




01
物化视图的使用场景
02
物化视图的分类
同步物化视图需要与基表的数据保持强一致性。 异步物化视图与基表的数据保持最终一致性,可能会有一定的延迟。它通常用于对数据时效性要求不高的场景,一般使用 T+1 或小时级别的数据来构建物化视图。如果时效性要求高,则考虑使用同步物化视图。
对于异步物化视图,可以使用单表或多表。 对于同步物化视图,只能使用单表。
对于异步物化视图
对于同步物化视图
这或许是一个对你有用的开源项目,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning
https://github.com/Mrkuhuo/data-warehouse-learning
https://bigdatacircle.top/
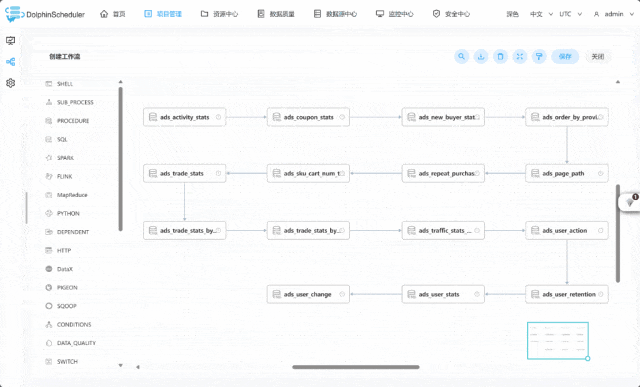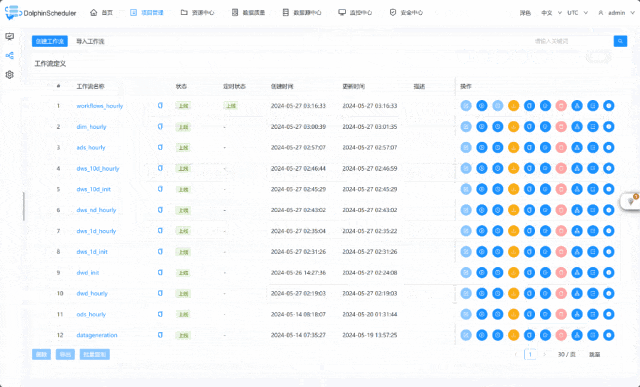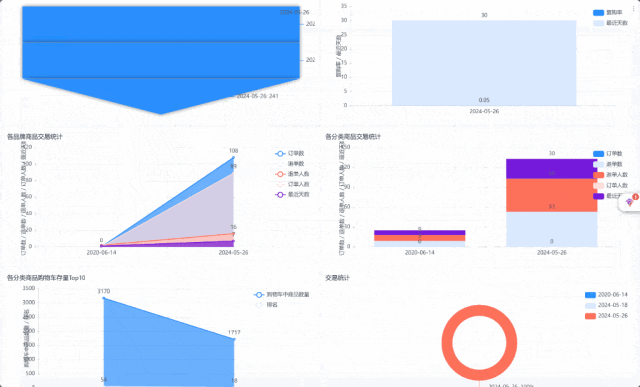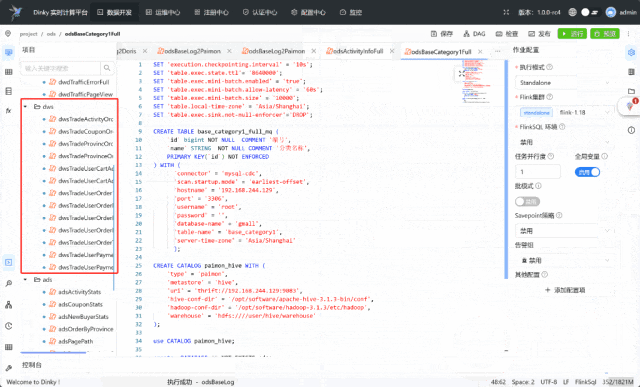
项目演示:
03
同步物化视图
加速耗时的聚合运算 查询需要匹配不同的前缀索引 通过预先过滤减少需要扫描的数据量 通过预先完成复杂的表达式计算来加速查询
同步物化视图只支持针对单个表的 SELECT 语句,支持 WHERE、GROUP BY、ORDER BY 等子句,但不支持 JOIN、HAVING、LIMIT 子句和 LATERAL VIEW。 与异步物化视图不同,不能直接查询同步物化视图。 SELECT 列表中,不能包含自增列,不能包含常量,不能有重复表达式,也不支持窗口函数。 如果 SELECT 列表包含聚合函数,则聚合函数必须是根表达式(不支持 sum(a) + 1,支持 sum(a + 1)),且聚合函数之后不能有其他非聚合函数表达式(例如,SELECT x, sum(a) 可以,而 SELECT sum(a), x 不行)。 如果删除语句的条件列在物化视图中存在,则不能进行删除操作。如果确实需要删除数据,则需要先将物化视图删除,然后才能删除数据。 单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和 Base 表的数据是同步更新的。如果一张表的物化视图表过多,可能会导致导入速度变慢,这就像单次导入需要同时导入多张表的数据一样。 物化视图针对 Unique Key 数据模型时,只能改变列的顺序,不能起到聚合的作用。因此,在 Unique Key 模型上不能通过创建物化视图的方式对数据进行粗粒度的聚合操作。
-- 创建一个 test_dbcreate database test_db;use test_db;-- 创建表create table sales_records(record_id int,seller_id int,store_id int,sale_date date,sale_amt bigint)distributed by hash(record_id)properties("replication_num" = "1");-- 插入数据insert into sales_records values(1,1,1,'2020-02-02',1);
create materialized view store_amt asselect store_id, sum(sale_amt) from sales_records group by store_id;
show alter table materialized view from test_db;
+--------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+| JobId | TableName | CreateTime | FinishTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |+--------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+| 494349 | sales_records | 2020-07-30 20:04:56 | 2020-07-30 20:04:57 | sales_records | store_amt | 494350 | 133107 | FINISHED | | NULL | 2592000 |+--------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
cancel alter table materialized view from test_db.sales_records;
desc sales_records all;
+---------------+---------------+---------------------+--------+--------------+------+-------+---------+-------+---------+------------+-------------+| IndexName | IndexKeysType | Field | Type | InternalType | Null | Key | Default | Extra | Visible | DefineExpr | WhereClause |+---------------+---------------+---------------------+--------+--------------+------+-------+---------+-------+---------+------------+-------------+| sales_records | DUP_KEYS | record_id | INT | INT | Yes | true | NULL | | true | | || | | seller_id | INT | INT | Yes | true | NULL | | true | | || | | store_id | INT | INT | Yes | true | NULL | | true | | || | | sale_date | DATE | DATEV2 | Yes | false | NULL | NONE | true | | || | | sale_amt | BIGINT | BIGINT | Yes | false | NULL | NONE | true | | || | | | | | | | | | | | || store_amt | AGG_KEYS | mv_store_id | INT | INT | Yes | true | NULL | | true | `store_id` | || | | mva_SUM__`sale_amt` | BIGINT | BIGINT | Yes | false | NULL | SUM | true | `sale_amt` | |+---------------+---------------+---------------------+--------+--------------+------+-------+---------+-------+---------+------------+-------------+
show create materialized view store_amt on sales_records;
+---------------+-----------+------------------------------------------------------------------------------------------------------------+| TableName | ViewName | CreateStmt |+---------------+-----------+------------------------------------------------------------------------------------------------------------+| sales_records | store_amt | create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id |+---------------+-----------+------------------------------------------------------------------------------------------------------------+
select store_id, sum(sale_amt) from sales_records group by store_id;
explain select store_id, sum(sale_amt) from sales_records group by store_id;
+-----------------------------------------------------------------------------------------------+| Explain String(Nereids Planner) |+-----------------------------------------------------------------------------------------------+| PLAN FRAGMENT 0 || OUTPUT EXPRS: || store_id[#11] || sum(sale_amt)[#12] || PARTITION: HASH_PARTITIONED: mv_store_id[#7] || || HAS_COLO_PLAN_NODE: false || || VRESULT SINK || MYSQL_PROTOCAL || || 3:VAGGREGATE (merge finalize)(145) || | output: sum(partial_sum(mva_SUM__sale_amt)[#8])[#10] || | group by: mv_store_id[#7] || | sortByGroupKey:false || | cardinality=1 || | final projections: mv_store_id[#9], sum(mva_SUM__sale_amt)[#10] || | final project output tuple id: 4 || | distribute expr lists: mv_store_id[#7] || | || 2:VEXCHANGE || offset: 0 || distribute expr lists: || || PLAN FRAGMENT 1 || || PARTITION: HASH_PARTITIONED: record_id[#2] || || HAS_COLO_PLAN_NODE: false || || STREAM DATA SINK || EXCHANGE ID: 02 || HASH_PARTITIONED: mv_store_id[#7] || || 1:VAGGREGATE (update serialize)(139) || | STREAMING || | output: partial_sum(mva_SUM__sale_amt[#1])[#8] || | group by: mv_store_id[#0] || | sortByGroupKey:false || | cardinality=1 || | distribute expr lists: || | || 0:VOlapScanNode(136) || TABLE: test_db.sales_records(store_amt), PREAGGREGATION: ON || partitions=1/1 (sales_records) || tablets=10/10, tabletList=494505,494507,494509 ... || cardinality=1, avgRowSize=0.0, numNodes=1 || pushAggOp=NONE || || || Statistics || planed with unknown column statistics |+-----------------------------------------------------------------------------------------------+
drop materialized view store_amt on sales_records;
04
异步物化视图
CREATE TABLE `t1` (`user_id` LARGEINT NOT NULL,`o_date` DATE NOT NULL,`num` SMALLINT NOT NULL) ENGINE=OLAPCOMMENT 'OLAP'PARTITION BY RANGE(`o_date`)(PARTITION p20170101 VALUES [('2017-01-01'), ('2017-01-02')),PARTITION p20170102 VALUES [('2017-01-02'), ('2017-01-03')),PARTITION p20170201 VALUES [('2017-02-01'), ('2017-02-02')))DISTRIBUTED BY HASH(`user_id`) BUCKETS 2PROPERTIES ('replication_num' = '1') ;CREATE TABLE `t2` (`user_id` LARGEINT NOT NULL,`age` SMALLINT NOT NULL) ENGINE=OLAPPARTITION BY LIST(`age`)(PARTITION `p1` VALUES IN ('1'),PARTITION `p2` VALUES IN ('2'))DISTRIBUTED BY HASH(`user_id`) BUCKETS 2PROPERTIES ('replication_num' = '1') ;
CREATE MATERIALIZED VIEW mv1BUILD DEFERRED REFRESH AUTO ON MANUALpartition by(`order_date`)DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT t1.o_date as order_date, t1.user_id as user_id, t1.num, t2.age FROM t1 join t2 on t1.user_id=t2.user_id;
[('2017-01-01'), ('2017-01-02')) [('2017-01-02'), ('2017-01-03')) [('2017-02-01'), ('2017-02-02'))
CREATE MATERIALIZED VIEW mv2BUILD DEFERRED REFRESH AUTO ON MANUALpartition by(`age`)DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT t1.o_date as order_date, t1.user_id as user_id, t1.num, t2.age FROM t1 join t2 on t1.user_id=t2.user_id;
('1') ('2')
CREATE TABLE hive1 (`k1` int)PARTITIONED BY (`year` int,`region` string)STORED AS ORC;alter table hive1 add if not existspartition(year=2020,region="bj")partition(year=2020,region="sh")partition(year=2021,region="bj")partition(year=2021,region="sh")partition(year=2022,region="bj")partition(year=2022,region="sh")
CREATE MATERIALIZED VIEW mv_hiveBUILD DEFERRED REFRESH AUTO ON MANUALpartition by(`year`)DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT k1,year,region FROM hive1;
CREATE MATERIALIZED VIEW mv_hive2BUILD DEFERRED REFRESH AUTO ON MANUALpartition by(`region`)DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT k1,year,region FROM hive1;
