





一.背景
误导性可视化是指一些图表通过利用数据的视觉表现,使不符合预期的数据看起来符合预期。近期在自动检测误导性可视化方面的进展主要集中在可视化的一些代码检查工具(linter)上,它通过检查图表的结构编程,识别违反既定可视化准则的行为。这只能为代码编写者提供帮助,却无法让数据使用者更好的对其进行甄别。
大语言模型在逻辑推理和解释数据方面有着卓越能力,可以理解图像等不同类型的输入。作者提出一个问题:多模态大语言模型是否能够识别和标记数据可视化中的误导元素?本文对三个专有的和一个开源的多模态LLMs进行了全面的评估。通过三套prompt让LLMs认识图表中的五个具体问题,再进行进一步的实验,探索其在提高数据可视化素养和对抗误导性信息方面的潜力。
面对更复杂的描述和说明细节使得LLMs响应时间变长的问题,本文采用在多轮对话设置中动态生成提示的方法解决。在实验中,LLMs一直在为图表寻找额外的判断要素,在发现可疑数据源和隐藏信息等问题方面发挥重要作用。
二.相关知识
2.1 误导性的可视化
误导性可视化是指通过图形设计有意或无意地歪曲数据表现,导致观众对数据的理解偏离事实。其形式包括截断坐标轴、比例失衡或选择性展示数据等,不仅加剧了社交媒体时代错误信息的传播,还对公众认知和决策产生负面影响。研究者通过详细分类和案例研究揭示其机制,并倡导在教育中融入批判性数据思维,以提升公众识别和解读数据的能力,从而更好应对数字时代的误导性信息。
2.2 可视化linters
数据可视化linters能够检测代码中的潜在错误,提醒程序员可能导致错误或低效结果的问题,是确保视觉数据呈现完整性的重要一步。这些linters在确保图表清晰和有效方面起到关键作用。如McNutt和Kindlmann引入了一个用于matplotlib的linter,利用代数可视化设计(AVD)框架中的规则来改善图表的清晰度和效果;GeoLinter将地图学原理应用于Vega-Lite中的地图可视化,以确保地图视觉呈现不会产生误导等。
2.3 计算机视觉中的图表分析
图表分析是计算机视觉研究中一个快速发展的领域,其重点是通过视觉表示提取数据并帮助问题的回答。随着图表分析的发展,它从简单的二进制问题转向需要数学推理的复杂开放式查询问题,在解释细微差别数据的能力上取得了巨大的进步。在研究过程中,引入了许多数据集进行基准测试,通过从图表中提取底层数据,以类似于表格问答的方式处理图表问答。
2.4 与LLMs的图表问答
