




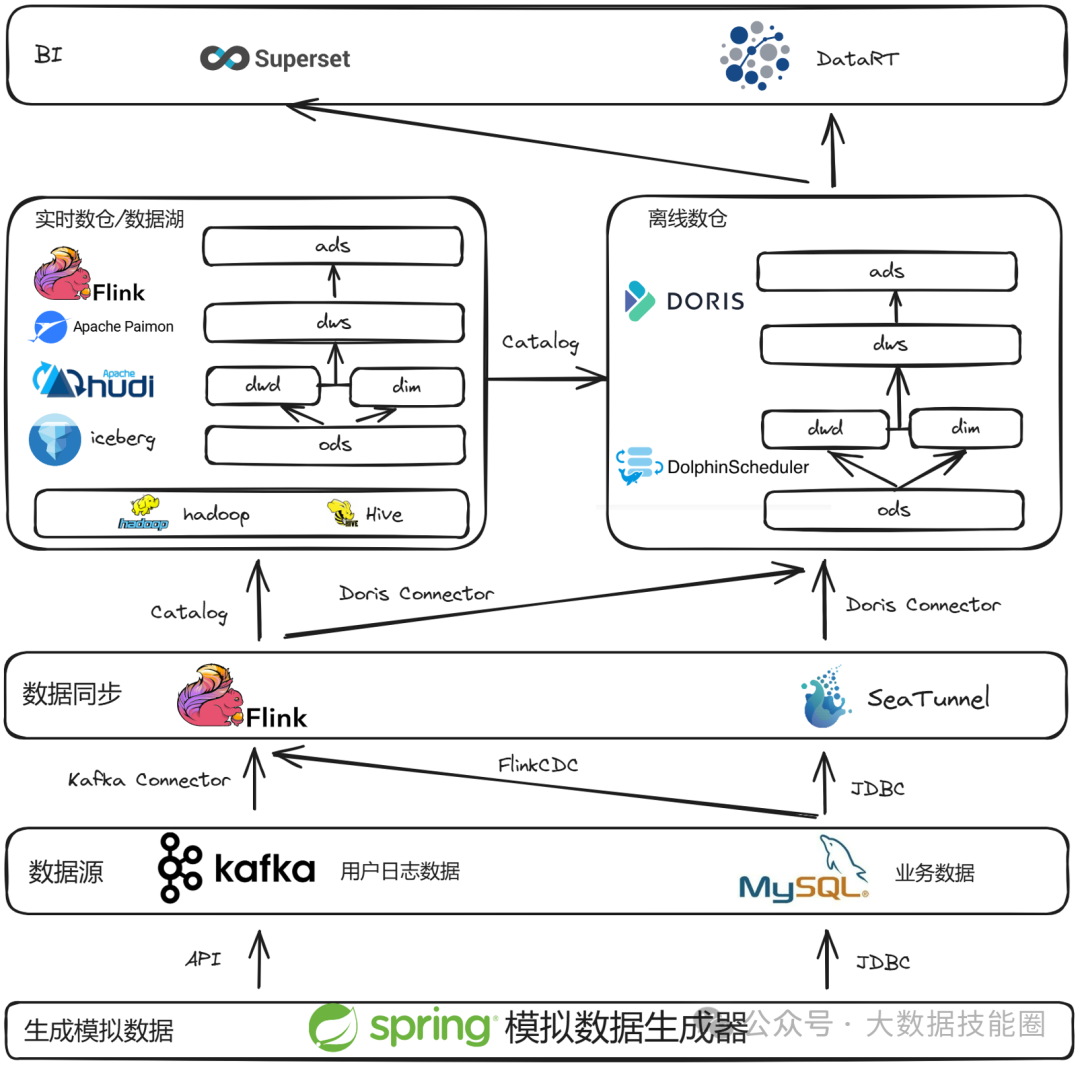
这或许是一个对你有用的开源项目,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning https://github.com/Mrkuhuo/data-warehouse-learning 项目演示:
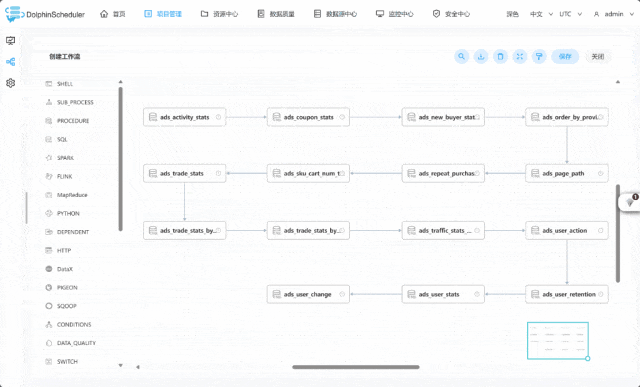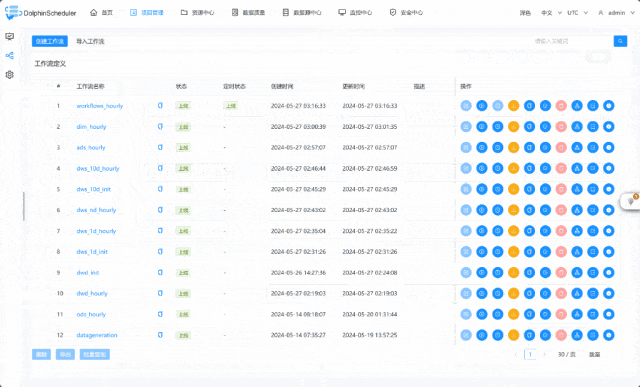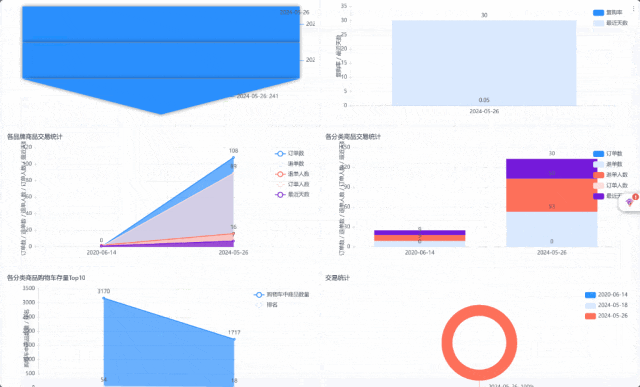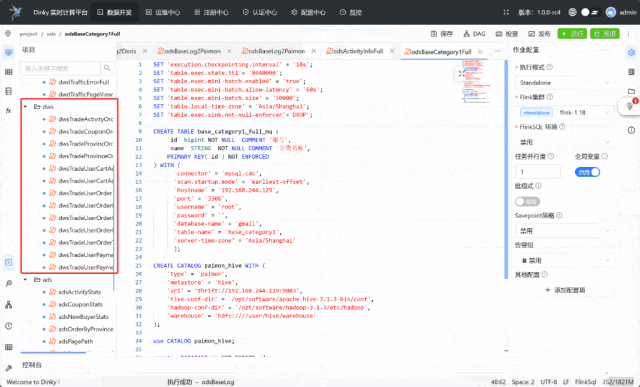
1. 用户日志模拟数据生成
2. ods层数仓建设
实时离线数仓实战No.13 | Paimon搭建实时数仓ODS层 →
3. dwd层数仓建设
实时离线数仓实战No.14 | Paimon搭建实时数仓DWD层 →
实时离线数仓实战No.15 | Paimon搭建实时数仓DIM层 →
5. dws层数仓建设
实现代码参考代码路径:
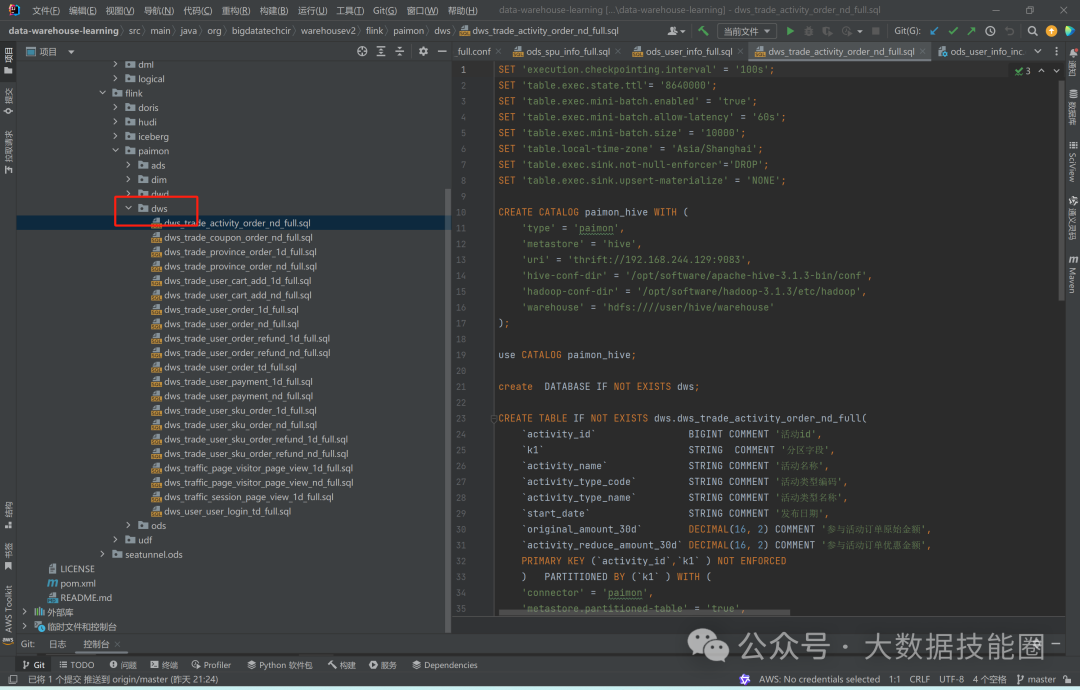
# 代码查看路径org/bigdatatechcir/warehousev2/flink/paimon/dws# 代码样例SET 'execution.checkpointing.interval' = '100s';SET 'table.exec.state.ttl'= '8640000';SET 'table.exec.mini-batch.enabled' = 'true';SET 'table.exec.mini-batch.allow-latency' = '60s';SET 