






Fluss: 面向分析的实时流存储
在 Data + AI 驱动的新时代,企业对实时数据分析的需求日益增长。然而,传统上我们所依赖的工具和架构,在设计时并未将分析场景作为首要考量,这导致了企业在使用实时数据时面临诸多挑战。目前,业界常见的实时数仓架构是采用消息队列 Kafka 与流处理引擎 Flink 的组合。但是,Kafka 并非专门为分析而设计,因此在应用于流分析场景时存在一些显著的问题,比如不支持数据更新、缺乏高效的查询功能、数据难以复用、回溯历史数据困难、以及高昂的网络成本等。这些问题不仅使得 Kafka 与 Flink 的结合使用变得不够理想,也在一定程度上限制了 Flink 在更广泛应用场景中的发挥。
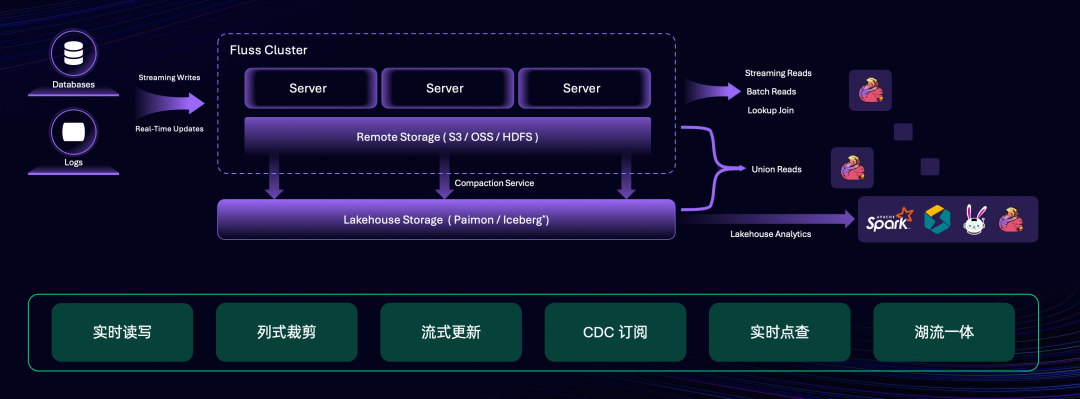
为了解决这些问题,我们研发了 Fluss 项目。Fluss 创新性地将列存格式和实时更新能力融合进了流存储中,并与 Flink 深度集成,帮助用户构建高吞吐量、低延迟、低成本的流式数仓。其具备如下核心特性:
实时读写:支持毫秒级的流式读写能力。
列式裁剪:以列存格式存储实时流数据,通过列裁剪可提升 10 倍读取性能并降低网络成本。
流式更新:支持大规模数据的实时流式更新。支持部分列更新,实现低成本宽表拼接。
CDC订阅:更新会生成完整的变更日志(CDC),通过 Flink 流式消费 CDC,可实现数仓全链路数据实时流动。
实时点查:支持高性能主键点查,可作为实时加工链路的维表关联。
湖流一体:无缝集成 Lakehouse,并为 Lakehouse 提供实时数据层。这不仅为 Lakehouse 分析带来了低延时的数据,更为流存储带来了强大的分析能力。
更多项目细节和特性介绍请访问项目官网:https://alibaba.github.io/fluss-docs
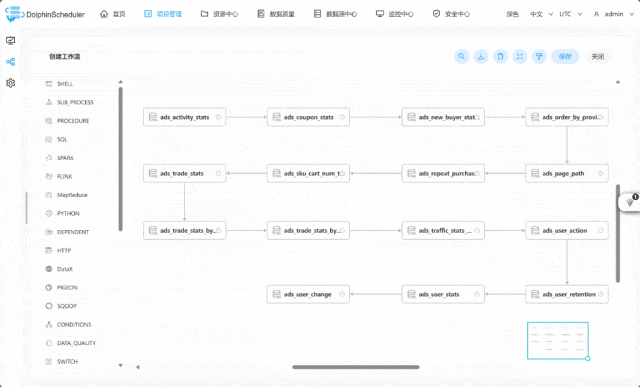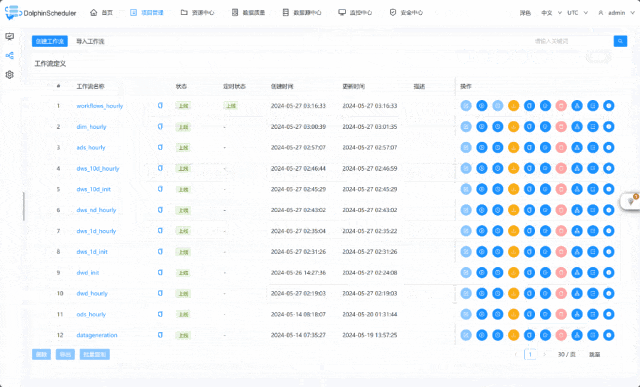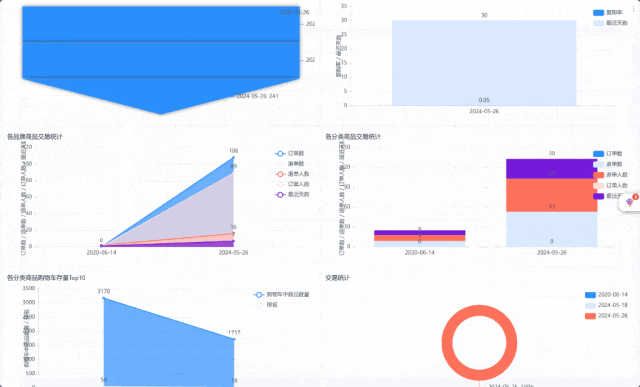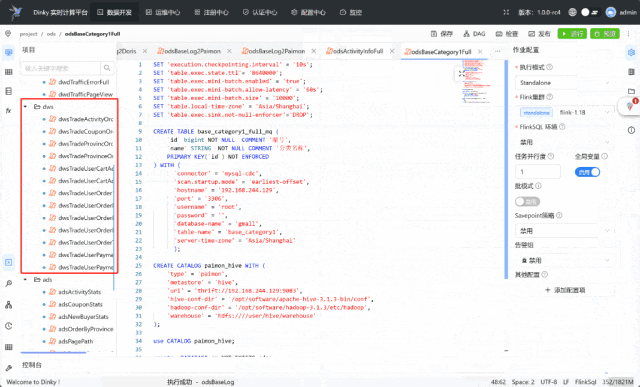
这或许是一个对你有用的开源项目,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning
https://github.com/Mrkuhuo/data-warehouse-learning
https://bigdatacircle.top/
项目演示:
01
进交流群群添加作者

推荐阅读系列文章
建议收藏 | Dinky系列总结篇 建议收藏 | Flink系列总结篇 建议收藏 | Flink CDC 系列总结篇 建议收藏 | 全网最全Doris实战文章合集 建议收藏 | Seatunnel 实战文章系列合集
如果喜欢 请点个在看分享给身边的朋友
