引言
在大数据时代,Apache Flink以其卓越的流处理能力,成为企业处理实时数据的利器。然而,随着数据量的不断增长,Flink性能优化成为了开发者必须面对的挑战。本文将从内存调优、任务调度优化、SQL性能优化等多个维度,深入探讨Flink性能优化的实战技巧,并提供详细的代码示例。
一、资源优化:内存与CPU配置
1.1 内存资源配置
内存是Flink任务运行的核心资源之一。合理的内存配置可以显著提升任务性能,避免频繁的垃圾回收(GC)导致的延迟。Flink提供了多种内存配置参数,以下是一些常用的配置:
-- 设置JVM堆内存大小SET 'env.java.opts' = '-Xms2048m -Xmx2048m';-- 设置Flink管理内存的大小SET 'taskmanager.memory.managed.size' = '512m';-- 设置网络缓冲内存的大小SET 'taskmanager.memory.network.min' = '64m';SET 'taskmanager.memory.network.max' = '1gb';
1.2 CPU资源配置
CPU资源的合理分配同样重要。Flink允许开发者设置作业的并行度,以充分利用多核CPU的优势:
-- 设置全局默认的并行度SET 'parallelism.default' = 8;-- 对特定操作设置更高的并行度SELECT COUNT(*) FROM input_streamGROUP BY window(TUMBLING, INTERVAL '5' SECONDS)-- 这里隐含地设置了该操作的并行度
二、任务调度优化
2.1 Task调度策略优化
在Flink作业的部署和运行过程中,TaskManager的调度策略对性能有直接影响。例如,减少userjar的下载次数可以降低JobManager的分发压力:
// 伪代码示例:优化userjar下载逻辑if (isSameNode()) {shareUserJarDownload();} else {downloadUserJar();}
2.2 Checkpoint跨机房副本
跨机房的Checkpoint副本对于提高Flink作业的容灾能力至关重要。以下是实现Checkpoint副本制作的示例代码:
// 伪代码示例:实现Checkpoint副本制作Checkpoint checkpoint = ...; // 获取Checkpoint对象CheckpointReplicationService service = new CheckpointReplicationService();service.replicateCheckpoint(checkpoint, targetDataCenter);
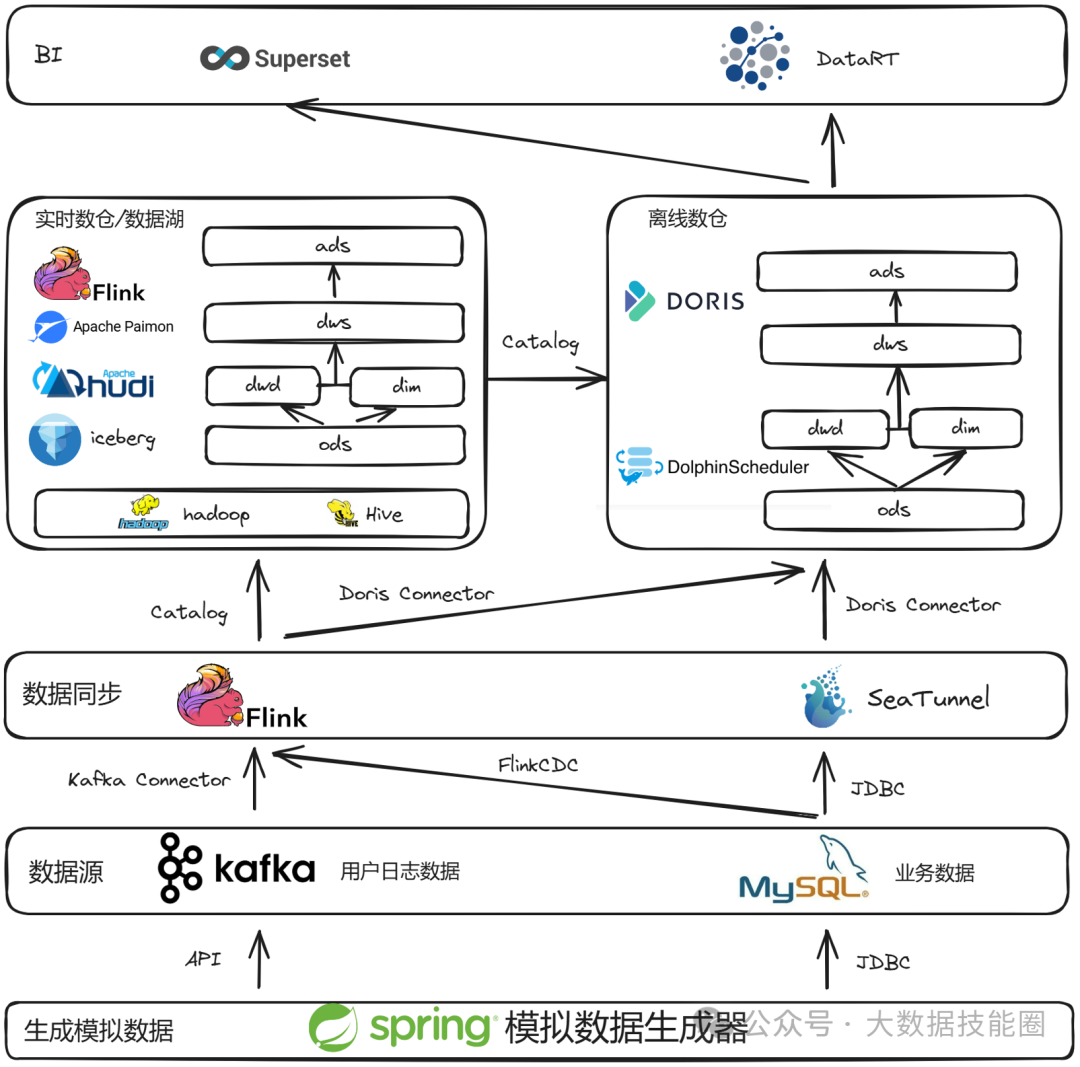
这或许是一个对你有用的开源项目,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning https://github.com/Mrkuhuo/data-warehouse-learning 项目演示:
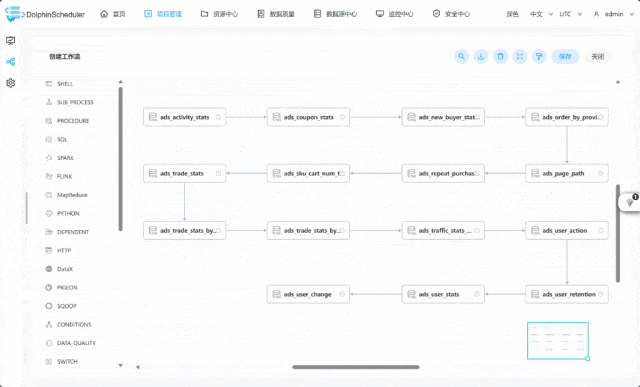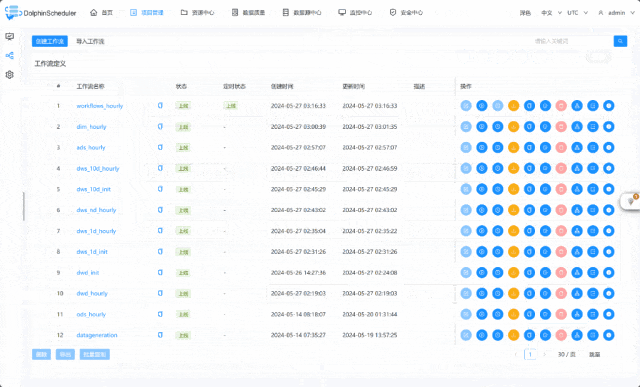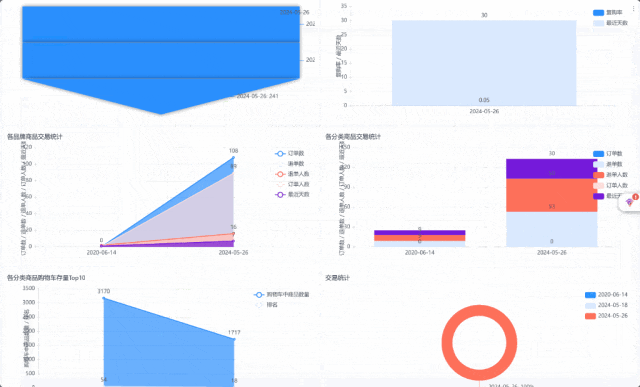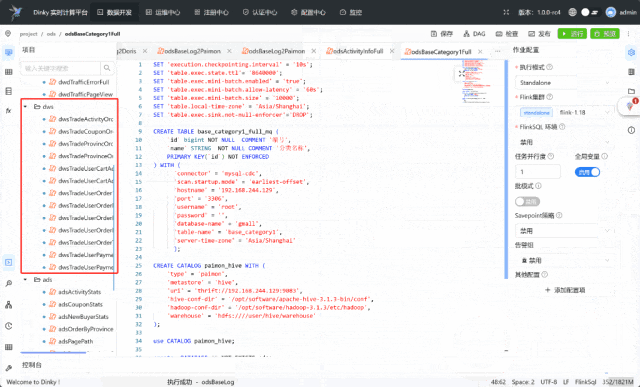
三、SQL性能优化
3.1 数据源读取效率
Flink SQL提供了丰富的数据源接口,合理的读取策略可以提高数据源的读取效率:
-- 通过并行读取提高数据源的读取效率CREATE TABLE input_table (id INT,data STRING) WITH ('connector' = 'kafka','topic' = 'input_topic','properties.bootstrap.servers' = 'localhost:9092','scan.startup.mode' = 'latest-offset','parallelism' = '4');
3.2 状态管理优化
状态管理是Flink SQL中的一个关键环节。使用RocksDB作为状态后端,可以提供更高效的本地状态存储:
-- 设置RocksDB作为状态后端CREATE TABLE state_table (id INT,count INT) WITH ('connector' = 'kafka','topic' = 'input_topic','properties.bootstrap.servers' = 'localhost:9092','scan.startup.mode' = 'latest-offset','state.backend' = 'rocksdb','parallelism' = '4');
四、系统配置调优
4.1 网络配置优化
网络传输是Flink作业中的瓶颈之一。优化网络缓冲区大小和调整序列化格式,可以减少网络传输的延迟和提高数据吞吐量:
-- 设置网络缓冲区大小SET 'taskmanager.network.memory.fraction' = 0.3;-- 设置序列化格式为更高效的AvroSET 'table.exec.resource.default-serialization-format' = 'avro';
4.2 异常处理与监控
合理的异常处理机制和实时监控系统对于及时发现和解决Flink作业中的问题至关重要:
// 伪代码示例:集成监控系统MonitoringSystem monitoringSystem = new MonitoringSystem();monitoringSystem.registerJob(jobId);// 异常处理示例try {// Flink作业执行逻辑} catch (Exception e) {monitoringSystem.reportError(jobId, e);}
五、总结
Flink性能优化是一个复杂的过程,涉及到资源配置、任务调度、SQL优化等多个方面。通过细致的调优,我们不仅可以提升Flink作业的处理速度,还可以增强作业的稳定性和容错能力。
项目文档地址
添加作者进大数据交流群