




作为一款高性能MPP架构的数据库,Doris提供了完备的DDL和DML功能,并且支持大部分标准的SQL语言。DDL操作包括CREATE、ALTER、DROP等,DML操作包括INSERT、SELECT、UPDATE、DELETE等,功能齐全。其中,UPDATE、DELETE操作会有一些限制,但是仍然可以满足用户大多数需求。
Doris作为一款简单、易用的分布式数据库,入门非常简单。如果你已经使用过MySQL数据库或者其他数据库,那么你在了解Doris的数据模型和基本数据类型以后,就可以马上上手使用Doris数据库了。作为一款面向未来的OLAP数据库,用户友好是Doris极其看重的一个方向,我们几乎可以参考MySQL来使用Doris数据库。这里说几乎,是因为Doris作为一款分布式架构的分析型数据库,在某些操作上还是会受到分布式架构的影响,和MySQL分库分表的集群模式还是有很大不同。比如,Doris是基于列存储数据的,这和MySQL的行存储有着截然不同的逻辑,在更新、查询、索引等方面也会有很大不同。
在数据类型、系统函数、分布式建表等方面,Doris比同赛道的ClickHouse要好用很多。ClickHouse的数据类型和系统函数名都是由大小写字母组合而成的,并且对大小写敏感,例如Float64、Decimal32(4)、DateTime64等类型和toString、toDecimal64OrZreo等函数。并且,字段类型不能隐式转换,必须要使用相应的函数。
作为一款兼容MySQL的分析型数据库,Doris提供了多种数据类型。Doris支持的数据类型主要分为数值类型、日期时间类型、字符串类型和其他扩展类型。
01
数值类型
Doris支持的数值类型主要有以下几种形式,和MySQL比,只少了MEDIUMINT类型,并且新增了LARGEINT类型。Doris支持的数值类型及其范围如表3-1所示。
从表3-1可以看出,Doris定义的数值类型不仅可以满足我们日常开发需求,而且使用非常简单。在实际项目中,我们一般使用INT表示整数类型、使用DECIMAL表示金额或者比率等,较少使用其他类型。
02
日期时间类型
Doris支持的日期时间类型较MySQL有所精简,仅保留了DATE和DATETIME类型。在实际项目中,我们也仅需这两种类型。当输入的日期格式不合法时,字段自动变成NULL值。Doris支持的日期时间类型及其格式如表3-2所示。
对于其他数据库常用的TIMESTAMP类型,Doris没有提供,如果确实有需要,可以用BIGINT类型代替。但是作为一款OLAP数据库,TIMESTAMP类型有最大和最小时间限制,且容易受时区影响。站在数据仓库角度考虑,TIMESTAMP类型的可读性差,我们在数据建模时应该将其转化成DATETIME类型。
03
字符串类型
相对于MySQL,Doris支持的字符串类型精简了很多,仅保留CHAR、VARCHAR及TEXT类型。Doris支持的字符串类型及其用途表述如表3-3所示。
其中,VARCHAR和TEXT类型的变长字符串是以UTF-8编码存储的,因此通常英文字符占1 B,中文字符占3 B。
VARCHAR类型的字符串长度比较确定,便于数据库分配存储空间,在构建索引时也方便确定存储位置和偏移量;TEXT类型的数据长度则比较灵活,支持用户根据需要变动长度,避免字段长度溢出造成数据插入失败。根据经验,字符串长度比较稳定且总长度在255 B以下时,推荐用VARCHAR类型存储,字符串长度变化比较大时,推荐用TEXT类型存储。
04
其他扩展类型
1. BITMAP类型
BITMAP类型只能用于Aggregate数据模型的表,并且不能用在Key列,建表时需搭配BITMAP_UNION使用。用户不需要指定BITMAP类型数据长度和默认值,长度根据数据的聚合程度调整。BITMAP类型数据只能通过配套的BITMAP_UNION_COUNT、BITMAP_UNION、BITMAP_HASH等函数进行查询或调用。
表3-1 Doris支持的数值类型及其范围
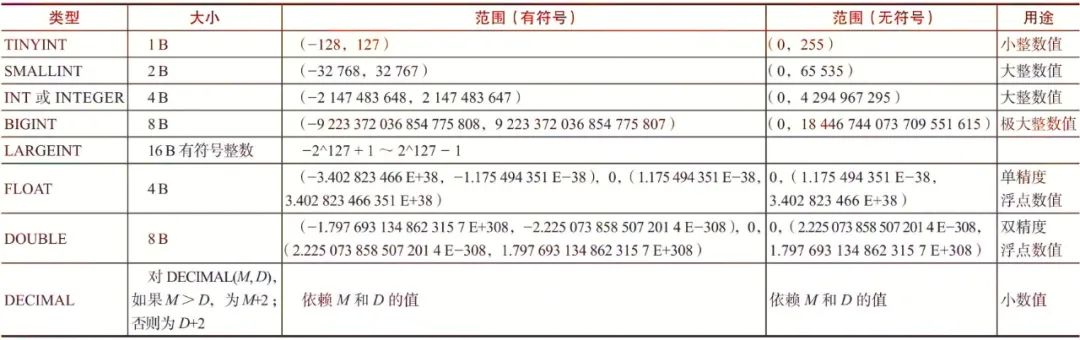
表3-2 Doris支持的日期时间类型及其格式

