




Apache NiFi是一个开源的、易于使用和可扩展的数据集成工具。它提供了一种可视化的方式来设计、管理和执行数据流。NiFi的设计目标是处理和分发大量数据的实时流。它提供了强大的数据流转和转换功能,可以将数据从各种源头(如数据库、文件系统、消息队列等)收集、转换和传输到各种目标(如数据库、文件系统、消息队列等)。

2. 双击run-nifi.bat启动
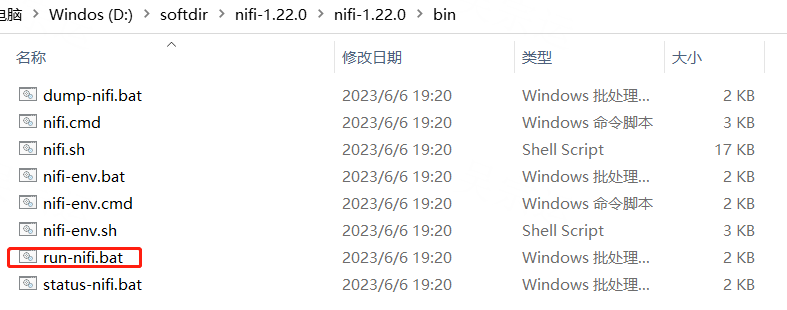
3. 需要注意的是,JDK版本要是11及以上。

二、配置任务
1.配置GenerateTableFetch,用来增量抽取数据
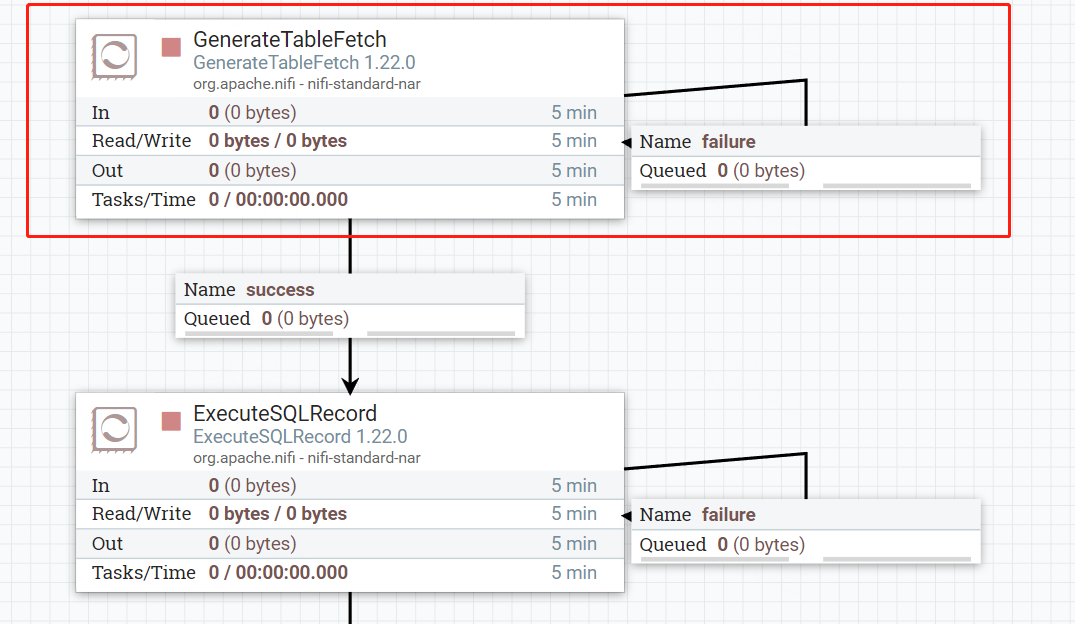
需要链接数据源连接池,同时指定表、字段及用来规定增量抽取开始的位置,一般是时间戳或者主键
