





本项目以Doris集群为数据仓库的唯一存储平台,完成“实时数仓+离线数仓”的一体化建设,不仅实现了高效的OLAP查询,还实现了基于同一套代码的“流批一体+全增量一体”实时数仓。

本文将介绍基于Doris和启数道大数据平台的特步儿童BI项目实现。本项目以Doris集群为数据仓库的唯一存储平台,完成“实时数仓+离线数仓”的一体化建设,不仅实现了高效的OLAP查询,还实现了基于同一套代码的“流批一体+全增量一体”实时数仓。
特步(中国)有限公司于2008年6月3日正式在港交所挂牌上市,是一家集综合开发、生产和销售运动鞋、服装、包、帽、球、袜等为主的大型体育用品企业。
2012年,厦门市特步儿童用品有限公司成立,正式进军童装行业。特步儿童的强大实力来自母公司——特步集团的全力支持。针对目前国内童装品牌现状,特步儿童制定品牌差异化发展战略,主张释放孩子的天性,关爱孩子健康,集中一切可利用的资源,创造行业新的品牌推广模式。
特步儿童坚持中高档的商品定位,三四线城市的价格定位,专注于3~14岁儿童群体,关注白领阶层父母对儿童商品的消费,旨在提供高性价比且品类丰富的儿童运动用品,为广大消费者带来轻松、舒适的体验和物超所值的购买经历。
特步儿童是特步旗下第二大品牌,也是从特步品牌中衍生出来的,所以和特步共用一套系统。早期的特步交易系统和分析系统都围绕SAP构建,2019年在阿里云的帮助下,构建了基于分布式RDRS的业务中台系统(简称“全渠道DRP系统”),这也是本次项目接入数据的主要来源系统。
在本次项目启动之前,特步儿童从底层业务到中层管理都实现了信息化运作,但现有信息化系统对企业决策支持需求尚难满足,之前的HANA数据仓库较难满足日常的敏捷数据分析需求,缺乏经营分析平台对数据进行整合,快速梳理各个业务单元经营表现及发现异常的能力,存在的具体问题如下。
1)企业经营过程中各业务环节数据未打通,业务分析断层。公司已经建设统一的数据仓库,但从应用到业务的流程长,从商品经营到终端经营各环节数据尚未打通,跨环节数据提取难度大、效率低。
2)数据处理依赖手工,耗时长,工作量大。企业管理数据依赖数据分析人员手工汇总、处理,易出错、效率低,且不能满足经营层、管理层和业务部门的需求。
3)缺乏数据洞察能力,数据展现不直观。企业主要通过各类报表进行数据分析,但报表之间缺乏关联和对照关系,导致不能及时、准确地获取数据的含义和发展趋势;缺乏对移动端报表的支持,不能满足移动办公与数据协同需求。
为了实现特步的业务增长和效率提升战略,特步通过准确、统一、快速的数据分析能力建设,持续提升数字化战略实现价值,实现精细化管理运营。本次项目需要加强数据自动化采集、计算,数据多平台整合,数据分析能力建设,同时,从IT角度考虑公司其他职能部门对此项目所搭建平台的复用性,基于行业最佳实践模式,统筹建设内部共享的、安全的敏捷数据分析平台。
在本次项目架构确定前,特步和百度、启高、观远等多方经过多次交流,选取了“全零售战绩”大屏作为试点项目,测试了Doris的Routine Load功能和查询能力。
