




1. SPARK节点
1.1 综述
Spark 任务类型用于执行 Spark 应用。对于 Spark 节点,worker 支持两个不同类型的 spark 命令提交任务:
(1) spark submit 方式提交任务。
(2) spark sql 方式提交任务。
1.2 创建任务
•点击项目管理 -> 项目名称 -> 工作流定义,点击”创建工作流”按钮,进入 DAG 编辑页面:
•拖动工具栏的 任务节点到画板中。
任务节点到画板中。
1.3 任务参数
•程序类型:支持 Java、Scala、Python 和 SQL 四种语言。
•主函数的 Class:Spark 程序的入口 Main class 的全路径。
•主程序包:执行 Spark 程序的 jar 包(通过资源中心上传)。
•SQL脚本:Spark sql 运行的 .sql 文件中的 SQL 语句。
•部署方式:
(1) spark submit 支持 cluster、client 和 local 三种模式。
(2) spark sql 支持 client 和 local 两种模式。
•命名空间(集群):若选择命名空间(集群),则以原生的方式提交至所选择 K8S 集群执行,未选择则提交至 Yarn 集群执行(默认)。
•任务名称(可选):Spark 程序的名称。
•Driver 核心数:用于设置 Driver 内核数,可根据实际生产环境设置对应的核心数。
•Driver 内存数:用于设置 Driver 内存数,可根据实际生产环境设置对应的内存数。•Executor 数量:用于设置 Executor 的数量,可根据实际生产环境设置对应的内存数。•Executor 内存数:用于设置 Executor 内存数,可根据实际生产环境设置对应的内存数。