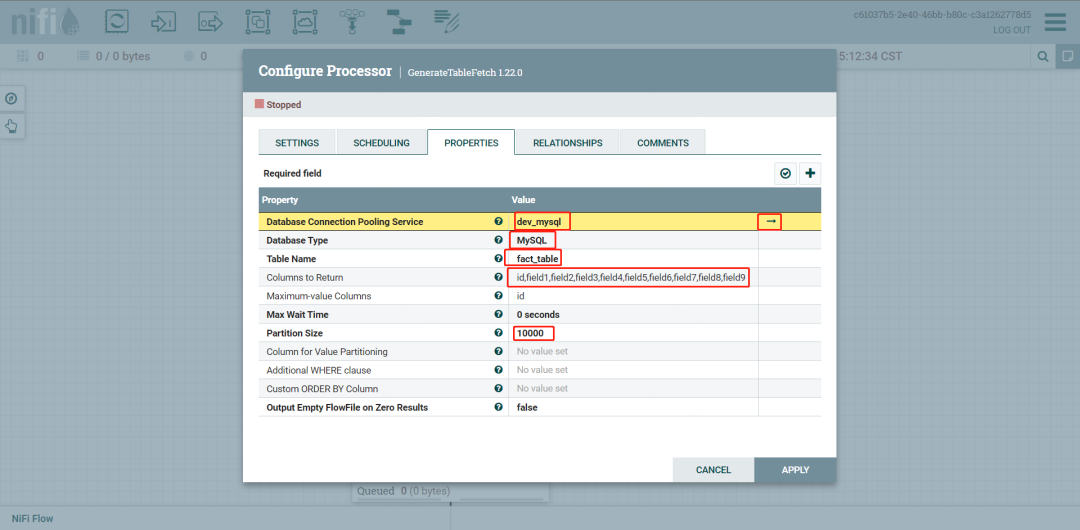
点击设置数据连接池
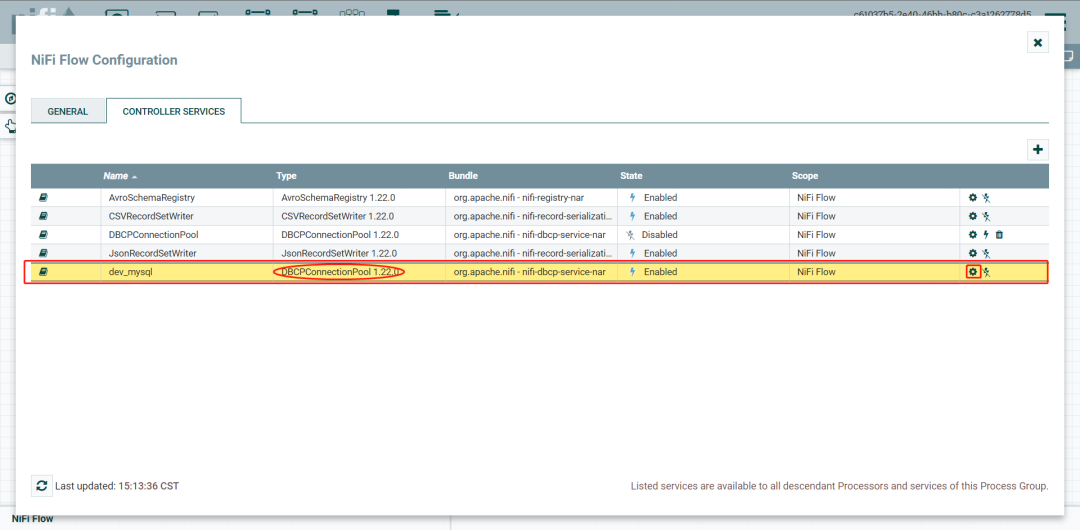
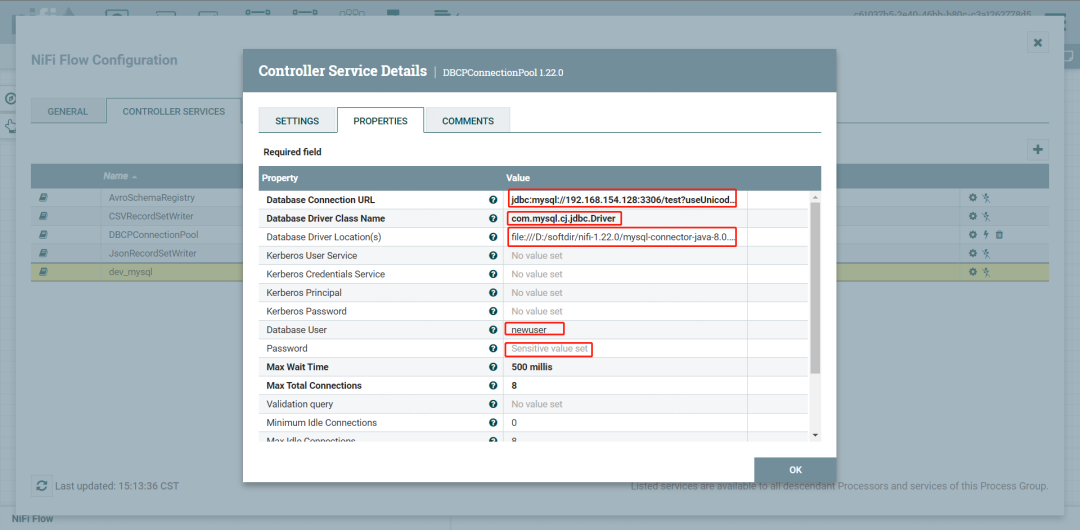
点击设置enable
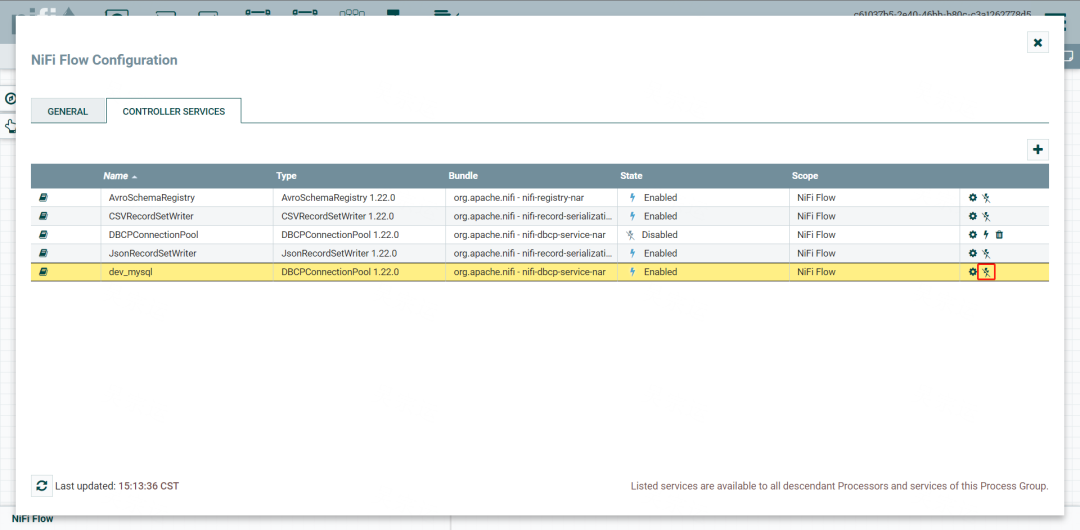
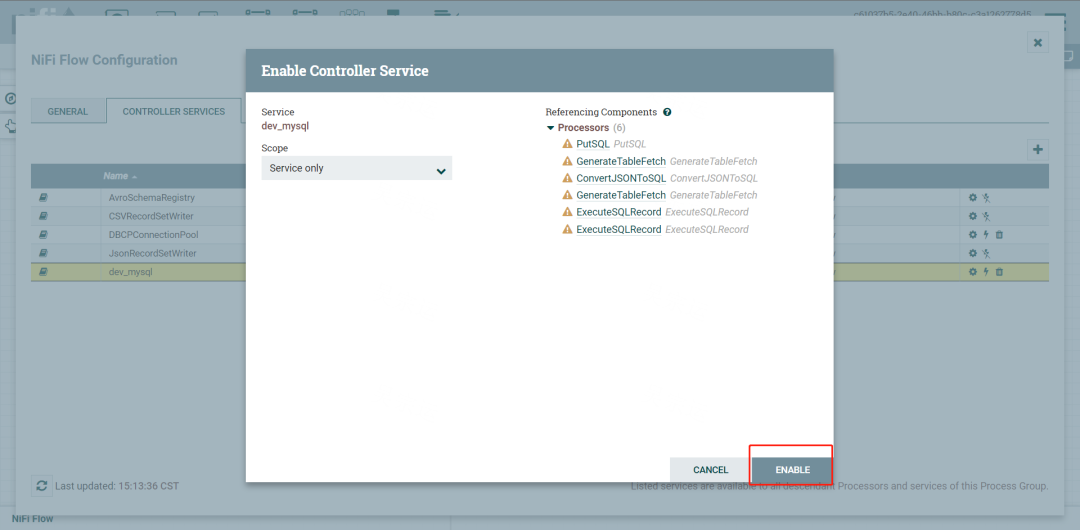
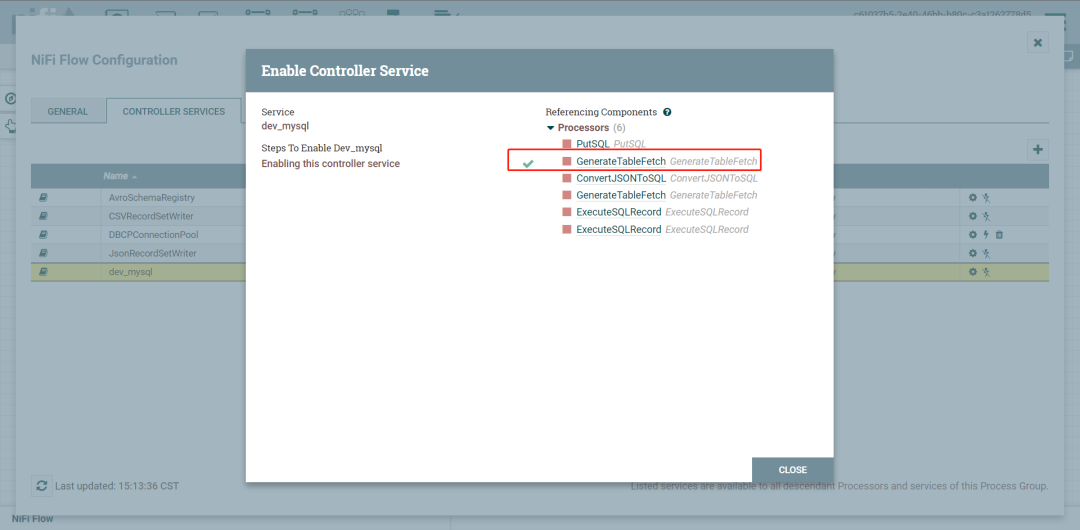
enable
2. 设置ExecteSQLRecord,用来将数据转成json
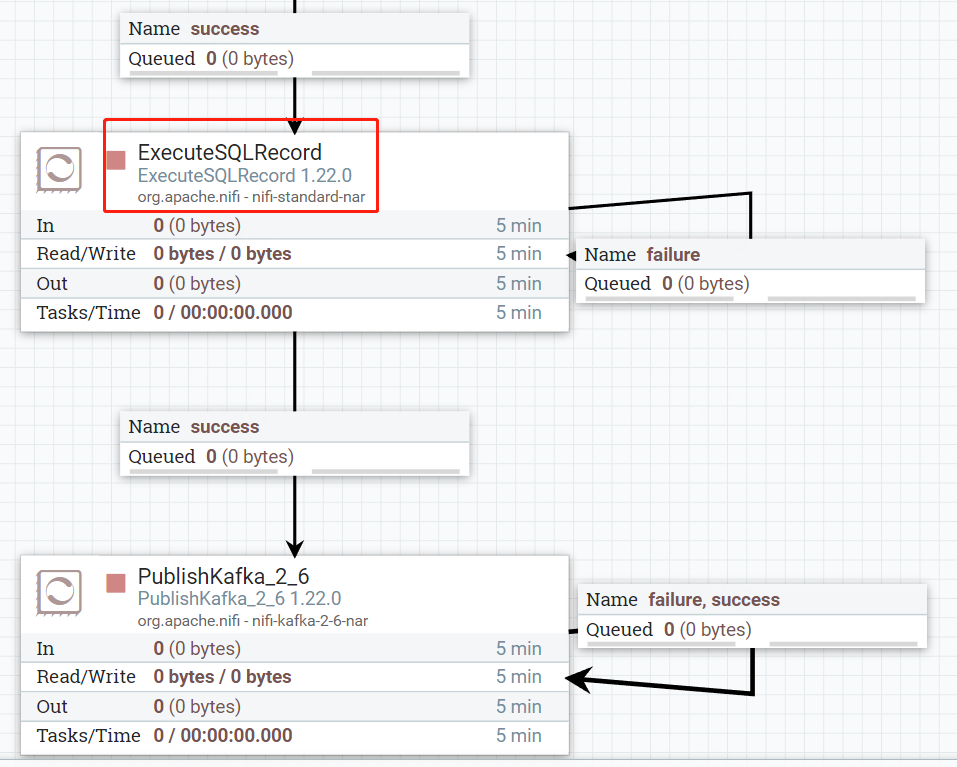
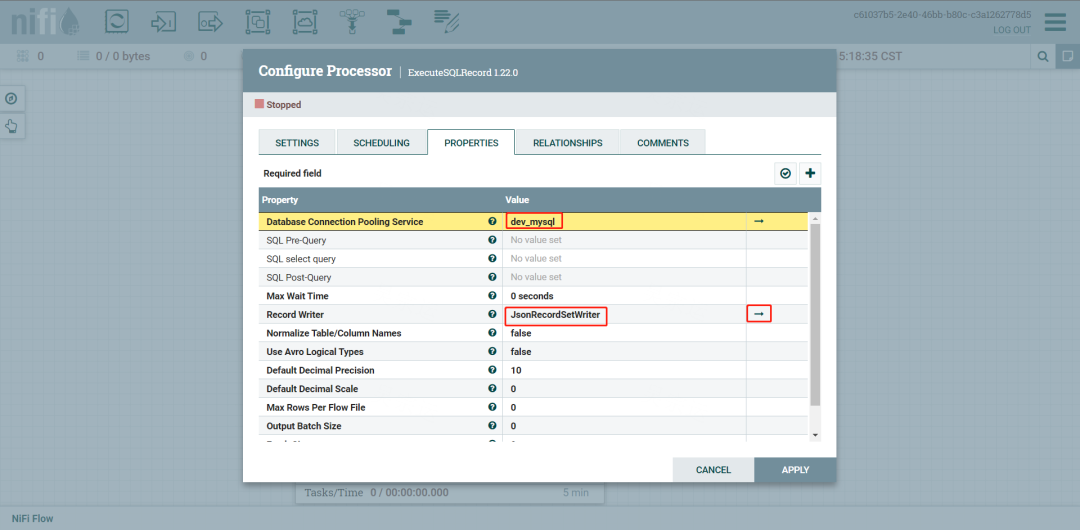
