




01
项目发展历史
2013-2017
■ 百度研发实时数仓平台Palo,采用列存和MPP查询引擎,最初应用在百度统计、广告报表分析场景
■ 推广到百度所有业务线,正式成为百度统一的实时数仓
2018-2021
■ Palo开源,并成为Apache基金会孵化器项目,更名为ApacheDoris
■ Apache Doris 被数百家企业应用在生产系统,包含美团、京东、小米、字节、华为、腾讯等公司
2022-至今
■ 2022年1月,Doris团队创建飞轮科技(SELECTDB),大力建设开源社区并提供商业化产品和服务支持
■ 2022年6月,孵化毕业,成为Apache顶级项目(TLP)
■ 2000多家中大企业使用,9000+star,550+多开发者,是目前最活跃、最受欢迎的开源大数据项目
这里留个彩蛋,为什么刚开始会叫Palo(最后评论区我会公布答案)
这或许是一个对你有用的开源项目,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning
https://github.com/Mrkuhuo/data-warehouse-learning
https://bigdatacircle.top/
项目演示:
02
在数据分析中的定位
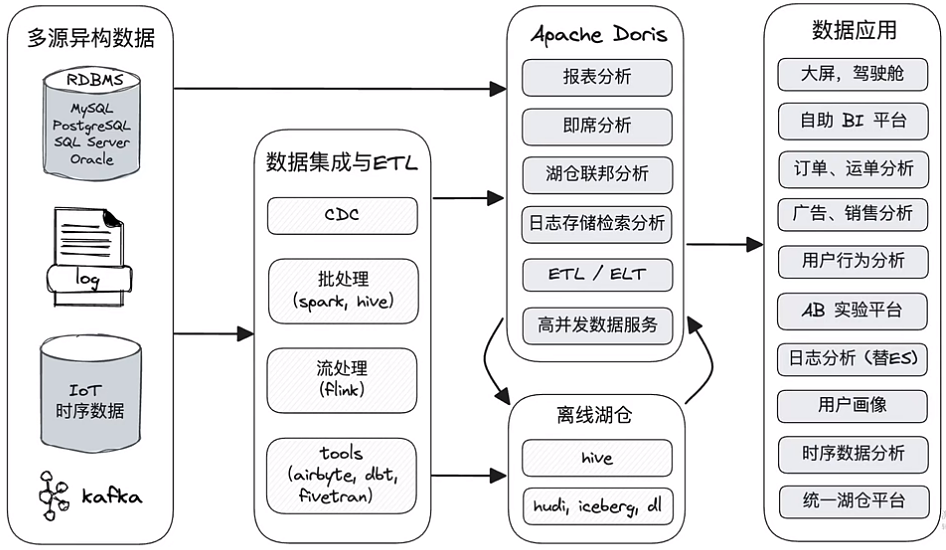
Doris主要定位在报表分析、即席分析、湖仓联邦分析、日志存储检索分析、高并发数据服务等场景,那Doris如何能够干这么多的事情呢?我们接着看。
03
主要特性

Doris主要特性可分为三部分:高效、简单、统一
■ 高效:极速的分析能力、高效的数据更新、丰富的数据导入、极致弹性及存算分离
■ 简单:高可用与高可靠、多租户管理、易用易管理
■ 统一:半结构化数据查询、湖仓一体
04
极速的分析能力

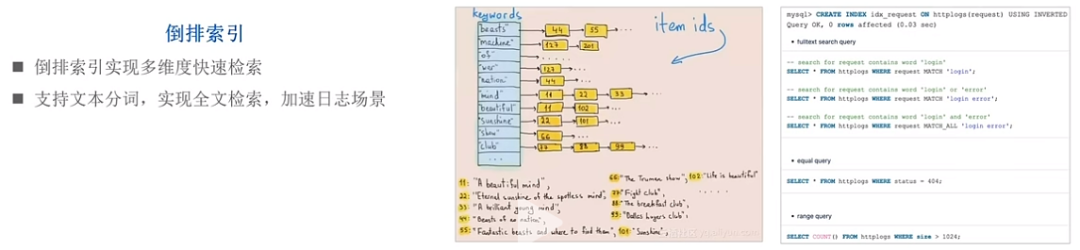
Doris除了拥有以上功能来完成极速的分析能力外,还实现了倒排索引来加速数据分析查询
05
实时的数据导入
■ 数据导入的核心目标 :实时、高吞吐、便捷、读写隔离
■ 实时小批量数据导入(时效性可以做到1s~5s)
口StreamLoad:通过 HTTP协议,将本地文件导入到 Doris,吞吐可线性提升,实际场景中有千万记录每秒
口Flink Doris Connector:使用F1nK-CDC机制从OLTP数据库中抽取数据,调用StreamLoad ,实时小批量导入到 Doris
口RoutineLoad :订阅Kafka 中数据,实时小批量导入到Doris,支持一流多表