•主程序参数:设置 Spark 程序的输入参数,支持自定义参数变量的替换。
•选项参数:支持 --jars、--files、--archives、--conf 格式。
•资源:如果其他参数中引用了资源文件,需要在资源中选择指定。
•自定义参数:是 Spark 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容。
1.3 任务样例
1.3.1 spark submit
1.3.1.1 执行 WordCount 程序
本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。
1.3.1.2 在 DolphinScheduler 中配置 Spark 环境
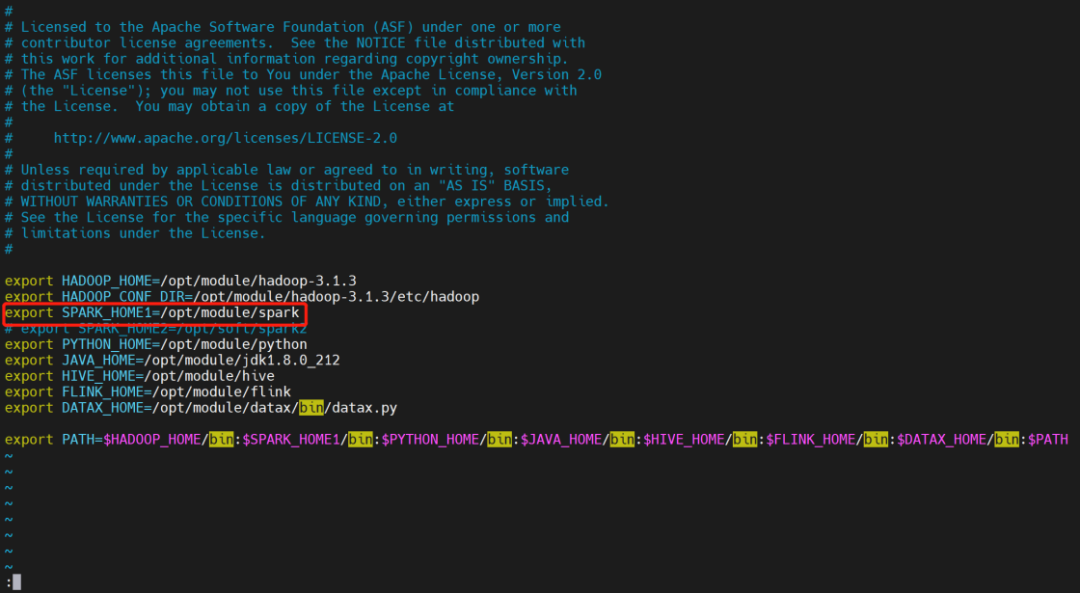
若生产环境中要是使用到 Spark 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
1.3.1.3 上传主程序包
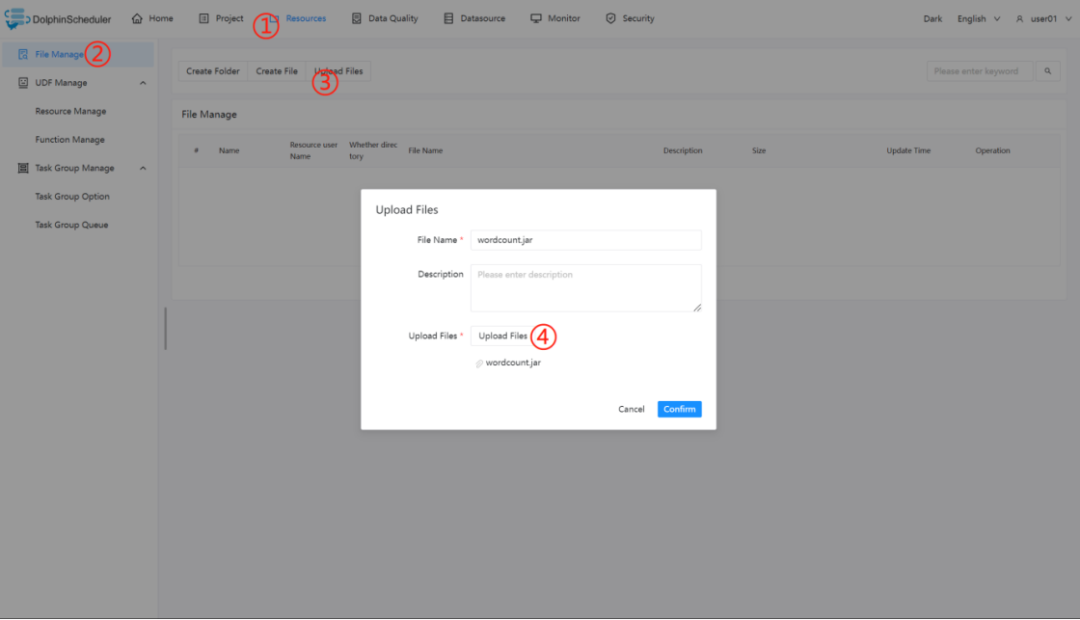
在使用 Spark 任务节点时,需要利用资源中心上传执行程序的 jar 包,可参考资源中心。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。
1.3.1.4 配置 Spark 节点
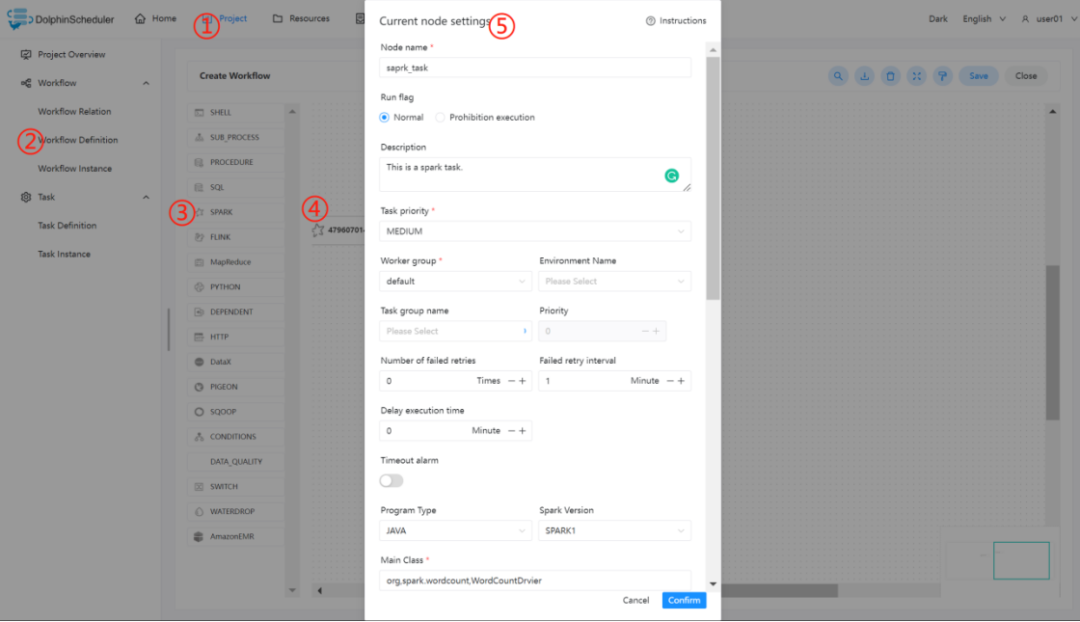
根据上述参数说明,配置所需的内容即可。
1.3.2 spark sql
1.3.2.1 执行 DDL 和 DML 语句