选择数据源,及Record Writer,我们选择JsonRecordSetWriter
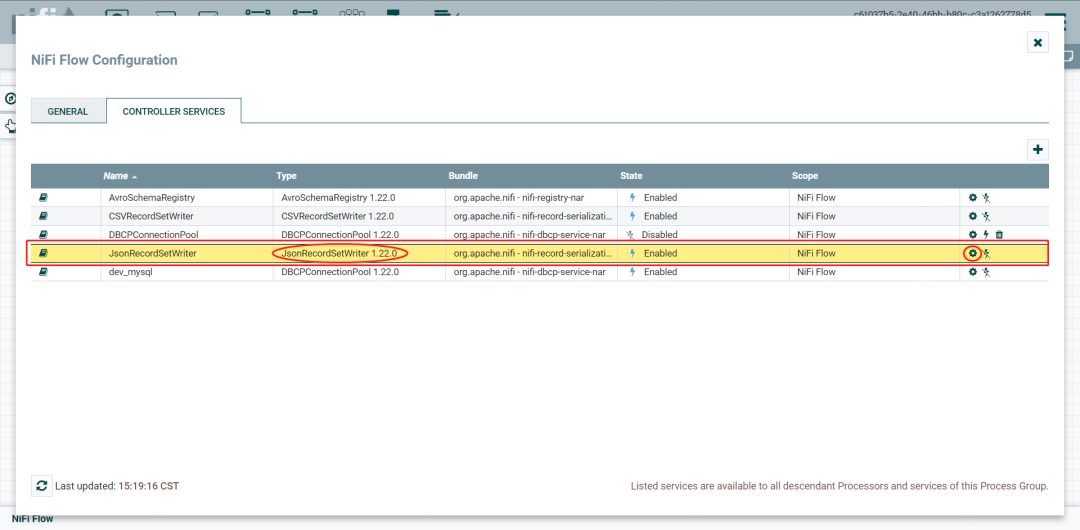
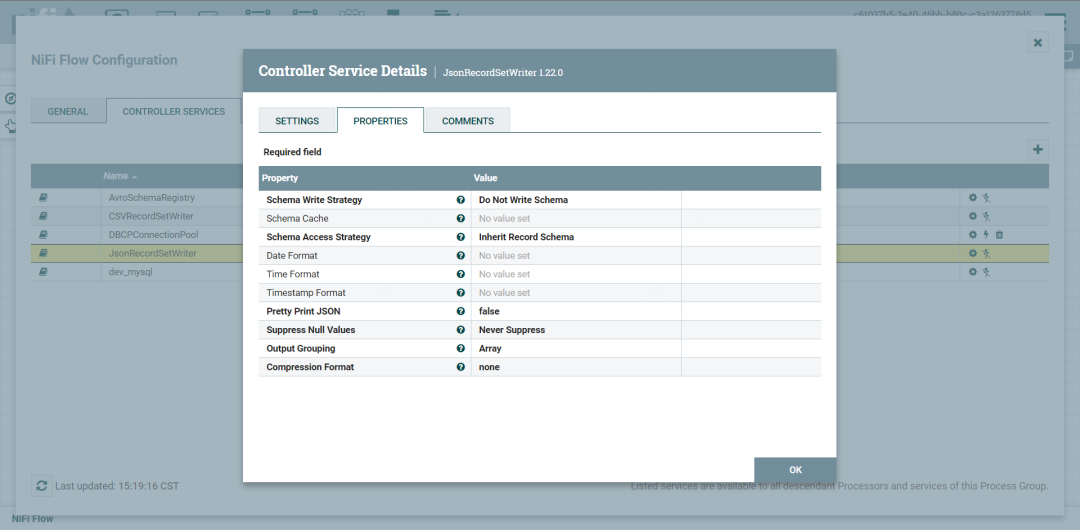
设置JsonRecordSetWriter
3.设置PublishKafka,用来向Kafka发送数据
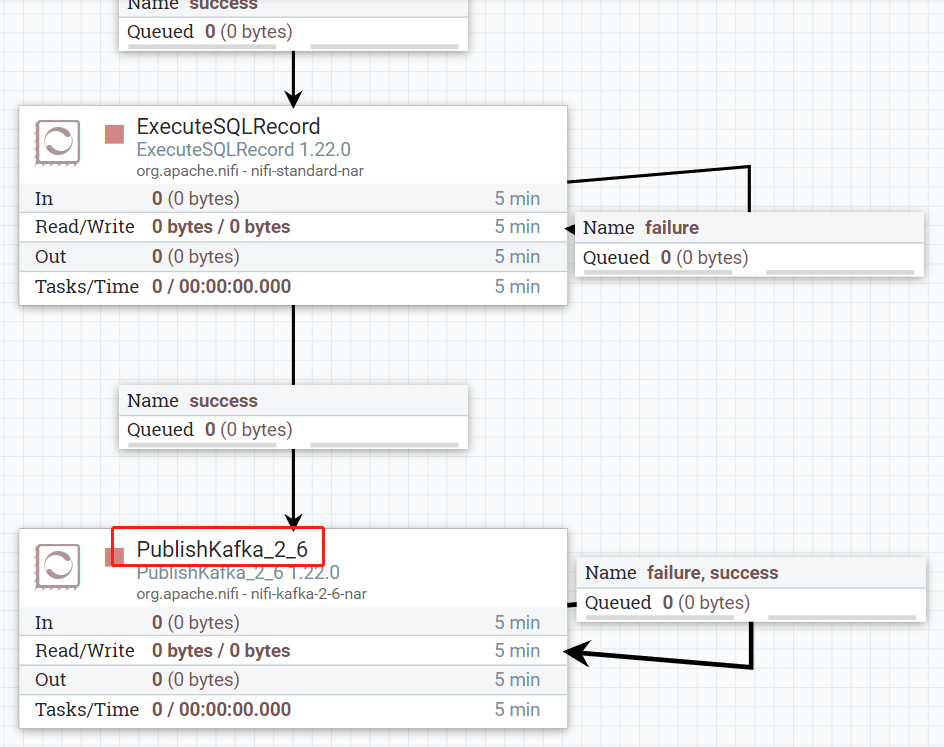
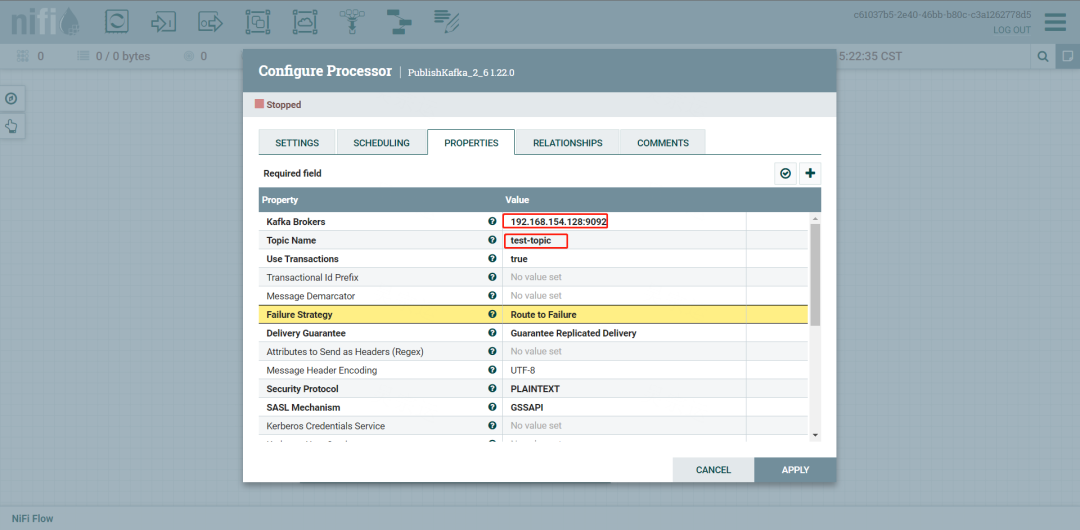
设置Broker、topic
使用kafka consumer可以查看发送过来的消息

4.设置ConsumerKafka,用来消费Kafka消息
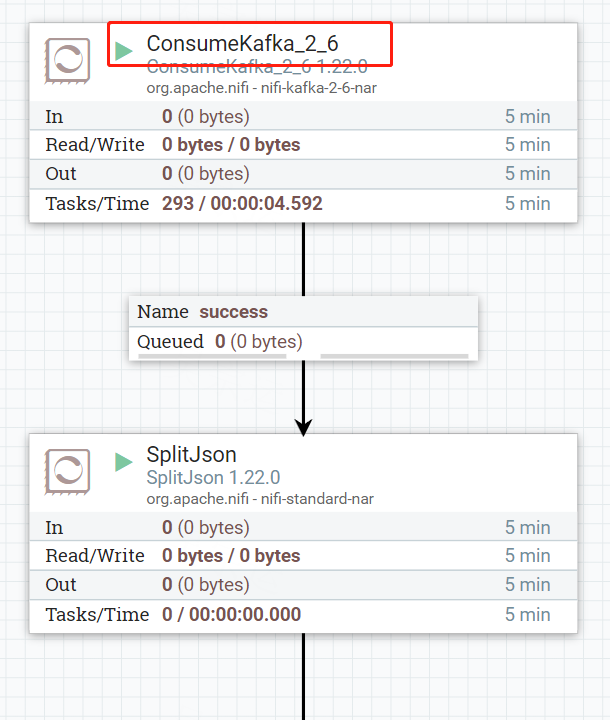
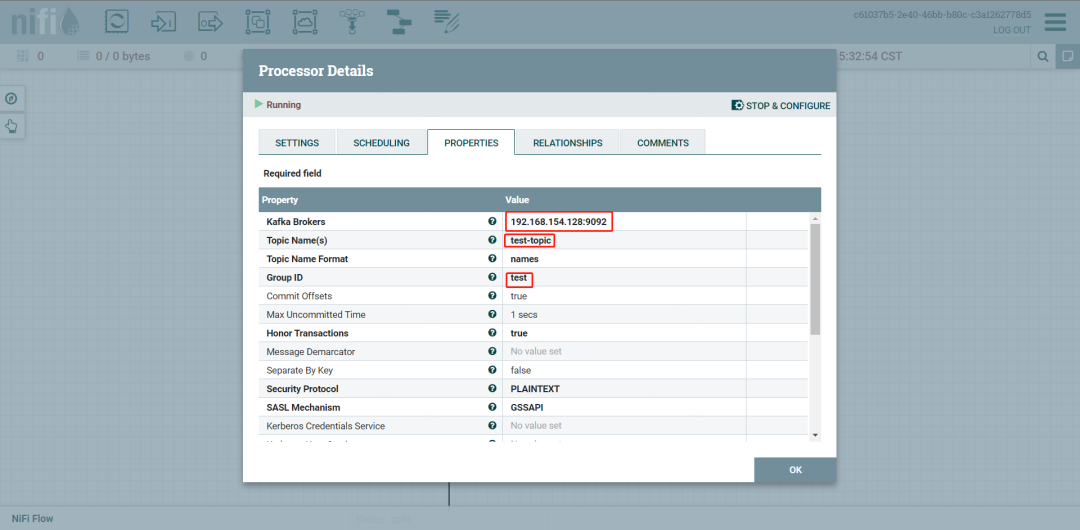