本次项目聚焦于特步儿童业务的BI分析需求,其销售渠道组织架构如图14-1所示。本次项目要求整合线上、线下数据,打通数据孤岛,提供全口径、准确、实时的数据分析结果。
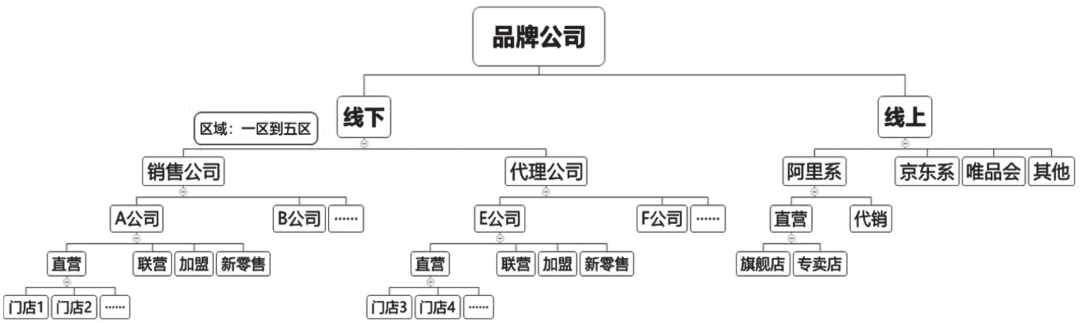
图14-1 特步儿童销售渠道组织架构
项目范围包含高管概览、零售、商品、会员、渠道、导购、节假日、故事包、直配店、店群管理、KPI看板11个场景,主要包括商品和店铺等维度数据、线下全渠道销售数据、线上电商销售数据、库存商品变动数据和补录的考核目标数据。
分析这些业务主题时,涉及的维度主要有时间(年>季度>月>周>日、节假日)、组织架构(最细到店铺粒度)、产品(最细到款式、SKU粒度)、会员(最细到单个会员粒度),实际分析维度以指标清单为准。
系统处理的业务数据主要包括全渠道DRP系统中的门店销售模型数据、门店商品调拨数据、会员消费数据,SAP系统中的商品调拨数据、批发数据、总仓和分公司仓库明细,多套电商平台中的商品销售数据,业务部门手动维护的目标数据等。本次项目需要完成以上数据的采集、建模、整合和汇总展现。
在本次项目中,前端数据可视化采用观远BI分析平台,通过数据库直连的方式读取加工好的数据,按照高管概览、零售、渠道、商品、故事包、KPI看板、直配店、节假日、会员等业务主题进行数据最终呈现,支持用户在平台进行数据查看和下载。可视化结果支持在移动端和PC端查看。
项目要求日常零售(包括节假日销售、线下销售、线上销售等)数据要以近实时(目标是5~10 min间隔)的频率刷新,目标数据、维度数据和商品库存数据可以T+1模式更新。
本次项目选择基于Doris搭建整个数据仓库,辅以启数道平台为数据中台,完成任务管理、工作流管理、元数据管理、数据资产管理、数据质量管理、数据安全管理等,如图14-2所示。
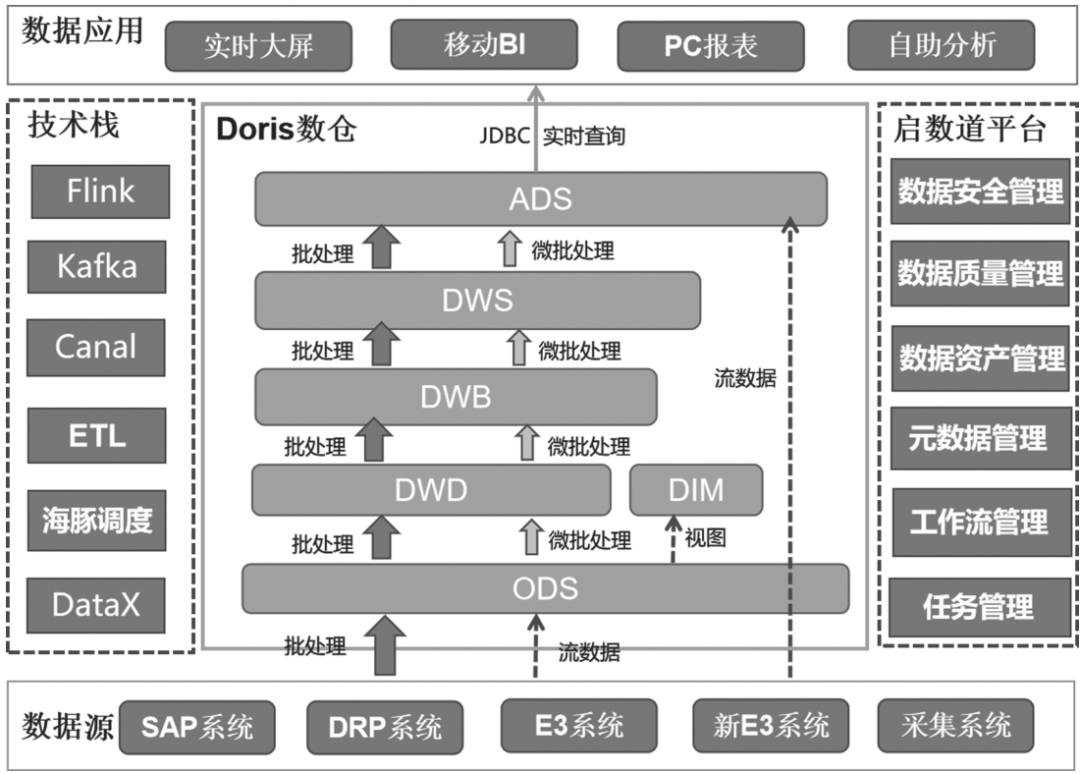
图14-2 特步儿童BI项目搭建的系统架构
3.1
批量数据同步
启数道批量数据同步功能基于DataX实现,提供界面化操作,只需简单几步即可完成表同步任务的创建。如图14-3所示,选择来源表和目标表,点击“匹配”按钮后,字段自动进行同名映射,然后保存。
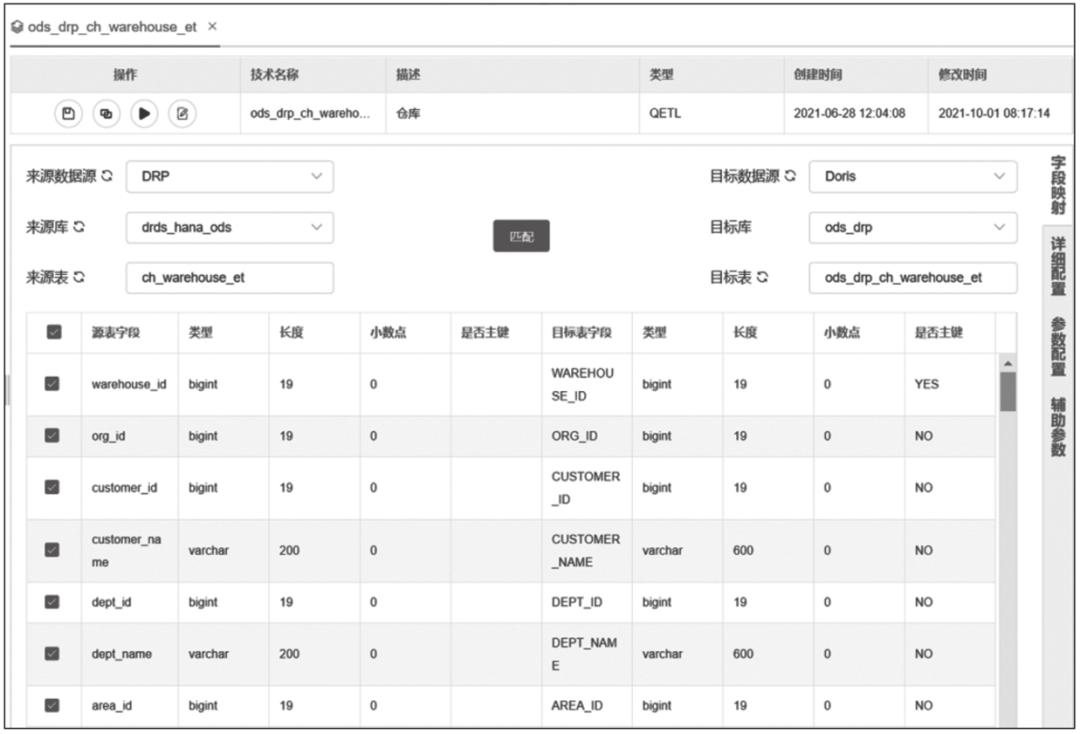
图14-3 DataX数据同步配置
在项目初期,Doris未发布DataX插件,仅通过原始的JDBC插入数据,达不到性能要求。产品团队开发了DataX加速功能,先将对应数据抽取到本地文件,然后通过Stream Load方式加载入库,可以极大地提升数据抽取速度。数据读取到本地文件取决于网络宽带和本地系统读写性能,加载2000万条记录(数据文件大小12.2GB)仅需5 min,截图如图14-4所示。
此外,DataX还支持自定义SQL同步数据,通过自定义SQL处理SQL Server数据库难解决的字符转换问题和偶尔出现的乱码问题。DataX基于自定义SQL同步数据的配置界面如图14-5所示。