口 Insert into values :通过JDBC的方式便捷写入:需要写入端攒批,写入吞吐有限:后续版本会做服务端自动攒批
■ 批量数据导入和集成
口数据湖集成: 通过数据湖联邦分析(insert into 内表 select from 外表)的形式导入,支持数据变换,大数据量高吞吐导入
√集成存储系统(S3,HDFS,本地文件)
√集成数据湖(lceberg,Hudi,Hive)
√集成数据库(MySQL,Oracle,ES等)
口SparkLoad:使用 Spark 计算资源处理位于HDFS或者对象存储上的原始数据,生成 Doris 存储格式,适合大批量数据灌入
口BrokerLoad:不再需要部署Broker,支持HDFS和S3协议
■ 丰富的数据集成工具和生态:Spark Connector,Airbyte,Dataworks,DataX,数据迁移工具 x2Doris,并行导入ParallelLoad
■ 读写隔离(V2.1)
06
高可用与高可靠
01
高可用架构
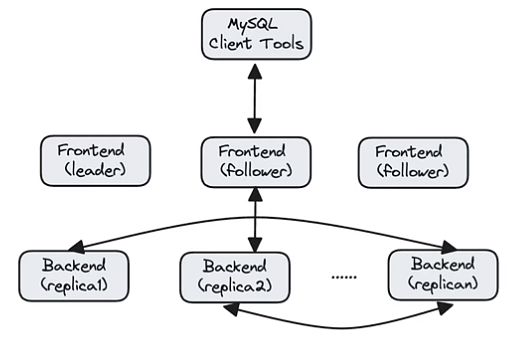
■ Frontend 节点管理元数据,多副本,类Paxos致性协议
■ Backend 节点管数据,多副本,自动副本补齐和均衡
■ Client 可以通过负载均衡链接Frontend节点
■ 查询过程中 Backend down,Query 会重试
■ 不停服滚动升级、扩缩容
02
数据备份恢复
支持全表或者分区级别的数据备份恢复(数据备份到HDFS或者对象存储)

03
跨集群复制
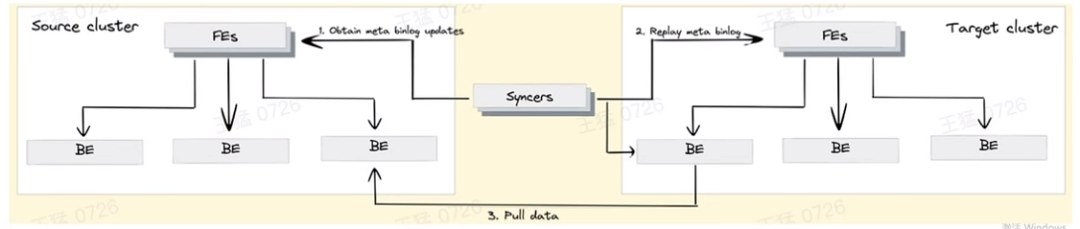
■ 容灾备份 :将企业的数据备份到另一个集群与机房中,当突发事件导致业务中断或丢失时,可以从备份中恢复数据或快速进行主备切换。一般在对 SLA 要求比较高的场景中,都需要进行容灾备份,比如在金融、医疗、电子商务等领域中比较常见。
■ 读写分离:读写分离是将数据的査询操作和写入操作进行分离,目的是降低读写操作的相互影响,保证数据库的性能及稳定性。
■ 隔离升级:当对集群升级时,为了避免不兼容和未知Bug,提前构建备集群进行双跑验证
■ 性能数据:最快可以做到分钟别数据延时,数据同步速度可以触及网卡和磁盘上限
07
多租户管理
01
多租户安全-认证和鉴权
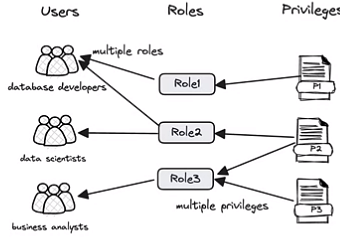
■ 认证:使用MySQL的安全认证过程(非对称加密)
■ 完善的RBAC的访控
■ 数据权限
口库表级别权限
口行级别权限
口列级别权限
■ 支持打通用户的LDAP为Doris提供认证和鉴权服务
支持SSL/TLS安全传输
02
多租户资源隔离
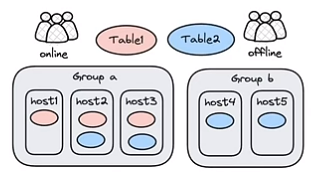
