





01

小鹏汽车是中国智能电动汽车领域的领军者,从2014年成立至今一直笃定投入智能化技术研发,始终身处全球智驾第一梯队。在自动驾驶领域,小鹏汽车创造了多个国内第一:第一个量产激光雷达高阶智驾方案、第一个基于高精地图实现城区高阶智驾、第一个去高精地图并让做到智驾“全国都好开”。目前更是业内最早实现“轻雷达、轻地图”高阶智驾全系标配的车企。

02

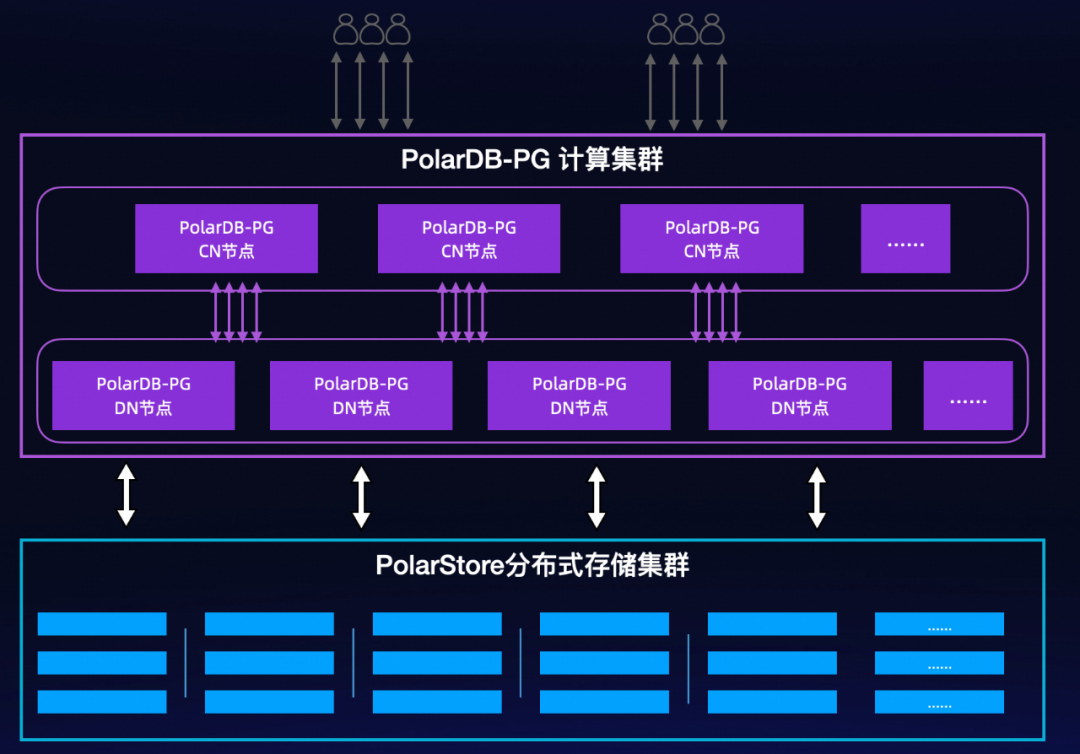
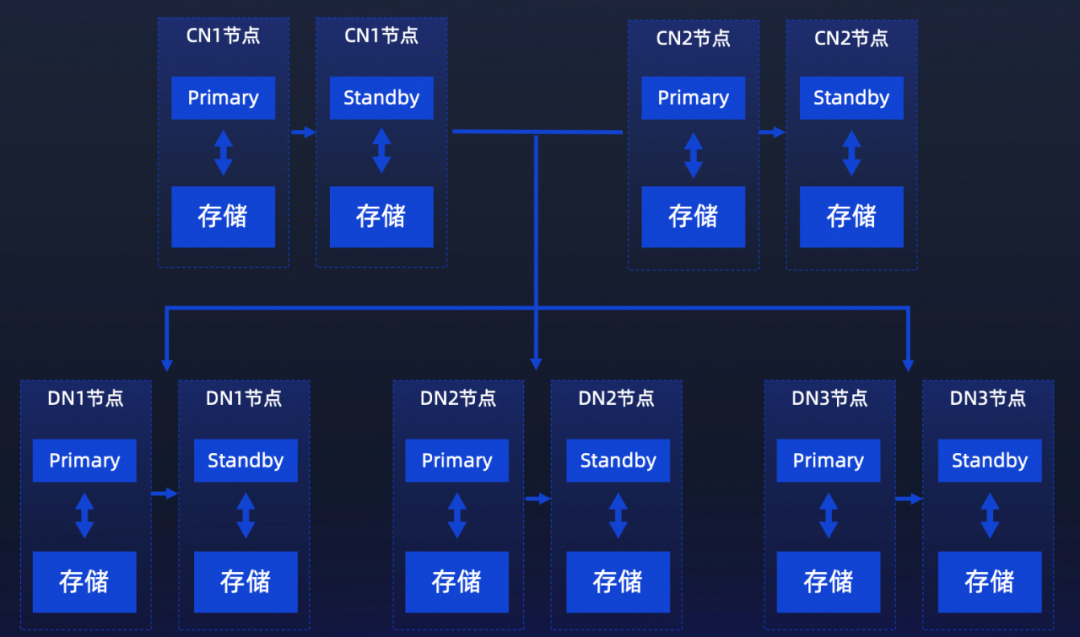
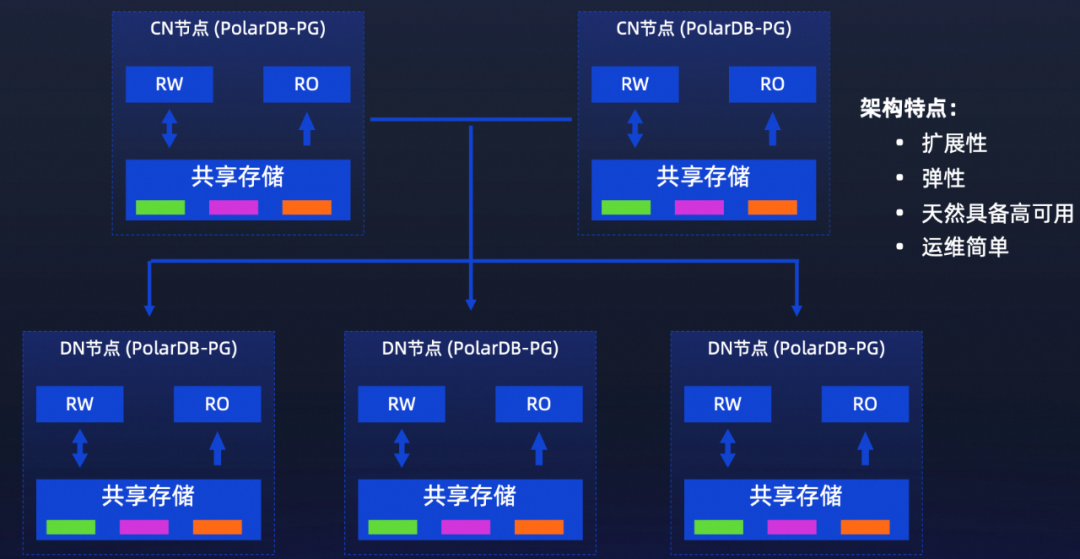
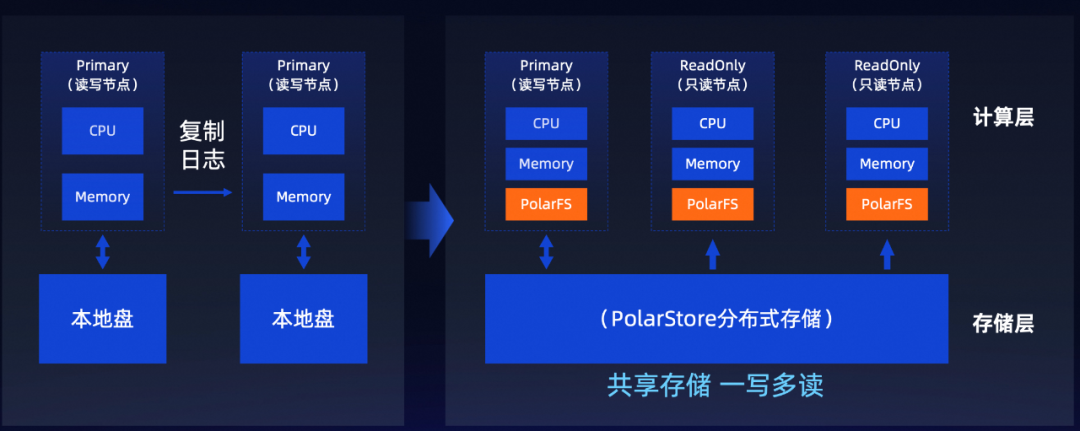