设置broker,topic
5.设置SplitJson,用来将数组中的JSON串切分出来
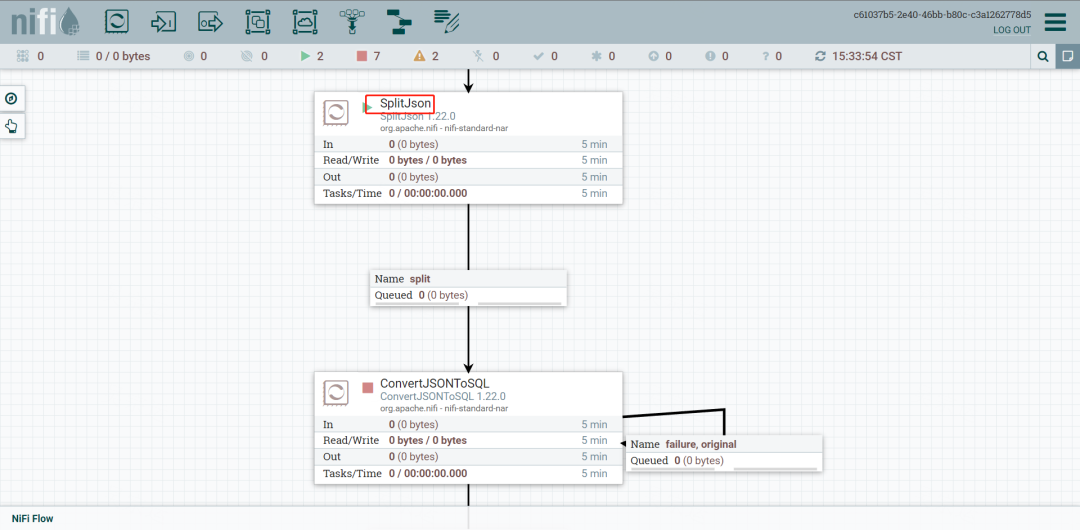
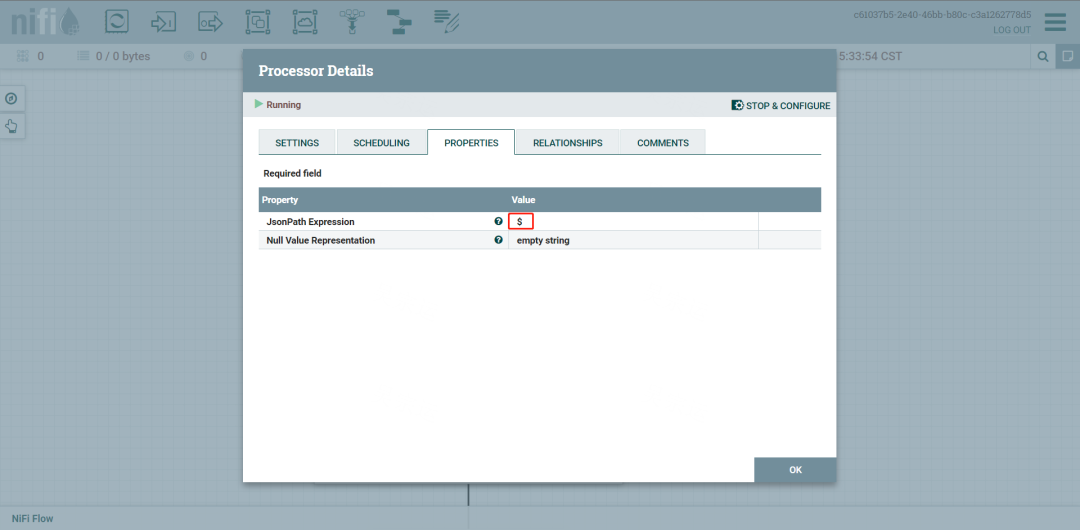
如果是根目录的话,穿参数$就可以,有其他KEY,可以用$.KEY
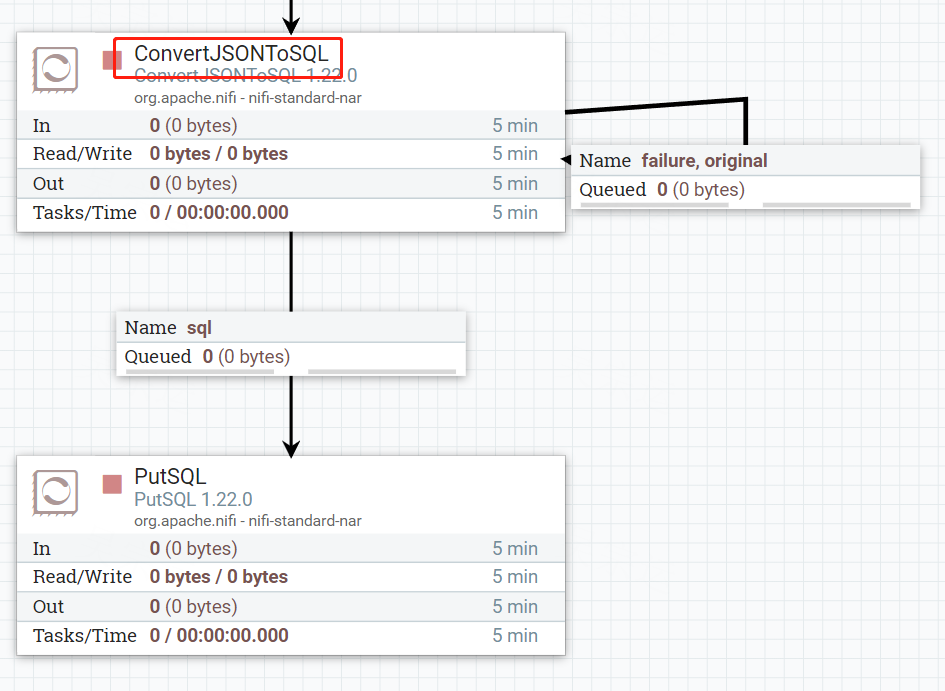
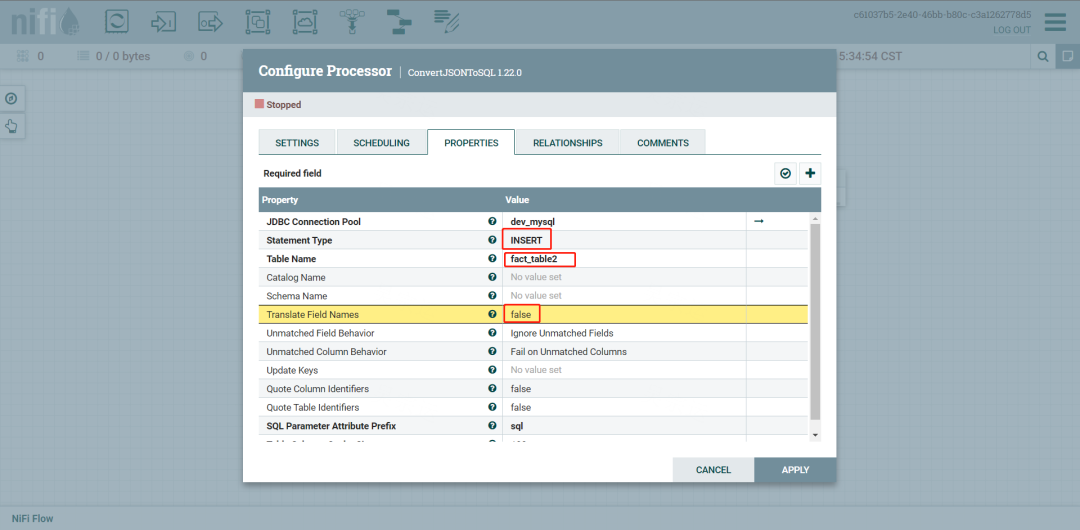
6.设置ConvertJSONToSQL,用来将JSON转成SQL
配置目标库、表,及写入方式
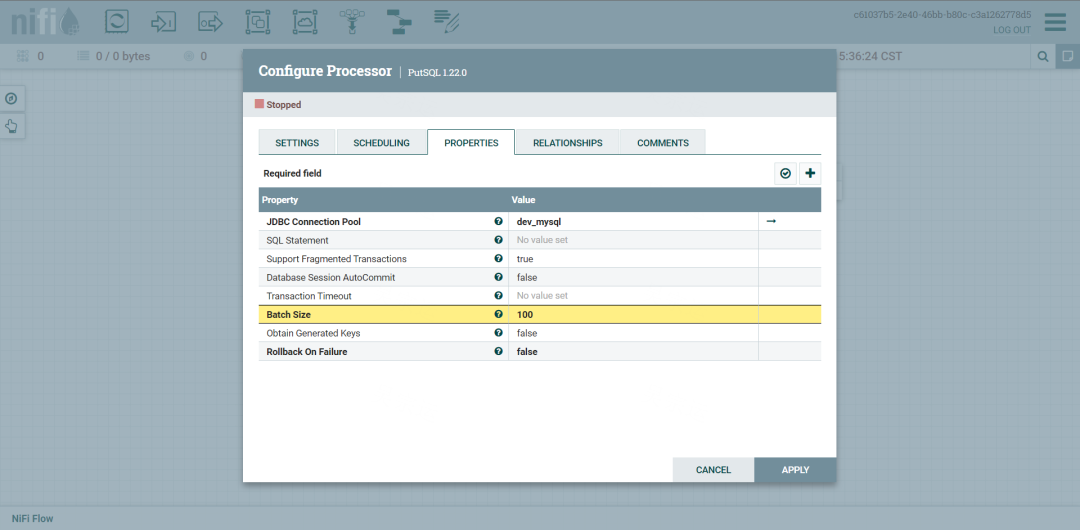
7.配置PutSQL,用来执行SQL
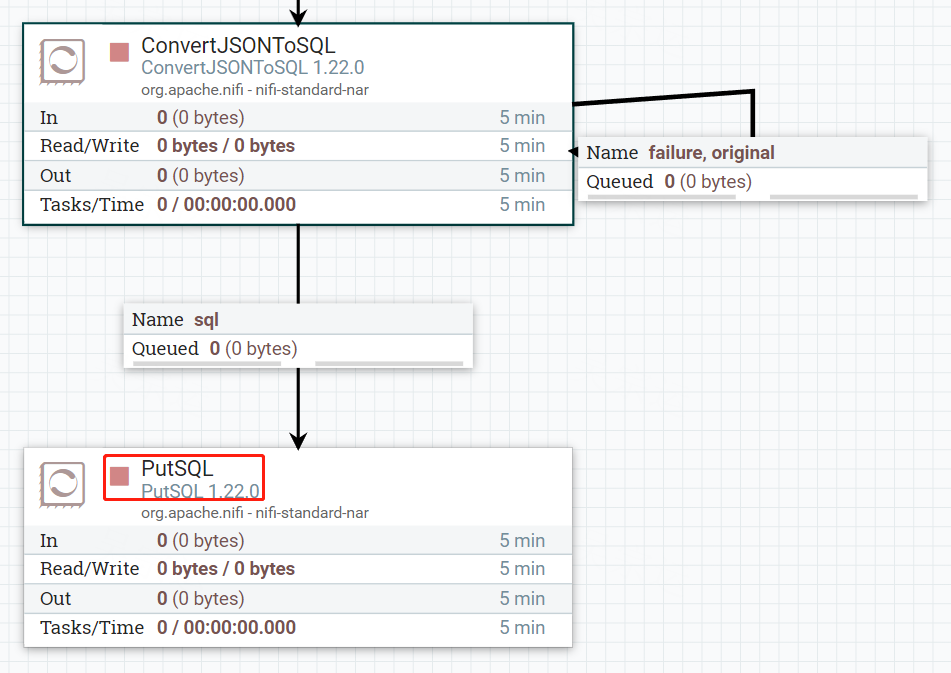