■ Resource Group:机器分组,副本放置到分组,user绑定分组
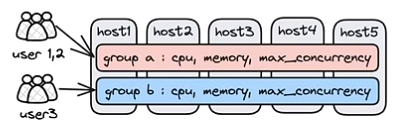
■ BlockRule:对特定查询模式、涉及分区/分片数大的查询拦截
■ 单查询内存限制和Memory Tracker
■ 存算分离:多cluster机制和reource group 整合(V2.1)
■ 导入和Compaction后台线程和查询隔离(v2.1)
08
易用易管理
01
兼容 MySQL 协议,学习成本低,和各类BI工具兼容性好
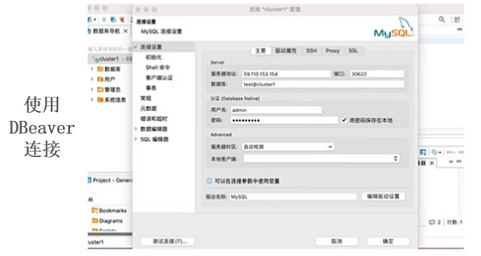
02
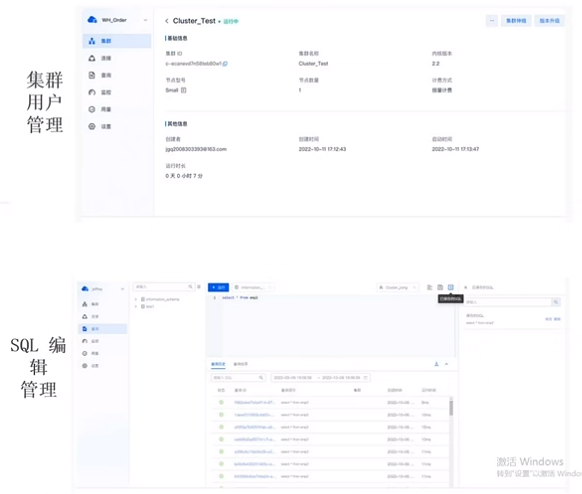
完善的管理(Doris Manager)和SQL开发工具
03
灵活轻量的 Schema 变更(Light Schema Change)
■ 轻量级Schema变更(v1.2起)
口在线毫秒级增减字段
口在线按需增减索引
口在线按需更改类型
■ FlinkConnector等工具结合LSC实现上游表变更毫秒级DDL同步
09
半结构化数据分析
■ 丰富的半结构化数据分析场景和特点
口日志检索分析、可观测性分析、时序数据分析、车联网数据分析、安全
口Schema Free、低成本、高效文本分析、任意维度分析和全文检索
■ 高效文本分析 (模糊查询 1ike)
口NGram Bloomfilter,提升like性能2倍
口Like下推到存储层,加速2-3倍
口自适应 Like
口高性能正则匹配库Hyperscan加速,提速2-10倍
口高性能子串匹配Volnitsky算法,加速1.5~3倍
■ 倒排索引
口多维度快速检索;支持文本分词,实现全文检索
■ 复合数据类型
口Array,Map,Json;Varint(v2.1),允许一个字段多种数据类型
■ 高效存储与写入
口列式存储,ZSTD压缩,冷热分层
口减少正排,时序compaction,单副本导入
10
湖仓一体
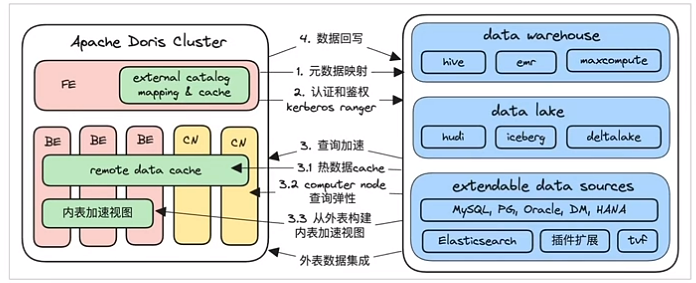
■ 主要应用场景
口湖仓查询加速
口数据导入和集成
口统一查询网关
口ETL/ELT加速,写回开放湖仓存储格式
■ 便捷的元数据和数据打通
口元数据映射、cache和自动刷新
口支持几乎所有开放湖仓格式和etastore
口支持ES和关系型数据库,并且插件扩展
口支持外表的认证鉴权,如keberos,ranger
■ 分析加速
口利用Doris 高效的分析引擎加速
口热数据Cache到本地
口支持弹性计算节点,实现计算弹性加速
口外表处理结果可写入内表,形成加速视图
