




Doris的查询引擎是基于MPP框架的火山模型,是从早期的Apache Impala演化而来的。Doris会基于SQL语句先生成一个逻辑执行计划,然后根据数据的分布,形成一个物理执行计划。物理执行计划涉及多个Fragment,Fragment之间的数据传输则是由Exchange模块完成的。通过Exchange模块,Doris在执行查询任务时就有了数据重分布(Reshuffle)能力,让查询不再局限于数据存储节点,从而更好地利用多节点资源并行进行数据处理。基于MPP框架的查询引擎执行流程示意图如图1-12所示。
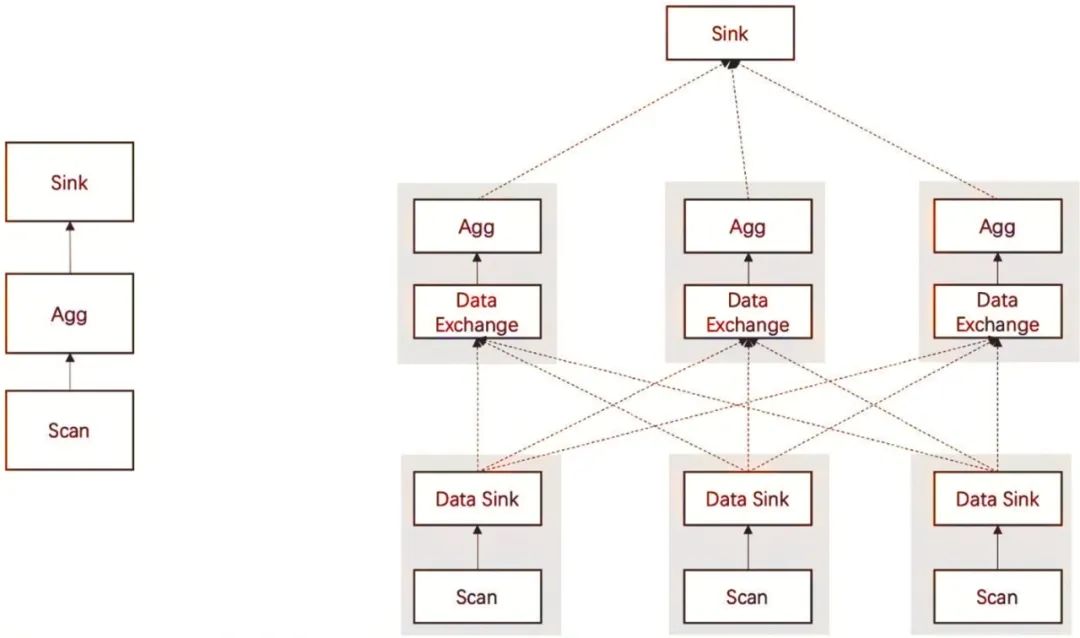
图1-12 基于MPP框架的查询引擎执行流程示意图
逻辑执行计划的Agg阶段分为先重分布数据再汇总两个步骤,这个过程和Hadoop类似,都是按照相同的Key进行数据重分布。
除了通过并行设计来提高查询效率外,Doris还对很多具体的查询算子进行了优化,比如图1-13中的聚合算子。
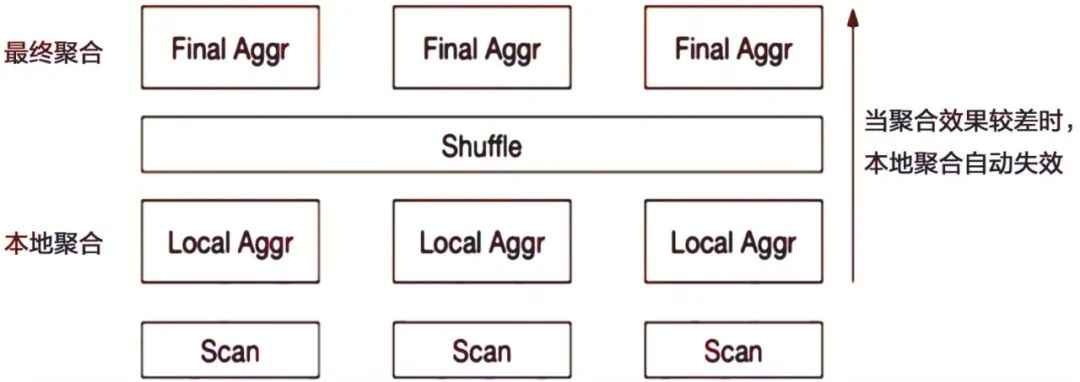
图1-13 聚合算子
在Doris中,聚合算子被拆分成两级聚合:第一级聚合是在数据所在节点,以减少第二级聚合的数据;而第二级聚合将Key相同的数据汇聚到同一个节点,进行最终的聚合。
在此基础上,Doris还实现了自适应聚合。首先我们要知道,聚合算子是一种阻塞型算子,需要等全部数据处理完后,才会将数据发送给上层节点。而自适应聚合是在第一级聚合中,如果发现聚合效果很差,即使聚合后也无法有效减少需要传输的数据,则会自动停止第一级聚合,转换为非阻塞的流式算子,直接将读取的数据发送到上层节点,从而避免不必要的阻塞等待。
针对Join算子,Doris也进行了大量优化,其中Runtime Filter是一种很重要的优化方式。在两个表的Join操作中,我们通常将右表称为BuildTable,将左表称为ProbeTable。在实现上,通常首先读取右表中的数据,在内存中构建一个HashTable,然后开始读取左表中的每一行数据,并在HashTable中进行连接匹配,返回符合连接条件的数据。通常来说,左表的数据量会大于右表的数据量。
Runtime Filter的设计思路是在右表内存中构建HashTable的同时,为连接列生成一个过滤器,之后把这个过滤器推给左表。这样,左表就可以利用过滤器对数据进行过滤,从而减少Probe节点需要传输和比对的数据。这种过滤器被称为Runtime Filter。针对不同的数据,Doris设计了不同类型的过滤器,例如In Predicate、Bloom Filter和Min Max。用户可以根据不同场景选择不同的过滤器。
Runtime Filter实现逻辑示意图如图1-14所示。Runtime Filter适用于大部分Join场景,包括节点的自动穿透,可将过滤器下推到最底层的扫描节点,例如分布式Shuffle Join中,可先将多个节点产生的过滤器进行合并,再下推到数据读取节点。
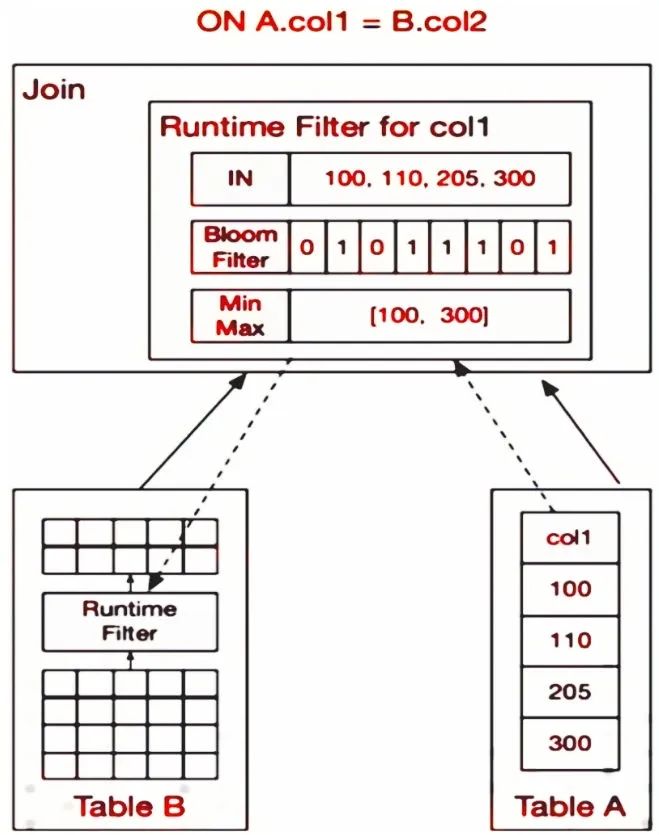
图1-14 Runtime Filter实现逻辑示意图
除了查询执行层面的优化,Doris在查询优化器方面也做了大量改进。Doris中的查询优化器能够同时进行基于规则和基于代价的查询优化。在基于规则的查询优化方面,Doris完成了包括但不限于以下方面的改进。
1)常量折叠。常量折叠可以预先对常量表达式进行计算,计算后的结果有助于规划器进行分区分桶裁剪,以及执行层利用索引进行数据过滤等。例如将where event_dt>=cast(add_months(now(),-1)as date)折叠成where event_dt>=2022-02-20。
2)子查询改写。将子查询改写为Join操作,从而利用Doris在Join算子上做的一系列优化来提升查询效率,例如将select*from tb1 where col1 in(select col2 from tb2)a改写成select tb1.*from tb1 inner join tb2 on tb1.col1=tb2.col2。
3)提取公共表达式。提取公共表达式可以将SQL中的一些析取范式转换成合取范式,而合取范式通常对执行引擎是比较友好的,可以将查询条件重组或者下推,减少数据扫描和读取的行数,例如将条件where(a>1 and b=2) or (a>1 and b=3)or (a>1 and b=4)转化成where a>1 and b in (2,3,4),明显后者的判断速度比前者的快很多。
4)智能预过滤。智能预过滤可以将SQL中的析取范式转换成合取范式并提炼出公共条件,以便预先过滤部分数据,从而减少数据处理量。
5)谓词下推。Doris中的谓词下推不仅可以穿透查询层,还能进一步下推到存储层,利用索引进行数据过滤,如图1-15所示。
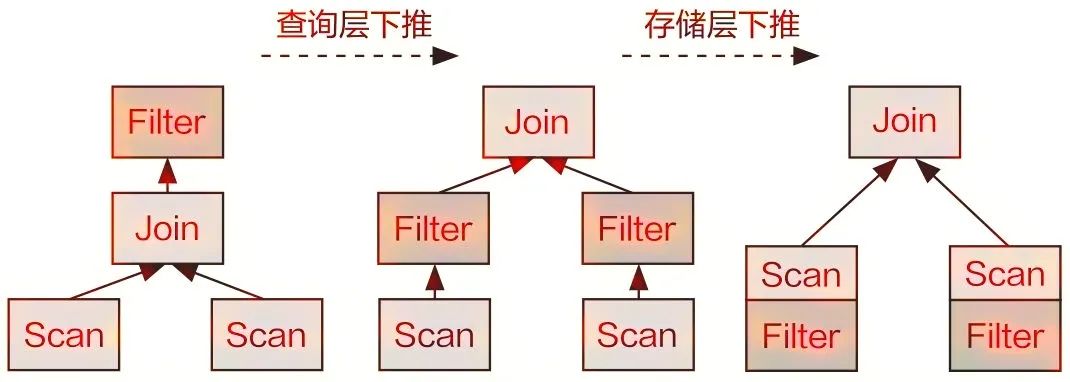
而在基于代价的查询优化方面,Doris主要针对Join算子进行了大量优化。
Join Reorder可以通过一些表的统计信息,自动调整Join顺序。而Join顺序的调整可有效减小Join操作中生成的中间数据集的大小,从而加速查询的执行,如图1-16所示。
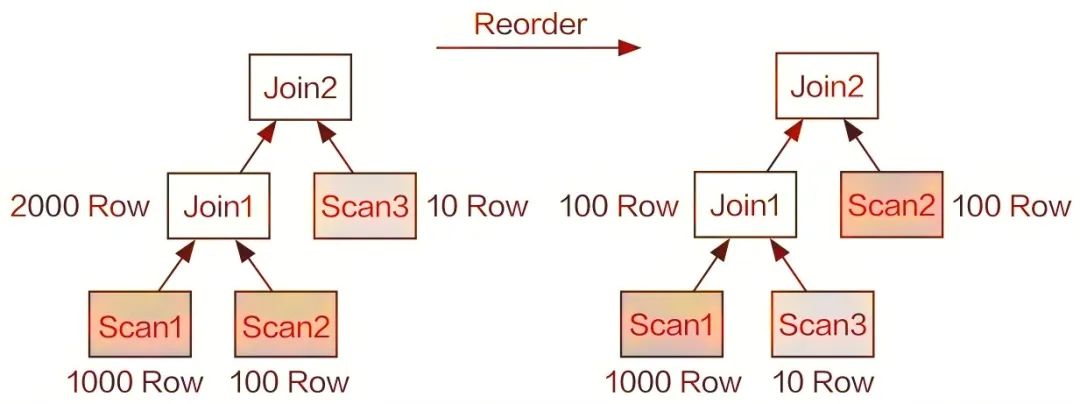
图1-16 Join Reorder优化示意图
Colocation Join可以利用数据的分布情况,将原本需要去重后才能进行关联的数据,在本地完成关联,从而避免去重时大量的数据传输,如图1-17所示。
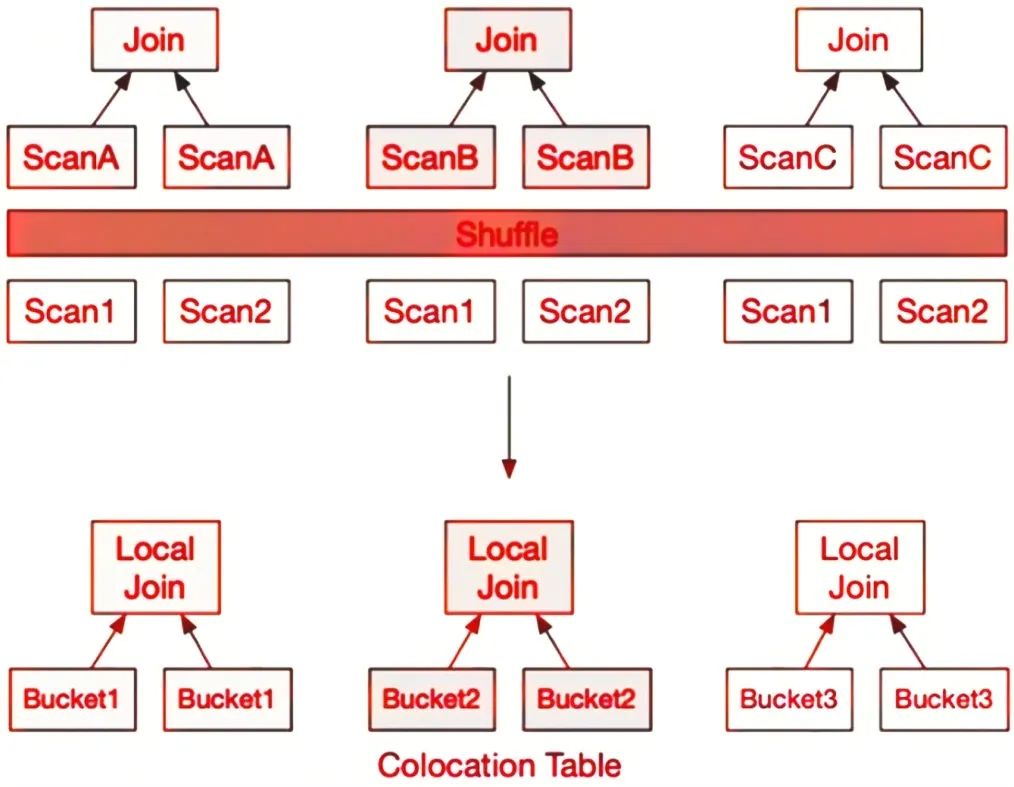
图1-17 Colocation Join优化示意图
Bucket Join是Colocation Join的通用版本。Colocation Join需要用户在建表时就指定表的分布,以保证需要关联查询的若干表有相同的数据分布。而Bucket Join会更智能地判断SQL中关联条件和数据分布之间的关系,将原本需要同时去重左右两张表中数据的操作,变成将右表数据重分布到左表所在节点,从而减少数据的移动,如图1-18所示。
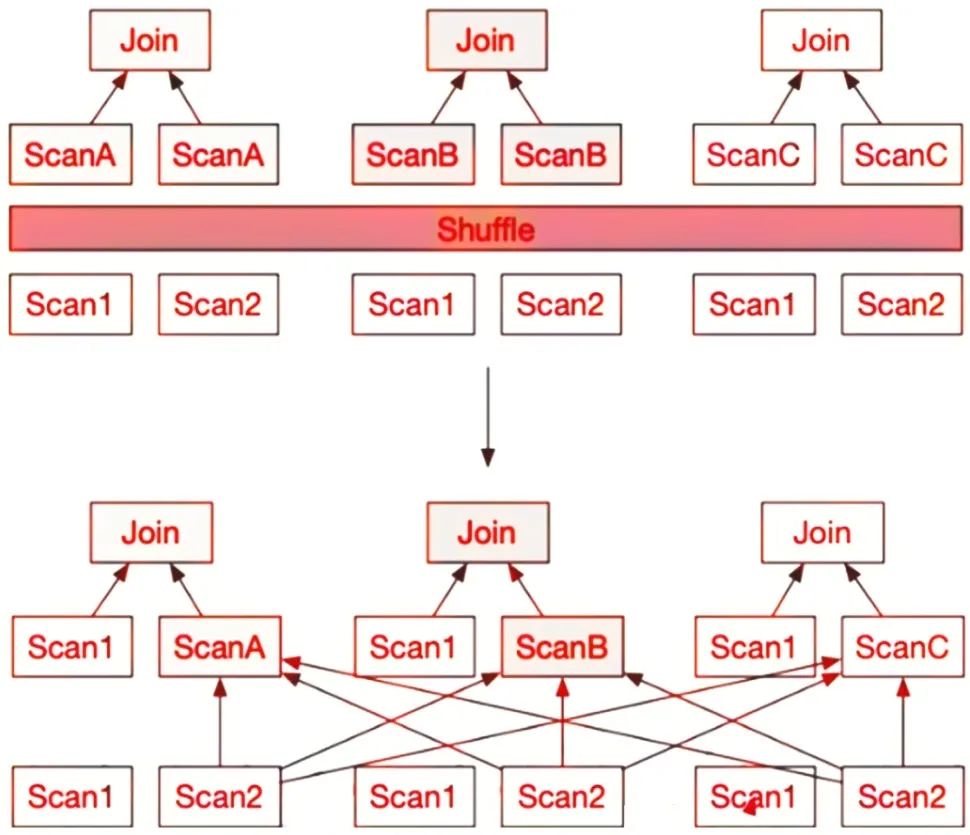