'table.exec.mini-batch.size' = '10000';SET 'table.local-time-zone' = 'Asia/Shanghai';SET 'table.exec.sink.not-null-enforcer'='DROP';SET 'table.exec.sink.upsert-materialize' = 'NONE';CREATE CATALOG paimon_hive WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://192.168.244.129:9083','hive-conf-dir' = '/opt/software/apache-hive-3.1.3-bin/conf','hadoop-conf-dir' = '/opt/software/hadoop-3.1.3/etc/hadoop','warehouse' = 'hdfs:////user/hive/warehouse');use CATALOG paimon_hive;create DATABASE IF NOT EXISTS dws;CREATE TABLE IF NOT EXISTS dws.dws_trade_activity_order_nd_full(`activity_id` BIGINT COMMENT '活动id',`k1` STRING COMMENT '分区字段',`activity_name` STRING COMMENT '活动名称',`activity_type_code` STRING COMMENT '活动类型编码',`activity_type_name` STRING COMMENT '活动类型名称',`start_date` STRING COMMENT '发布日期',`original_amount_30d` DECIMAL(16, 2) COMMENT '参与活动订单原始金额',`activity_reduce_amount_30d` DECIMAL(16, 2) COMMENT '参与活动订单优惠金额',PRIMARY KEY (`activity_id`,`k1` ) NOT ENFORCED) PARTITIONED BY (`k1` ) WITH ('connector' = 'paimon','metastore.partitioned-table' = 'true','file.format' = 'parquet','write-buffer-size' = '512mb','write-buffer-spillable' = 'true' ,'partition.expiration-time' = '1 d','partition.expiration-check-interval' = '1 h','partition.timestamp-formatter' = 'yyyy-MM-dd','partition.timestamp-pattern' = '$k1');INSERT INTO dws.dws_trade_activity_order_nd_full(activity_id, k1, activity_name, activity_type_code, activity_type_name, start_date, original_amount_30d, activity_reduce_amount_30d)selectact.activity_id,od.k1,activity_name,activity_type_code,activity