11
极致弹性与存储分离
01
存算一体模式
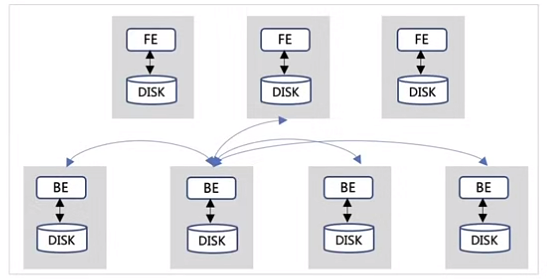
■ 简单易部署,易运维,适合绝大多数用户
■ FE和BE节点都可以灵活扩缩容
■ 存储支持冷热数据分层,将冷存储下沉到对象存储或HDFS
■ 可以支持弹性计算节点,快速实现计算弹性
02
存算分离模式
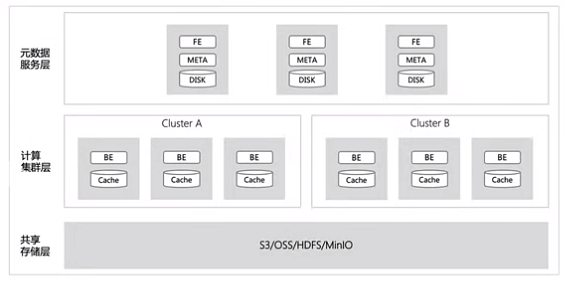
■ 飞轮科技2022基于ApacheDoris实现了存算分离式的SelectDB Cloud,2023年V2.1贡献给 Apache Doris
■ 存储资源和计算资源分离,各自弹性,更极致性价比
■ 依赖足够稳定、高吞吐的共享存储,通常公有云上才有
■ 可以通过多cluster 机制实现负载隔离,读写分离等机制
12
版本Roadmap
2022.07 V1.1
■ 全面向量化引擎支持,性能提升3-5倍
■ 内存统计和限制机制,稳定性大幅提升
■ 500+优化和修复:ZSTD压缩算法、Latera1View 语法及 Table Function 表函数等
2022.12 V1.2
■ 算子全面优化,宽表性能领先
■ Clickbench全球性能第一,领先Clickhouse
■ 新主键模型(MoWUniqueKey),聚合性能提升5-10倍
■ 嵌套数据类型:Array,JSON
■ 初步完备的LakeHouse,性能比presto快3-5倍
■ 轻量 Schema Change
2023.07 V2.0 (2023.05 alpha,2023.06 beta)
■ 复杂查询盲测性能提升近10倍:全新的查询优化器,pipeline执行引擎
■ 倒排索引,相比ElasticSearch10倍性价比的日志存储分析方案
■ 完善的LakeHouse(hive,iceberg,hudi,jdbc rdbms)和性能提升
■ 高并发数据服务支持,点查性能单机数万,线性可扩展
■ MoW UniqueKey稳定支持大批量导入,支持部分列更新,完善的DML
■ 资源弹性:冷热数据分层+弹性计算节点
■ 众多企业级特性:跨级群复制CCR、负载管理和排队、万表入库、K8S对接
2023.10 V2.1(2023.09 preview)
■SelectDB Cloud 上完善的存算分离能力开源到社区
■ 数据科学场景高速读取数据
■ Varint 数据类型,更灵活的半结构化数据支持
■ 多表物化视图
■ LakeHouse 兼容 trino 语法
■ PL/SQL 存储过程
以上就是Doris介绍全部内容,后续系列我们会逐节展开进行详细说明,请持续关注..
13
加入知识星球
14
进交流群群添加作者