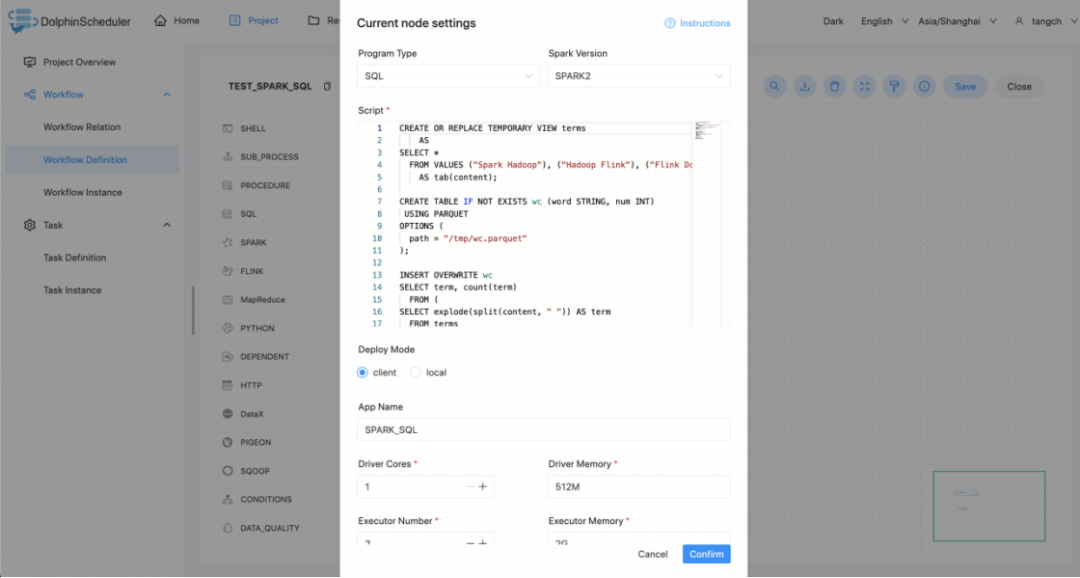
本案例为创建一个视图表 terms 并写入三行数据和一个格式为 parquet 的表 wc 并判断该表是否存在。程序类型为 SQL。将视图表 terms 的数据插入到格式为 parquet 的表 wc。
1.3.3 注意事项:
注意:JAVA 和 Scala 只用于标识,使用 Spark 任务时没有区别。如果应用程序是由 Python 开发的,那么可以忽略表单中的参数Main Class。参数SQL脚本仅适用于 SQL 类型,在 JAVA、Scala 和 Python 中可以忽略。
SQL 目前不支持 cluster 模式。
2. SQL
2.1 综述
SQL任务类型,用于连接数据库并执行相应SQL。
2.2 创建数据源
可参考 数据源配置 数据源中心。
2.3 创建任务
•点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
•工具栏中拖动 到画板中,选择需要连接的数据源,即可完成创建。
到画板中,选择需要连接的数据源,即可完成创建。
2.4 任务参数
•数据源:选择对应的数据源
•sql类型:支持查询和非查询两种。
•查询:支持 DML select 类型的命令,是有结果集返回的,可以指定邮件通知为表格、附件或表格附件三种模板;
•非查询:支持 DDL全部命令 和 DML update、delete、insert 三种类型的命令;
•默认采用;\n作为SQL分隔符,拆分成多段SQL语句执行。Hive的JDBC不支持一次执行多段SQL语句,请不要使用;\n。
•sql参数:输入参数格式为key1=value1;key2=value2…