DataX还支持增量数据同步,通过抽取最近7天的数据,配合Doris的主键模型,轻松解决大部分业务场景下的增量数据抽取问题。DataX增量数据同步配置截图如图14-6所示。
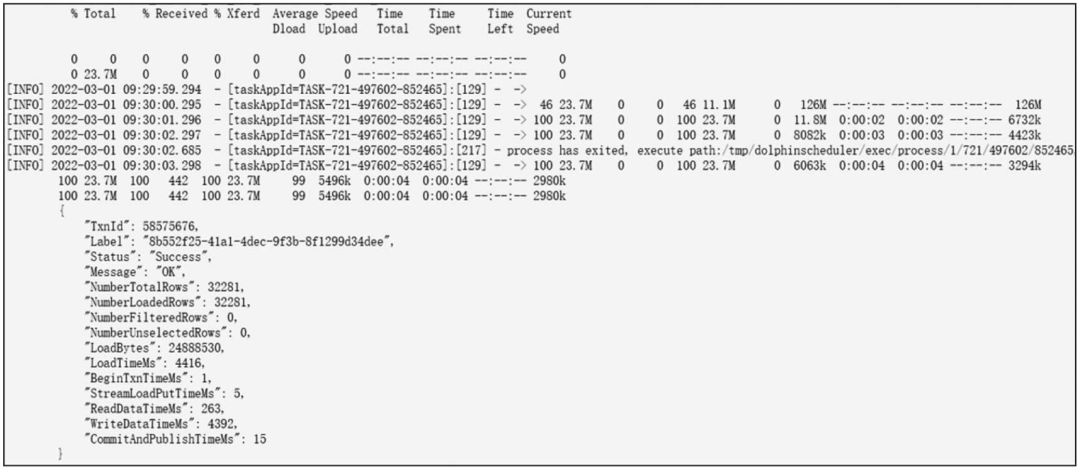
图14-4 Stream Load加载数据截图
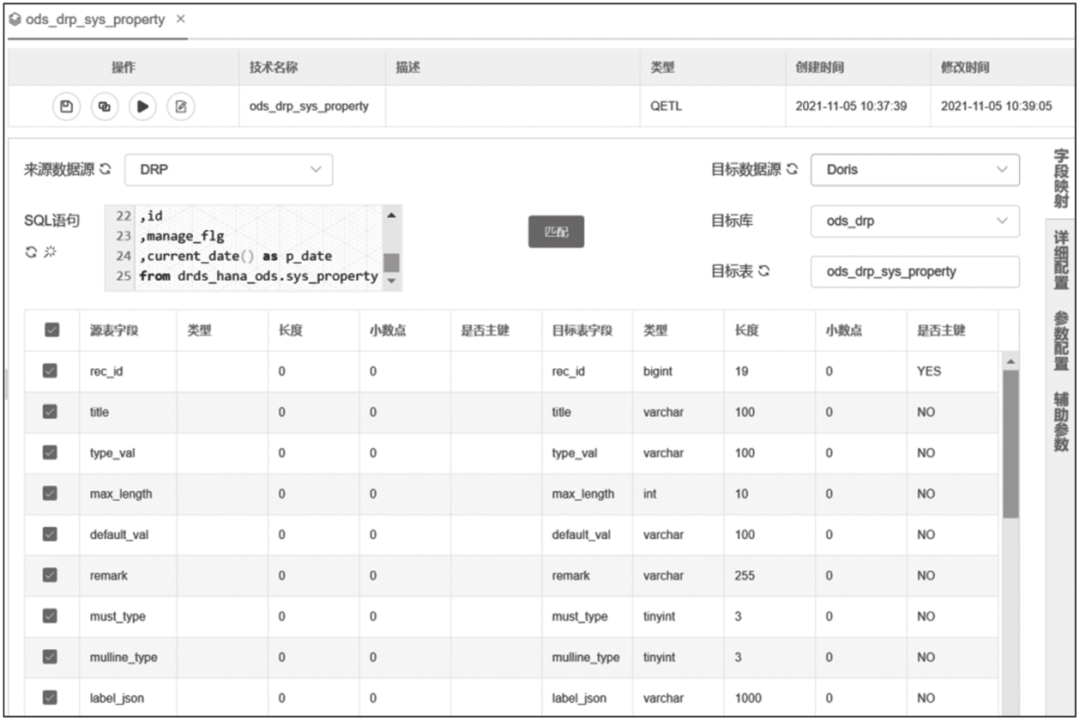
图14-5 DataX基于自定义SQL同步数据的配置界面

图14-6 DataX增量数据同步配置截图
3.2
实时数据入库
针对实时数据,我们采用Routine Load模式加载Kafka数据。
首先需要在Canal中配置Binlog日志拦截。Canal配置路径在/canal-server/conf下,进行Binlog日志拦截配置截图如图14-7所示。
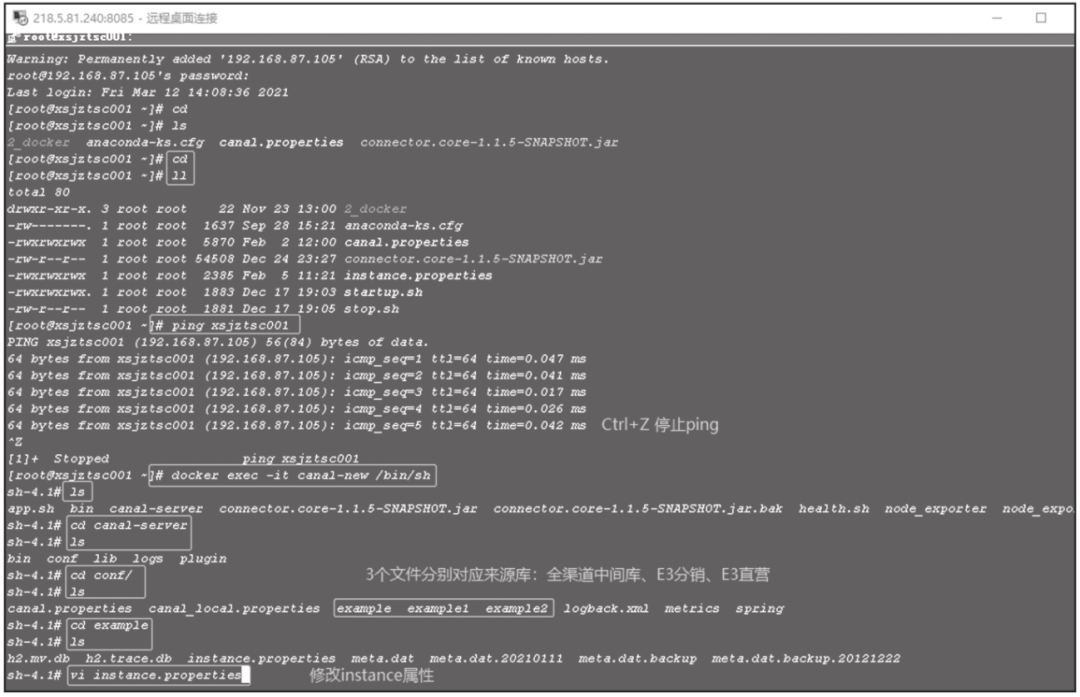
图14-7 Binlog日志拦截配置截图
在数据库文件夹下修改instance.properties文件,按照正则表达式拦截对应表的Binlog日志,截图如图14-8所示。这里支持正则表达式,可以同时获取分库分表的日志,极大地降低了配置工作量。

图14-8 Binlog日志解析配置截图
然后在Doris中新建ROUTINE LOAD任务,代码示例如下:


3.3
数据仓库分层
按照项目前期和客户沟通的结果,数据仓库层分成了3个子层,即DWD、DWB、DWS,如图14-9所示。增加DWB的原因有3点:电商业务数据来自多个系统,需要先进行合并才能进行汇总计算;指标层的计算规则变动频繁,客户期望将配置规则做成参数表,由程序自动解析(配置过于复杂,暂未实现);项目将DWS层定位为宽表模型,因此需要在DWB层完成指标逻辑的加工。
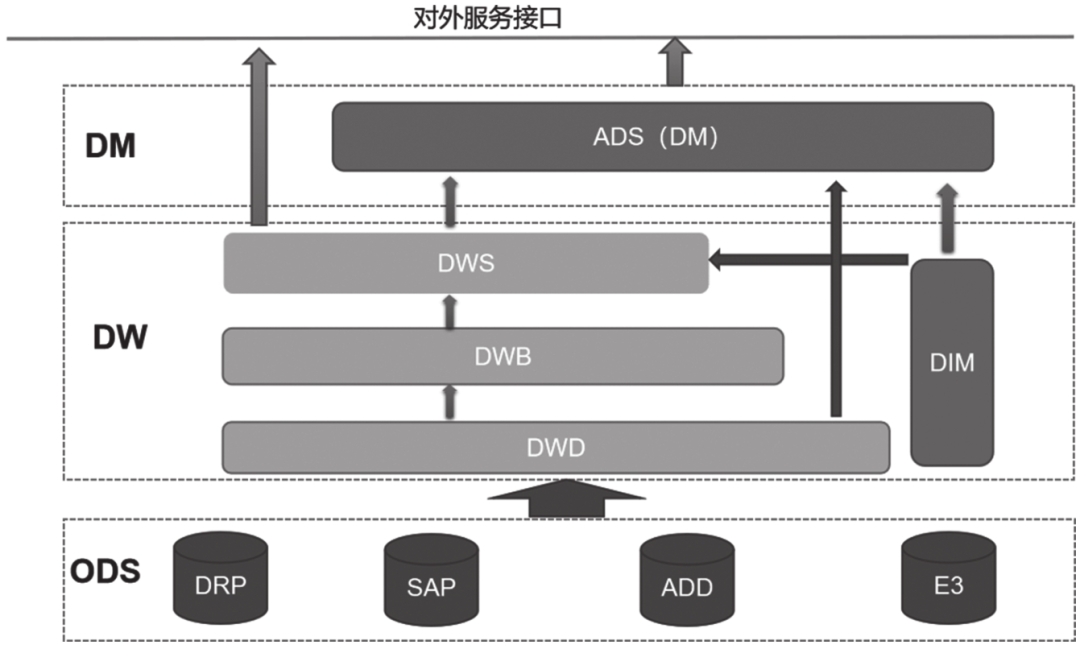
图14-9 特步儿童BI项目系统分层
分层逻辑如下。
❑DWD层:明细数据的组合加工,包括行头合并、商品拆箱处理、命名统一、数据粒度统一等。DWD层的销售、库存明细数据均按照来源系统加工,保留每条业务数据的主键信息,通过Doris的Unique模型确保数据不膨胀。
❑DWB层:按照公共维度汇总数据。根据业务需求统计小票数量,其他业务数据均汇总到业务日期、店铺、分公司、SKC等粒度,并基于汇总数据加工公共维度指标,例如销售吊牌金额、库存吊牌金额。DWB层采用Duplicate模型,以业务日期和店仓代码为Key字段,以SKC编码为分布键。
❑DWS层:将DWB层计算结果宽表化,数据粒度、数据模型、数据分布等和DWB层保持一致。
数据仓库层之外的ODS层、DM层和11.2节的仓库分层逻辑一致,这里不再赘述。
3.4
全增量一体化数据加工
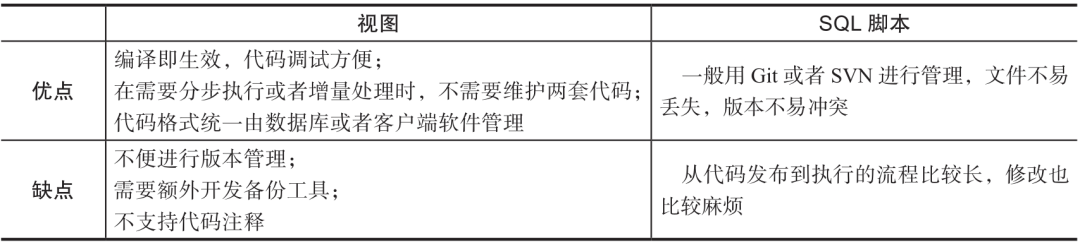
通过前文的介绍,我们了解到Doris不支持存储过程。综合考虑视图和SQL脚本开发,我们最终选择了视图。二者的对比如表14-1所示,仅供各位参考。