表3-3 Doris支持的字符串类型及其用途

离线场景下,BITMAP类型数据导入速度慢,在数据量大的情况下查询速度慢于HLL类型数据的查询速度,但优于COUNT DISTINCT。注意:实时场景下,BITMAP如果不使用全局字典,使用BITMAP_HASH()函数计算去重值可能导致千分之一左右的误差。下面展示构建BITMAP类型计算去重值的典型案例。

在实际项目中,对于千万级以下数据去重,不推荐使用BITMAP类型,直接用COUNT DISTINCT,两者性能差不多。
2. HLL类型
HLL类型源自HLL算法。HLL(英文全称HyperLogLog)算法是统计数据集中唯一值个数的高效近似算法,有着计算速度快、节省空间的特点,不需要直接存储集合本身,而是存储一种名为HLL的数据结构。
HLL算法在计算速度和存储空间上都有优势。在时间复杂度上,Sort算法排序时长至少为O(nlogn)。虽然Hash算法和HLL算法一样只需扫描一次全表,仅需O(n)的时间就可以得出结果,但是存储空间上,Sort算法和Hash算法都需要先把原始数据存储起来再进行统计,会导致存储空间消耗巨大,而HLL算法不需要存储原始数据,只需要维护HLL数据结构,故占用空间始终是1280 B。
HLL类型的用法和BITMAP类型类似,仅用于Aggregate数据模型的表,且不能用在Key列,建表时需搭配HLL_UNION使用。用户不需要指定HLL类型数据长度和默认值。长度根据数据的聚合程度调整。HLL类型数据只能通过配套的HLL_UNION_AGG、HLL_RAW_AGG、HLL_CARDINALITY、HLL_HASH进行查询或调用。
在数据量大的情况下,HLL类型模糊去重性能优于COUNT DISTINCT和BITMAP_UNION_COUNT。HLL算法的误差率通常在1%左右,默认可计算去重数据的最大数量为1.6e12,误差率最大可达2.3%。注意:如果去重结果超过默认规格会导致计算结果误差变大,或计算失败并报错。下面展示构建HLL类型计算去重值的典型案例。

3. BOOLEAN类型
BOOLEAN类型也可以简写成BOOL,在各种数据库中都很常见。BOOLEAN类型只有0、1、NULL三个值。在实际项目中,建议用CHAR(1)或者VARCHAR(1)来代替BOOLEAN类型,字段值用Y表示“是”,用N表示“否”。
有了数据类型,我们就可以定义Doris表对象。虽然Doris数据类型和MySQL数据类型非常类似,但是两个数据库的建表语句差异还是非常大的。
建表的基本语法如下:

ENGINE默认支持表类型为OLAP,还支持MySQL、Broker、Hive、Iceberg四种外部表。本节聚焦于OLAP表定义说明,关于外部表在3.4节展开说明。OLAP表定义主要包含列定义、键描述、分区描述、分布描述和键值对五部分内容,其中列定义、键描述、分布描述是必需的,键值对根据需求添加,分区描述在3.3节展开说明。
01
列定义
列定义即确定表的每一列对应的属性,包括列名、列类型、可选的聚合类型、是否为空和默认值。列定义的语法如下:
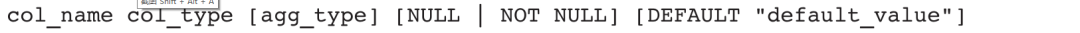
其中,agg_type仅用于Aggregate模型,且仅支持SUM、MAX、MIN、REPLACE、BITMAP_UNION、HLL_UNION等聚合类型。agg_type是可选项,如果不指定,说明该列是维度列(Key列),否则是事实列(Value列)。在建表语句中,所有的Key列必须在Value列之前,一张表可以没有Value列(这样的表叫作维度表),但不能没有Key列。
默认情况下,所有的列允许值为NULL(导入时用\N来表示)。
02
键描述
键描述是指对表的数据模型及主键进行明确定义。键描述是Doris特有的建表特性。键描述内容包括键类型和键清单。
目前,Doris键类型有Aggregate Key、Unique Key、Duplicate Key。StarRocks在Doris键类型Unique Key的基础上增加了Primary Key,用“Delete+Insert”策略替换Unique Key的Merge策略,实现了更高效的查询性能。键清单用来确定Doris的Key列排序,且不同的键类型有不同的键清单要求,具体如下。
❑Aggregate Key:Key列相同的记录,Value列按照指定的聚合类型进行聚合,要求所有未定义聚合类型的列都写入键清单。
❑Unique Key:Key列相同的记录,Value列按导入顺序进行覆盖,键清单为该表的主键字段(支持联合主键)。
❑Duplicate Key:Key列相同的记录,键清单一般为排序字段或者查询字段,主要用于索引优化。在不指定的情况下,Doris表默认为Duplicate Key类型,Key列为列定义中前36 B,如果前36 B的列数小于3,将使用前三列。
再次强调,在建表时,除Aggregate Key外,Value列不需要指定聚合类型。
03
分布描述
分布描述用于定义表数据的分桶数和分布键。分桶数是指数据切分份数,分布键是切分的依据,推荐使用Hash分桶。Hash分桶语法如下:
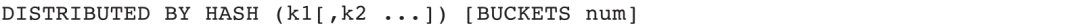
相对于其他MPP架构数据库的分桶和分布机制,Doris的分桶和分布更为灵活。以最常用的Greenplum和ClickHouse为例,这两个数据库的分桶数只能是集群节点数(Greenplum分桶数是Primary Segment,ClickHouse分桶数是主分片数),也就是说数据必须按照指定分布规则分布到每一个节点(Greenplum 6.0之后版本提供了复制表,支持每个节点分布一份数据,提高了小表的JOIN效率,但是浪费了存储空间),不便于扩大集群和提高并发能力。而Doris支持自定义分桶数,如果集群规模比较小,可以选择2、4、6等分桶数;如果集群规模比较大,可以选择8、10、16、32等分桶数。在分布键方面,Greenplum和ClickHouse只支持单字段作为分布键,而Doris支持多个字段组合作为分布键,在建模方面更具优势。
一般来说,数据仓库中的大表和小表是遵循“二八原则”分布的:20%的大表存储80%以上的数据,80%的小表存储不到20%的数据。按照Greenplum和ClickHouse数据库推荐的数据分布方式,数据平均分布到各个节点,如果集群达几十台,甚至上百台,任何表中的数据都需要切分成几十分之一或者几百分之一,而且任何一次查询都需要所有主节点参与计算和数据交互,这显然会耗费大量网络资源,也不利于提高查询并发能力。如果采用类似于复制表的模式,针对80%的小表,每个节点保存一份数据,存储膨胀和数据同步的瓶颈又是很难突破的。Doris是基于分桶数来分布数据的,支持用户根据不同的表设置不同的分桶数,并将数据随机分布到部分节点上。
灵活的分桶数、支持联合字段的分布键,再配合表级副本,Doris可以完美地将数据分布在集群的部分BE节点,这样在读取数据时就有了更高的灵活度、更高的并发度。
04
键值对
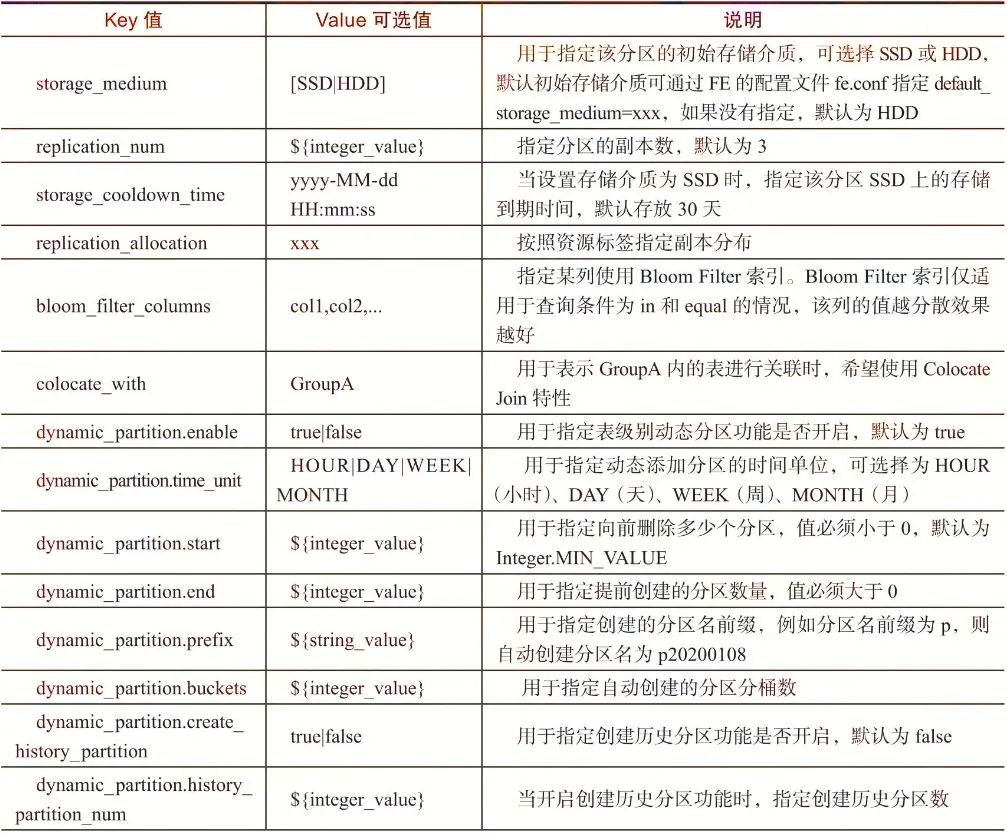
针对OLAP类型的表引擎,PROPERTIES主要用于设置表的存储特性、索引特性、动态分区特性、内存表特性等。键值对表达式为:

其中,键值对分类及其说明如表3-4所示。
表3-4 键值对分类及其说明
键值对相关注意事项如下。
1)当FE配置项enable_strict_storage_medium_check为true,且集群中没有设置对应的存储介质时,建表语句会报错:Failed to find enough host in all backends with storage medium is SSD|HDD。
2)当表为单分区表时,以上键值对为表的属性。当表为两级分区时,这些属性附属于每一个分区。如果希望不同分区有不同的属性,我们可以通过ADD PARTITION或MODIFY PARTITION进行指定。
3)目前,Bloom Filter索引只支持除了TINYINT、FLOAT、DOUBLE类型以外的Key列及聚合类型为REPLACE的Value列。
4)动态分区的键值对需要组合使用,并且动态分区只支持RANGE分区,以小时为单位的分区列,数据类型不能为时间日期类型。
下面举几个具体的例子。
示例1:创建一个OLAP表,使用Hash分桶,使用列存,覆盖相同Key的记录,设置初始存储介质和冷却时间。