_type_name,date_format(start_time,'yyyy-MM-dd'),sum(split_original_amount),sum(split_activity_amount)from(selectactivity_id,activity_name,activity_type_code,activity_type_name,start_timefrom dim.dim_activity_fullgroup by activity_id, activity_name, activity_type_code, activity_type_name,start_time)actleft join(selectactivity_id,k1,order_id,split_original_amount,split_activity_amountfrom dwd.dwd_trade_order_detail_fullwhere activity_id is not null)odon act.activity_id=od.activity_idgroup by act.activity_id,od.k1,activity_name,activity_type_code,activity_type_name,start_time;
FlinkSQL处理 Paimon dwd层和dim层数据实时写入Paimon dws层中。
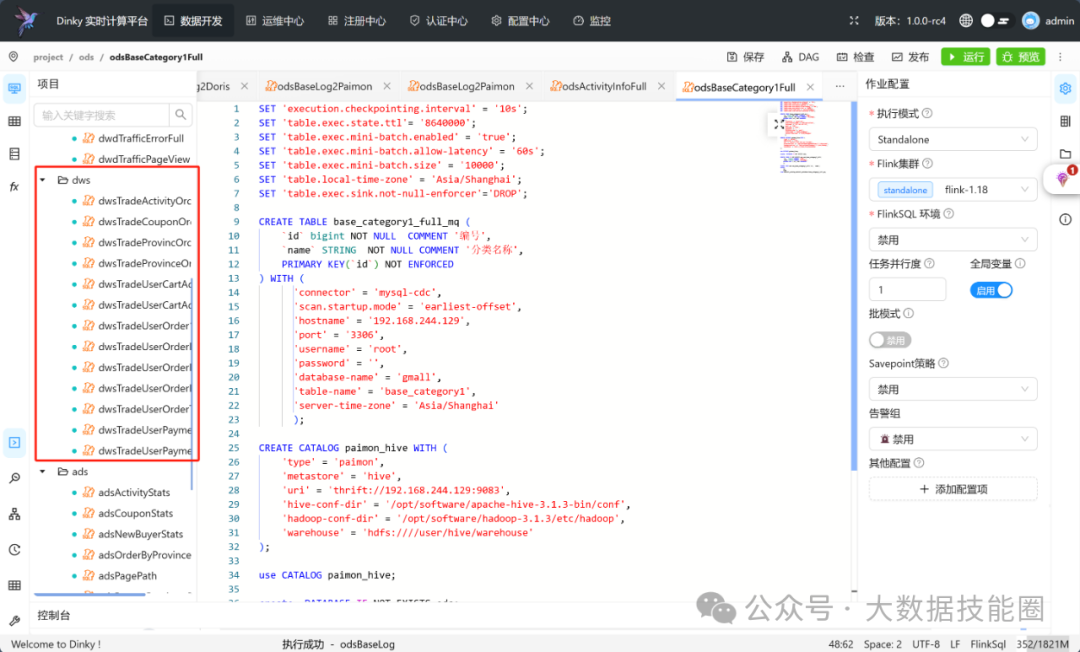
可在hive中查看通过paimon写进数仓dws层的表

项目文档地址
添加作者进大数据交流群
推荐阅读
文章转载自大数据技能圈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