表14-1 视图和SQL脚本开发对比
业务数据的加工逻辑都比较复杂,不合理的设计会导致SQL代码非常长。在实际项目开发中,我们应尽量控制代码行数在200行以内,一方面是可读性强,便于维护,另一方面可以避免逻辑过于复杂而导致计算超时。这里展示一个简单的DWB层SQL代码:
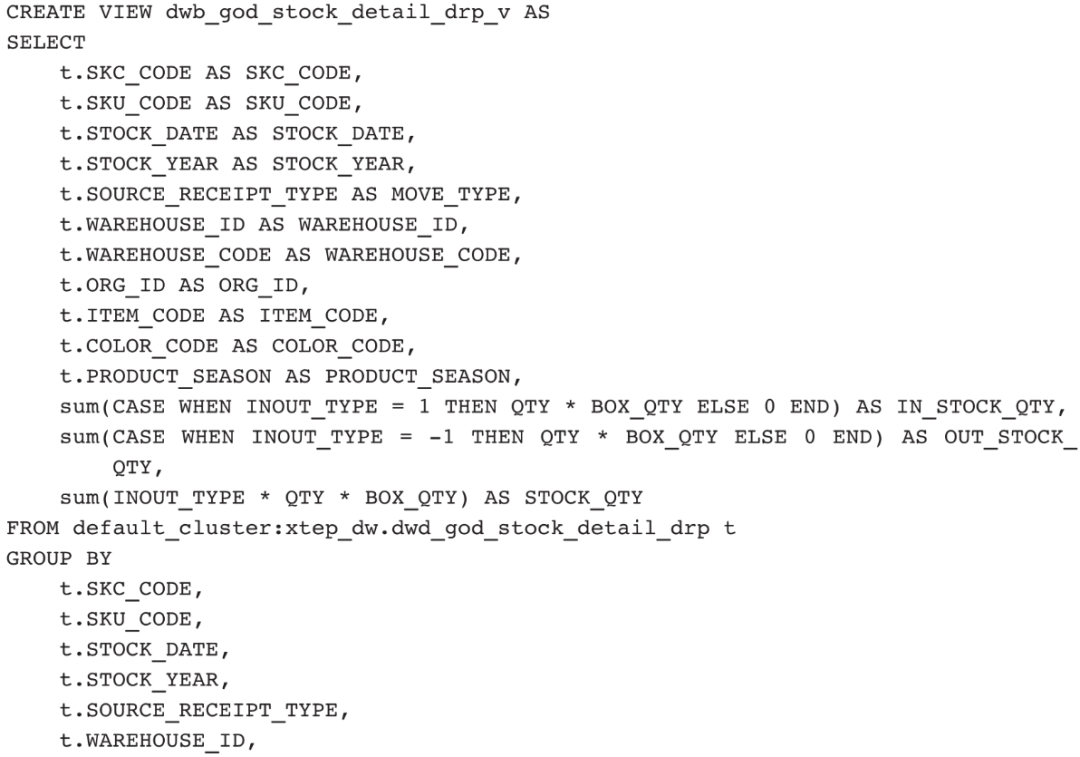

代码逻辑保存在视图中,需要按照10.3.4节介绍的方式每天3次备份表结构和视图创建语句。数据加工关键链路上的每一个视图,都有一张物理表来存储对应的数据。这里不用物化视图是因为很多加工需要多表关联计算,并且数据是批量更新的,物化视图效率低。
数据从视图中读出再写入物理表,这对Doris来说是一个较大的挑战。Doris支持快速高效查询,所以内存分配比较充裕,但是超大规模数据的加工或者过多的并发很容易占满内存导致某个BE节点崩溃,从而造成任务执行失败或者超时。经过多次尝试和优化,我们最终选择了根据业务日期来控制数据的处理量级。针对过亿数据量的汇总业务,单次仅计算一个季度的数据;针对数据量适中的业务,一次计算一个自然年度的数据;针对千万级以下的表,直接全量加工。这样,基于相同的视图逻辑,既可以完成超大规模数据的加工,又可以确保Doris夜间调度的稳定。一个复杂的全量批处理任务截图如图14-10所示。
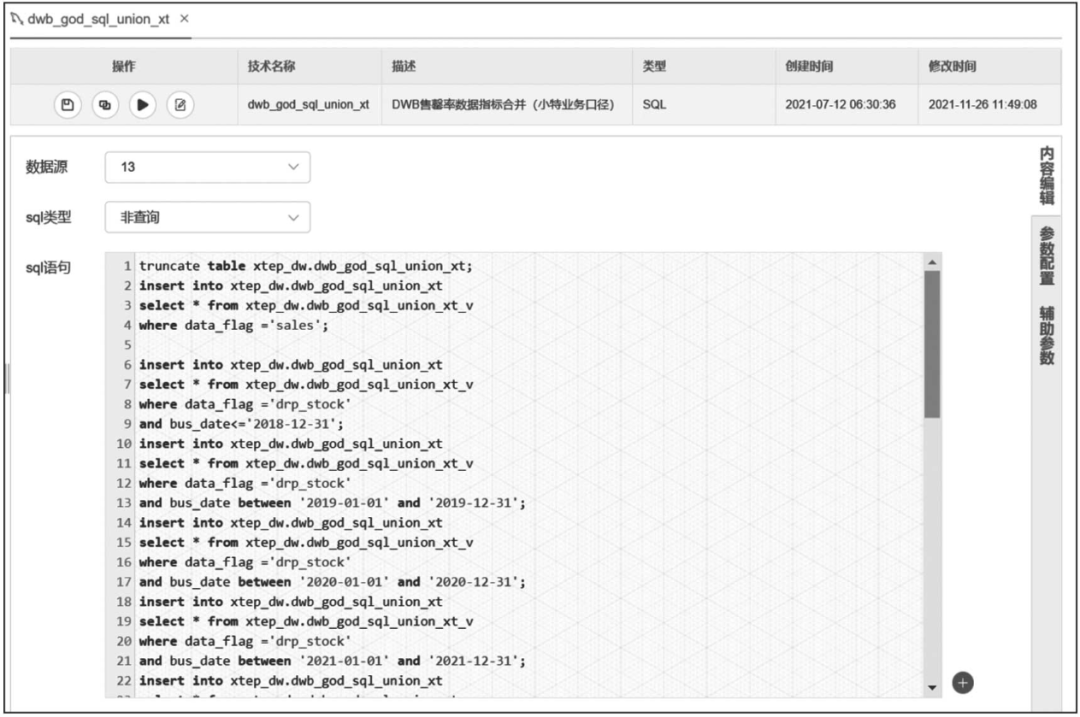
图14-10 全量批处理任务截图
根据项目要求,调度平台会自动拆解SQL语句,并在一个会话连接内逐句执行,中间有连接失败时立即报错。
针对增量数据加工任务,我们也可以采用先删除后插入的方式,继续复用视图逻辑。针对上述任务,每次只更新最近2个自然月的数据,SQL语句内容如下:

Doris的DELETE语句不支持表达式,只能通过任务变量{{p_lastmonth}}来植入一个常量值。通过这种方式,全量和增量任务实现了逻辑的统一,大大减少了系统维护的工作量。该方式有一个缺点,针对数据量特别大的任务,需要提前预设未来1~2年的跑批语句,看上去会比较奇怪,但是未来日期的SQL语句会快速执行,并不会影响跑批性能,因此是可以接受的。
报表数据实时统计任务和增量数据同步任务一样,从9点到24点每半小时循环刷新一次。数据刷新包含面向仓库层的数据刷新和面向报表展示的数据刷新。仓库层的数据由于不涉及展现,可以直接删除以后重新查询,典型的SQL语句如下:

针对面向报表展示的数据刷新任务,在数据重新写入过程中可能会有页面查询,导致查到空数据,因此不能先删除再插入。这里有3种方案可选。
方案一,继续保留主键,构建Unique模型,每次跑批追加当日最新数据。该方案适合几乎不会删除数据的场景。
方案二,针对有业务数据删除或者无法构建主键模型的场景,先将当日数据写入临时表,然后快速将临时表中的数据写入当前表。数据从临时表写入当前表的过程中不涉及复杂计算,因此用户几乎无感知。

方案三,针对计算结果是高度汇总,没有合适的Key字段做增量删除的场景,推荐使用Swap方式,如图14-11所示。
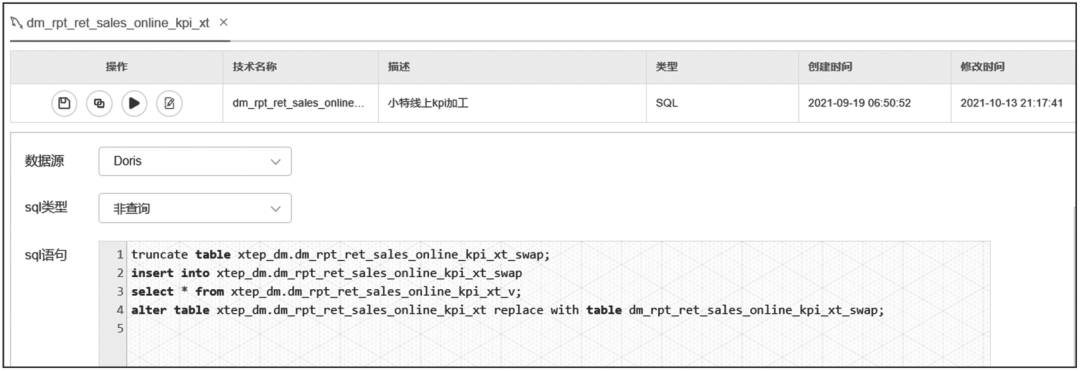
图14-11 利用Swap方式无缝交换数据
通过以上3种方案,我们可以实现全量数据计算、增量数据更新、微批处理实时数据3种模式复用一套代码,不仅大大减少了代码维护工作量,而且满足了不同业务场景需求,确保了数据的准确性和可靠性。
3.5
流批融合的实时大屏
虽然T+1更新和微批处理可以满足业务分析需求,但是面对“双十一”大屏这种实时性要求更高的场景,我们必须将数据的延时降到秒级。由于“双十一”大屏主要关注当日实时销售数据,并且不需要进行复杂的指标计算,因此我们直接复用DWD层的计算逻辑,以DWD层的视图数据来加工大屏数据。因为ODS层的数据是通过Kafka写入的,直接查询DWD层的视图,相当于去掉了调度跑批,直接将查询时效提高到秒级。
以“双十一”大屏的关键指标为例,其查询语句如下:

大屏通常还会展现分组汇总数据或者排名数据,以店铺排名为例,其查询语句如下:


ODS层的接口采用Unique模型,可以实现基于主键的数据去重,但是在查询时,资源会有损耗,这时我们就要让大表实现Colocate Join,尽可能降低资源消耗。以上方法只能缩短Doris查询时间,但是并不能保证前端可以无缝展示查询结果。在这里,我们引入一个操作:在前端页面发起查询请求时,直接读取Redis中的数据并返给前端,如果Redis中的数据生成时间在30秒内,则不再发起查询,如果Redis中的数据生成时间超过30秒,则请求Doris查询数据来更新Redis,这样下一次请求数据就又快又准确。
3.6
调度任务
有了抽取任务和数据加工任务,我们就可以把任务串联起来,组成工作流,交由定时管理器来定时启动执行。这是所有调度平台都具有的功能。启数道的调度平台基于DolphinScheduler进行二次开发,提升了调度效率,也在用户体验方面做了较多优化。
针对数据量较大的任务或者占用内存较多的任务,我们采用串行执行方式,如图14-12所示。
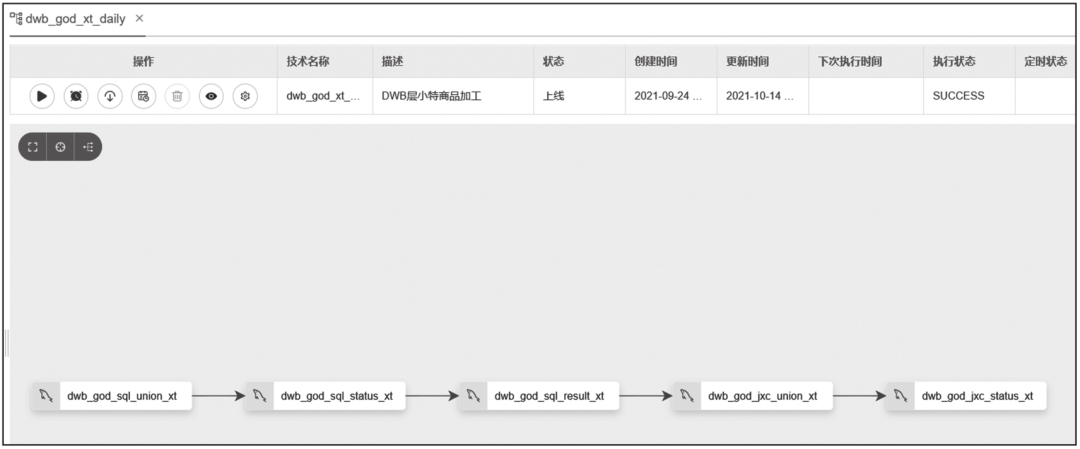
图14-12 串行执行截图
针对报表任务,处理逻辑比较简单,我们较多采用并行执行方式,提高跑批速度,如图14-13所示。
图14-13 并行执行截图
多个子工作流串联并设置定时,如图14-14所示。
图14-14 子工作流串联截图
程序开发过程这里就不详细展开了,因为在其他项目上复用的概率比较小,这里主要梳理开发规范。
4.1
数据对象命名规范
前面已经介绍了数据仓库的分层逻辑,按照项目的设计,总体上分为ODS层、DW层和DM层,其中DW层又分为DIM、DWD、DWB、DWS和ADS层。
ODS层的表以“ods_系统简称_源系统表名[_后缀]”为标准命令。后缀包括_incr、_hist、_chain 3种。不带后缀的表保存和源系统一致的数据。_incr保存一个批处理周期的增量数据;_hist保存多个时间点的快照;_chain保存拉链数据。系统简称同模式名,主要有drp、ezy、efx、epa等。