Matcha项目利用LLMs将图表图像转化为程序代码和数据表,UniChart展示了一种灵活的图表问答框架,可能无需生成数据表。实验证明有效的提示机制是LLMs整合成功的关键,Marsh等人开发的提示构造模块提升了图表问答任务与LLMs操作能力之间的匹配程度,是该领域的最新成果。在此基础上,本文利用多模态LLMs识别视觉数据呈现中的误导元素,探索LLMs在避免通过数据可视化传播错误信息方面的潜力。
三.实验方法
实验分为三部分,第一步为初步实验收集多种可视化图表,包括误导性和有效图表,建立评估基线;在第二步中扩展提示,捕捉更广泛的图表问题,并面临输出长度和性能下降等挑战;最后探讨克服这些限制的策略,深入分析21种常见图表问题。实验涵盖四种多模态LLMs,包括OpenAI的ChatGPT、微软的Copilot、谷歌的Gemini以及开源的LLaVA-NeXT,其中LLaVA-NeXT在多个基准测试中表现出色 。实验从网络和社交媒体收集误导性图表,标注74种独特问题,同时构建了一组有效图表集,由来自不同来源的24张图像组成,以评估LLMs区分误导性和准确表示的能力。最后,使用准确率和F1分数(F1-score)来评估分类性能,引入事实正确性作为评估标准,以衡量LLMs的图表理解能力。
四.实验过程
4.1 实验一:探索阶段
收集一组误导性图表(30个)和有效图表(24个),并将其平均分为开发集和测试集。为了客观分析结果,通过将生成的对话重新输入LLMs,请求其以JSON格式总结对话,这样可以进行结构化和无偏见的响应分析。在初步实验中测试了三种提示类型:直接询问、Likert量表评估和大模型思维链(CoT)推理。
提示1(直接询问): 直接问出“这张图表是否真实地描绘了数据?”大多数LLMs将27个测试图表标记为“误导性”,ChatGPT正确识别了3个有效图表。常见标记的问题有“缺乏比例一致性”和“失真表示”,但缺失标题未被标记。
提示2(Likert量表):引入5分Likert量表,允许LLMs提供非严格的“是”或“否”的答案。实验将其回答分为三类,1分或2分为“真实”,3分为“既非真实也非误导”,4分或5分为“误导”。所有LLMs的表现均有所下降,唯一例外是Copilot,其F1分数完美。Copilot的21个响应被归类为“既非真实也非误导”,与特定问题的相关性较低。这表明Likert量表提示未能有效帮助LLMs识别图表问题。
提示3(CoT):采用CoT的推理方法,鼓励LLMs进行逐步分析后再给出最终答案。实验设计提示时询问图表的关键信息,例如是否存在标题、是否使用3D效果以及坐标轴是否从零开始等,促使模型思考每个问题。为LLMs提供一套标准或准则,让它们判断图表是否符合这些标准,从而进行更系统的分析。结果是回应的相关性显著提升,LLMs能够更准确地理解图表并识别问题。
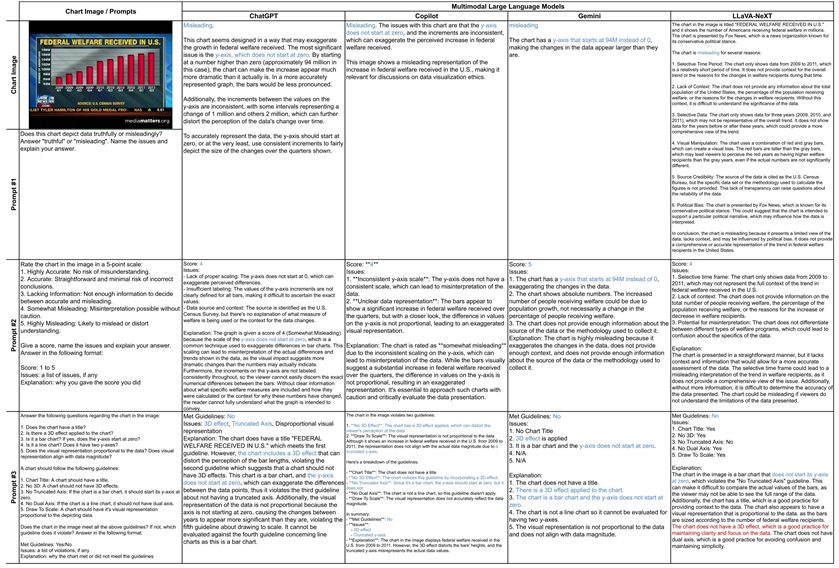
图1 实验一中不同LLMs的提示和响应
图1所示为实验一过程,其中蓝色文字代表正确解释,红色文字代 表错误解释。
表1 实验一结果

如表1所示,准确度(Acc.)表示正确答案占所问问题总数的比例。F1分数(F1)是精确率(Prec.)和召回率(Rec.)的调和平均值。提示1显示高召回率和低精确率,有假阳性的倾向。提示2中,Copilot在78%的情况下于5分制的李克特量表中选择了3分,剩下的6个案例中得分准确。相关性(Rel.)是相关响应的百分比。如果通过关键字匹配在回复中提到图表问题,则视作LLM的回复具有相关性。LLMs的响应比传统检测系统更复杂,引入问题清单可以减少歧义,使评价更清晰。接下来的研究将引导LLMs按问题严重性分类,而非简单的“是”或“否”。
4.2 实验二:探索阶段
实验一的结论说明提出事实性问题和提供检查清单是有效的、LLMs倾向于避免给出明确答案以及LLMs能够遵循实验中对问题的命名。提示3中采用CoT策略颇有成效,为了区分清单和CoT策略的影响,设计了提示4(仅使用检查清单)和提示5(模仿提示3)。
随着问题数量的增加,提示长度的增加为实验带来可扩展性的挑战。例如提示5中LLMs会忽略一些早期问题。于是提示6采用多轮对话格式,将提示5划分为小提示,以确保LLMs会回答所有问题。
在第二次实验中,数据集扩大到60个误导性图表和24个有效图表。由于数据集的不平衡,选择使用F1分数代替准确率,并在提示5和6中评估对事实问题的准确性。
提示4(仅使用检查清单):要求LLMs通过检查清单将识别的问题分为三类:主要问题、次要问题和潜在或不确定的问题。
提示5(CoT):在提示4的基础上,结构化为三个部分。第一部分提出有关图表结构的基本问题,例如图表类型、3D效果、坐标轴、图例和数据来源。第二部分涉及需要解释的复杂问题,如坐标轴上表示的数据类型和范围。最后一部分则更复杂,探讨数据是否可能被选择性采集或伪造。
提示6(分段CoT):在执行提示5时发现,LLMs有时会忽略前两组问题,直接响应最终检查清单。为此,本文将提示分为三部分,按顺序向LLM提供,每一轮都包含之前的对话内容。该方法使得从LLM中引出详细分析的过程更加可控和有结构。
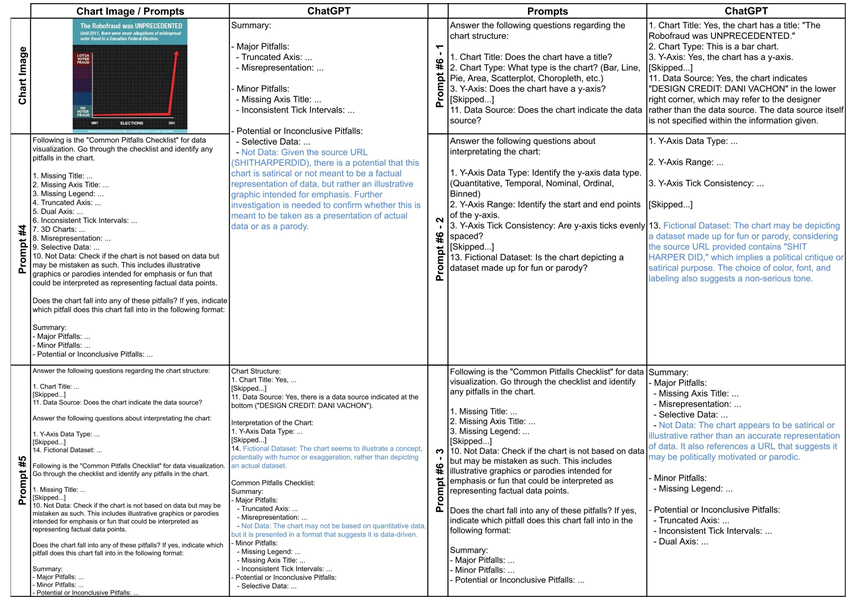
图2 实验二中不同LLMs的提示和响应
图2展示了一个被标记为“非数据”的示例图表,并提醒不要将其视为事实。蓝色短语表示准确的解读。
表2 实验二结果

如表2所示,实验二与实验一相比,高召回率和低精确度的情况有所改善,但仍观察到大量假阳性。引入事实正确性(Fact.),衡量对关于图表的事实问题(如图表类型、标题、坐标轴、比例和编码)的正确回答百分比。
实验结果显示,虽然三个提示的F1分数相似,但报告的问题数量和相关性有所不同。在提示4中,LLMs报告了更多无关问题,而在提示5和6中,相关问题的提及保持稳定,且无关问题减少。
LLMs展现出理解图表的能力,准确回答关于图表组件、比例和编码的问题,这表明它们具有出色的视觉解读能力。实验还发现LLMs能够识别以虚构数据为基础的恶意图表。然而,LLaVA-NeXT和Gemini在生成重复输出方面遇到了问题,影响了性能。为了应对输出的随机性,调整了Gemini的温度设置。
除此之外,长输出可能会触发最大令牌限制,导致提前返回不完整的响应,因此需要重新运行实验以获得结果。随着检测的问题数量增加,提示长度也随之增加,这对输入长度有限的LLMs构成可扩展性挑战。虽然提示4较短,但导致LLMs报告了更多无关问题;与之相比,提示6成功实现了相关结果,并提高了事实准确性。
4.3 实验三:解决可扩展性问题
实验二中的冗长提示和回答导致提前终止和推理问题的遗漏,虽然LLMs能正确回答事实性问题,但在最终评估中有时做出矛盾判断,例如注意到标题缺失却未将其视为问题。为此,作者在实验三中增加了更多解释性问题用于改进这一点。
提示7(分段CoT):从基础事实问题入手,再逐步询问数据类型、编码和比例,最终要求 LLM 更批判性地评估图表标题、坐标轴必要性及颜色方案适用性。这种分段提示在实验二中表现良好,但随着实验扩展至识别21类图表问题,提示长度大幅增加,达到约6,500字符和1,550 token。
提示8(直接JSON输出):基于实验二得出,简单的检查清单指令是无效的。在实验三中尝试通过指示LLM以JSON格式生成直接的问题列表,同时保持推理步骤, 让 LLMs生成直接的JSON格式问题列表。
提示9(动态链式推理):根据LLM的回答动态构建分段提示,从基本问题开始,根据初步答案定制后续查询。例如,如果LLM识别出某图表为饼图,则关于坐标范围或刻度一致性的问题将被省略。
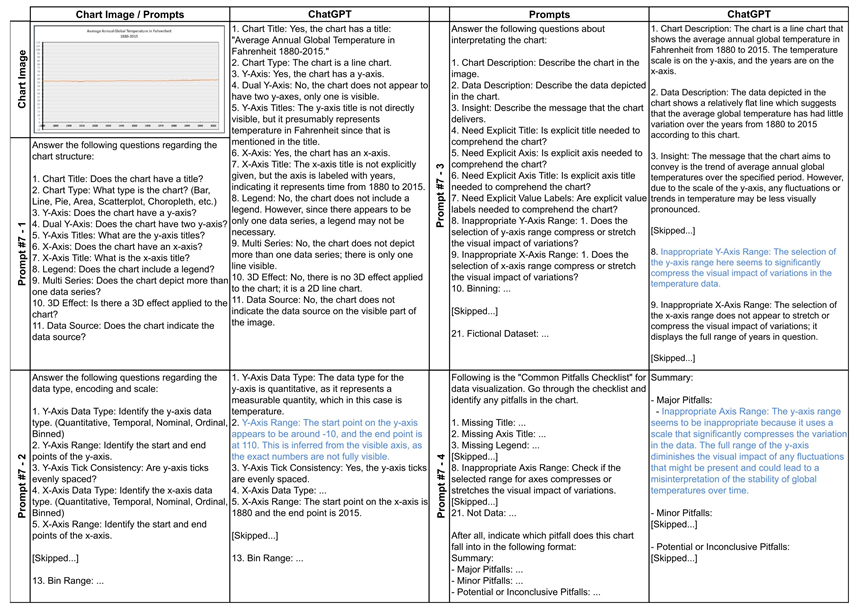
图3 实验三中不同LLMs的提示和响应
图3所示,提示7在提示6的基础上扩展,应用链式推理策略,包含额外的图表问题定义。示例图表存在一个主要问题,即y轴范围设置不当。
表3 实验三结果

表3为实验三的结果,测试数据集包含63个误导性图表和12个有效图表。提示7和9在正确识别有效图表和突出误导性图表问题方面表现更均衡。提示8表现出过度报告图表问题的倾向,尽管F1分数较高,但仅识别一个有效图表,且将其错误分类为假阴性。提示9通过过滤早期对话中的事实反应,减少了过度报告的问题数量,但其相关性评分低于未过滤的提示7。
LLaVA-NeXT在执行提示7和9时遇到重大困难,可能是由于其较小的模型参数(7B)导致,当前硬件限制妨碍了对更大模型(34B)的测试。
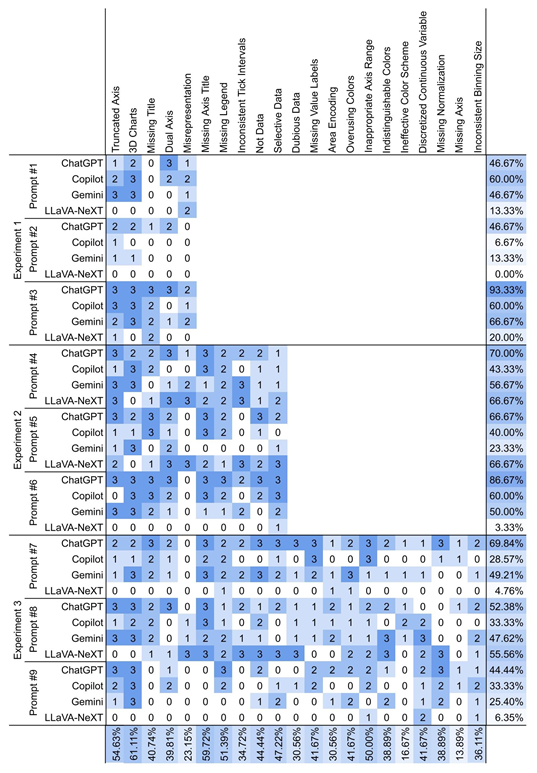
图4 LLMs关于颜色或分类的问题检测
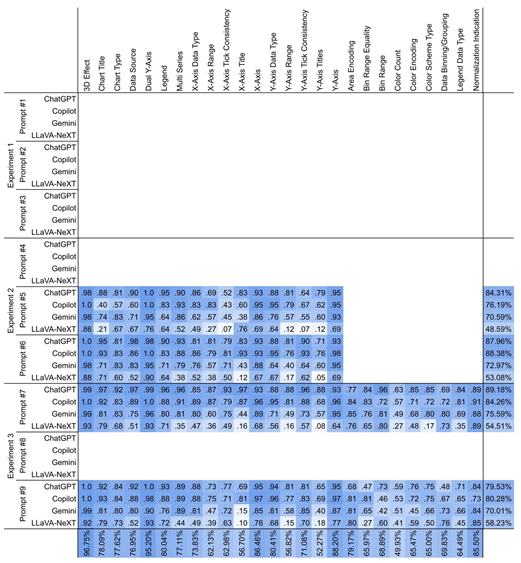
图5 LLMs关于图表属性的问题检测
如图4、图5所示,LLMs在回答图表属性问题(如图表类型、数据类型、3D效果等)时表现良好,但在颜色计数和刻度一致性检查上存在困难,在处理与颜色和分类不一致相关的问题时表现较差,如颜色过度使用、颜色不可区分、无效的配色方案和不一致的刻度间隔等。
五.总结
本文研究了LLMs在自动检测误导性可视化中的应用。三轮实验从最初的5种问题类型逐步扩展到21种问题,用以识别有效的提示策略。
研究发现,尽管LLMs在图表分析中展示了一定的能力,也存在一些局限性,例如处理颜色计数和刻度一致性等问题。实验得出,LLMs能够区分虚构数据与事实数据,并显示出对“非数据”图表的较强理解能力。在本文中CoT是最有效的提示策略,实验中探索了多种策略以优化LLM性能,但随着检测问题范围的扩大,提示长度显著增加,导致响应时间变长。为了解决可扩展性的问题,可以使用LLMs生成或从提示池中检索相关提示,以减小提示大小并保持相关性。采用多重LLMs的混合代理(MoA)方法在某些方面优于链式推理,未来也可能成为有前景的方向。最终,研究结果表明,LLMs有潜力增强传统的图表分析方法,并能有效识别图表中的误导元素。LLMs的发展为进一步研究提供了新的方向,开发支持数据解读和可视化分析的批判性思维工具。
 |
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!

图文|刘苧锐
校稿|李 政
编辑|李佳俊
审核|李瑞远
审核|杨广超