配置数据源即可
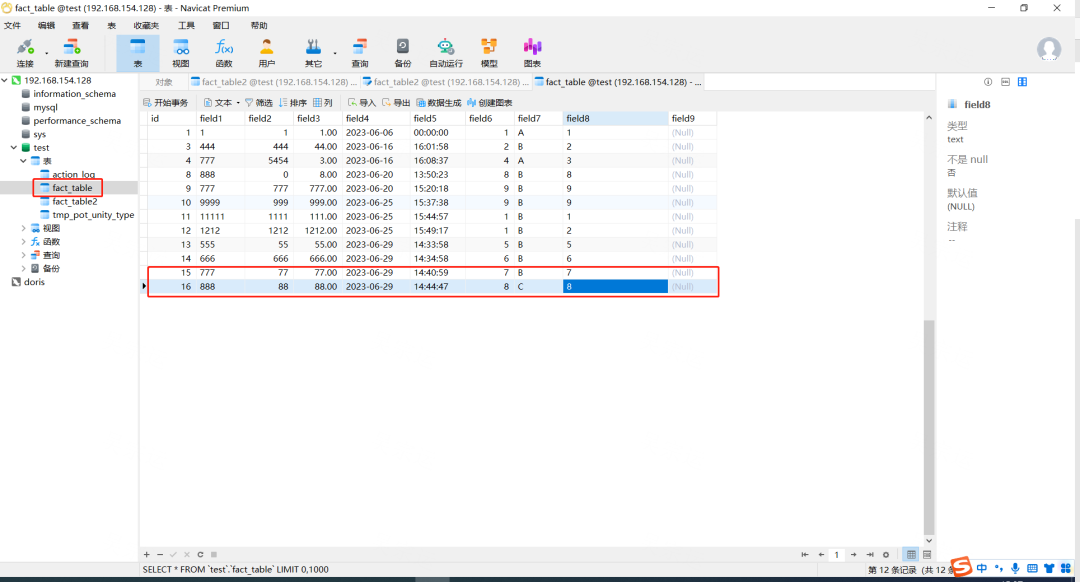
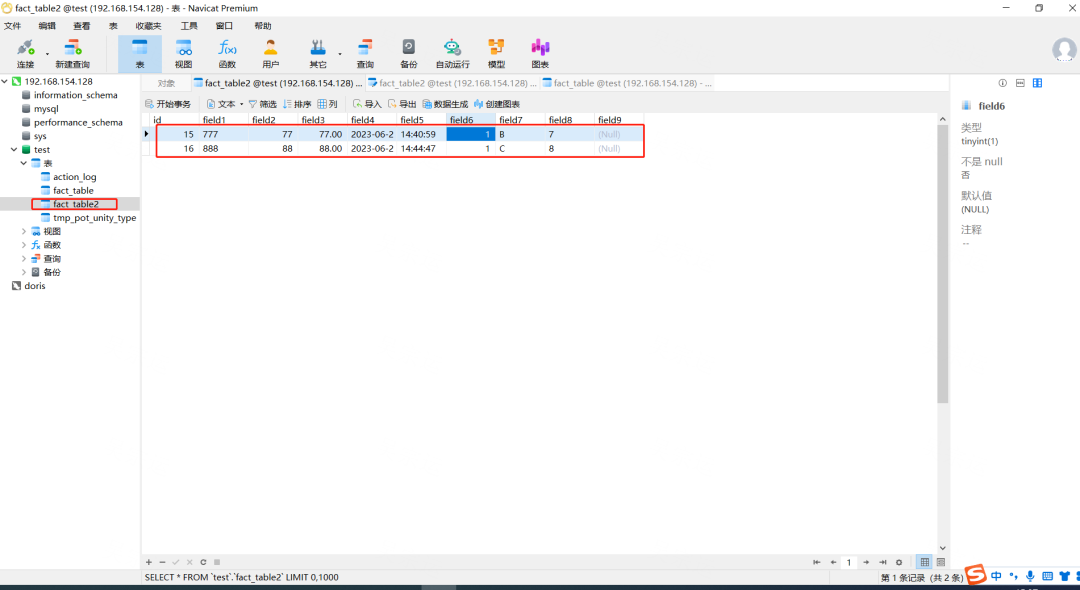
8.查看效果
9.配置全量抽取
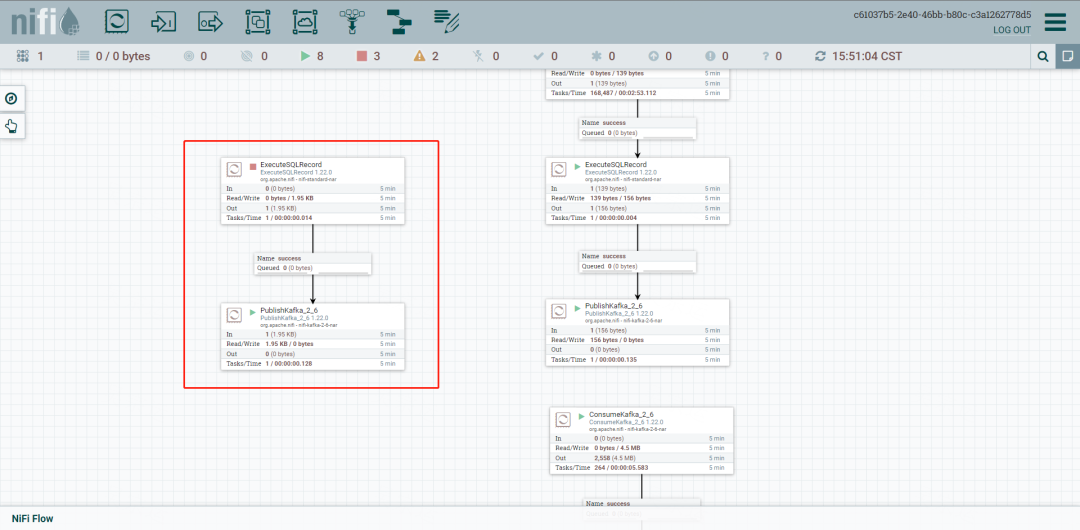
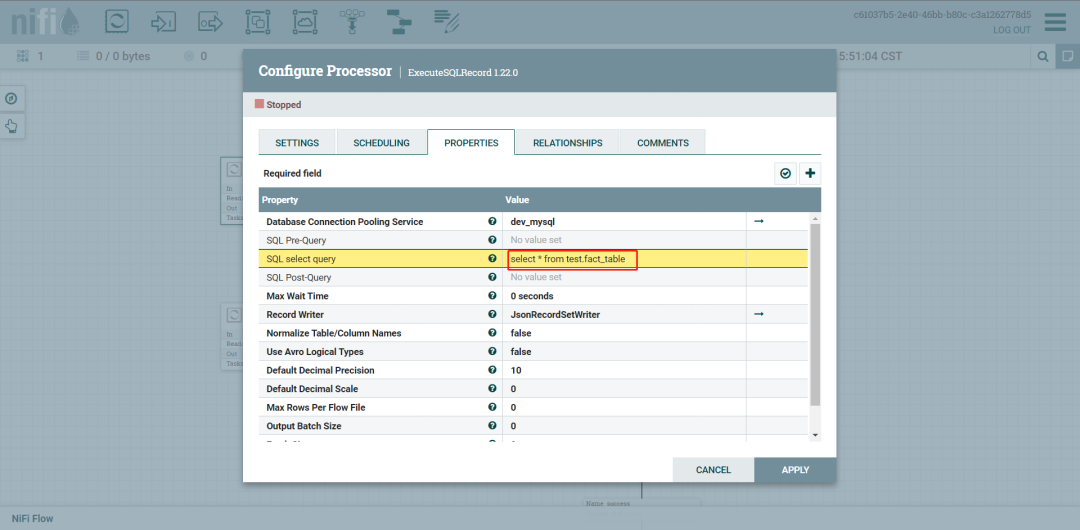
复制一个ExcuteSQLRecord 配置SQL select Query即可
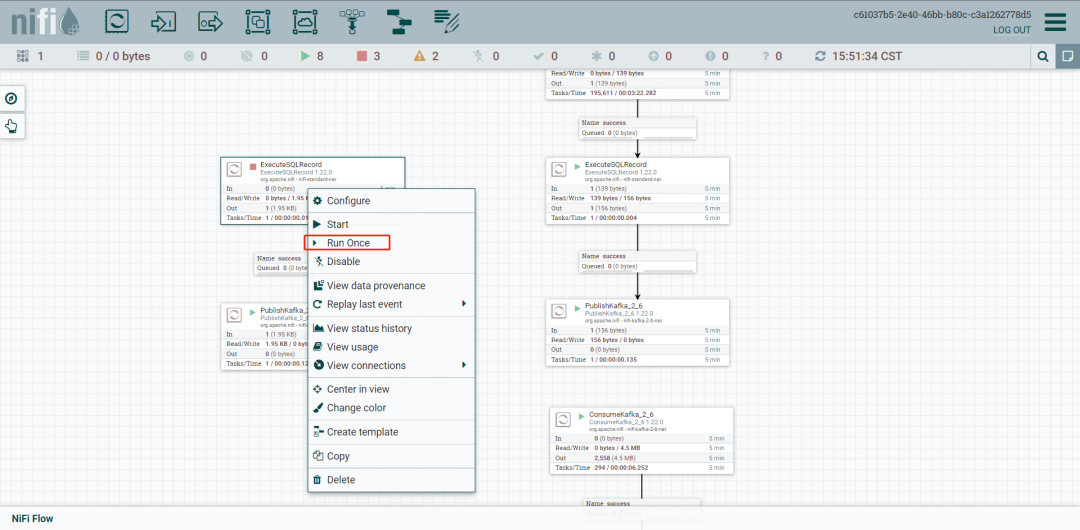
执行单次运行
10.查看效果
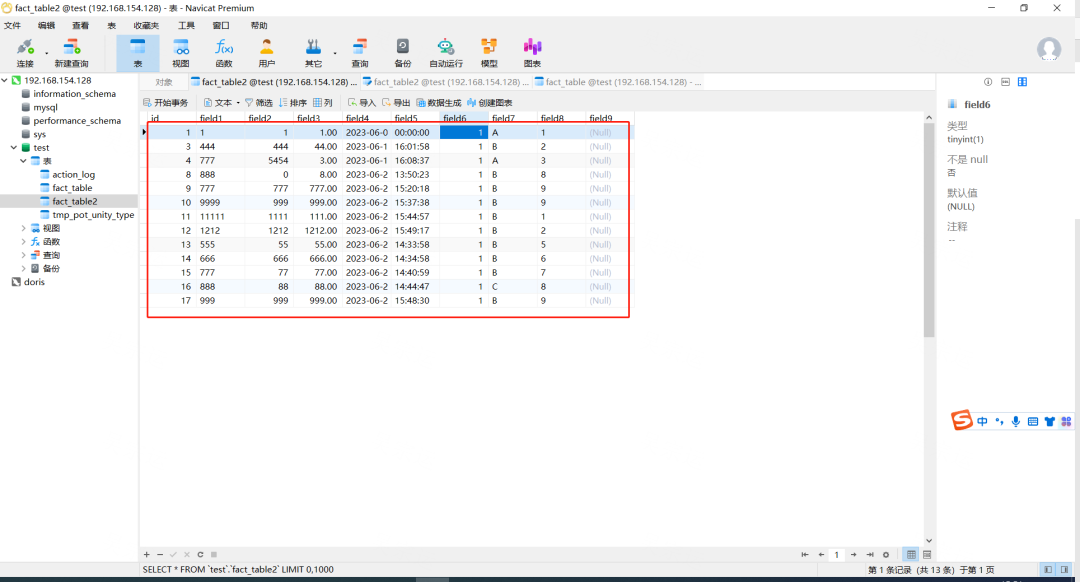
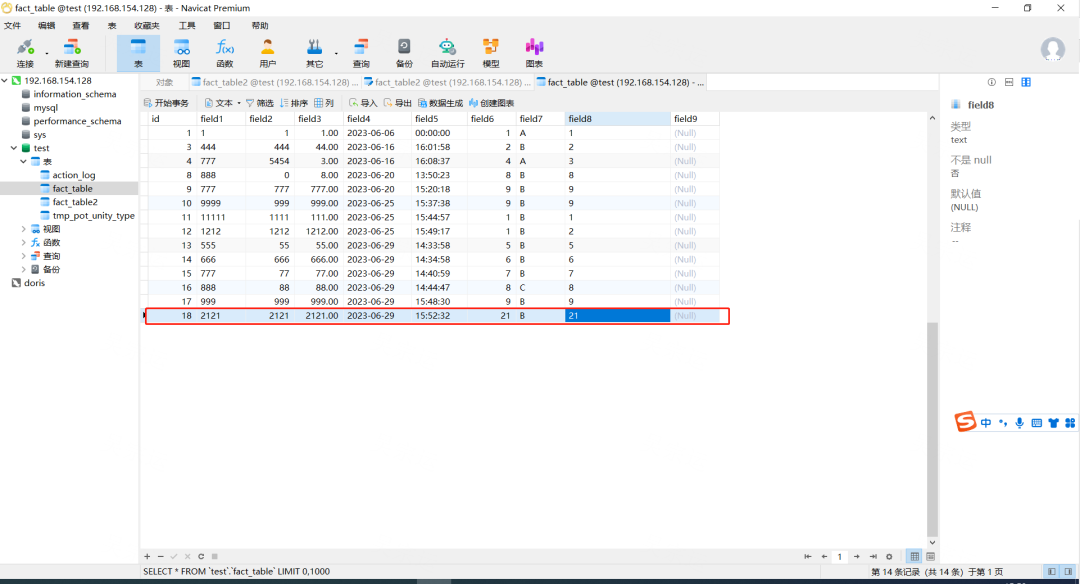
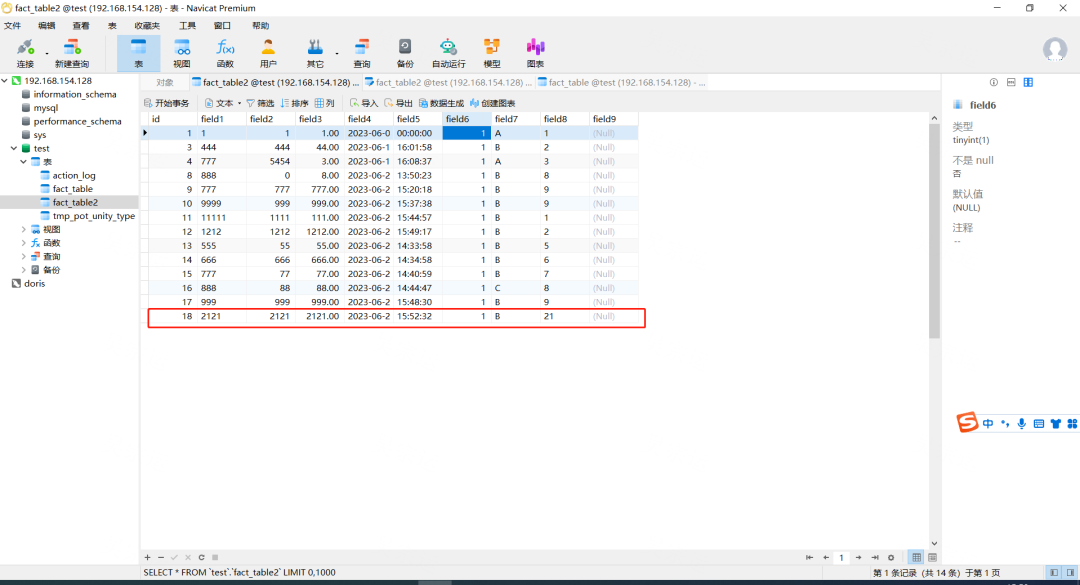