•sql语句:SQL语句
•UDF函数:对于HIVE类型的数据源,可以引用资源中心中创建的UDF函数,其他类型的数据源暂不支持UDF函数。
•自定义参数:SQL任务类型,而存储过程是自定义参数顺序,给方法设置值自定义参数类型和数据类型,同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量}。
•前置sql:前置sql在sql语句之前执行。
•后置sql:后置sql在sql语句之后执行。
2.5 任务样例
2.5.1 Hive表创建示例
2.5.1.1 在hive中创建临时表并写入数据
该样例向hive中创建临时表tmp_hello_world并写入一行数据。选择SQL类型为非查询,在创建临时表之前需要确保该表不存在,所以我们使用自定义参数,在每次运行时获取当天时间作为表名后缀,这样这个任务就可以每天运行。创建的表名格式为:tmp_hello_world_{yyyyMMdd}。
注意:sql任务组件的hive应用是基于JDBC去调用,SQL statement 不支持多行执行,请注意不要在语句末尾使用';'。如果要执行多行语句请使用Hive-Cli任务。
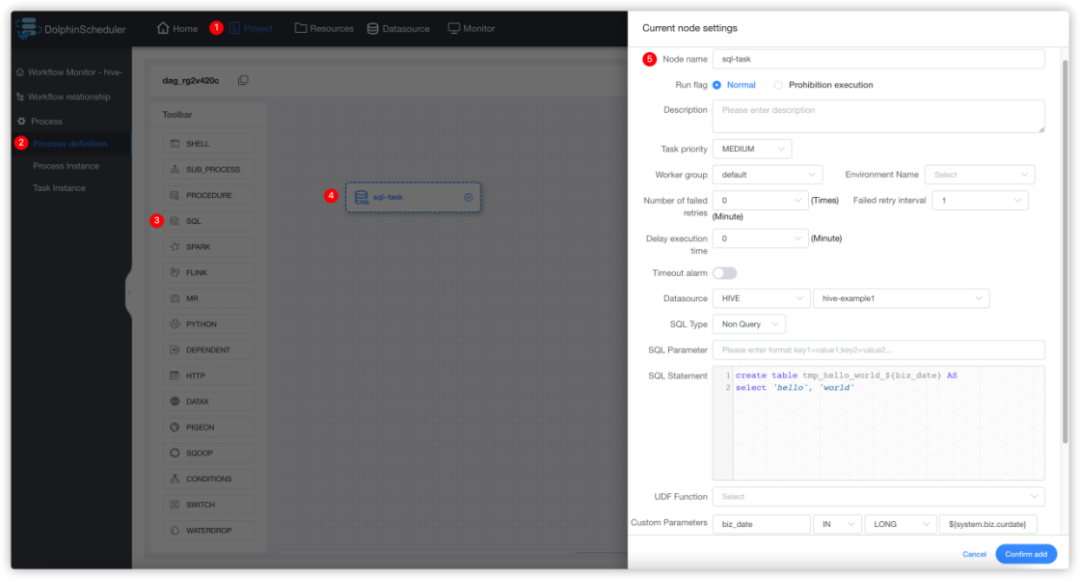
2.5.1.2 运行该任务成功之后在hive中查询结果
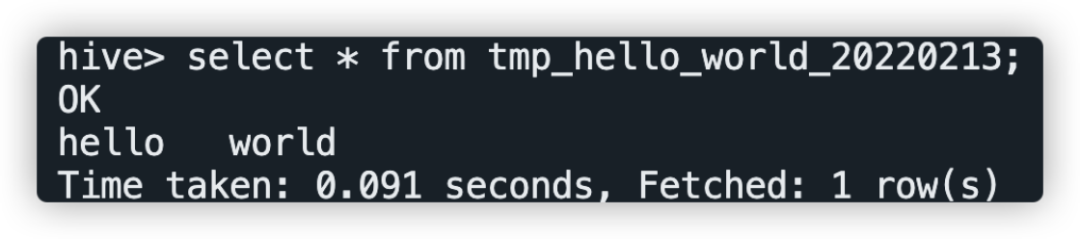
登录集群使用hive命令或使用beeline、JDBC等方式连接apache hive进行查询,查询SQL为select * from tmp_hello_world_{yyyyMMdd},请将{yyyyMMdd}替换为运行当天的日期,查询截图如下:
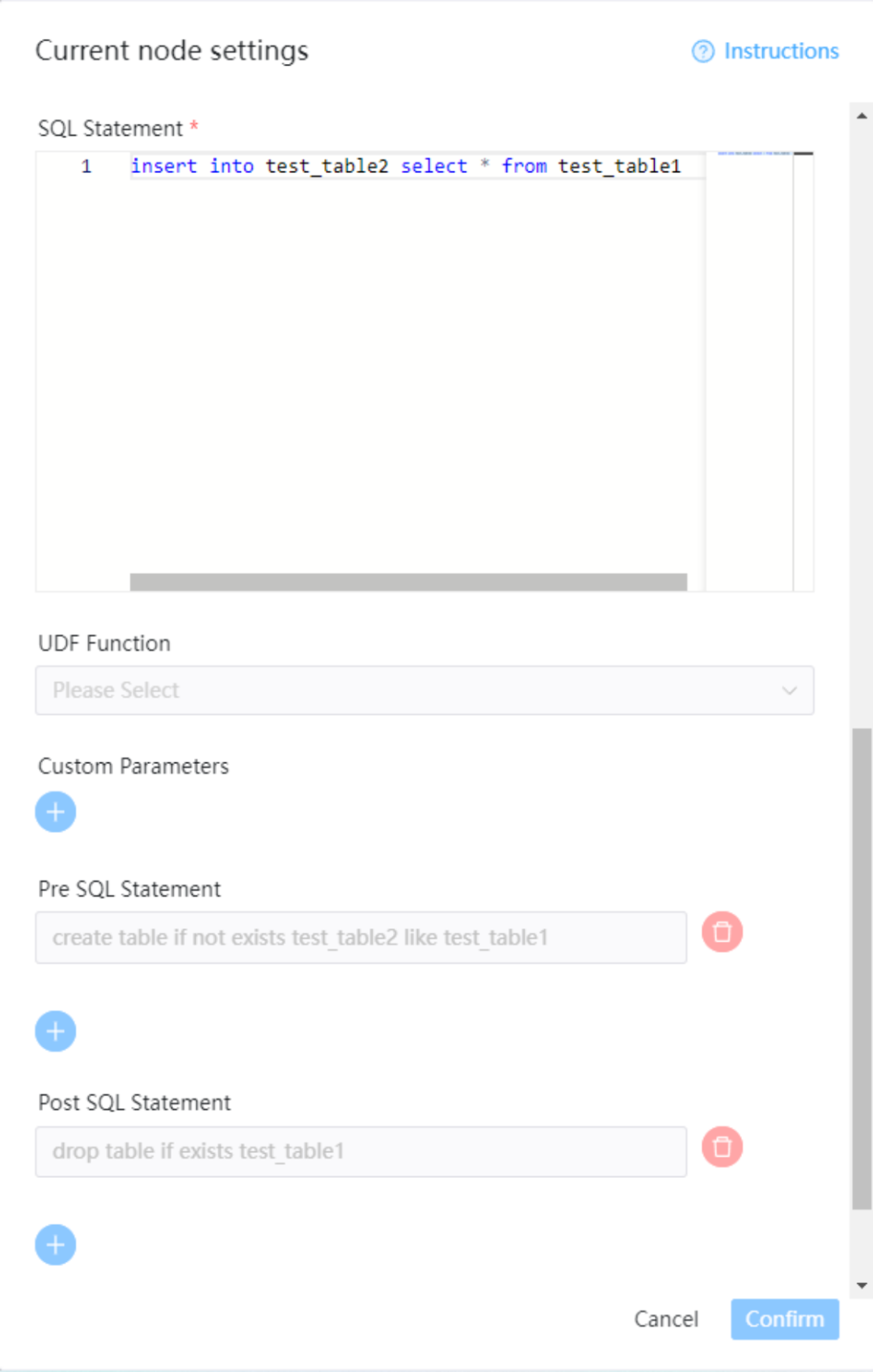
2.6 使用前置sql和后置sql示例
在前置sql中执行建表操作,在sql语句中执行操作,在后置sql中执行清理操作。
2.7 注意事项
•注意SQL类型的选择,如果是INSERT等操作需要选择非查询类型。
•为了兼容长会话情况,UDF函数的创建是通过CREATE OR REPLACE语句
3. SQOOP 节点
3.1 综述
SQOOP 任务类型,用于执行 SQOOP 程序。对于 SQOOP 节点,worker 会通过执行 sqoop 命令来执行 SQOOP 任务。
3.2 创建任务
•点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
•拖动工具栏的 任务节点到画板中。
任务节点到画板中。
3.3 任务参数
任务参数 | 描述 |
任务名称 | map-reduce 任务名称 |
流向 | (1) import:从 RDBMS 导入 HDFS 或Hive (2) export:从 HDFS 或 Hive 导出到 RDBMS |
Hadoop 参数 | 添加自定义 Hadoop 参数 |
Sqoop 参数 | 添加自定义 Sqoop 参数 |
数据来源 - 类型 | 选择数据源类型 |
数据来源 - 数据源 | 选择数据源 |
数据来源 - 模式 | (1) 单表:同步单张表的数据,需填写表名和列类型 (2) SQL:同步 SQL 查询的结果,需填写SQL语句 |
数据来源 - 表名 | 设置需要导入 hive 的表名 |
数据来源 - 列类型 | (1) 全表导入:导入表中的所有字段 (2) 选择列:导入表中的指定列,需填写列信息 |
数据来源 - 列 | 填写字段名称,多个字段之间使用英文逗号分割 |
数据来源 - SQL 语句 | 填写 SQL 查询语句 |
数据来源 - Hive 类型映射 | 自定义 SQL 与 Hive 类型映射 |
数据来源 - Java 类型映射 | 自定义 SQL 与 Java 类型映射 |
数据目的 - 类型 | 选择数据目的类型 |
数据目的 - 数据库 | 填写 Hive 数据库名称 |
数据目的 - 表名 | 填写 Hive 表名 |
数据目的 - 是否创建新表 | 选择是否自动根据导入数据类型创建数据目的表,如果目标表已经存在了,那么创建任务会失败 |
数据目的 - 是否删除分隔符 | 自动删除字符串中的\n、\r和\01字符 |
数据目的 - 是否覆盖数据源 | 覆盖 Hive 表中的现有数据 |
数据目的 - Hive 目标路径 | 自定义 Hive 目标路径 |
数据目的 - 替换分隔符 | 替换字符串中的\n、\r和\01字符 |
数据目的 - Hive 分区键 | 填写 Hive 分区键,多个分区键之间使用英文逗号分割 |
数据目的 - Hive 分区值 | 填写 Hive 分区值,多个分区值之间使用英文逗号分割 |
数据目的 - 目标路径 | 填写 HDFS 的目标路径 |
数据目的 - 是否删除目录 | 如果目录已经存在,则删除目录 |
数据目的 - 压缩类型 | 选择 HDFS 文件压缩类型 |
数据目的 - 保存格式 | 选择文件保存格式 |
数据目的 - 列分隔符 | 自定义列分隔符 |
数据目的 - 行分隔符 | 自定义行分隔符 |
3.4 任务样例
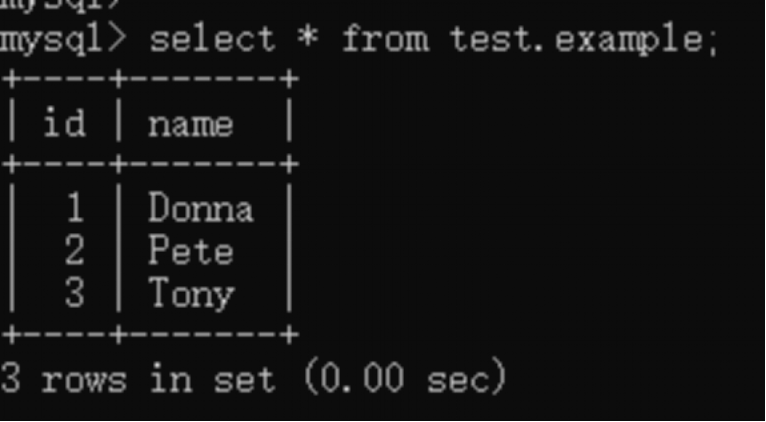
该样例演示为从 MySQL 数据导入到 Hive 中。其中 MySQL 数据库名称为:test,表名称为example。下图为样例数据。
3.4.1 配置 Sqoop 环境
若生产环境中要是使用到 Sqoop 任务类型,则需要先配置好所需的环境。确保任务节点可以执行sqoop命令。
3.4.2 配置 Sqoop 任务节点
可按照下图步骤进行配置节点内容。
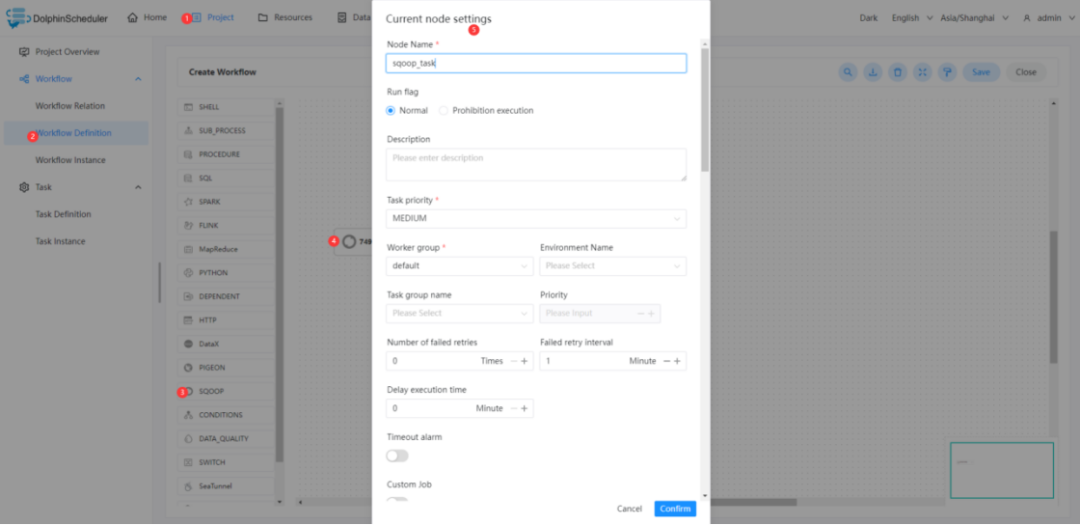
本样例中的关键配置如下表。
任务参数 | 参数值 |
任务名称 | sqoop_mysql_to_hive_test |
流向 | import |
数据来源 - 类型 | MYSQL |
数据来源 - 数据源 | MYSQL MyTestMySQL(您可以将MyTestMySQL改成您自己取的数据源名称) |
数据来源 - 模式 | 表单 |
数据来源 - 表名 | example |
数据来源 - 列类型 | 全表导入 |
数据目的 - 类型 | HIVE |
数据目的 - 数据库 | tmp |
数据目的 - 表名 | example |
数据目的 - 是否创建新表 | true |
数据目的 - 是否删除分隔符 | false |
数据目的 - 是否覆盖数据源 | true |
数据目的 - Hive 目标路径 | (无需填写) |
数据目的 - 替换分隔符 | , |
数据目的 - Hive 分区键 | (无需填写) |
数据目的 - Hive 分区值 | (无需填写) |
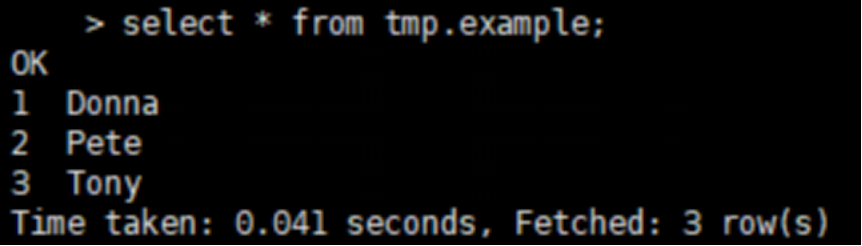
3.4.3 查看运行结果
更多大数据内容请关注字节智传公众号:
