




梧桐数据库对接HIVE数据库
1.概述
目前原始业务数据每天达到500-700TB,针对超大规模数据量目前采用的方案是将数据直接入库到HIVE,供后续业务分析。由于 HIVE HQL 表达能力有限和Hive效率较低,所以通过采用梧桐数据库对接HIVE,将HIVE数据作为梧桐数据库的外表,通过梧桐数据库SQL引擎进行统计分析。
2.获取HIVE配置信息
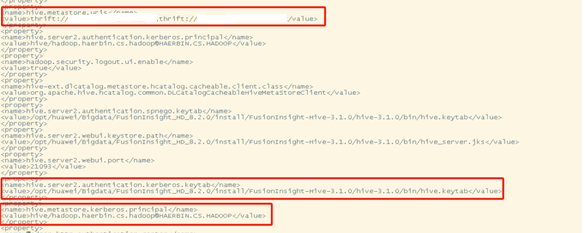
从hive-site配置中获取 metastore 的 hms、keytab 票据信息。具体如下图所示:
3.更新DB配置信息
根据客户hive-site配置中hms的ip端口、keytab、三段式principal,修改hdfs-client.xml配置,增加以下配置,如下所示:
<property>
<name>ip:port.hadoop.security.authentication
<value>kerberos
</property>
<property>
<name>ip:port.hadoop.security.token.lifetime
<value>604800000
</property>
<property>
<name>ip:port.hadoop.security.ticket.lifetime
<value>604800000
</property>
<property>
<name>ip:port.hadoop.security.principal
<value>hive/xxxx@xxxx
</property>
<property>
<name>ip:port.hadoop.security.keytab
<value>/user/loca/wutong/conf/wutongdb/xxxx.keytab
</property>
4. 测试访问hive 库
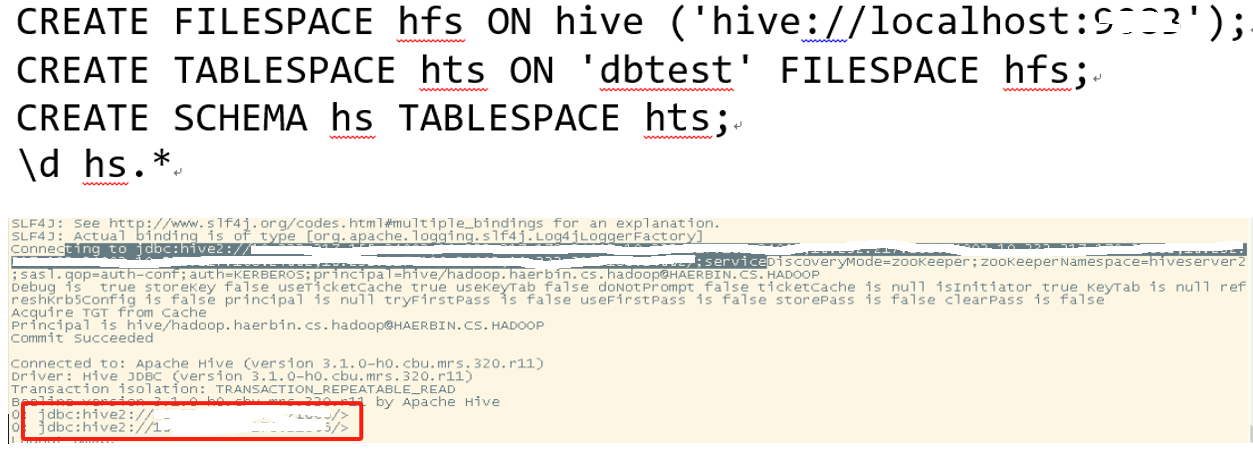
- 创建hive的filespace,'hive://localhost:9083’是hive的hms,在 hive-site.xml配置文件中的hive.metastore.uris 项查看,将localhost:port替换成hive-site中hms的ip和端口。
- 创建tablespace,'dbtest’是hive的数据库名称。
- 创建schema 绑定 tablespace
- \d hs.* 查看hive库下的所有表信息,如果能连通,则会显示库下所有表的表结构
具体如下图所示:
5. 注意事项
第一、梧桐数据库支持访问 Hive 的 ORC、PARQUET、TEXT 和 CSV 表格式。
第二、梧桐型数据库支持标量的基本数据类型:smallint, int, bigint, boolean, float, double, string, binary, timestamp, decimal, date, varchar, char
第三、仅支持读操作。
产品简介
- 梧桐数据库(WuTongDB)是基于 Apache HAWQ 打造的一款分布式 OLAP 数据库。产品通过存算分离架构提供高可用、高可靠、高扩展能力,实现了向量化计算引擎提供极速数据分析能力,通过多异构存储关联查询实现湖仓融合能力,可以帮助企业用户轻松构建核心数仓和湖仓一体数据平台。
- 2023年6月,梧桐数据库(WuTongDB)产品通过信通院可信数据库分布式分析型数据库基础能力测评,在基础能力、运维能力、兼容性、安全性、高可用、高扩展方面获得认可。
点击访问:
梧桐数据库(WuTongDB)相关文章
梧桐数据库(WuTongDB)产品宣传材料
梧桐数据库(WuTongDB)百科