小鹏汽车的数据管理平台经历了3次大的技术升级,从社区PostgreSQL、到阿里云瑶池旗下的云原生数据库 PolarDB PostgreSQL 版(以下简称PolarDB-PG)的一写多读、再到现在PolarDB-PG多写多读的云原生分布式形态。

03
PolarDB-PG 分布式在大模型训练的应用
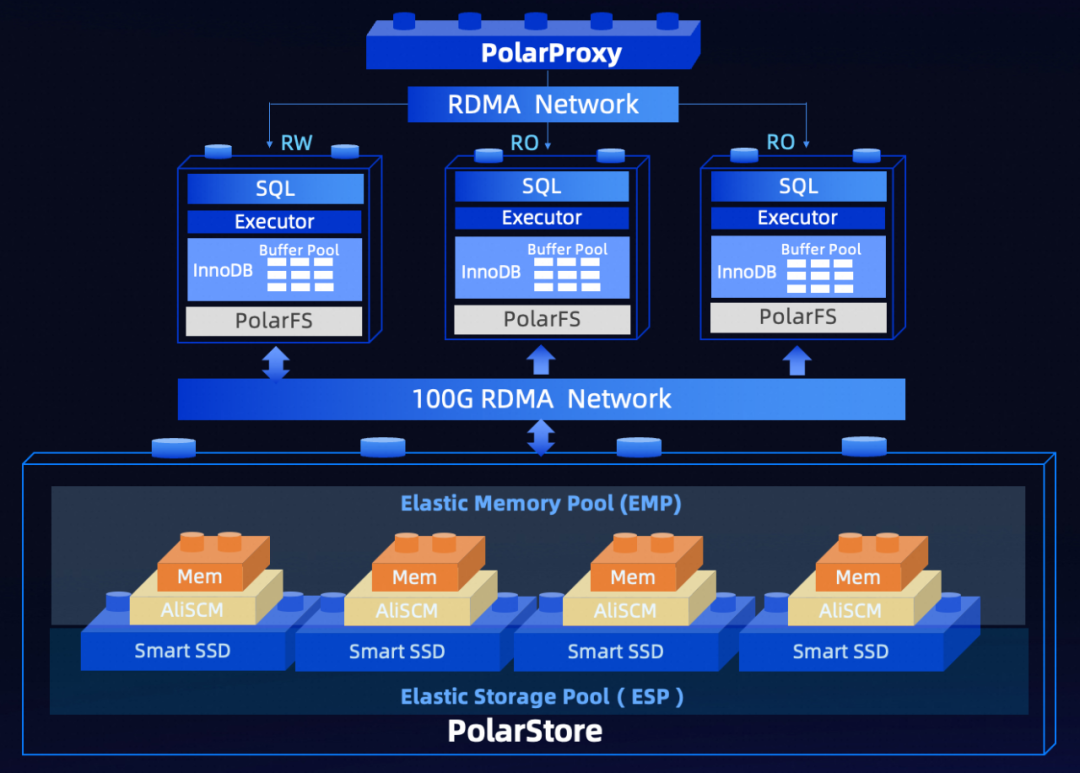
PolarDB-PG 分布式架构
ScaleUp扩展:集群中的每个节点都是读写分离的设计,具备独立的弹性能力;
ScaleOut扩展:可扩展1024个节点,提供百PB级别的存储;
存储按需扩容:无需提前预分配存储,可以根据实际业务的写入量实时的扩展;
集群的秒级备份:支持秒钟级完成整个集群的数据备份。
AI场景高弹性的存算分离