图1-18 Bucket Join优化示意图
传统的数据库都是典型的迭代模型,执行计划中的每个算子通过调用下一个算子的next()方法来获取数据,从最底层的数据块中一条一条读取数据,最终返给用户。它的问题在于每个Tuple都要调用一次函数,开销太大,而且因为CPU每次只处理一条数据,无法利用CPU技术升级带来的新特性,比如SIMD。向量化模型每次处理的是一批数据,这些数据会被保存在一种叫作向量的数据结构里,由于每次处理的是一批数据,因此可以在每个Batch内做各种优化。简单地说,向量化执行引擎=高效的向量数据结构(Vector)+批量化处理模型(nextBatch)+Batch内性能优化(例如SIMD等)。
原本向量化执行引擎只是一个概念,是ClickHouse将其变成了现实,并展示出强大性能。通过向量化执行引擎原理的介绍,我们可以看出,向量化执行引擎非常适合基于列存储的OLAP数据库,可以极大地提高并行查询效率。在ClickHouse之后,OLAP数据库配套向量化执行引擎几乎已经成为标配。目前,除了Doris以外,openGuass、Polar-x、TDSQL实现了部分或所有向量化执行引擎功能。
Doris是在0.15版本中引入向量化执行引擎的,并在1.0版本中逐渐成熟。根据Doris的演进计划,向量化执行引擎会逐步替换当前的行式SQL执行引擎,以充分释放CPU的计算能力,达到更强大的查询性能。
参考:Doris实时数仓实战:https://weread.qq.com/web/reader/e3432570813ab8029g019a69?
