Doris即将推出存算分离架构,在存算分离架构下,计算节点不再存储主数据,而是将共享存储层作为统一的数据主存储空间
一、特性
弹性的计算资源:不同时间点使用不同规模的计算资源服务业务请求,按需使用计算资源,节约成本。
负载 (完全) 隔离:不同业务之间既要共享数据又不想共享计算资源,数据共享和稳定性二者兼得。
更低的存储成本:可以使用更低成本的对象存储,HDFS 等低成本存储。
上述 3 点最终核心还是降本增效,弹性实现按需使用资源,资源隔离。
二、架构方案
存算分离架构如下图所示:

2.1 基于共享存储系统的主数据存储
在存算分离架构下,计算节点不再存储主数据,而是将共享存储层作为统一的数据主存储空间,这将带来如下收益:
上层的计算节点可以做到无状态,可以实现完全关机
更便捷的数据共享,不同的集群之间以及不同的仓库可以便捷地进行数据共享
更简易的数据备份与恢复,以及实现数据的 Time Travel
当然,成熟稳定的 HDFS/对象存储还为系统带来极低的存储成本和极高的数据可靠性,并且大大简化上层计算节点的实现复杂度。
2.2 基于本地高速缓存的性能优化
存算分离依赖从网络上读取存储系统的数据来进行计算,在一定程度上会造成计算性能的下降,这也是相较于存算一体架构的主要劣势。为了解决这一问题,可以在本地利用 SSD 提供高速缓存。
存算一体通过冷热数据分层技术来大大缓解了存储和计算必须同时扩展的问题,同样在存算分离架构中引入计算节点本地高速缓存实际也是融合了存算一体的能力。这种本地高速缓存加上共享存储系统,我们也可以称之为混合模式,无论是 Snowflake 还是 Redshift,实际上都是采用了这种方式来应对底层对象存储系统性能不佳和网络传输带来的性能下降。
2.3 多计算集群实现工作负载隔离
在存算分离模式下,提供了同一个仓库多个物理计算集群的隔离方式。因为主数据存储在共享的对象存储上,因此用户可以按需创建多个计算集群但共享同一份数据。计算集群之间是物理隔离的,可以独立扩缩容,其计算节点的本地高速缓存都是隔离的,这样保证了尽可能比较好的隔离性。