由于底层的存储是PolarStore分布式共享存储使用ParallelRaft复制协议,天然具备了数据高可用;
PolarStore支持基于COW的快照,可以在秒级对整个集群做全量备份;
单CN/DN节点在出现瓶颈时,可按需扩容RO节点和存储容量。
AI场景下的自动冷热数据分层存储
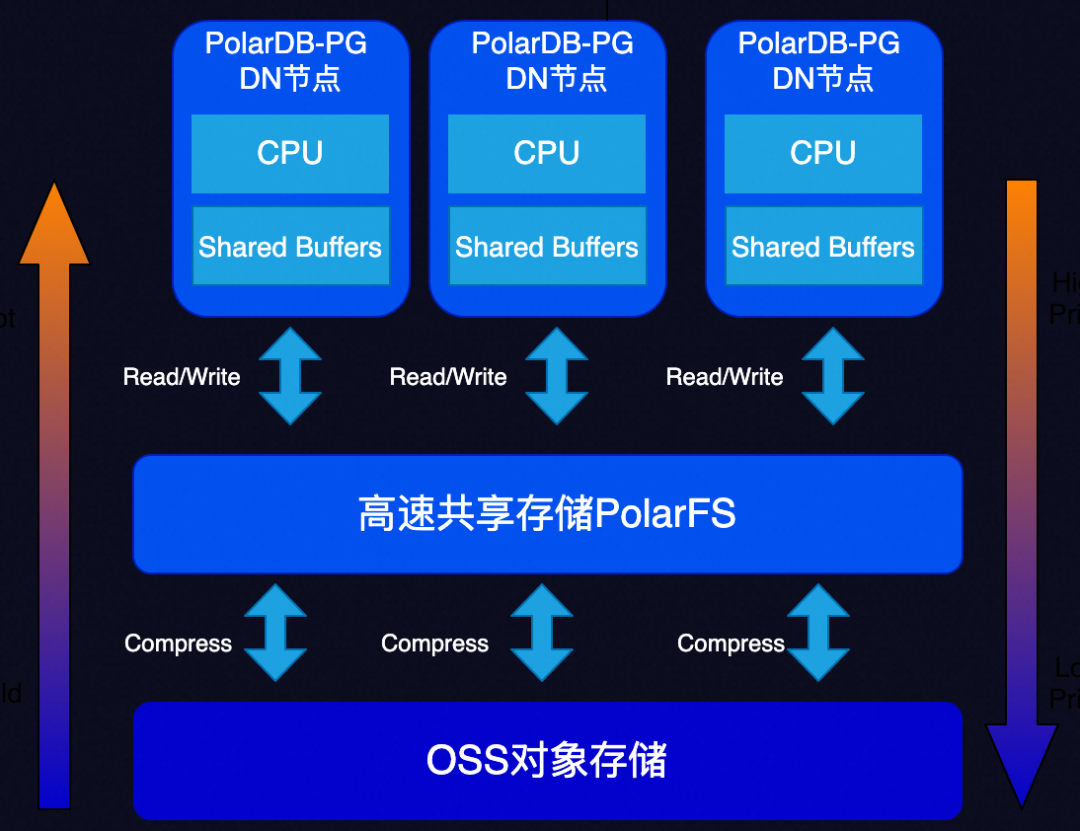
SQL全透明; 写入到OSS的数据仍支持修改; PolarStore做为高速持久化缓存; 写性能损耗5% 读性能下降2~3倍; 支持大块压缩。
AI场景下的向量化查询加速
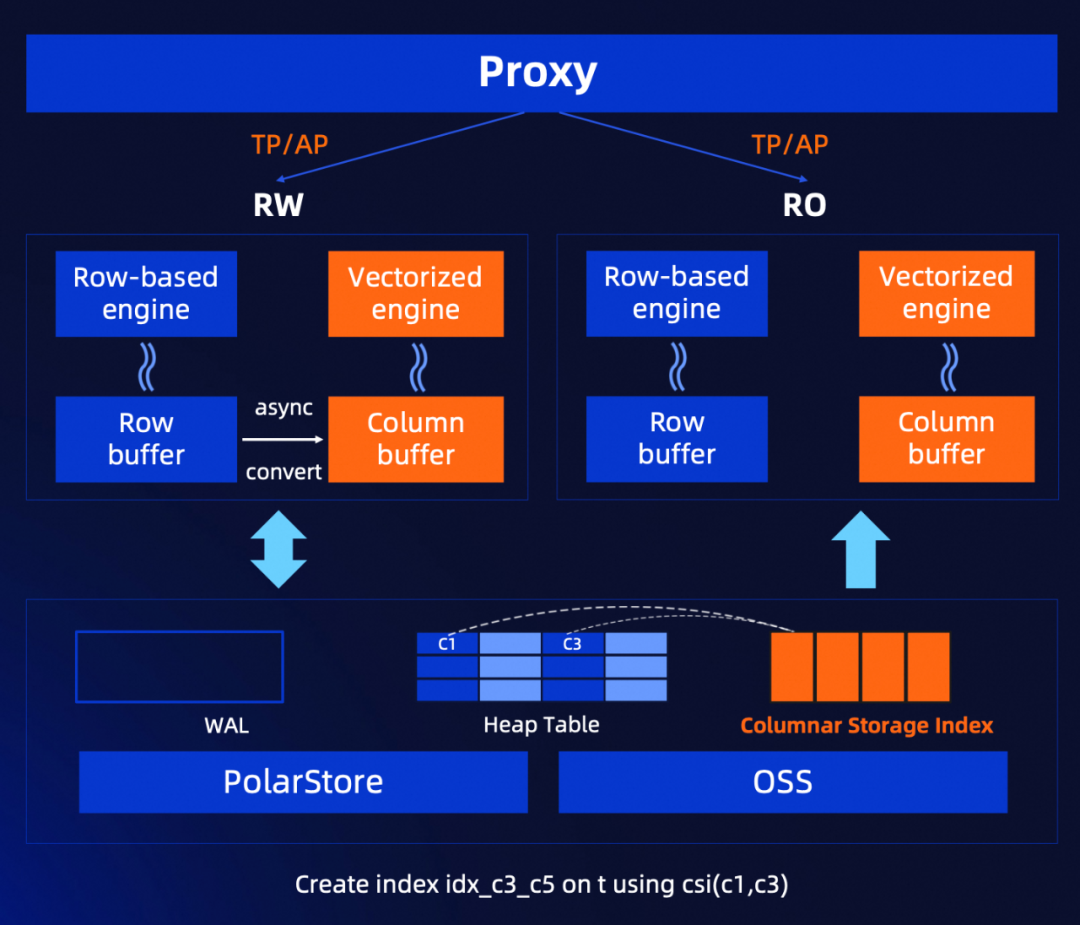
为了加速分析场景,PolarDB-PG内置duckdb引擎,实时将行存转成列存数据,可以在RW/RO节点上进行分析查询以实现资源隔离。