11. 测试表建表语句
-- test.fact_table definitionCREATE TABLE `fact_table` (`id` int NOT NULL AUTO_INCREMENT,`field1` varchar(255) DEFAULT NULL,`field2` int DEFAULT NULL,`field3` decimal(10,2) DEFAULT NULL,`field4` date DEFAULT NULL,`field5` time DEFAULT NULL,`field6` tinyint(1) DEFAULT NULL,`field7` enum('A','B','C') DEFAULT NULL,`field8` text,`field9` blob,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- test.fact_table2 definitionCREATE TABLE `fact_table2` (`id` int NOT NULL AUTO_INCREMENT,`field1` varchar(255) DEFAULT NULL,`field2` int DEFAULT NULL,`field3` decimal(10,2) DEFAULT NULL,`field4` date DEFAULT NULL,`field5` time DEFAULT NULL,`field6` tinyint(1) DEFAULT NULL,`field7` enum('A','B','C') DEFAULT NULL,`field8` text,`field9` blob,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
配置配置如图
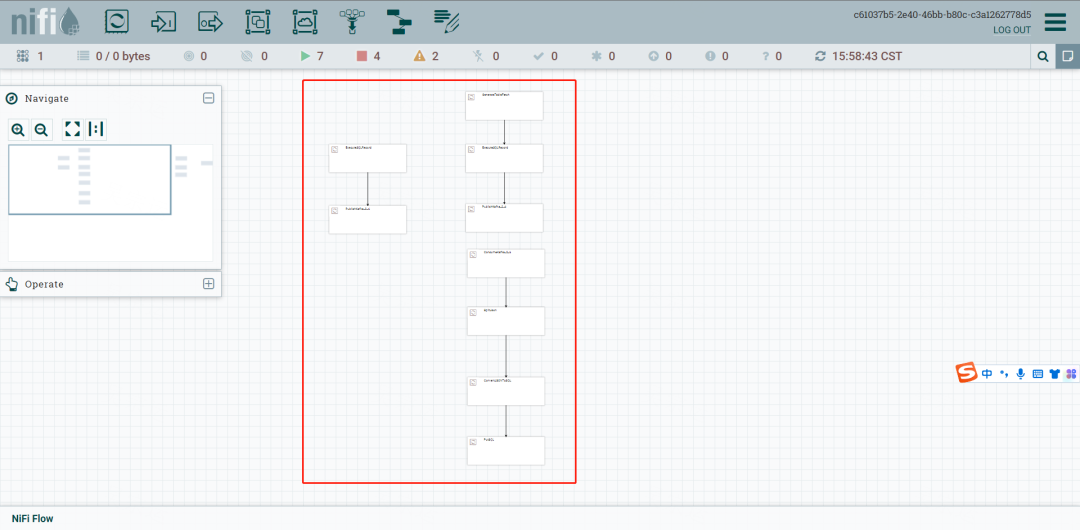
定时任务都配置成任务之间0S间隔,就能达到实时的效果
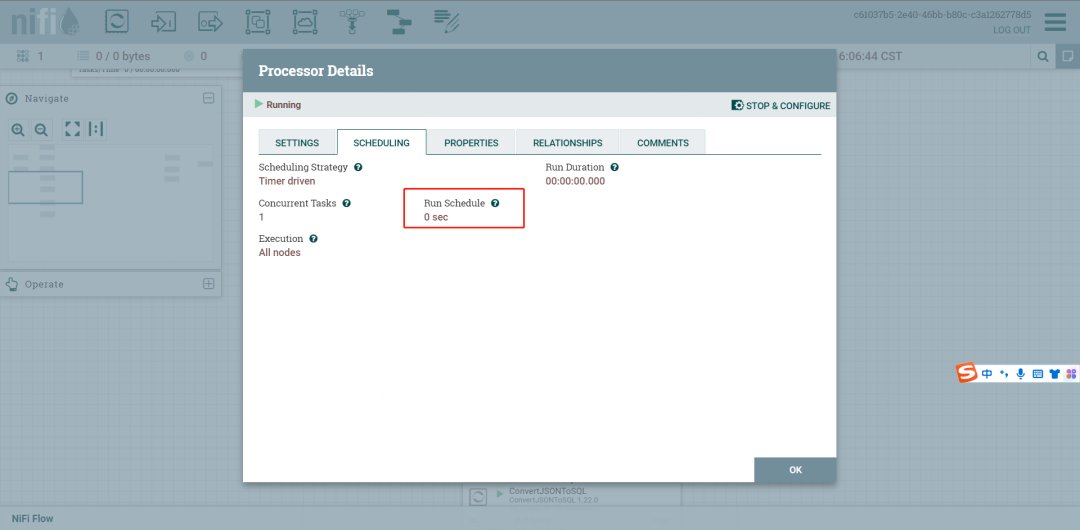
查看每个步骤之间的输出效果,可以停止下游执行器,让数据积累在关系中
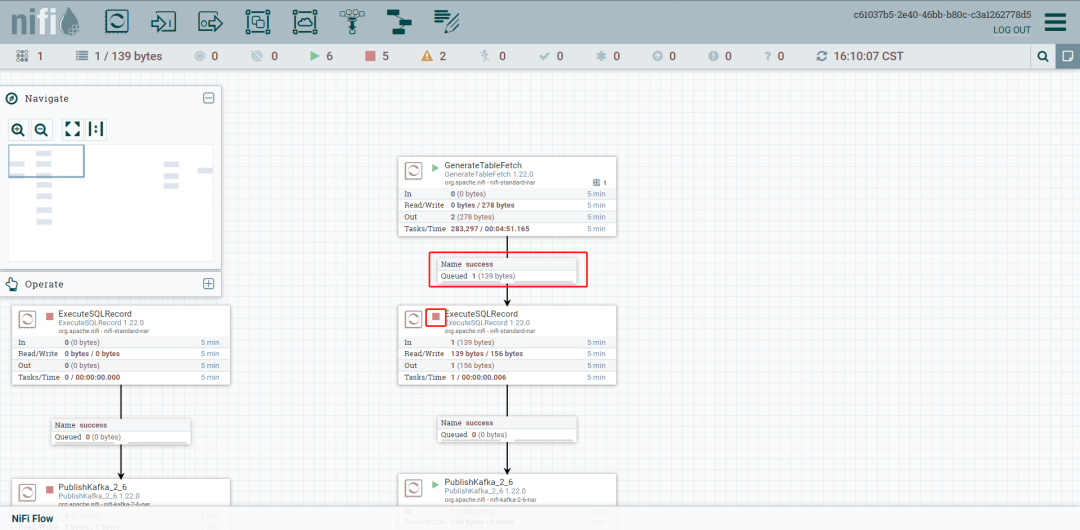
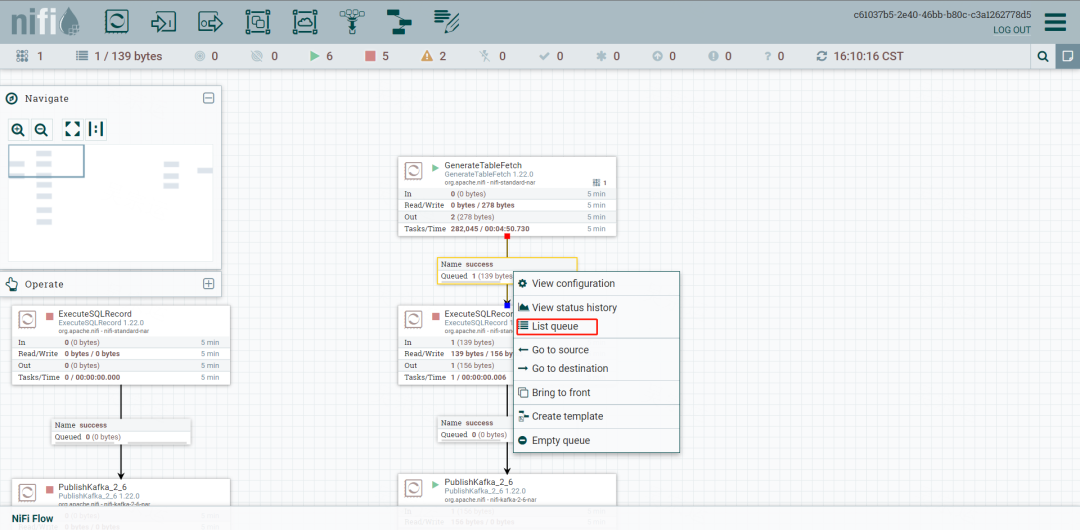
右键关系查看List Queue
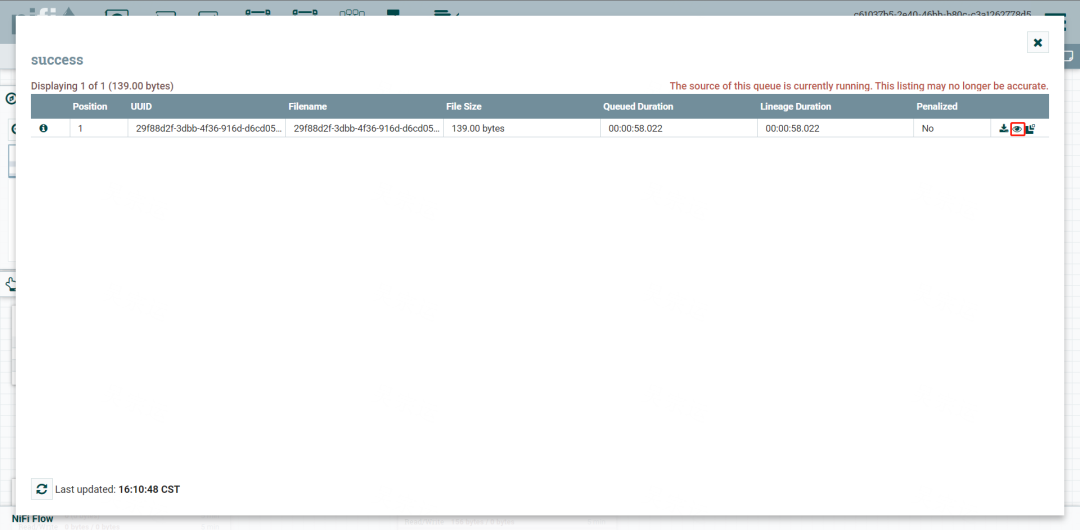
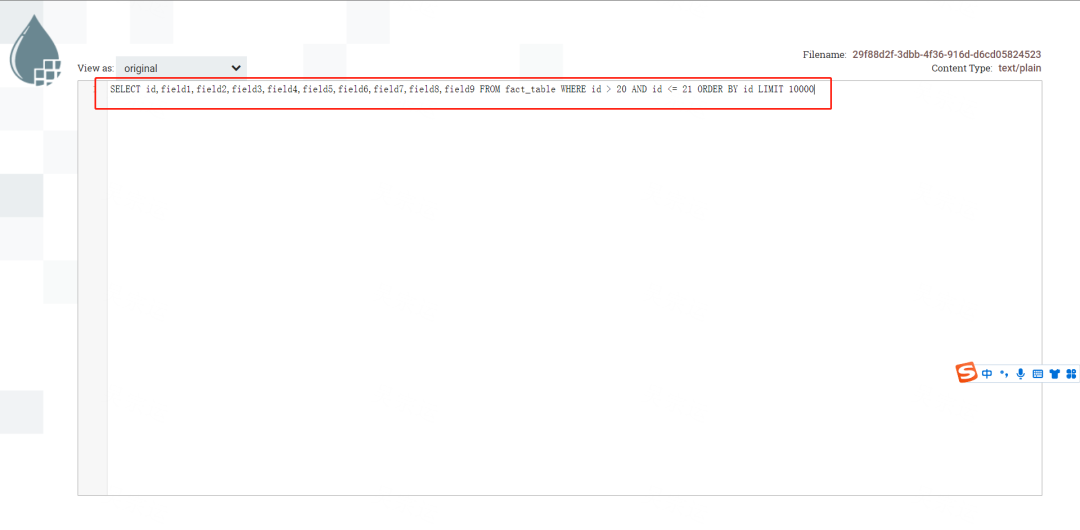
点击小眼睛查看数据内容
更多大数据相关内容请关注大数据技能圈公众号:
