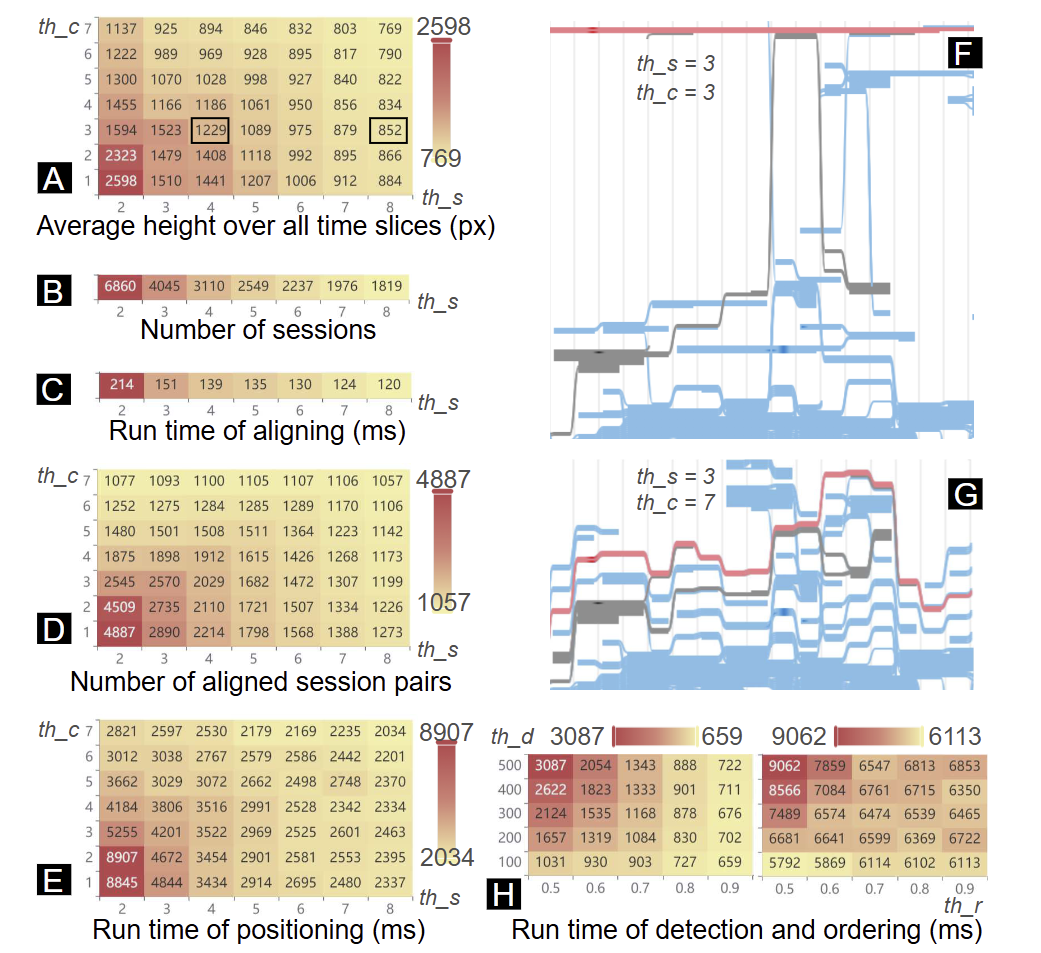
图9 定量实验结果
6.3 运行时间分析
为了优化布局,用户可能需要调整设置。作者报告了四个后端模块(演化模式检测、排序、对齐和定位)的运行时间,确保调整时的流畅性。实验在配备Intel Core i7 3.70GHz CPU和16GB RAM的Ubuntu 20.04桌面上进行,检测和对齐模块通过12池多进程加速。相关性计算不需要高效性,因为结果已提前缓存。
检测和排序:用户在调整thd和 thr时会与这两个模块交互。作者报告了不同thd和thr下的运行时间(图9H)。随着thd增加和thr减少,这两个模块的运行时间会增加,因为考虑的相关ST序列对更多。图10H中的最宽松情况总运行时间为12秒。
对齐和定位:用户在调整ths和thc时会与这两个模块交互。对齐模块的运行时间取决于会话数量,ths增加时,剩余会话较少,运行更快。定位模块的运行时间取决于对齐会话对的数量,ths和thc较小时,更多的对齐对导致更长的运行时间。实验中,对齐和定位模块的运行时间不超过10秒,后端能在几秒内响应,帮助用户快速调整布局。
七.总结
本文提出了GeoChron,一种有效的大规模ST序列可视化方法。文章将大规模ST序列的可视化问题表述为演化模式可视化问题,而Storyline技术可以很好地解决这一问题。为了应用Storyline技术,GeoChron包含一个用于从ST序列中提取演化模式的数据挖掘框架和一个改进的两层可视化机制,以提高视觉可扩展性。因此,GeoChron能够实现对大规模ST序列的模式感知和叙事保留的可视化。
 |

图文|许 熠
校稿|孙杨洋
编辑|李佳俊
审核|李瑞远
审核|杨广超
