




本期将分享近期全球知识图谱相关
行业动态、开源工具、论文推荐
TigerGraph图数据库混合搜索技术
TigerGraph于2025年3月4日发布了下一代图数据库混合搜索技术,结合图搜索和向量搜索,为大规模AI应用提供支持。该技术通过高性能平台实现数据异常检测、个性化推荐等功能,显著提升AI系统的准确性和响应速度。同时,TigerGraph推出免费社区版图数据库,提供16核CPU、200GB图存储和100GB向量存储,支持开发者构建AI驱动应用。
TigerGraph的混合搜索技术具有5.2倍搜索速度提升、23%召回率提高及22.4倍资源节省等优势,支持复杂关系建模和知识图谱构建。其集成查询语言GSQL和Python库简化了混合查询操作。CEO Rajeev Shrivastava表示,该技术将帮助开发者构建关键任务型AI产品,改善用户体验。
https://t.hk.uy/bPHV

GOOGLE AI MODE
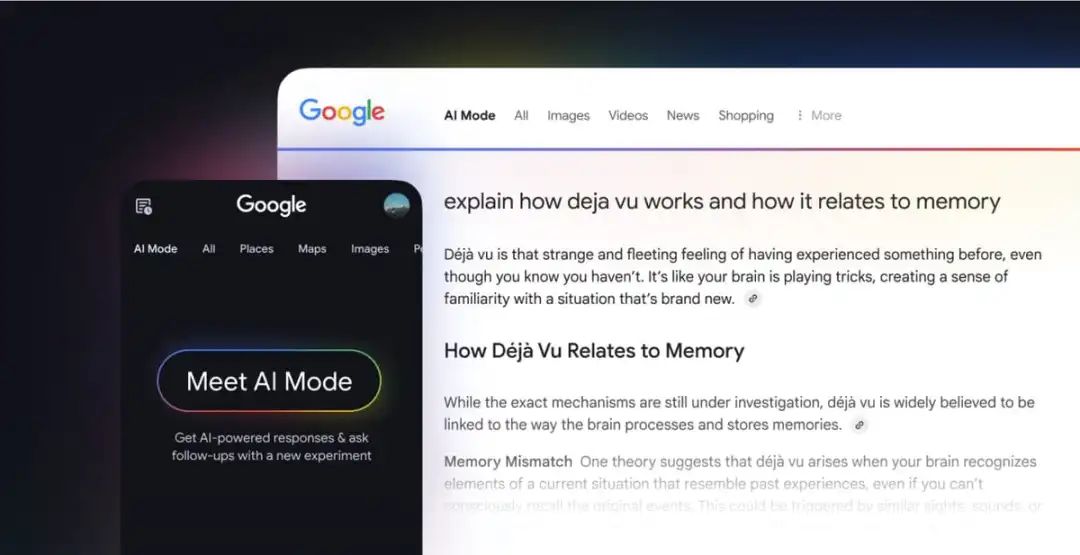
谷歌搜索再次升级,推出实验性功能“AI Mode”,通过增强AI概述能力,支持处理复杂的多步骤查询。该功能由Gemini 2.0驱动,结合深度推理和多模态能力,帮助用户进行深入探索和比较。例如,用户可一次性比较智能戒指、智能手表和追踪垫的睡眠监测功能,并进一步追问相关问题。AI Mode整合了谷歌的知识图谱和实时网络数据,确保回答的准确性和时效性。
知识图谱在AI Mode中扮演关键角色,通过结构化知识表示和实体关系建模,为用户提供高质量、上下文丰富的搜索结果。谷歌采用“查询扩展”技术,将多个相关子主题的搜索结果整合为简洁易懂的回答。目前,AI Mode仅限Google One AI高级订阅用户通过Google Labs体验,未来将增加图像、视频等视觉化回答形式,进一步提升用户体验。
https://t.hk.uy/bPzz
本周推荐的是arxiv 2025.2上的论文:Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs,该文提出了一种高效微调方法,将标准的多头注意力机制转换为多头潜在注意力,以提高推理效率并降低内存占用。作者来自复旦大学,华东师范大学,海康威视有限公司和上海人工智能实验室。

随着下游任务日益复杂,长上下文处理和计算密集型推理已成为LLM应用的核心。一个关键的瓶颈在于多头注意力机制中固有的键值(KV)缓存的内存占用,它随序列长度和模型大小线性增长。为解决这一问题,研究者们研究了分组查询注意力和多查询注意力等变体。然而,这些方法不仅减少了KV缓存的大小,还降低了注意力中的参数数量,导致性能下降。DeepSeek引入多头潜在注意力,这是一种具备低秩键值联合压缩的注意机制。实证显示,MLA在与MHA相比时表现出更优异的性能,同时在推理过程中显著减少KV缓存,从而提升推理效率。
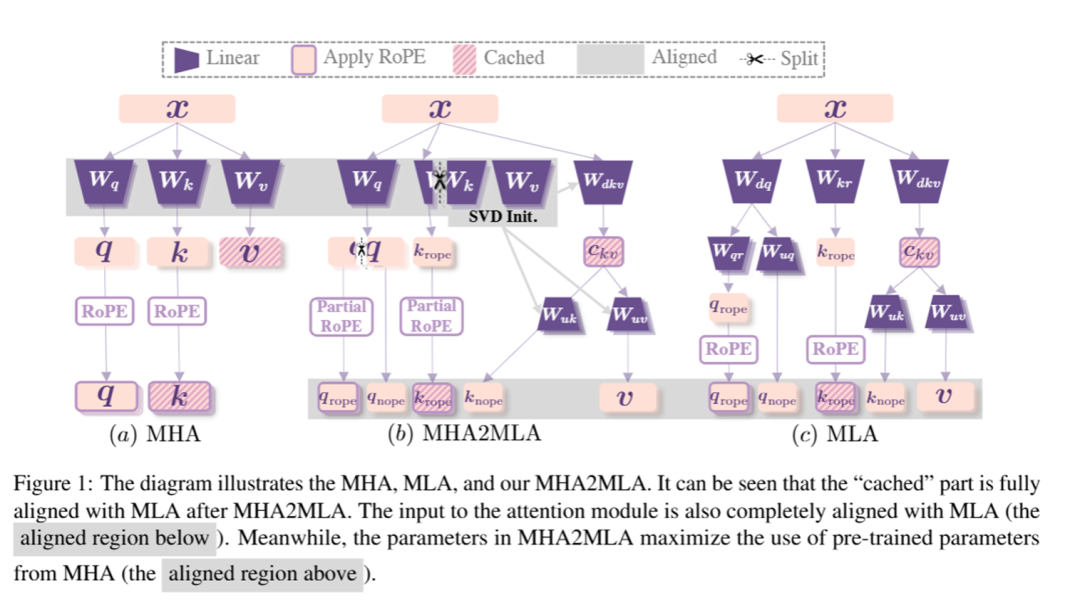
这引发的一个关键且未探索的问题是:最初为MHA精心训练的LLM能否适用于MLA进行推理?MHA和MLA之间固有的架构差异使得零样本转移不切实际,而从头开始预训练的高昂成本使这一转换在技术上具有挑战性且现有研究中未能得到充分探索。为解决这一问题,该文提出了首个数据高效的微调方法,以实现从MHA到MLA(MHA2MLA)的过渡,该方法包括两个关键组件:对于部分RoPE,作者从对注意力分数贡献较小的查询和键的维度中移除RoPE;对于低秩近似,作者引入基于键和值的预训练参数的联合SVD近似。这些精心设计的策略使得MHA2MLA能够仅使用很小一部分数据(3‰至6‰)恢复性能,大幅降低推理成本,同时与KV缓存量化等压缩技术无缝集成。例如,Llama2-7B的KV缓存大小减少了92.19%,而LongBench性能仅下降0.5%。
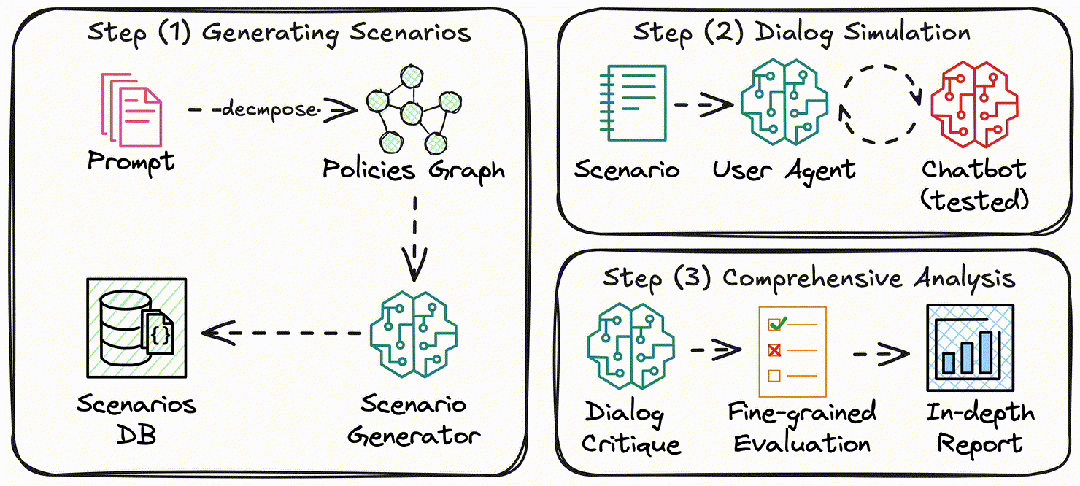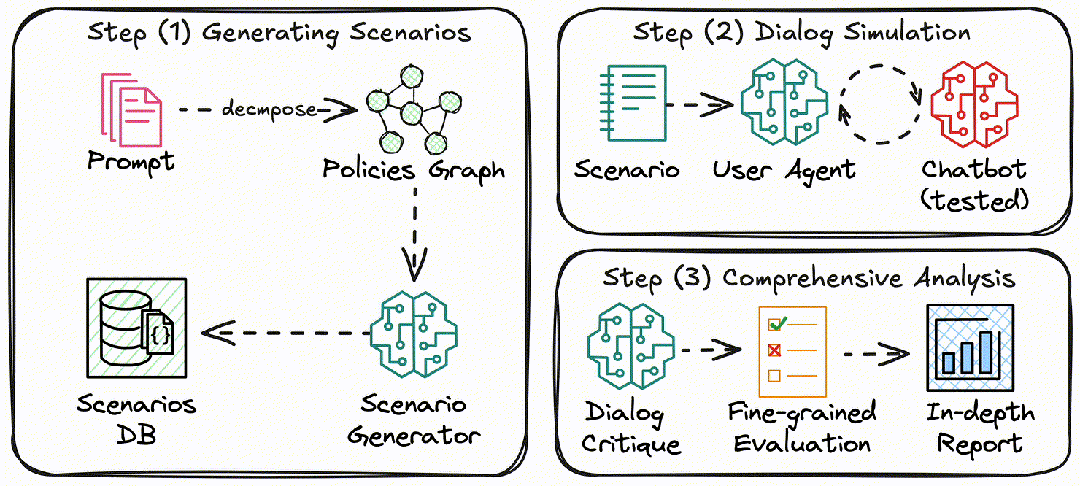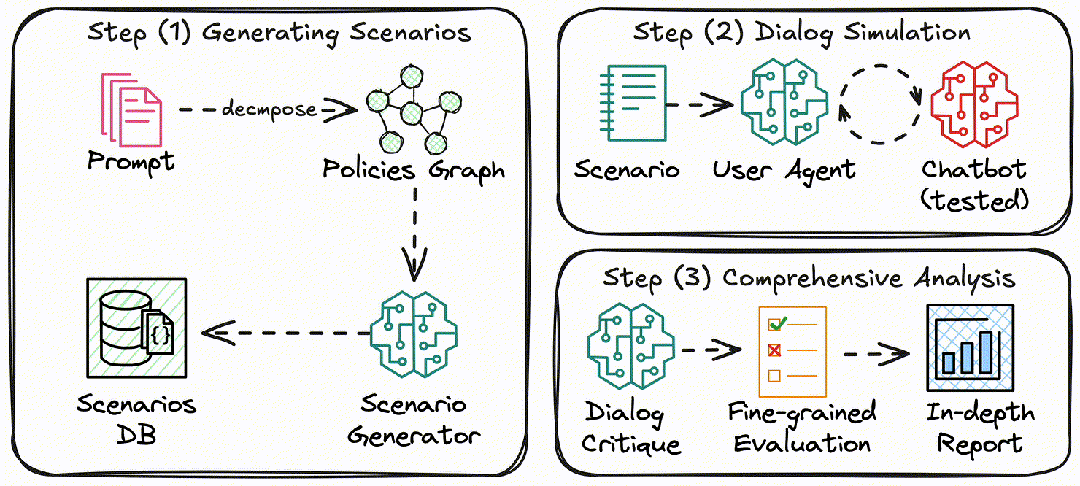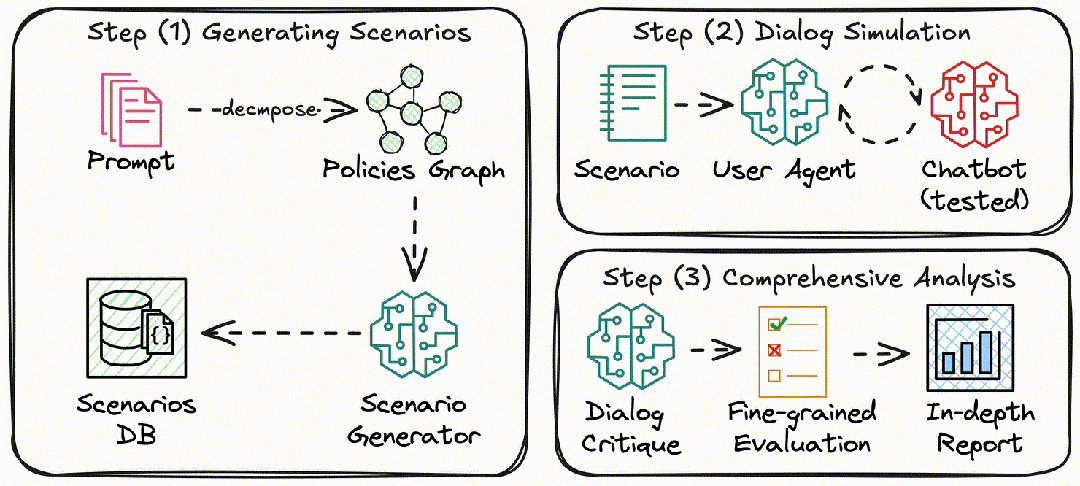
该文提出的MHA2MLA如下图所示:
该文源代码已在https://github.com/JT-Ushio/MHA2MLA 上提供,感兴趣的读者可以关注。
更多链接
内容:袁知秋、程湘婷、王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~

微信社区群:请回复“社区”获取