示例2:创建一个动态分区表(需要在FE配置中开启动态分区功能),该表每天提前创建3天的分区,并删除3天前的分区。例如今天为2020-01-08,则创建名为p20200108、p20200109、p20200110、p20200111的分区。


除了根据基础语句创建表外,Doris还支持CREATE TABLE LIKE建表语句(用于创建一个表结构和另一张完全相同的空表),同时支持可选复制一些ROLLUP对象。语法模板如下:

复制的表结构包括Column Definition、PARTITIONS、TABLE PROPERTIES等属性,也可以同步复制OLAP表的ROLLUP对象。复制表只需要拥有SELECT权限即可。外部表也支持复制功能。
LIKE模式建表有很多小窍门,在不同的需求场景中,使用的语句不一样。
示例1:在test2库下创建一张表结构和test1.table1相同的空表,表名为table2。
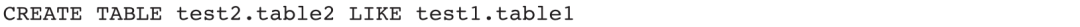
示例2:在test1库下创建一张表结构和table1相同的空表,表名为table2,同时复制table1的r1、r2两个ROLLUP对象。
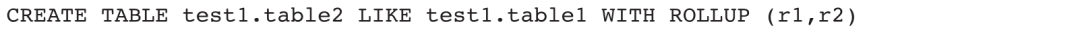
示例3:在test1库下创建一张表结构和table1相同的空表,表名为table2,同时复制table1的所有ROLLUP对象。
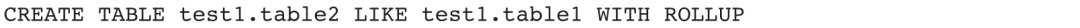
Doris分区表定义有两种模式:一种是3.2节OLAP表定义中介绍的通过PROPERTIES设置动态分区模式;另一种是自定义分区模式。自定义分区模式是通过PARTITION BY关键字实现的,主要分为Range分区和List分区两种。无论Range分区还是List分区,只要是分区字段值不在分区范围内的数据都会被丢弃。
01
Range分区
Range分区也叫范围分区,是通过划定分区键范围来划分分区的。这里主要包括Less Than分区和Fixed Range分区。
Less Than分区使用指定的Key列和指定的数值范围进行分区,一般用于时间维度的划分,有如下限制。
1)分区名称仅支持以字母开头,由字母、数字和下划线组成。
2)目前,Doris仅支持TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME类型的列作为Range分区列。
3)分区为左闭右开区间,首个分区的左边界为最小值。
4)NULL值只会存放在包含最小值的分区。当包含最小值的分区被删除后,NULL值将无法导入。
5)可以指定一列或多列作为分区列。如果分区值缺省,默认填充最小值。Fixed Range分区比Less Than分区灵活些,左右区间完全由用户自己确定,不受其他分区的影响。
示例1:创建Less Than分区。

上述代码会将数据划分成3个分区:[MIN,"2014-01-01"),["2014-01-01","2014-07-01"),["2014-07-01","2014-12-01")。不在这些分区范围内的数据将被视为非法数据而过滤。
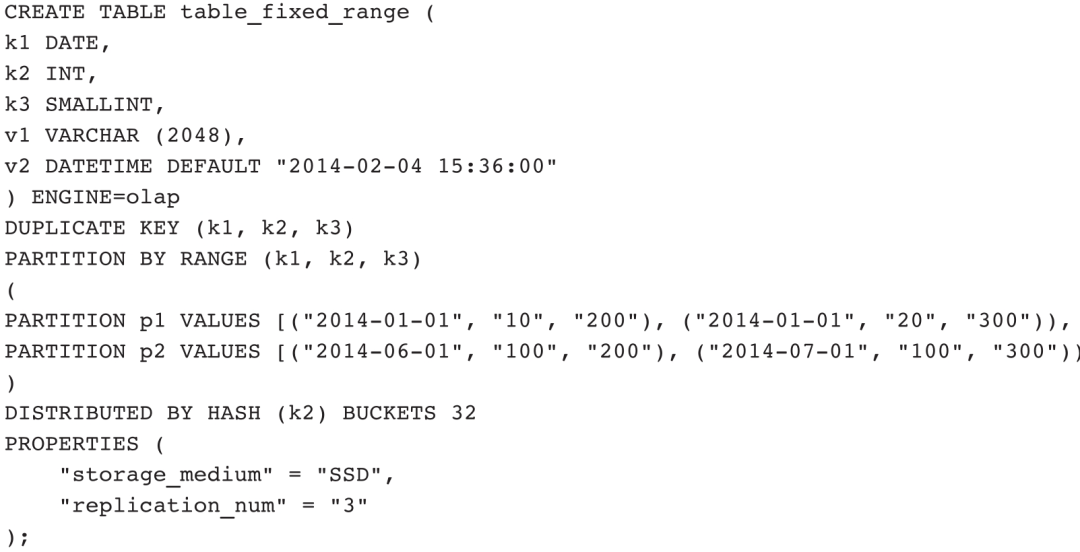
示例2:创建Fixed Range分区,并且按照3个字段划分分区。
02
List分区
List分区是指分区值被明确定义的分区表,主要分为单列分区和多列分区。
单列分区是指仅对单列值进行分区,支持BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、CHAR、VARCHAR等类型字段,分区为枚举值集合,各个分区之间值不能重复。多列分区是指包含多个字段的分区,并且多个字段的值组成元组集合,每个元组包含值的个数必须与分区列数相等。
示例1:创建单列分区。