DW层的表命名前缀包括两种:以dim_开头,以dws_、dwb_和dwd_开头,具体命名如下:
❑dim_表内容含义[_系统简称][_后缀]
❑dwd_业务领域_表内容含义[_系统简称][_后缀]
❑dwb_业务领域_表内容含义[_品牌标识][_后缀]
❑dws_业务领域_表内容含义[_品牌标识][_后缀]
具体来说,特步集团内部把零售数仓划分为零售ret、会员vip、渠道chn、商品god、供应链scm五个业务领域。后缀包括_hist、_chain、_tmp、_incr。品牌标识主要有特步dt、特步儿童xt、电商ds、新品牌xpp。例如dim_shop_info表示DIM层的店铺维度表,dwd_god_stock_detail_drp表示DWD层的DRP系统库存明细表,dws_ret_sale_detail_xt表示DWS层的特步儿童品牌销售明细表。
DM层的表命名以dm_开头,要求命名标准为“dm_应用方向_业务领域_表内容含义(报表代码、汇总粒度、核心指标等)_品牌标识”。例如:dm_rpt_god_listing_xt表示特步儿童商品上市分析。
除ODS层以外,视图和表几乎是一一对应的,所有的视图命名在对应目标表名基础上增加_v结尾。当有同一个数据多次加工需求时,推荐使用with as语句来处理,若需要建多个视图,可以根据业务含义建不同名的视图。
4.2
建表规范
Doris建表规范具体如下。
1)replication_num指定分区的副本数,默认为3。
2)分桶数维度表选择1,业务表选择2、4、8、10等。
3)DISTRIBUTED BY取最能平均分布数据的字段,一般是VARCHAR类型。
4)引擎默认为OLAP。
5)bloom_filter_columns取类似于唯一键的字段。
6)colocate_with和DISTRIBUTED BY配合使用,可以减少桶数据广播情况发生,需要关联的头行表取相同字段作为DISTRIBUTED键,并且指定和colocate_with为同一组。7)ODS层、DW层规定主数据为group0,流水为group1,库存为group2。
我们需要根据各张表的数据内容来确定表引擎,如表14-2所示。

分区表推荐按年分区和按月分区,不推荐按日分区。分区表建表语句示例如下:
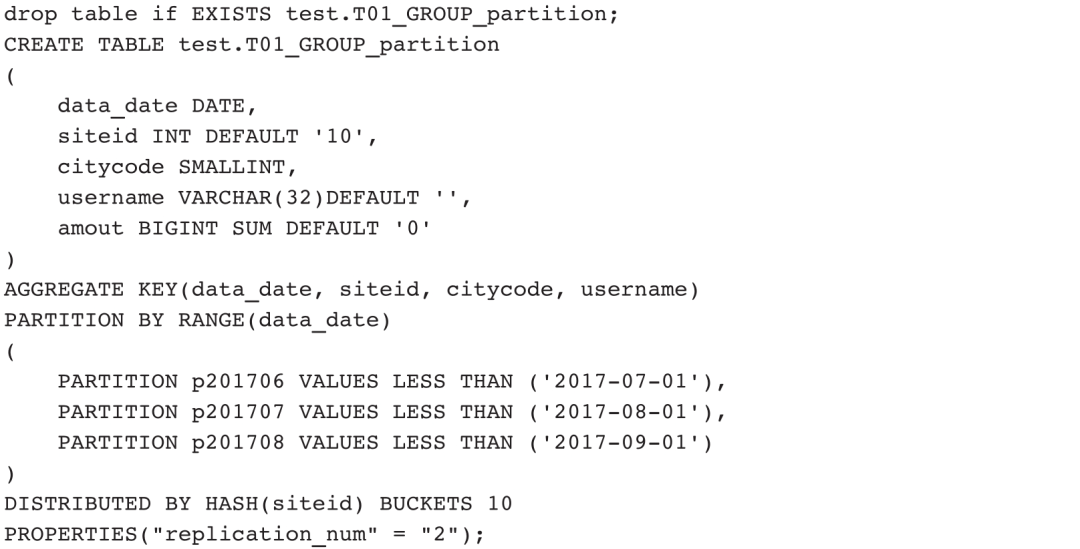
4.3
字段命名规范
字段命名以容易理解和前后一致为最高原则。字段名由词根组成,词根选择业务英文翻译或者业务拼音首字母,一般由2~5个字符组成。如果字段只有两个词根,可以适当延长,例如currency_code(币种编码)、material_code(物料编码)。对于某些简写的业务名词,没有合适的翻译也可以选择拼音首字母,例如:sql(售罄率),kxb(库销比),xhl(消化率)。
前后一致是指数据仓库层和数据集市层用到的相同含义的字段名应该保持一致,例如商品编码统一用skc_code,店铺代码统一用shop_code。
DW层和DM层可以参考ODS层的字段命名,但是要保持相同含义的字段名一致。
命名字段时,注意id和code字段,name和desc字段,尽量不要用_no字段。id和code字段同时存在时优先保留code字段。
❑数据库生成的无意义的随机字符串或者序列,以_id结尾,例如org_id。
❑有规则的编码或者编号,以_code结尾,例如curreny_code。
❑有确定含义的业务命名(值是定长或者接近定长),以_name结尾,例如curreny_name;
❑仅仅是解释性和描述性的业务命名(值长短不齐,可能包含中英文或者标点符号),以_desc结尾,例如material_desc。
4.4
调度任务命名规范
一般来说,一个任务只有一个目标表,因此,任务编码必须要包含目标表,以便于理解和查找。调度任务主要分为以下3种。
1)实时同步任务。针对实时同步的数据,解析MySQL数据库日志并写入Kafka以后,创建ROUTINE LOAD任务来读取数据。ROUTINE LOAD任务以“rtld+表名”命名。
2)DataX数据同步任务。DataX数据同步任务分为全量和增量同步任务,全量同步任务将全部数据直接写入目标表,增量同步任务将数据先写入临时表,然后通过后置SQL写入目标表。全量同步任务以“sync+目标表名”命名,增量同步任务以“incr_目标表名”命名。
3)数据加工SQL任务。数据加工统一由SQL任务组成,但是针对相同的目标表,会有不同的数据刷新周期,因此SQL任务以“目标表+数据刷新周期”命名。例如dwb_ret_sale_detail_curday、dwb_ret_sale_detail_all分别表示刷新dwb_ret_sale_detail表当日数据和刷新dwb_ret_sale_detail表全量数据。
在调度任务之上,按照业务模块组合成工作流。工作流以“模块名+执行频率”命名,例如ods2dwd_ret_10min表示零售模块每10 min刷新一次ODS层数据到DWD层。
本次项目交付成果包括PC端报表、移动端报表、自助分析报表和实时大屏。其中PC端报表、移动端报表和自助分析报表都是基于观远BI平台开发的,实时大屏基于E-Charts定制化开发的。
5.1
PC端报表
PC端报表主要采用组合图的方式开发,配合少量表格。PC端报表支持多维条件筛选,但是不支持变更展现样式。最典型的案例是线下商品概览报表,图14-15是该类报表的核心指标,图14-16是该类报表关键指标的对比分析,图14-17是该类报表的商品销量排名。
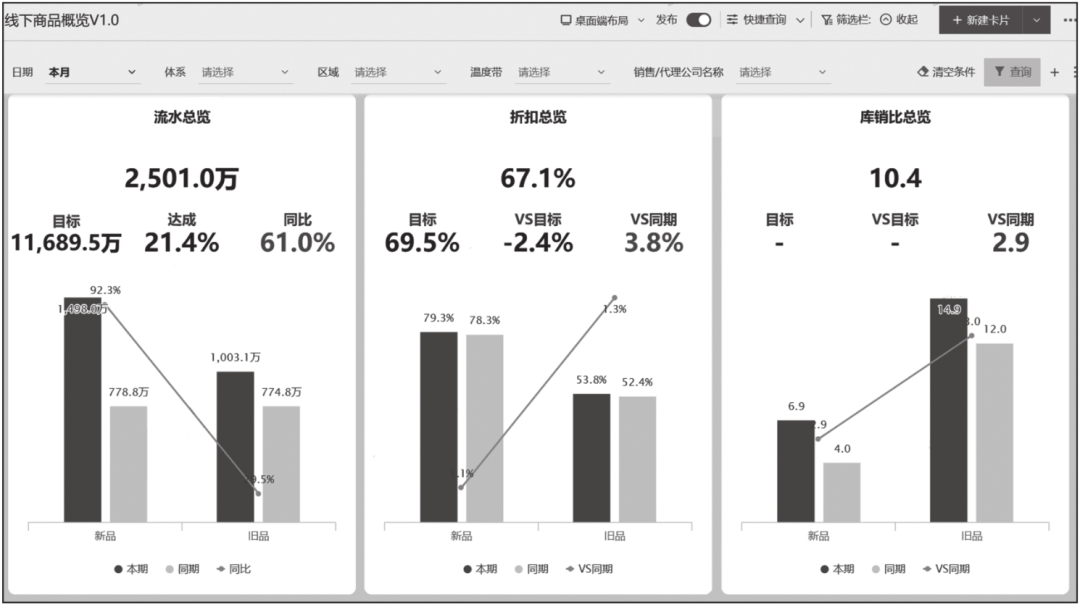
图14-15 线下商品概览报表的核心指标
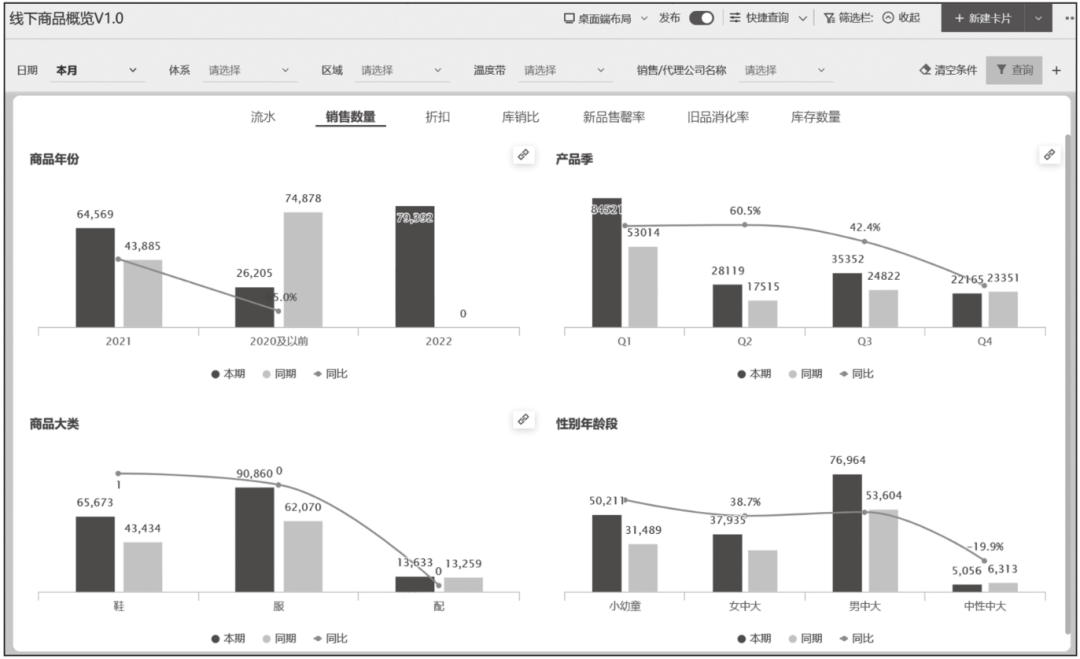
图14-16 线下商品概览报表关键指标的对比分析
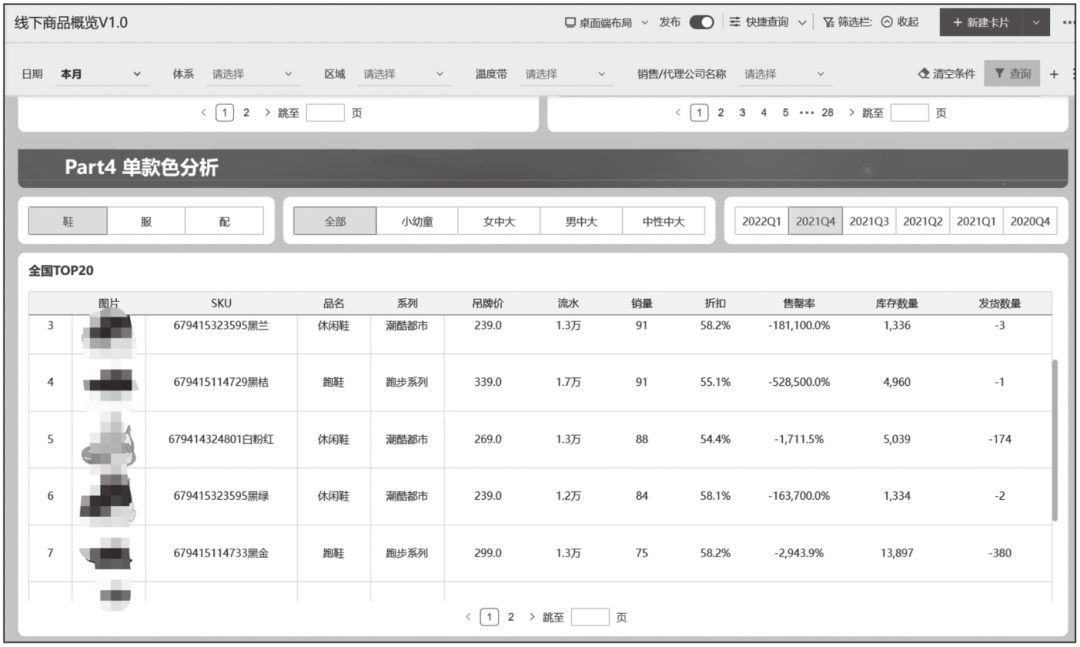
图14-17 线下商品概览报表的商品销量排名
5.2
移动端报表