2.4 极致的弹性扩缩容
存储与计算的分离,带来的最大优势是存储和计算可以独立扩缩容。数据存储在 HDFS 或对象存储上,可以按需扩缩容。每个计算集群的计算节点,可以实现更加高效的弹性扩缩容,包括手动扩缩容、分时扩缩容以及自动停机。
三、读写流程
下图展示了存算分离架构下读写数据流转的流程
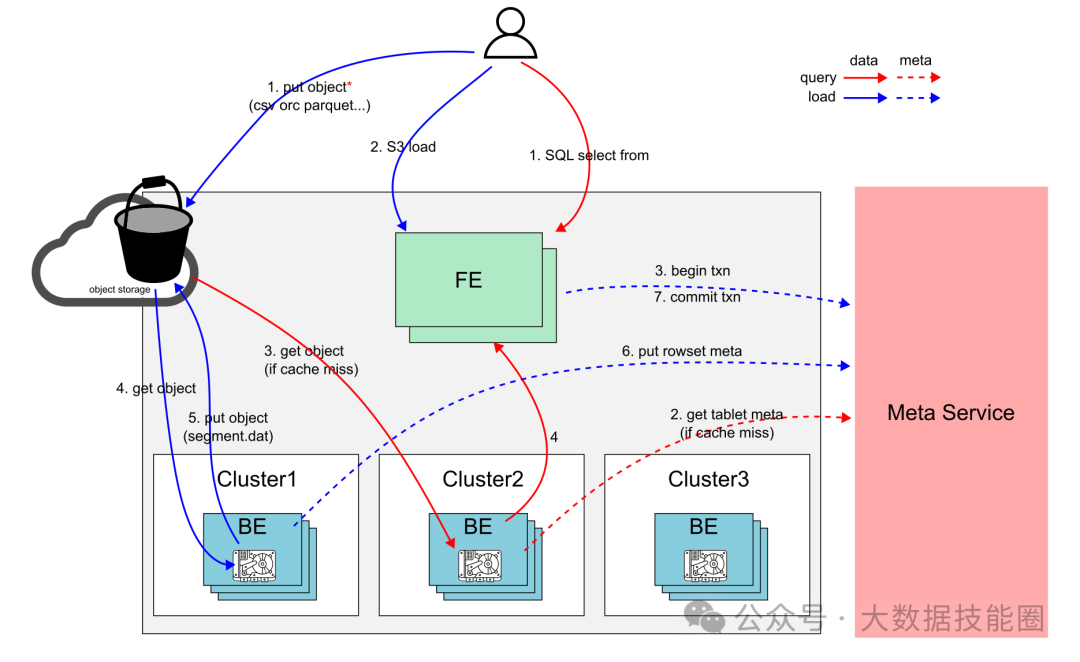
3.1 导入 (s3 load 为例):
将需要导入的数据 (事先) 存放在对象存储上
通过 s3 load 语句创建导入任务
FE 创建导入规划 (具体导入哪些数据到那些表), 启动导入事务
BE 根据执行导入规划从对象上获取需要导入的数据转换成内 Doris 内部格式
BE 将转换完成的数据 (segment 文件) 上传到对象存储,数据持久化完成
BE 将对应的 rowset meta 通过 Meta-service 持久化
FE 完成该次导入事务,导入流程完成
注意:除了 s3load, 存算分离架构支持所有的 Doris 导入方式:stream load, insert into, routine load 等等。
3.2 查询流程:
用户发起查询语句 (select), FE 生成对应的查询规划 发往指定 Cluster 的某个 BE
BE 按照执行规划执行,查询对应的表的元数据,获取到数据分布。这一步会可能会和 meta-service 交互获取 tablet 元数据,如果 BE 上没有这些元数据的缓存。
BE 根据规划读取数据进行扫描/过滤。这一步会优先查找本地数据缓存,如果不命中本地缓存,则从 S3 上获取到对应的数据进行处理。
BE 完成查询规划,返回数据
注意:
如果查询的数据能全部命中缓存,查询性能和 Doris 存算一体保持一致。