AI训练场景下高IO吞吐
业务上的一个表,在逻辑上是一个“大文件”,在数据库内核中被切分成了1GB的文件;
优化器/刷脏进程每次操作表都会定位具体的物理文件,以及计算表大小;
社区PG的算法是从前往后依次遍历,当单表很大时,O(N)的复杂度对文件系统造成了极大的压力;
PolarDB-PG使用指数探测+回溯的方法,优化到O(logN)复杂度;
可以支持单表30TB+的随机读写(顺序写其实很简单不需要太多的优化)。
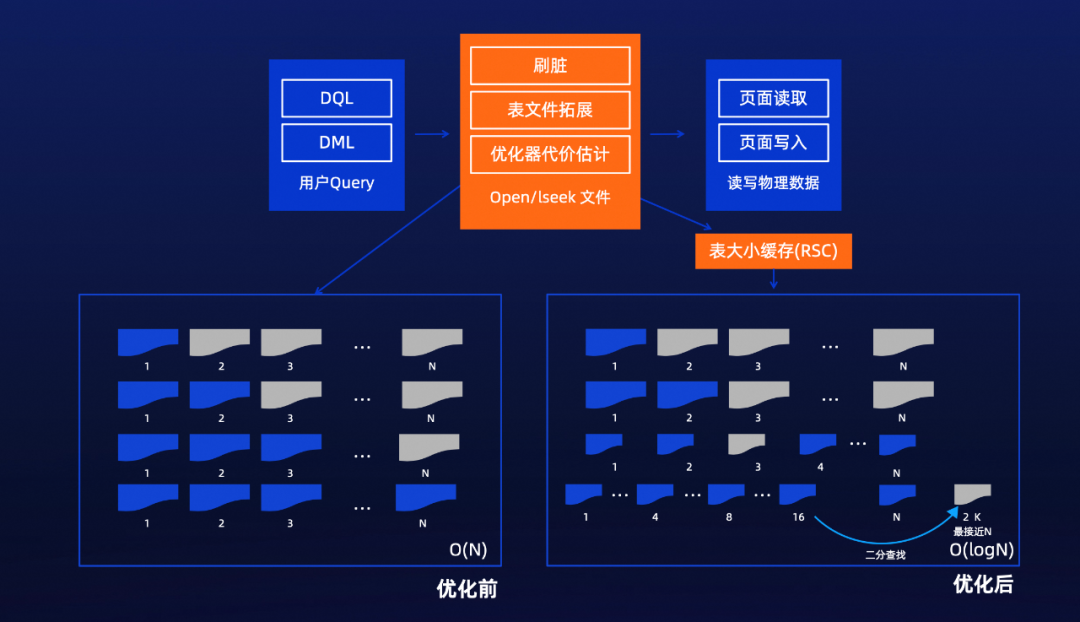
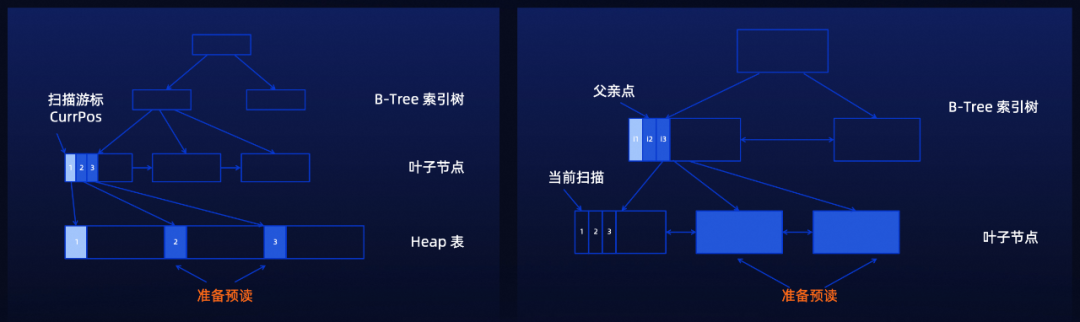
同时,为了最大程度发挥底层存储集群的性能通过AIO对IO进行提前预读,可将单点吞吐跑到4GB/s。
软硬协同设计的高性能分布式存储PolarStore
PolarStore是高度软件与硬件协同设计的全用户态分布式存储,如果结合业务负载特点,充分发挥出RDMA、Nvme、Optane、大内存、多核等硬件的性能,对软件的设计有更大的挑战,PolarStore的核心思想如下:
1. IO全链路用户态和ZeroCopy:应用层的读写IO从计算集群到后端存储集群,以及存储节点之间的ParallelRaft复制,每个IO的流转全部在用户态;网络传输使用RDMA,磁盘读写使用SPDK,IO在各个组件之间流转使用指针,避免了内存拷贝
2. IO全链路并行执行:如上个章节的介绍,数据库内核通过大量的优化尽量使用并行IO,在数据复制时通过自研ParallelRaft优化Raft协议只能顺序复制的瓶颈问题,在IO落盘时通过SPDK绑定NVMe的多队列并与CPU绑定,减少IO在底层的锁竞争;
3. 全栈组件异步化编程:异步化的方法是比较容易理解的,组件之间的通信使用共享存储,在于网络的交互使用RDMA,与磁盘的交互通过SPDK。最大的挑战是组件内部在同一时刻有不同的事件发生,每个事件有相应的上下文、正常流程下的处理机制、以及错误时的处理机制,同时需要考虑软件的可扩展性和各类事件的优先级;
4. 极致的细节设计:在RDMA的网络通信设计时可以结合大数据包、小数据包、超大数据包的收发特点真针对性的优化;内存分配的优化;Polling模式的优化;IO链路监控的优化等。
04
总结




点击阅读原文了解 PolarDB PostgreSQL 分布式版