移动端报表组件更丰富,包含指标卡、组合图、饼图、折线图等多种展现形式,同时针对手机屏幕进行适配。移动端报表也支持多种条件组合筛选。图14-18是移动端报表清单截图。移动端由于屏幕尺寸因素,页面内容被拉长。这里展示简单拼接两张报表的局部截图,组合图标展示效果如图14-19所示,筛选框和表格全屏效果如图14-20所示。
5.3
自助分析报表
自助分析报表是基于预定义的宽表数据集,自由组合维度指标进行分析后产出的报表。由于使用灵活,自助分析报表受到数据分析师的广泛欢迎。自助分析报表也是本次项目构建的重点,因此我们在项目初期就确定了DWS层的大宽表都要作为自助分析的数据源,最终建设了零售、渠道、会员、进销存和售罄率5个自助分析报表。其中,零售自助分析报表展现效果如图14-21所示,进销存自助分析报表展现效果如图14-22所示。

图14-18 移动端报表清单

图14-19 移动端组合图标展示效果
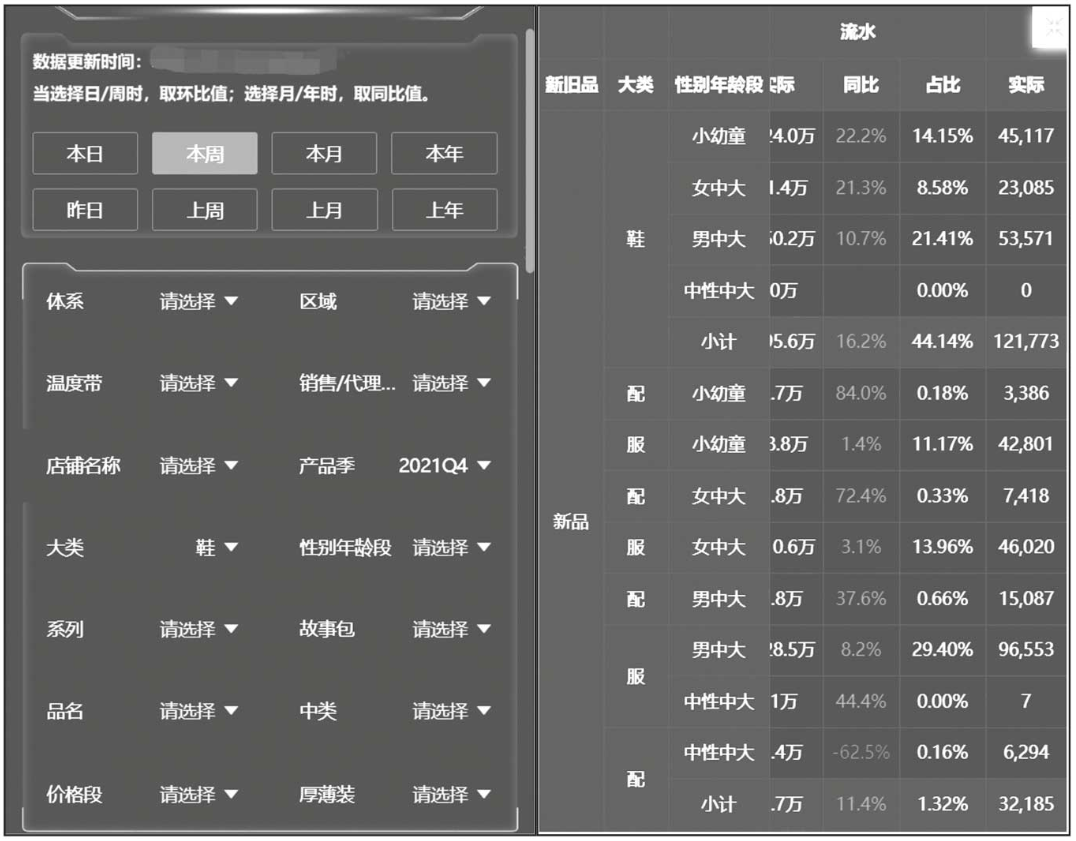
图14-20 移动端筛选框和表格全屏效果
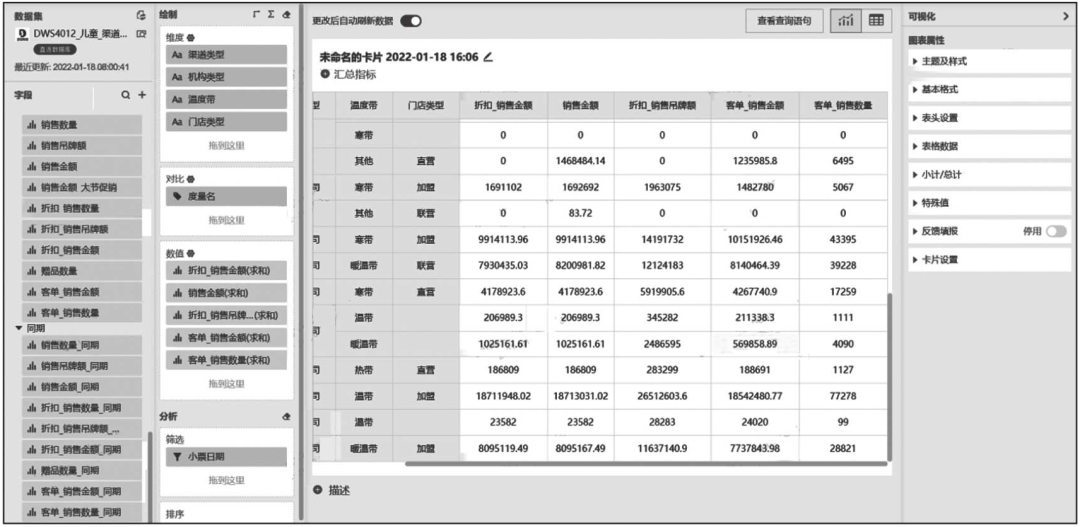
图14-21 零售自助分析报表展现效果
图14-22 进销存自助分析报表展现效果
特步儿童BI项目自2021年4月份启动,经过1个月的需求设计、3个月的开发、2个月的测试,于9月底上线。
数据仓库ODS层主要对接DRP系统、E3系统、SAP系统和业务补录数据,共接入200余张接口表,其中实时接口表15张、增量接口表10张。在仓库层,构建了店铺、商品、日期、分公司、仓库等6个维度模型,20余个DWD层明层模型,11个整合的DWB层指标模型,9个DWS层宽表模型。在集市层,根据具体报表需求构建了30多张实体表和视图,作为报表查询的数据来源。同时,基于观远BI平台开发了27张PC端报表,并通过App适配到移动端,方便用户随时随地查看数据和分析业务状况。
本次项目选择Doris作为数据仓库平台是一个非常正确的选择,主要体现在以下几方面。
1)查询高效。基本上不需要太多优化,90%的页面模块都可以在3s内完成刷新。
2)开发简单。数据接入Doris数据库后不用进行二次迁移,大大降低了开发难度,可以让开发人员把精力集中在模型设计和优化上。
3)运维简单。数据都是通过视图加载到表中的,追溯简单,方便快速定位问题。
4)实时性强。通过30 min的微批处理和秒级延时的实时大屏查询,实现数据时效性飞跃提升,极大地满足了数据分析需求。
5)流处理和批处理结合。Doris除支持强大的流处理外,还支持批处理。
项目建设也不是一帆风顺的,我们在数据仓库设计、任务调度和秒级查询等方面都踩了不少坑。后期,我们计划将集群节点进行拆分,将Kafka数据加载、任务跑批和报表查询分开,减少资源的抢占,让系统可以更加稳定地运行。
以上。
参考:Doris实时数仓实战:https://weread.qq.com/web/reader/e3432570813ab8029g019a69k1ff325f02181ff1de7742fc
点击蓝字 关注我们