用户可以通过新增的use @<cluster_name> 的语句来指定 sql 在特定 cluster(物理资源组) 上执行
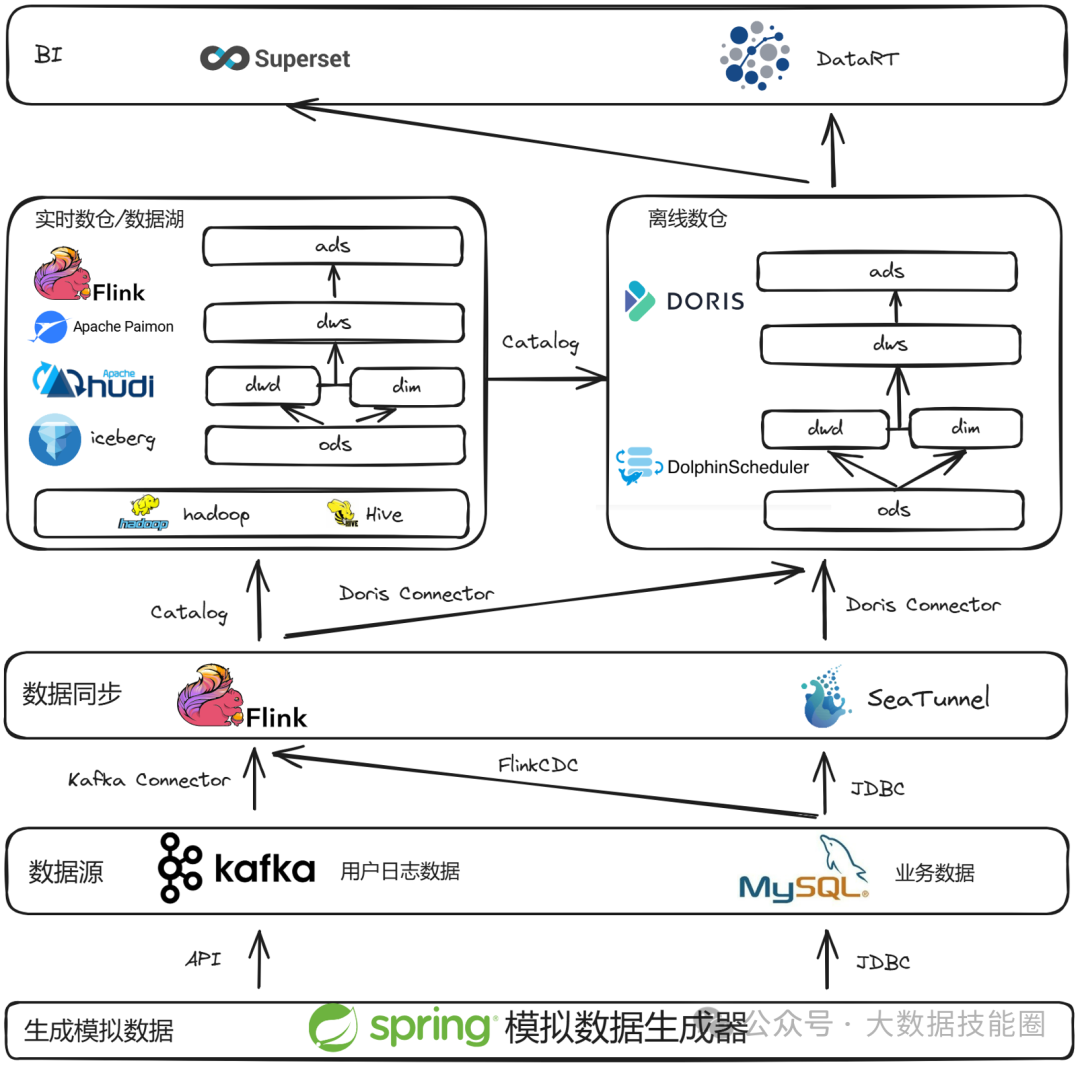
这或许是一个对你有用的开源项目,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning https://github.com/Mrkuhuo/data-warehouse-learning 项目演示:
3.3 资源隔离:
通过灵活应用 cluster (use @<cluster_name> 语句) , 可以实现多导入以及查询的物理隔离。
假设当前有 2 个 cluster: c1, c2
读读隔离:两个 (类) 大查询发起之前分别 use @c1, use @c2, 可以实现这两个 (类) 查询使用不同的计算节点完成对相同数据集的,CPU, 内存 查询等长尾不相互竞争,不相互影响。
读写隔离:Doris 导入也会消耗一些资源,特别是在大数据量 高频导入场景。为了避免查询和导入之间的资源竞争,导入和查询分别 use @c1, use @c2, 可以实现查询请求完全在 c1 上执行,导入请求完全在 c2 上执行,并且 c1 使用到全量的新导入的数据。
写写隔离:和读写隔离同理,导入和导入之间也可以进行隔离,常用的场景是不同表的导入进行隔离,比如高频小导入,大批量导入的隔离。批量导入往往耗时长,重试成本高,高频小导入单次耗时短,重试成本低,如果小导入影响到了批量导入,使用体验会大打折扣。这个场景可以高频导入和的大批量导入分别use @c1, use @c2. 达到小导入完全在 c1 上执行,批量导入在 c2 上执行,互不影响。
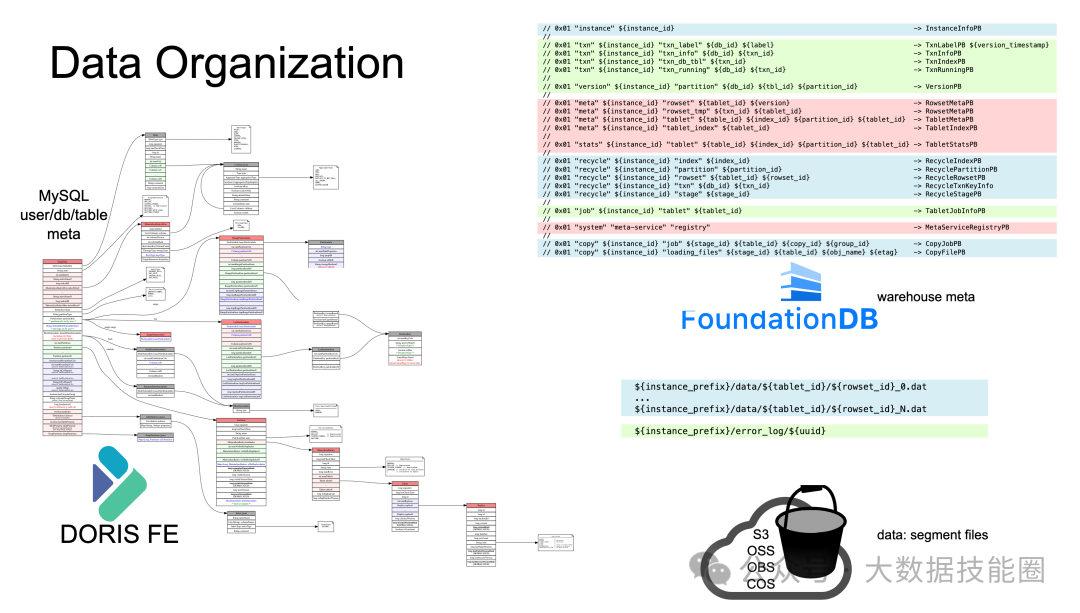
3.4 数据布局:
项目文档地址
添加作者进大数据交流群