上述代码将数据划分成3个分区:("1","2","3")、("4","5","6")、("7","8","9")。不在这些分区范围内的数据将被视为非法数据而被过滤掉。
示例2:创建多列分区。
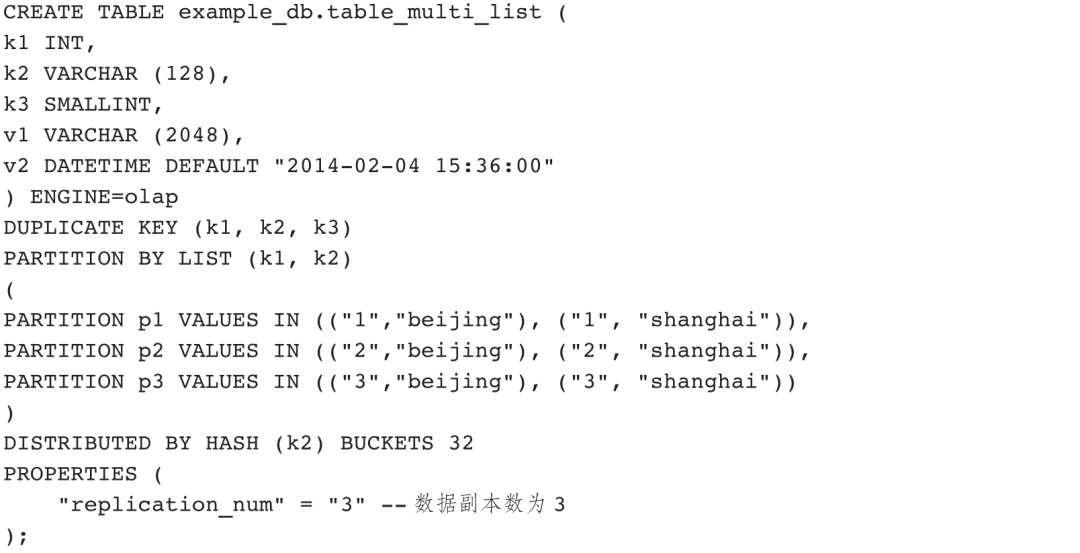
目前,Doris支持4种外部表引擎来读取外部表数据,分别是MySQL、Broker、Hive、Iceberg,它们都是通过表定义的PROPERTIES来补充链接信息的,其中Broker表引擎还用到了BROKER PROPERTIES属性。
01
MySQL表引擎
MySQL表引擎用于引入外部MySQL表以作为Doris的外部表,类似于DBLink。在Doris中创建MySQL表的目的是通过Doris访问MySQL数据库中的数据。而Doris本身并不维护、存储任何MySQL表数据。Doris中的表名可以和MySQL数据库中的表名不一致。
如果是MySQL表引擎,表的访问需要在PROPERTIES中提供以下信息:

示例1:直接通过外部表创建MySQL表。

示例2:通过Resource对象创建MySQL表。

02
Broker表引擎
Broker表引擎主要用于读取外部数据文件映射成Doris数据库的外部表,支持读取HDFS、S3、BOS等存储系统上的文件。
如果是Broker表引擎,表的访问需要通过指定的Broker,并在PROPERTIES提供以下信息:

另外,还需要提供Broker访问需要的Property信息,这可以通过BROKER PROPERTIES传入,例如访问HDFS时需要传入:

根据不同的Broker类型,需要传入的Property信息也不相同。
其中,path中如果有多个文件,用逗号分割。文件名中的逗号用%2c来替代,文件名中的%用%25代替。文件格式支持CSV,以及GZ、BZ2、LZ4、LZO压缩格式。
示例1:创建一个数据文件存储在HDFS上的Broker外部表,数据使用"|"分割,"\n"换行。

示例2:创建一个数据文件存储在BOS上的Broker外部表。


01
Hive表引擎

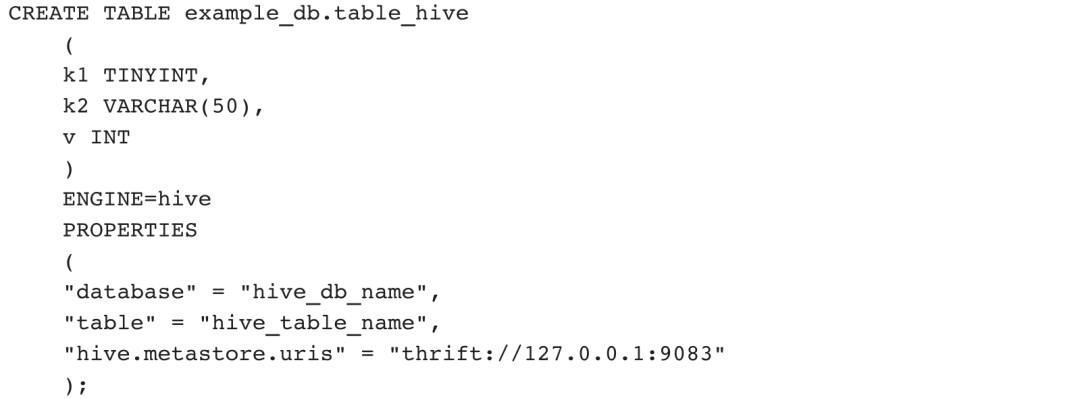
其中,database是Hive表对应的库名,table是Hive表的名,hive.metastore.uris是Hive Metastore的服务地址。
相比Broker表引擎,Hive表引擎支持的存储类型更丰富,并且需要提供的PROPERTIES信息也更少。
示例:创建一个Hive外部表。
04
Iceberg表引擎

其中,database是Iceberg对应的库名;table是Iceberg中对应的表名;hive.metastore.uri是Hive Metastore的服务地址;catalog.type默认为HIVE_CATALOG。当前,Doris仅支持HIVE_CATALOG类型,后续会支持Catalog类型。示例:创建一个Iceberg外部表。

Doris支持灵活的表结构变更,包括修改、删除、清空等操作。
01
修改表
修改表语句用于对已有的表进行修改。修改表操作包含几种:变更表结构(Change Schema)、变更键值对(Change Properties)、变更索引(Change Index)、变更分区(Change Partition)、数据交换(Data Swap)和重命名操作(Rename)。这几种操作不能同时出现在一条修改表语句中。其中,变更表结构和变更聚合是异步操作,任务提交成功则返回,之后可使用SHOW ALTER命令查看任务进度。变更分区是同步操作,命令返回表示执行完毕。另外,Doris1.2.0版本提供了Light Schema Change功能,表结构变更可以同步生效。
(1)变更表结构
变更表结构操作包括新增字段、删除字段、修改字段等,可以使用以下语法:
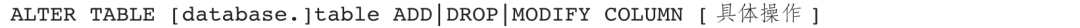
常见操作示例如下。
1)向example_db.my_table的col1后添加一个Key列new_col(非聚合模型):
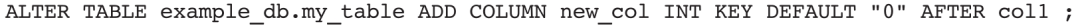
2)向example_db.my_table的col1后添加一个Value列new_col SUM(聚合模型):
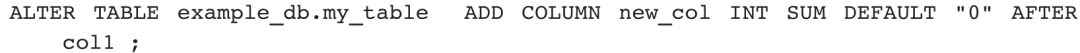
3)向example_db.my_table添加多列(聚合模型):
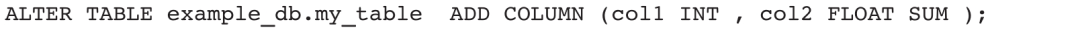
4)从example_db.my_table中删除一列:
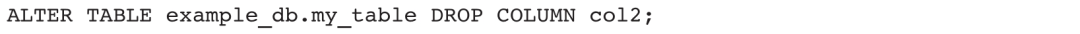
5)修改example_db.my_table的Key列col1的类型为BIGINT,并移动到col2列后面:
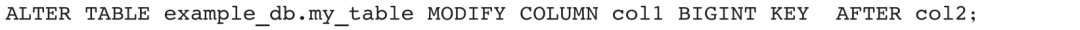
6)修改列注释:
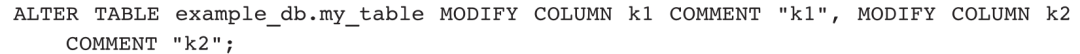
(2)变更键值对
变更键值对用于修改表的PROPERTIES内容,操作示例如下。
1)修改表的默认副本数量,新建分区副本数量默认为该值:
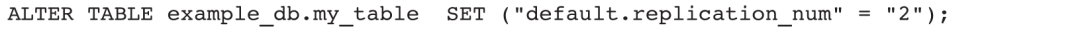
2)修改单分区表的实际副本数量(只限单分区表):

3)修改表的布隆过滤器列:
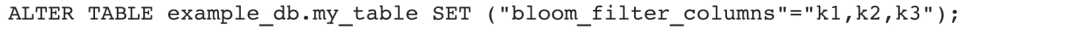
4)修改表的Colocate属性:
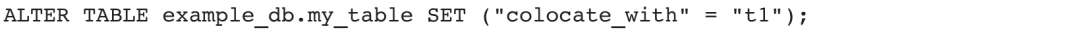
5)将表的分桶方式由随机分布改为Hash分布:

6)修改表的动态分区属性(支持未添加动态分区属性的表添加动态分区属性):
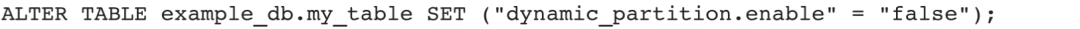
7)修改表的in_memory属性:
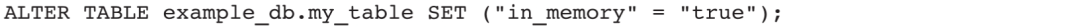
8)在Unique模型表中批量删除数据:
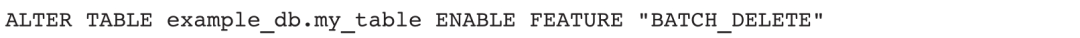
(3)变更索引操作示例
1)在table1上为siteid创建Bitmap索引:

2)删除table1上siteid列的Bitmap索引:

(4)变更分区操作包括修改分区、删除分区、增加分区等。常见操作示例如下。
1)增加分区。现有分区[MIN,2013-01-01),增加分区[2013-01-01,2014-01-01),使用默认分桶方式:

2)增加分区。使用新的分桶数:
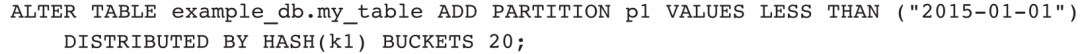
3)修改分区副本数:
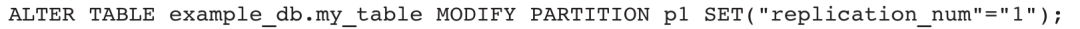
4)批量修改指定分区:
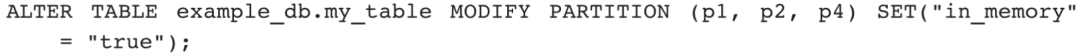
5)批量修改所有分区:

6)删除分区:

(5)数据交换操作
交换操作包括单分区表数据交换和分区表分区数据交换两种。交换操作仅适用于内部表,且在Doris0.14及以后版本才支持。交换操作本质上是对两个表中的数据进行替换。
单分区表数据交换语句如下:
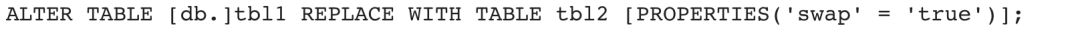
其中,swap参数默认为true。如果swap参数为true,执行语句后,tbl1表中的数据为tbl2表中的数据,tbl2表中的数据为tbl1表中的数据,即两张表中的数据发生了互换。如果swap参数为false,执行语句后,tbl1表中的数据为tbl2表中的数据,而tbl2表被删除。
当swap参数为true时,交换操作等价于:

分区表分区数据交换是通过临时分区实现的,操作语句如下:

(6)重命名操作
重命名操作包括重命名表、重命名Rollup、重命名Partition。常见操作示例如下。
1)将表名table1修改为table2:

2)将表example_table中名为rollup1的rollup修改为rollup2:
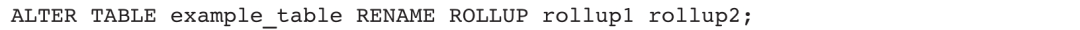
3)将表example_table中名为p1的partition修改为p2:
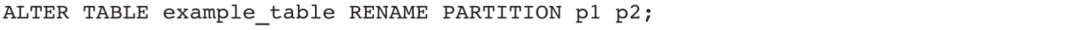
02
删除表
删除表语句如下:
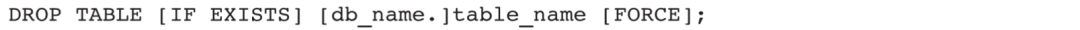
执行删除表语句一段时间后(默认是1天),用户可以通过RECOVER语句恢复被删除的表。但是如果执行DROP TABLE FORCE语句,系统不会检查该表是否存在未完成的事务,将直接删除表并且不能恢复,一般不建议执行此操作。
03
清空表
清空表语句如下:
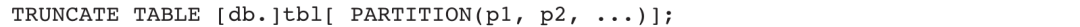
清空表语句用于清空表中数据,但保留表或分区,被删除的数据不可恢复。不同于DELETE语句,该语句只能清空指定的表或分区中数据,不能添加过滤条件,同时不会对查询性能造成影响。使用该命令时,表状态需为NORMAL,即不允许执行Schema变更等操作。
清空表包含两种操作:第一种是清空表,第二种是清空分区。举例如下。
1)清空example_db下的表tbl:

2)清空表tbl的p1和p2分区:

01
创建视图

示例1:在example_db上创建视图example_view。

示例2:创建一个包含COMMENT的视图。

02
修改视图
视图只有结构定义,没有数据存储,因此只存储在FE节点的元数据中。在使用视图时,Doris会执行视图定义中的查询语句并返回结果,因此,修改视图等价于修改视图的查询语句,基本语法如下:

示例:修改example_db上的视图example_view。

03
删除视图
由于视图实际上不存储数据,删除视图其实就是删除数据库中对应的元数据信息。删除视图用DROP VIEW语句,语法模板如下:

不管数据查询还是数据加工,都少不了系统内置函数的帮助。Doris内置函数包括日期函数、正则匹配函数、BITMAP函数、JSON函数、表函数、窗口函数等。
01
日期函数
日期函数(TIME_ROUND)用于取日期时间的上限和下限,类似于Hive和Oracle的trunc函数。
TIME_ROUND函数由两部分组成:TIME部分可以是SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、YEAR,ROUND部分可以是FLOOR(下限)、CEIL(上限),这两部分组合起来就有14种形式。该函数的参数可以变化,进而衍生出更多类型。TIME_ROUND的参数有以下4种形式:

其中,period指定每个周期有多少个TIME单位,默认为1;origin指定周期的开始时间,默认为1970-01-01T00:00:00。
该函数应用举例如下。
1)获取2022年2月10日对应的月初第一天和下月的第一天:
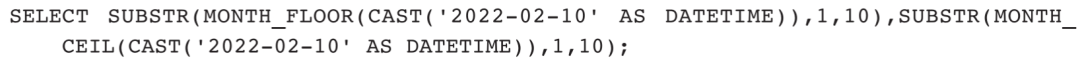
2)获取2022年2月10日所在周的第一天和最后一天:
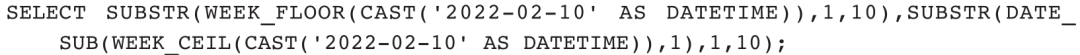
02
正则匹配函数
正则匹配函数包括REGEXP、REGEXP_EXTRACT、REGEXP_REPLACE和NOT REGEXP,分别表示正向匹配、提取、替换和反向匹配,示例如下。
1)查找k1字段中以billie为开头的所有数据:
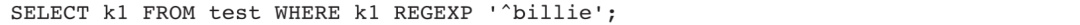
2)查找k1字段中以ok为结尾的所有数据:
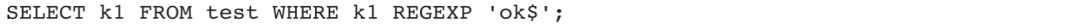
3)去掉k1字段中前置的0:
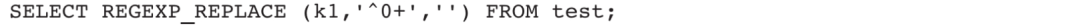
4)查找k1字段中不以billie开头的所有数据:
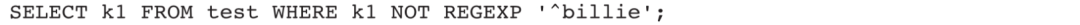
03
BITMAP函数
Doris是基于MPP架构构建的,在使用COUNT DISTINCT语句做精准去重时,可以保留明细数据,灵活性较高。但是,在查询过程中需要进行多次数据重分布,导致查询性能随着数据量增加而直线下降。BITMAP函数可以解决上述问题。
Doris中常用的BITMAP函数包括BITMAP_EMPTY、BITMAP_HASH、BITMAP_UNION等。BITMAP_EMPTY用于返回一个空的Bitmap,主要用于执行INSERTINTO或Stream Load任务时填充默认值,例如:

当UNION ALL字段为空时,不能直接用NULL,需要用BITMAP_EMPTY函数,例如:

BITMAP_HASH用于对任意类型的输入计算32位的哈希值,返回包含哈希值的Bitmap,主要用于在Stream Load任务中将非整型字段导入Doris表的Bitmap字段。
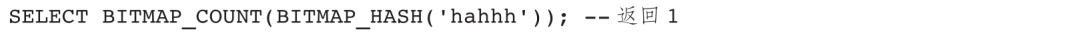
BITMAP_UNION用于对Bitmap类型字段进行汇总,常见使用场景如下。
1)针对Aggregate模型汇总ticket_id字段:

2)与BITMAP_COUNT函数组合求得ticket_id字段的去重汇总值:

04
JSON函数
顾名思义,JSON函数是处理JSON格式数据的函数。JSON格式自诞生以来,以简洁、灵活的特性,作为网络传输数据的首选格式使用越来越普及。随着NoSQL的发展,越来越多的数据直接以JSON格式存储,因此JSON函数成为数据处理的得力助手
get_json_double()、get_json_int()、get_json_string()函数可分别提取JSON字符串内指定路径的数值、整型、字符串内容。json_path必须以“$”符号开头,以“.”为分割符,如果路径中包含“.”,使用双引号包围起来。“[]”表示数组下标(从0开始)。路径中不能包含"、[、]。如果json_string格式不对,或json_path格式不对,或无法找到匹配项,返回NULL。
示例1:获取key为"k1"的浮动类型值。

示例2:获取所有的k1对应的值。
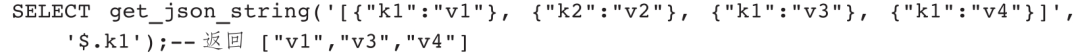
JSON_ARRAY用于生成一个包含指定元素的JSON数组,未指定元素时返回空数组。JSON_OBJECT用于生成一个包含指定Key-Value对的JSON对象,当Key值为NULL或者传入参数个数为奇数时,返回异常错误。
示例1:生成JSON数组。
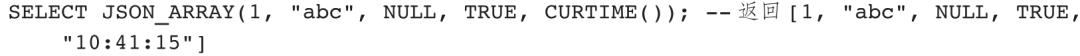
示例2:生成JSON对象。
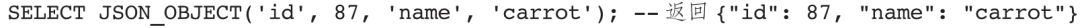
05
表函数
表函数主要用于将一条记录转换成多条记录,需要配合Lateral View使用。表函数主要有EXPLODE_BITMAP、EXPLODE_SPLIT、EXPLODE_JSON_ARRAY,可分别将Bitmap对象、字符串、JSON数组展开形成多条记录。其中,EXPLODE_JSON_ARRAY主要包含下面3种用法:

表函数是Doris 1.0以后版本才支持的,使用前需要设置SET enable_lateral_view=true,应用示例如下。
创建一张简单的表test_explode,只有k1、k2两个字段,并初始化两条记录。

1)构建Bitmap对象,并通过EXPLODE_BITMAP展开形成多条记录:
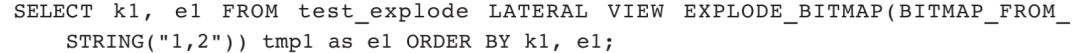
2)通过EXPLODE_SPLIT函数拆分字符串并形成多条记录:

3)通过EXPLODE_JSON_ARRAY_INT函数解析JSON对象并形成多条记录:

以上代码执行结果如图3-1所示。

06
窗口函数

窗口函数由Function函数、PARTITION BY子句、ORDER BY子句和Window子句4部分组成,除Function函数以外,其他都可以省略。
(1)Function函数
目前,Doris支持的Function函数包括AVG()、COUNT()、DENSE_RANK()、FIRST_VALUE()、LAG()、LAST_VALUE()、LEAD()、MAX()、MIN()、RANK()、ROW_NUMBER()和SUM()等。
(2)PARTITION BY子句
PARTITION BY子句和GROUP BY类似,可将输入行按照指定的列数(一列或多列)分组,将相同值的行分到一组。
(3)ORDER BY子句
ORDER BY子句和外层的ORDER BY基本一致。与外层ORDER BY唯一不同的是,OVER从句中的ORDER BY n(n是正整数)只是用于指定逐行聚合计算的顺序,而外层的ORDER BY n表示对第n列排序。
(4)Window子句
(4)Window子句Window子句用来为窗口函数指定一个运算范围,以当前行为准,前后若干行作为分析函数运算的对象。Window子句支持的方法有AVG()、COUNT()、FIRST_VALUE()、LAST_VALUE()和SUM()。
Window子句语法如下:

此外,Doris还支持自定义函数,但是自定义函数的过程过于复杂,建议读者先了解Doris函数的运作机制,然后通过修改源代码实现。
参考:Doris实时数仓实战:https://weread.qq.com/web/reader/e3432570813ab8029g019a69?