CREATE TABLE t1 (`k1` INT,`k2` DATE NOT NULL) ENGINE=OLAPDUPLICATE KEY(`k1`)COMMENT 'OLAP'PARTITION BY range(`k2`)(PARTITION p26 VALUES [("2024-03-26"),("2024-03-27")),PARTITION p27 VALUES [("2024-03-27"),("2024-03-28")),PARTITION p28 VALUES [("2024-03-28"),("2024-03-29")))DISTRIBUTED BY HASH(`k1`) BUCKETS 2PROPERTIES ('replication_num' = '1');
CREATE MATERIALIZED VIEW mv1BUILD DEFERRED REFRESH AUTO ON MANUALpartition by(`k2`)DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1','partition_sync_limit'='1','partition_sync_time_unit'='DAY')ASSELECT * FROM t1;
List 分区
CREATE TABLE `t1` (`k1` INT NOT NULL,`k2` DATE NOT NULL) ENGINE=OLAPDUPLICATE KEY(`k1`)COMMENT 'OLAP'PARTITION BY list(`k2`)(PARTITION p_20200101 VALUES IN ("2020-01-01"),PARTITION p_20200102 VALUES IN ("2020-01-02"),PARTITION p_20200201 VALUES IN ("2020-02-01"))DISTRIBUTED BY HASH(`k1`) BUCKETS 2PROPERTIES ('replication_num' = '1') ;
CREATE MATERIALIZED VIEW mv1BUILD DEFERRED REFRESH AUTO ON MANUALpartition by (date_trunc(`k2`,'month'))DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT * FROM t1;
CREATE MATERIALIZED VIEW mv1BUILD DEFERRED REFRESH AUTO ON MANUALpartition by (date_trunc(`k2`,'year'))DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT * FROM t1;
Range 分区
CREATE TABLE `t1` (`k1` LARGEINT NOT NULL,`k2` DATE NOT NULL) ENGINE=OLAPDUPLICATE KEY(`k1`)COMMENT 'OLAP'PARTITION BY range(`k2`)(PARTITION p_20200101 VALUES [("2020-01-01"),("2020-01-02")),PARTITION p_20200102 VALUES [("2020-01-02"),("2020-01-03")),PARTITION p_20200201 VALUES [("2020-02-01"),("2020-02-02")))DISTRIBUTED BY HASH(`k1`) BUCKETS 2PROPERTIES ('replication_num' = '1') ;
CREATE MATERIALIZED VIEW mv1BUILD DEFERRED REFRESH AUTO ON MANUALpartition by (date_trunc(`k2`,'month'))DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT * FROM t1;
CREATE MATERIALIZED VIEW mv1BUILD DEFERRED REFRESH AUTO ON MANUALpartition by (date_trunc(`k2`,'year'))DISTRIBUTED BY RANDOM BUCKETS 2PROPERTIES ('replication_num' = '1')ASSELECT * FROM t1;
REFRESH MATERIALIZED VIEW mvName AUTO;
REFRESH MATERIALIZED VIEW mvName COMPLETE;
REFRESH MATERIALIZED VIEW mvName partitions(partitionName1,partitionName2);
CREATE MATERIALIZED VIEW mv1REFRESH COMPLETE ON SCHEDULE EVERY 10 hourpartition by(`xxx`)ASselect ...;
CREATE MATERIALIZED VIEW mv1REFRESH AUTO ON SCHEDULE EVERY 10 hourpartition by(`xxx`)ASselect ...;
4.2.3 自动触发
CREATE MATERIALIZED VIEW mv1REFRESH ON COMMITpartition by(`xxx`)ASselect ... from t1;
05
进交流群群添加作者

推荐阅读系列文章
建议收藏 | Dinky系列总结篇 建议收藏 | Flink系列总结篇 建议收藏 | Flink CDC 系列总结篇 建议收藏 | Doris实战文章汇总
如果喜欢 请点个在看分享给身边的朋友
文章转载自大数据技能圈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
