




在脉脉上有一个热度很高的帖子「硕 1.5,被劝退后三月中旬到现在无 offer,不知道怎么破」。
有网友说:「如果能约到面试,说明简历不差,但是 50 场都没有 offer,说明你的面试谈判技巧出现了问题,应该总结一下,及时调整,心态不要崩」。
由这个话题为引子,码哥接下来给你分享一个知识点:「如何设计一个高性能MySQL 主键,实现海量数据下的高效查询」。
为什么需要主键
三个点。
数据记录需具有唯一性(第一范式) 数据需要关联 join。 数据库底层索引用于检索数据所需数据。
为什么主键不宜过长
这个问题的点在长上。那短比长有什么优势?(嘿嘿嘿,内涵)—— 短不占空间。
但这么点磁盘空间相对整个数据量来说微不足道。
那么原因应该在快上,而且和原始数据关系不大。以此自然得出和索引相关,而且和索引读取相关。那么为什么主键过大在索引中会影响性能?
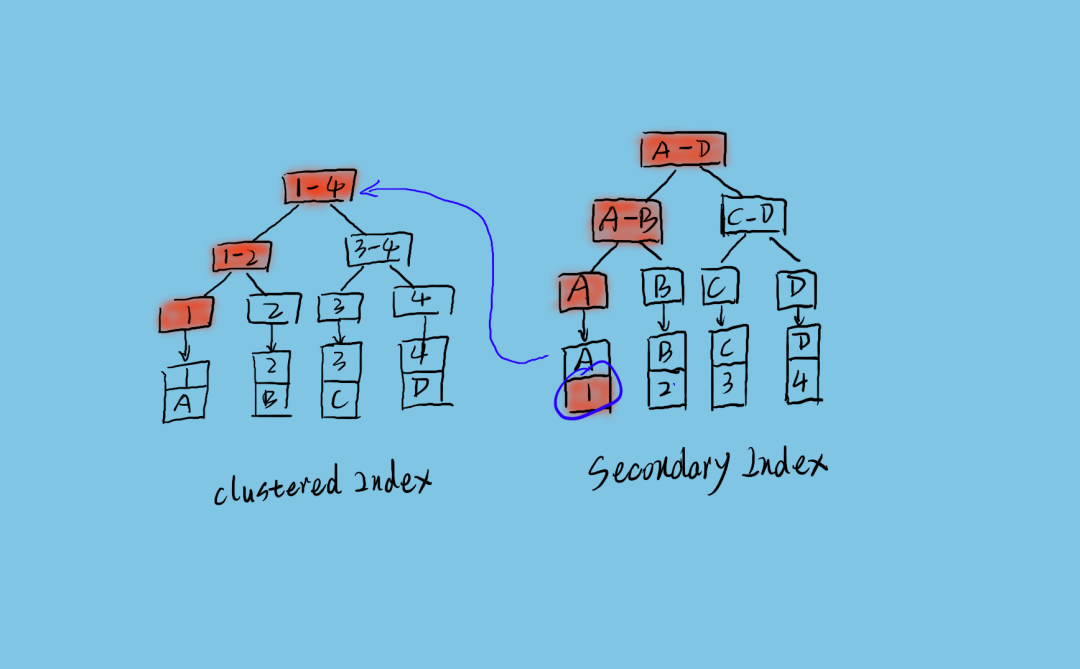
图中是 MySQL Innodb 引擎的索引数据结构。
左边是聚簇索引,通过主键定位数据记录。
右边是普通索引,对列数据做索引,通过列数据查找数据主键。
如果通过普通查询数据,流程如图所示,先从普通索引树上搜索到主键,然后在聚簇索引上通过主键搜索到数据行。
其中普通索引的叶子节点是直接存储的主键值,而不是主键指针。
所以如果主键太长,一个普通索引树所能存储的索引记录就会变少,这样在有限的索引缓冲中,需要读取磁盘的次数就会变多,所以性能就会下降。
为什么建议使用递增 ID
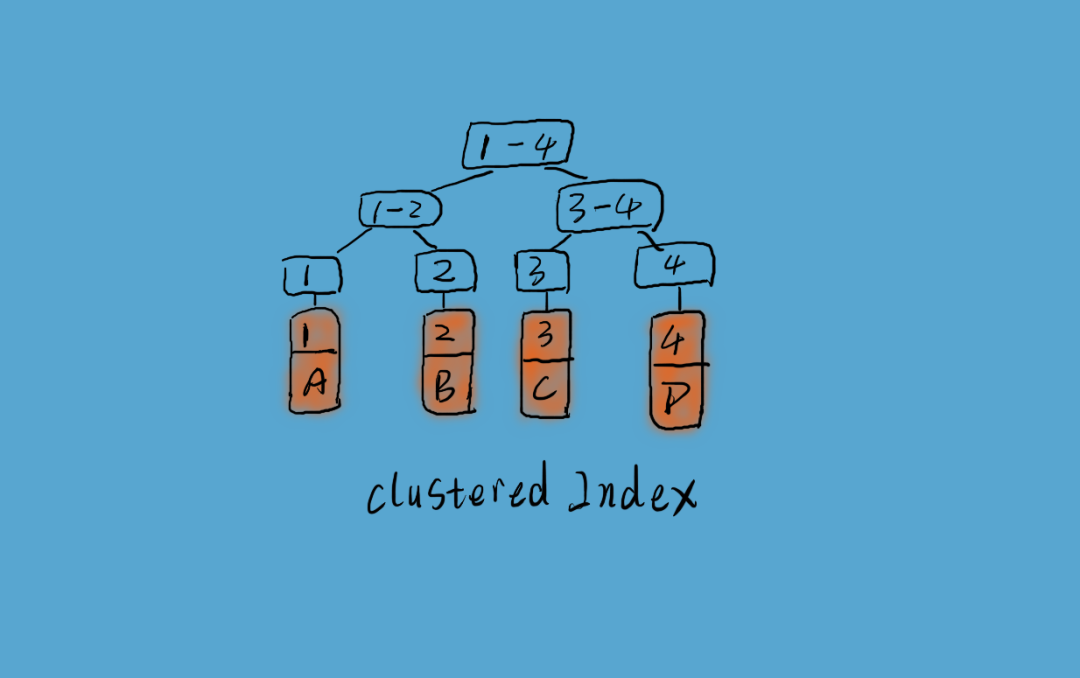
InnoDB 使用聚簇索引,如上图所示,数据记录本身被存于索引(一颗 B+Tree)的叶子节点上有序存储。
这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放。
因此每当有一条新的记录插入时,MySQL 会根据其主键值将其插入适当的节点和位置,如果页面达到装载因子(InnoDB 默认为 15/16),则开辟一个新的页(节点)。
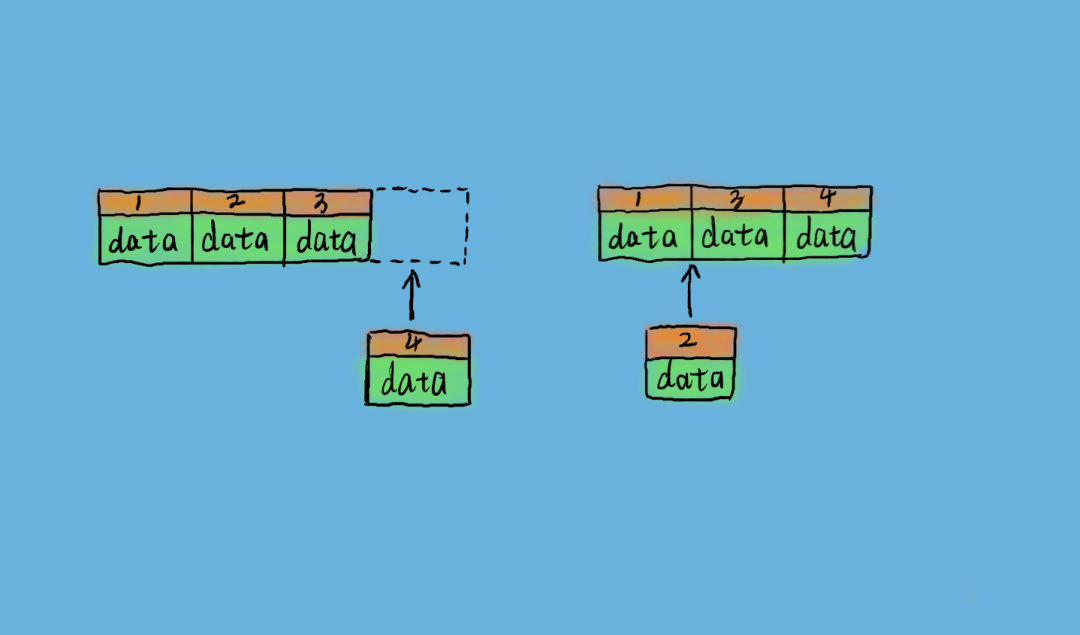
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。这样就会形成一个紧凑的索引结构,近似顺序填满。
由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上,如下图所示。
否则由于每次插入主键的值近似于随机,因此每次新记录都要被插到现有索引页的中间某个位置,MySQL 不得不为了将新记录插到合适位置而移动数据,如下图右侧所示。
ID 是否有需要具备业务含义
业务 ID,即使用具有业务意义的 id,比如使用订单流水号作为订单表的主键 Key。
逻辑 ID,即无关业务的 id,按某种规则生成 id,如自增 ID。
业务 ID 的优点
ID 具有业务意义,在查询时可以直接作为搜索关键字使用。 不需要额外的列和索引空间。 可以减少一些 join 操作。
业务 ID 的缺点
当业务发生变化时,有时需要变更主键。 涉及多列 ID 时比较难操作。 业务 ID 往往比较长,所占空间更大,导致更大的磁盘 I/O。 在 ID 确定前不能持久化数据,有时我们没有在确定数据 ID 。时,就想先添加一条记录,之后再更新业务 ID。 设计一个兼具易用和性能的 ID 生成方案比较难。
逻辑 ID 的优点
不会因为业务的变动而需要修改 ID 逻辑。 操作简单,且易于管理。 逻辑 ID 往往更小,性能更优。 逻辑 ID 更容易保证唯一性。 更易于优化。
逻辑 ID 的缺点
查询主键列和主键索引需要额外的磁盘空间。 在插入数据和更新数据时需要额外的 I/O。 更多的 join 可能。 如果没有唯一性策略限制,容易出现重复的 ID。 测试环境和正式环境 ID 不一致,不利于排查问题。 ID 的值没有和数据关联,不符合三范式。 不能用于搜索关键字。 依赖不同数据库系统的具体实现,不利于底层数据库的替换。
主键 ID 生成方式有哪些?
一般情况下,我们都使用 MySQL 的自增 ID,来作为表的主键,这样简单,而且从上面讲到的来看,性能也是最好的。
但是在分库分表的情况情况下,自增 ID 则不能满足需求。我们可以来看看不同数据库生成 ID 的方式,也看一些分布式 ID 生成方案。
MySQL 自增
MySQL 在内存中维护一个自增计数器,每次访问 auto-increment 计数器的时候, InnoDB 都会加上一个名为AUTO-INC 锁直到该语句结束(注意锁只持有到语句结束,不是事务结束)。
AUTO-INC 锁是一个特殊的表级别的锁,用来提升包含 auto_increment 列的并发插入性。
在分布式的情况下,其实可以独立一个服务和数据库来做 ID 生成,依旧依赖 MySQL 的表 ID 自增能力来为第三方服务统一生成 id。
Mongodb ObjectId
Mongodb 为防止主键冲突,设计了一个 ObjectId 作为主键 id。它由一个 12 字节的十六进制数字组成,其中包含以下几部分:
Time:时间戳。4 字节。秒级。
Machine:机器标识。3 字节。一般是机器主机名的散列值,这样就确保了不同主机生成不同的机器 hash 值,确保在分布式中不造成冲突,同一台机器的值相同。
PID:进程 ID。2 字节。上面的 Machine 是为了确保在不同机器产生的 objectId 不冲突,而 pid 就是为了在同一台机器不同的 mongodb 进程产生的 objectId 不冲突。
INC:自增计数器。3 字节。前面的九个字节保证了一秒内不同机器不同进程生成的 objectId 不冲突,自增计数器,用来确保在同一秒内产生的 objectId 也不会发现冲突,允许 256 的 3 次方等于 16777216 条记录的唯一性。
开源框架实现
百度 UidGenerator:基于snowflake算法。 美团 Leaf:同时实现了基于 MySQL 自增(优化)和 snowflake 算法的机制。
博主简介
码哥,9 年互联网公司后端工作经验,InfoQ 签约作者、51CTO Top 红人,阿里云开发者社区专家博主,目前担任后端架构师主责,擅长 Redis、Spring、Kafka、MySQL 技术和云原生微服务。
喜欢的可以给个关注,也可以在公众号后台回复“资料”下载我原创 300 多页的《Redis 高手心法》。
往期推荐
